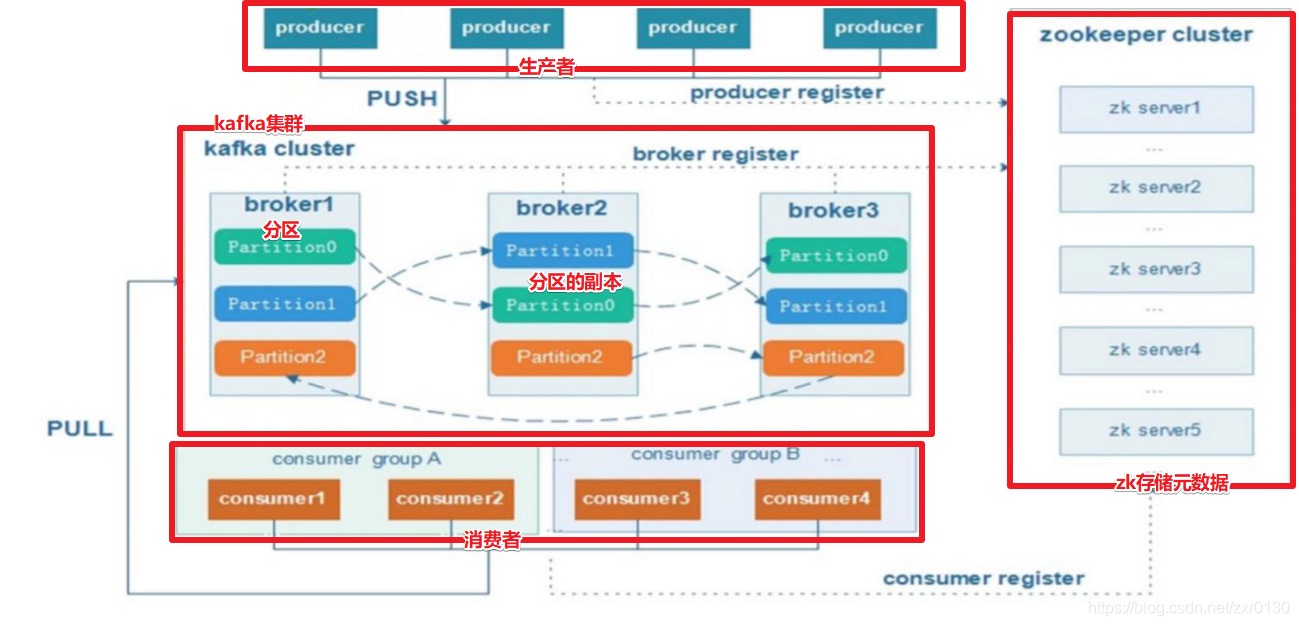
一个kafka集群中包含一个或多个Producer、一个或多个broker、一个或多个ConsumerGrop以及一个Zookeeper集群。kafka通过Zookeeper管理kafka集群配置、leader副本的选举、生产者的负载均衡等。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
专业术语
- kafkaCluster : kafka集群,由一个或多个Broker节点组成。
- Broker : 一个Kafka集群包括一个或多个服务器,一台服务器就是一个Broker节点。Broker用于保存Producer发送的消息。
- Producer :生产者,用来发送指定的Topic的消息到Broker。生产者可以是代码,还可以是命令行工具。本质上是一个进程或者线程。
- Consumer :消费者,用来接收/消费Kafka集群中的消息。每个Consumer属于一个ConsumerGroup(如果在创建消费者时没有指定Consumer,系统会默认分配一个ConsumerGroup),消费者可以是代码,还可以是命令行工具,本质上就是一个进程/线程。
- ConsumerGroup :消费者组,由一个或多个Consumer组成(在同一个消费者组的消费者具有相同的
group.id),便于管理Consumer。 - Zookeeper :在Kafka集群中用来存储元数据,如:有Broker节点信息、分区的信息、分区与Broker的对应关系、生产者的负载均衡等等。
- Topic :主题,主题用于区分业务,比如订单主题业务,购物车主题业务,物流主题业务……方便对消息进行分类管理
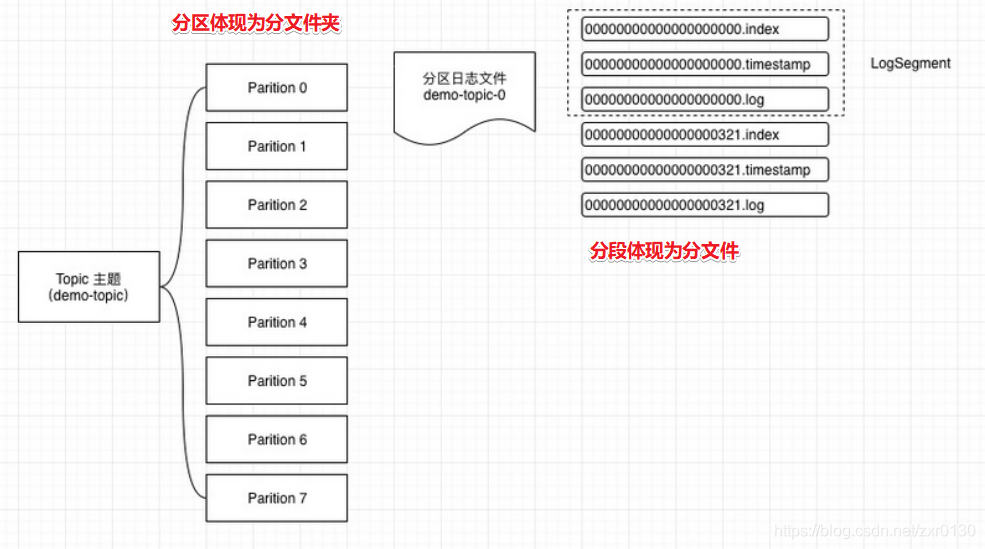
- Partition :分区,一个Topic的消息由一个或多个Partition存储。分区的作用是提高读写并行度/读写效率。
- Segment :分段,发送到kafka集群的消息会先存到内存中,然后划分文件夹、划分文件存入磁盘中
- Replication :副本,副本的作用是保证数据的安全性,副本分为Leader(主副本)和Follower(从副本),Leader只有一个,Follower可以有多个,但是副本数一般都为1-3个(副本数过多会占用大量的存储空间)。
注意:读写都只能从Leader进行,Follower在Leader宕机后自动选举出新的Leader。
扩展: 为什么读写都只能从Leader进行?
答:保证数据的一致性,只在Leader中进行写入数据,Follow同步Leader中的数据,在写过程中避免了多个副本中存储的数据不同的问题。Leader 和 Follow之间同步数据存在延时,所以读操作也需要在Leader中进行。
11. ISR : 表示目前Alive(活着的)且与Leader能够 “Catch-up”(跟得上)的Replicas(Follower)集合。
12. Record :记录,就是发送到Kafka集群的消息。一条消息就是一条记录。
13. offset : 偏移量,用于记录消息的序号,各个分区的偏移量都是从0开始。
备注: Kafka中有分区和分段的概念,分区就是分文件夹,分段就是分文件。这个思想在Hive中也有:Hive中的分区就是分文件夹,Hive中的分桶就是分文件。
跟RocketMQ的区别
1,元素据管理:
RocketMQ 有自己的管理节点 Nameserver, Kafka中是依赖zookeeper做元素据的管理。
2,消息存储
RocketMQ 所有Topic数据同时只会写一个文件。Kafka每个Top


)
- MTK mtk_drm_crtc.c(Part1))




)
:(七)双向链表)
重新找工作开始聊起)
八股小记)






读书笔记 25)
