Spring Cloud Sleuth作为微服务架构中的核心监控组件,通过轻量级的无侵入式跟踪机制,解决了分布式系统中请求路径复杂、问题定位困难的痛点。它自动为每个服务请求创建唯一的Trace ID,并为每个服务间调用生成Span ID,形成完整的调用链路图,使开发人员能够清晰地看到请求在各个服务间的流转过程。Sleuth的核心价值在于提供了一种简单高效的方式来实现分布式系统的可观测性,帮助开发团队快速定位性能瓶颈和故障根源。

一、什么是Spring Cloud Sleuth?
Spring Cloud Sleuth是一个专为Spring Boot和Spring Cloud应用设计的分布式追踪解决方案。它通过在请求的Header中自动添加跟踪信息(如Trace ID、Span ID等),实现了跨服务调用的链路追踪。当一个请求从客户端传入微服务系统时,Sleuth会为该请求创建一个唯一的Trace ID,并为系统内每个服务的处理过程创建对应的Span ID,通过父子关系将整个调用链路串联起来 。
Sleuth的设计理念是"无侵入式跟踪",这意味着开发者不需要在业务代码中添加任何跟踪逻辑,框架会自动处理所有跨服务调用的跟踪工作。这种设计使得Sleuth能够无缝集成到Spring Cloud生态中,与Feign、Ribbon、Hystrix等组件协同工作,提供完整的微服务监控能力 。
二、诞生背景
1. 微服务架构的挑战
随着微服务架构的普及,系统复杂度急剧上升。一个简单的用户请求可能需要经过多个微服务的协同处理,形成复杂的调用链路 。这种架构带来了以下挑战:
- 问题定位困难:当链路上的某个服务出现故障时,难以快速定位问题所在。
- 性能分析复杂:请求的总耗时由多个服务的处理时间和网络传输时间共同决定,难以精确分析各环节的性能表现。
- 依赖关系不透明:服务间的依赖关系随着业务发展变得越来越复杂,缺乏可视化工具来展示这种依赖关系。
2. 分布式追踪的出现
为了解决上述问题,分布式追踪技术应运而生。Spring Cloud Sleuth正是基于这种需求,为Spring生态提供了专业的链路追踪解决方案。
在Spring Cloud生态中,Sleuth与Zipkin结合使用,形成了完整的分布式追踪系统:Sleuth负责在服务端收集跟踪数据,Zipkin负责存储和可视化这些数据。这种组合为微服务架构提供了从请求入口到出口的全链路追踪能力,使开发者能够直观地看到请求在各个服务间的流转过程。
三、架构设计
1. 核心组件
Spring Cloud Sleuth的架构主要包括以下几个核心组件:
| 组件 | 功能描述 |
|---|---|
| Tracer | 跟踪器,负责创建和管理Trace和Span |
| span tags | 标签,用于记录Span的元数据信息 |
| span context | 上下文,用于在服务间传递跟踪信息 |
| span使者 | 负责将跟踪数据发送到Zipkin等收集器 |
2. 数据模型
Sleuth基于OpenTracing标准实现,其数据模型主要包括以下概念:
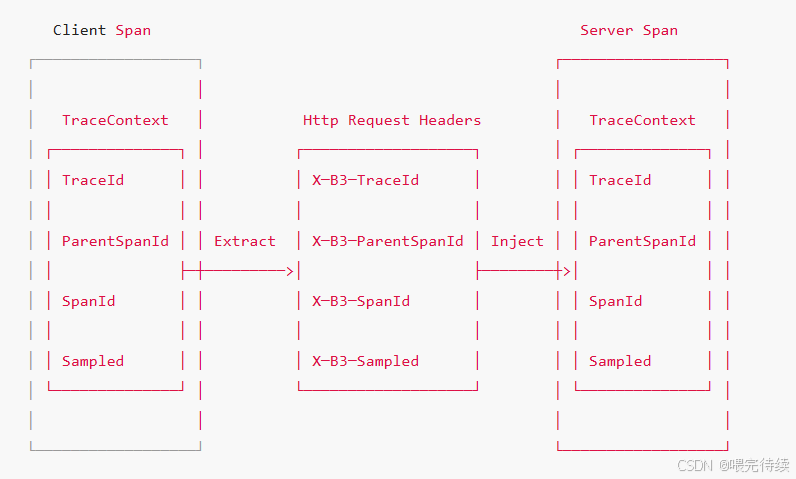
Trace(追踪):表示一个完整的请求链路,由多个Span组成,通过Trace ID唯一标识 。
Span(跨度):表示请求链路中的一个工作单元,如一次HTTP请求或RPC调用,通过Span ID唯一标识 。
Parent ID(父ID):用于表示Span之间的父子关系,将整个调用链路串联成树状结构 。
时间戳和注解:记录Span的开始时间、结束时间以及关键事件(如客户端发送请求、服务端接收请求等) 。
标签(Tags):记录Span的元数据信息,如服务名称、方法名、IP地址等 。
举个例子:用户下单请求的链路结构
Trace ID: a1b2c3d4(整个链路唯一)
├─ Span 1(网关接收请求):Span ID=x5y6z7,父Span ID=null(根Span)
│ ├─ Annotation: cs(网关接收请求时间)
│ └─ Annotation: sr(网关转发前时间)
├─ Span 2(订单服务接收请求):Span ID=p8q9r0,父Span ID=x5y6z7
│ ├─ Annotation: cs(订单服务接收时间)
│ └─ Annotation: sr(订单服务处理前时间)
└─ Span 3(库存服务接收请求):Span ID=m2n3o4,父Span ID=p8q9r0├─ Annotation: cs(库存服务接收时间)└─ Annotation: sr(库存服务处理前时间)3. 工作原理
Sleuth的工作原理可以分为以下几个关键步骤:
请求入口跟踪:当请求进入微服务系统时,Sleuth会自动创建一个Trace,并为入口服务生成第一个Span 。
跨服务调用跟踪:在服务间调用时(如通过Feign或Ribbon),Sleuth会自动将当前Span的上下文信息(如Trace ID、Span ID等)通过HTTP Header传递给被调用服务,使被调用服务能够创建关联的Span 。
