本文不生产技术,只做技术的搬运工!!
前言
公开的Qwen2.5-VL模型虽然功能非常强大,但有时面对专业垂直领域的问题往往会出现一些莫名其妙的回复,这时候大家一版选择对模型进行微调,而微调后的模型如果直接部署则显存开销过大,这时就需要执行量化,下面将介绍执行本地GPTQ量化的具体流程。
ms-swift
由于作者没有找到AutoGPTQ框架下进行Qwen2.5-VL的量化教程,所以干脆偷懒,使用ms-swift进行量化
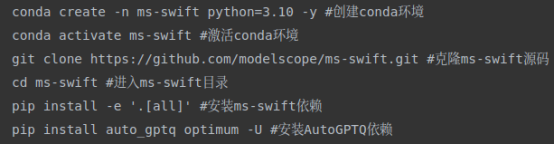
这里安装完成后还需要补充一下安装
pip install qwen_vl_utils
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0执行量化
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift export \--model /data/qwen2.5-vl-32b/ \--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \




![[Upscayl图像增强] Electron主进程命令 | 进程间通信IPC](http://pic.xiahunao.cn/[Upscayl图像增强] Electron主进程命令 | 进程间通信IPC)



)



)

)
)
: Qwen3‑Max‑Preview上线、GLM-4.5提供一键迁移、Gemini for Home,AI风向何在?)

