最近面试过程中,Predict-then-Optimize是运筹优化算法工程师未来的发展方向。就像我之前写过的运筹优化(OR)-在机器学习(ML)浪潮中何去何从?-CSDN博客,机器学习适合预测、运筹优化适合决策。我研究的基本就是调度优化方面,因此对时序需求的预测显得十分重要。
而我之前只是使用多层感知机(MLP)做过一些回归预测,它本身不理解时序序列的顺序性。DNN其实是时序预测的好工具,其中GNN、LSTM、GRU、Transformer都是非常好的DNN特定架构。MLP也属于DNN,只是他不能理解时间顺序。
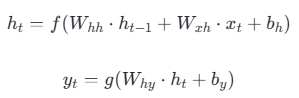
此外,时序预测还可以使用梯度提升树、Prophet以及传统的SARIMA。今天就先梳理一下循环神经网络(GNN)的使用,以及他的变体LSTM。
循环神经网络GNN
与标准神经网络不同,RNN引入了一个隐藏状态。隐藏状态
和输出
通过上一时间步的隐藏状态
以及当前时间步输入向量
计算。
GNN的“循环”也体现在:
结构上:同一个神经网络单元在时间序列上反复调用自己,并通过隐藏状态形成一个从过去指向未来的反馈连接;
数学上:隐藏状态的计算是一个递归公式(),当前状态不断“循环”地依赖于过去的状态。
然而,RNN有一个致命的问题,就是会产生梯度爆炸/消失的问题,这就需要LSTM解决。
长短期记忆网络LSTM
引入了两个核心组件:细胞状态和门控机制(Gates)。
细胞状态: LSTM 的“长期记忆高速公路”;
遗忘门:
![]() ,用sigmoid激活函数输出0-1的向量,
,用sigmoid激活函数输出0-1的向量,中每个元素表示
的每个分量保留多少;
输入门:
![]() ,用sigmoid激活函数输出0-1的向量,
,用sigmoid激活函数输出0-1的向量,中每个元素表示哪些新信息重要;
输出门:
![]() ,用sigmoid激活函数输出0-1的向量,
,用sigmoid激活函数输出0-1的向量,中每个元素表示哪些信息作为
;
候选细胞状态:
![]()
更新细胞状态:![]() ,前一项去除不需要的旧信息,后一项添加有用的新信息,用到了遗忘门和输入门;
,前一项去除不需要的旧信息,后一项添加有用的新信息,用到了遗忘门和输入门;
![]() ,生成最终的隐藏状态,用到了输出门。
,生成最终的隐藏状态,用到了输出门。
上述是LSTM单元的更新,最后进行输出层的更新。
![]() ,其中,对于激活函数
,其中,对于激活函数的选择,序列生成任务可以用softmax、分类任务可以用sigmoid/softmax、时间序列预测等回归任务则通常是线性函数。
上述就是LSTM对GNN的改进,GRU则是LSTM的简化而高效的变体机器学习-时序预测2-CSDN博客。








)
)








Redis 分布式锁及改进策略详解)