Span生命周期管理:每个Span都有明确的开始和结束,Sleuth会自动记录这些时间点,并计算处理时间 。
数据收集与发送:Sleuth会将生成的Span数据收集起来,并通过配置的发送器(如HTTP或Kafka)发送到Zipkin等收集器 。
上下文传播机制:Sleuth通过字节码增强技术,在HTTP请求、消息队列等通信通道中自动传播跟踪上下文,无需开发者手动处理 。
+---------------------+ +---------------------+ +---------------------+
| 微服务A | | 微服务B | | 微服务C |
| (订单服务) | | (支付服务) | | (库存服务) |
+----------+----------+ +----------+----------+ +----------+----------+| | || 1. 生成Trace/Span | | ||----------------------------> | || 2. 传递TraceContext (HTTP头) | | ||<-----------------------------| | || | 3. 生成子Span | || |----------------------------> || | | 4. 传递TraceContext || | |----------------------------> || | | | 5. 生成最终Span| | | |<-----------------------------| | | || | | 6. 上报Zipkin || | |----------------------------> || | | | 7. 存储到Elasticsearch| | | |<-----------------------------| | | || | | | 8. 可视化展示| | | |------------------------------>
+----------+----------+ +----------+----------+ +----------+----------+| | | || 9. 日志关联Trace ID | | ||----------------------------> | || | 10. 日志聚合分析 | || |----------------------------> || | | 11. 监控告警 |
+----------+----------+ +----------+----------+ +----------+----------+四、解决的问题
1. 链路复杂性问题
在微服务架构中,一个请求可能经过多个服务的处理,形成复杂的调用链路。Sleuth通过Trace和Span的树状结构,将这些复杂的调用关系清晰地呈现出来,使开发者能够直观地理解请求的处理流程。
2. 问题定位困难
当系统出现故障时,传统日志方法难以快速定位问题所在服务。Sleuth通过将请求与Trace ID关联,使开发者能够根据Trace ID快速定位到完整的调用链路,进而找到故障发生的具体服务和位置。
3. 性能分析困难
请求的总耗时由多个服务的处理时间和网络传输时间共同决定。Sleuth通过记录各个Span的时间戳,能够精确分析每个服务的处理时间和网络延迟,帮助开发者找出性能瓶颈 。
4. 服务依赖关系不透明
微服务架构下,服务间的依赖关系随着业务发展变得越来越复杂。Sleuth通过可视化调用链路,使开发者能够清晰地看到服务间的依赖关系,进而优化系统架构 。
五、关键特性
1. 无侵入式跟踪
Sleuth的核心优势是无侵入式跟踪,开发者无需在业务代码中添加任何跟踪逻辑,框架会自动处理所有跨服务调用的跟踪工作 。这种设计使得Sleuth能够无缝集成到Spring Cloud生态中,与Feign、Ribbon、Hystrix等组件协同工作。
2. 自动上下文传播
Sleuth通过字节码增强技术,在HTTP请求、消息队列等通信通道中自动传播跟踪上下文,无需开发者手动处理 。这种机制确保了跨服务调用的链路完整性,使开发者能够看到完整的请求处理流程。
3. 多种采样策略
Sleuth支持多种采样策略,包括百分比采样(PercentageBasedSampler)和边界采样(BoundarySampler)等 。通过调整采样率,开发者可以在数据采集的完整性和系统性能之间找到平衡点,避免在高并发场景下因全量采集导致的性能问题。
4. 灵活的数据发送机制
Sleuth支持多种数据发送机制,包括HTTP直接发送(默认)和通过消息队列(如Kafka或RabbitMQ)发送等。这种灵活性使得Sleuth能够适应不同的系统环境和性能需求。
5. 与多种存储后端集成
Sleuth生成的跟踪数据可以发送到多种存储后端,包括Zipkin、Elasticsearch、MySQL等。这种集成能力使得开发者可以根据实际需求选择最适合的存储方案,平衡数据存储的性能和成本。
6. 与OpenTelemetry兼容
随着OpenTelemetry成为行业标准,Spring Cloud Sleuth也提供了与OpenTelemetry的兼容方案。通过排除默认的Brave实现,引入OpenTelemetry的SDK和出口器,Sleuth可以与更广泛的可观测性生态系统集成。
六、同类产品对比
1. 与CAT对比
| 特性 | Spring Cloud Sleuth | CAT |
|---|---|---|
| 埋点方式 | 自动(无侵入式) | 需要手动代码埋点 |
| 配置复杂度 | 简单,通过YAML/Properties配置 | 需要额外配置文件和目录 |
| 存储选型 | 灵活,支持多种现代存储 | 选型较老旧,扩展性差 |
| 功能专注性 | 专注于链路追踪 | 功能综合性强,但链路追踪功能较弱 |
| 适用场景 | Spring Cloud生态,轻量级跟踪 | 大型系统,需要综合监控 |
CAT是一个更综合性的监控平台,提供了日志、性能、业务等多方面的监控功能,但其链路追踪功能相对弱,且需要侵入式代码埋点,增加了业务开发的复杂度。Spring Cloud Sleuth专注于链路追踪,与CAT相比,它在Spring生态中的集成更加紧密,配置更加简单,适合需要快速实现链路追踪的微服务系统。
2. 与SkyWalking对比
| 特性 | Spring Cloud Sleuth | SkyWalking |
|---|---|---|
| 埋点方式 | 自动(无侵入式) | 需要Agent注入 |
| 配置复杂度 | 简单,通过YAML/Properties配置 | 复杂,需要Agent部署 |
| 存储选型 | 支持多种存储,但功能相对简单 | 功能全面,支持多种存储 |
| 可视化能力 | 依赖Zipkin等外部工具 | 自带强大的可视化界面 |
| 适用场景 | Spring Cloud生态,轻量级跟踪 | 复杂系统,需要全面监控 |
SkyWalking是一个功能全面的APM(应用性能管理)系统,提供了从链路追踪到性能监控的全方位解决方案。与Sleuth相比,SkyWalking的配置和部署更加复杂,需要Agent注入,而Sleuth则通过Spring Boot的自动配置机制简化了部署流程。在Spring Cloud生态中,Sleuth提供了更轻量级的链路追踪解决方案,而SkyWalking则提供了更全面的性能监控能力。
3. 与Jaeger对比
| 特性 | Spring Cloud Sleuth | Jaeger |
|---|---|---|
| 埋点方式 | 自动(无侵入式) | 需要手动配置或自动检测 |
| 配置复杂度 | 简单,通过YAML/Properties配置 | 复杂,需要独立部署 |
| 存储选型 | 支持多种存储,但功能相对简单 | 支持Elasticsearch、Cassandra等 |
| 可视化能力 | 依赖Zipkin等外部工具 | 自带强大的可视化界面 |
| 云原生支持 | 支持,但需要额外配置 | 原生支持Kubernetes等云环境 |
| 适用场景 | Spring Cloud生态,轻量级跟踪 | 复杂云环境,需要全面监控 |
Jaeger是一个专注于分布式追踪的开源工具,由Uber开源,支持多种存储后端和云环境。与Sleuth相比,Jaeger的配置和部署更加复杂,需要独立部署,而Sleuth则通过与Spring Boot的紧密集成简化了部署流程。在云原生环境中,Jaeger提供了更好的支持,而Sleuth则在Spring Cloud生态中表现更佳。
七、使用方法
1. 基础配置
步骤1:启动Zipkin服务端
使用Docker快速启动Zipkin服务端:
docker run -d -p 9411:9411 openzipkin/zipkin访问Zipkin UI:http://localhost:9411/zipkin/
步骤2:在微服务中添加依赖
在pom.xml中添加Sleuth和Zipkin依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>步骤3:配置应用属性
在application.yml中配置Zipkin地址和采样率:
spring:application:name: your-service-namesleuth:sampler:probability: 1.0 # 采样率,1.0表示全量采集zipkin:sender:type: web # 数据发送方式,web表示HTTP直接发送base-url: http://localhost:9411 # Zipkin服务地址2. 高级配置
使用MySQL存储跟踪数据
步骤1:初始化Zipkin数据库
CREATE TABLE zipkin_spans (trace_id_high BIGINT NOT NULL DEFAULT 0,trace_id BIGINT NOT NULL,id BIGINT NOT NULL,name VARCHAR(255) NOT NULL,remote_service_name VARCHAR(255),parent_id BIGINT,debug BIT(1),start_ts BIGINT,duration BIGINT,PRIMARY KEY (trace_id_high, trace_id, id),INDEX (trace_id_high, trace_id),INDEX (name),INDEX (remote_service_name),INDEX (start_ts)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE=utf8_general_ci;-- 创建其他必要的表(略)步骤2:配置Zipkin服务端使用MySQL
java -jar zipkin-server-2.20.1-exec.jar \--STORAGE_TYPE=mysql \--MYSQL_HOST=localhost \--MYSQL_PORT=3306 \--MYSQL_USER=root \--MYSQL_PASSWORD=root \--MYSQL_DB=zipkin步骤3:在微服务中添加MySQL驱动依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency>使用Kafka作为消息中间件
步骤1:添加Kafka依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>步骤2:配置Kafka和Zipkin
spring:zipkin:sender:type: kafka # 使用Kafka发送数据cloud:stream:binders:zipkin:type: kafka# 当项目同时使用kafka和rabbit时,需要指定zipkin:目的地: zipkin # Kafka主题名称
kafka:bootstrap-servers: 192.168.1.36:9092,192.168.1.33:9092,192.168.1.47:9092使用OpenTelemetry
步骤1:排除默认的Brave实现,添加OpenTelemetry依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId><exclusions><exclusion><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-brave</artifactId></exclusion></exclusions>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-otel-autoconfigure</artifactId>
</dependency>
<dependency><groupId>io.opentelemetry</groupId><artifactId>opentelemetry-exporter-otlp-trace</artifactId>
</dependency>步骤2:配置OpenTelemetry
spring:sleuth:otel:config:trace-id-ratio-based: 1.0 # 采样率exporter:otlp:endpoint: http://otel-collector:4317 # OpenTelemetry收集器地址protocol: http/1.13. 使用示例
通过Feign调用生成Span
@Service
public class PaymentService {@Autowiredprivate RestTemplate restTemplate;@GetMapping("/payment/zipkin")public String paymentZipkin() {// 通过RestTemplate调用其他服务,自动生成Spanreturn restTemplate.getForObject("http://CLOUD-PAYMENT-SERVICE/payment/zipkin", String.class);}
}自定义Span标签
@RestController
public class OrderController {@Autowiredprivate Tracer tracer;@GetMapping("/order")public String createOrder() {Span span = tracer.currentSpan();spantag("order-type", "standard"); // 添加自定义标签spantag("priority", "high"); // 添加自定义标签return "Order created successfully";}
}在日志中关联Trace ID
@RestController
public class UserController {@Autowiredprivate Tracer tracer;@GetMapping("/user")public String getUser() {Span span = tracer.currentSpan();MDC.put("X-B3-TraceId", spancontext().traceIdString()); // 将Trace ID注入日志框架MDC.put("X-B3-SpanId", spancontext().spanIdString()); // 将Span ID注入日志框架// 业务逻辑MDC.remove("X-B3-TraceId"); // 清除Trace IDMDC.remove("X-B3-SpanId"); // 清除Span IDreturn "User information";}
}4. 最佳实践
采样率优化:在生产环境中,应根据系统负载和性能需求合理设置采样率。对于QPS较高的系统,建议将采样率设置为5%-10%,关键业务场景可动态提升采样率。
跨语言支持:对于多语言微服务系统,需确保各服务正确透传跟踪Header。例如,对于Python服务,可通过中间件自动注入和转发X-B3-* Header。
性能监控:Sleuth本身对系统性能有一定影响,特别是在高并发场景下。可通过以下方式优化性能:
- 使用异步发送机制
- 设置合理的采样率
- 避免在循环或高频调用中生成Span
数据存储扩展:对于大规模微服务系统,建议使用Elasticsearch或Cassandra等分布式存储后端,并设置合理的索引生命周期管理策略(如设置索引TTL为7天)。
与监控系统集成:将Sleuth的跟踪数据与Prometheus、Grafana等监控系统集成,实现更全面的系统可观测性。
八、Azure云环境下的配置
对于部署在Azure云环境中的微服务,Sleuth提供了专门的配置方案:
步骤1:添加Azure依赖
<dependency><groupId>com.azure.spring</groupId><artifactId>spring-cloud-azure-starter-appconfiguration-config</artifactId>
</dependency>步骤2:配置Azure应用配置
spring:cloud:azure:appconfiguration:stores[0]:connection-string: ${CONFIGSTORE_CONNECTIONSTRING}credential:managed-identity-enabled: true # 使用托管标识client:http:logging:level: HEADERS # 记录HTTP请求和响应的头部信息pretty-print-body: false步骤3:配置Sleuth与Azure集成
spring:sleuth:otel:config:trace-id-ratio-based: 0.1 # 默认采样率exporter:otlp:endpoint: https://你的收集器地址headers:Azure-Function-Id: your-function-id九、未来发展趋势
随着云原生和可观测性技术的发展,Spring Cloud Sleuth也在不断演进:
OpenTelemetry集成:Spring Cloud Sleuth正在逐步与OpenTelemetry集成,提供更标准、更全面的跟踪能力。
云原生支持:Spring Cloud Sleuth正在加强对Kubernetes、Service Mesh等云原生环境的支持,提供更灵活的部署方案 。
AI驱动的分析:未来Sleuth可能会结合AI技术,对跟踪数据进行更智能的分析,帮助开发者更快地发现潜在问题。
与监控系统的深度集成:Sleuth可能会与Prometheus、Grafana等监控系统进行更深度的集成,提供更全面的系统可观测性。
十、文末
Spring Cloud Sleuth作为微服务架构中的链路追踪工具,通过轻量级的无侵入式跟踪机制,解决了分布式系统中请求路径复杂、问题定位困难的痛点。它通过自动创建和管理Trace和Span,形成完整的调用链路图,帮助开发人员快速定位性能瓶颈和故障根源。
与同类产品相比,Sleuth在Spring Cloud生态中的集成更加紧密,配置更加简单,适合需要快速实现链路追踪的微服务系统。对于复杂系统,可以考虑与SkyWalking、Jaeger等更全面的监控系统结合使用,实现更全面的系统可观测性。
在实际应用中,应根据系统规模和性能需求合理配置Sleuth,包括采样率、数据存储后端和发送机制等。对于大规模系统,建议使用Elasticsearch或Cassandra等分布式存储后端,并结合OpenTelemetry实现更标准的跟踪能力。
Spring Cloud Sleuth的核心价值在于提供了一种简单高效的方式来实现分布式系统的可观测性,帮助开发团队快速定位问题,优化系统性能,提升系统稳定性。随着云原生和可观测性技术的发展,Sleuth将继续演进,为微服务架构提供更强大的链路追踪能力。
参考资料:
- Spring Cloud Sleuth 文档
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于博主:
🌟博主GitHub
🌞博主知识星球
|入门的开始:Linux基本指令(2))














图表--环境监测表盘)



