PostgreSQL内核学习:通过 ExprState 提升哈希聚合与子计划执行效率(一)
- 引言
- 背景
- 补丁的意义
- 补丁概述
- JIT & LLVM
- 实际例子(以 PostgreSQL 为例)
- 提交信息
- 提交描述
- 引入 `ExprState` 进行哈希计算:
- 支持 `JIT` 编译:
- 改进哈希值扰动:
- 代码结构调整:
- 优化目的
- 源码解读
- 定义
- 新增函数 `ExecBuildHash32FromAttrs`
- 实例说明
- ExprState 结构体
- ExprEvalStep 结构体
- TupleHashTableHash_internal 函数
- 下层调用 ExecJustHashVarImpl 函数
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-18 beta2 的开源代码和《PostgresSQL数据库内核分析》一书
引言
背景
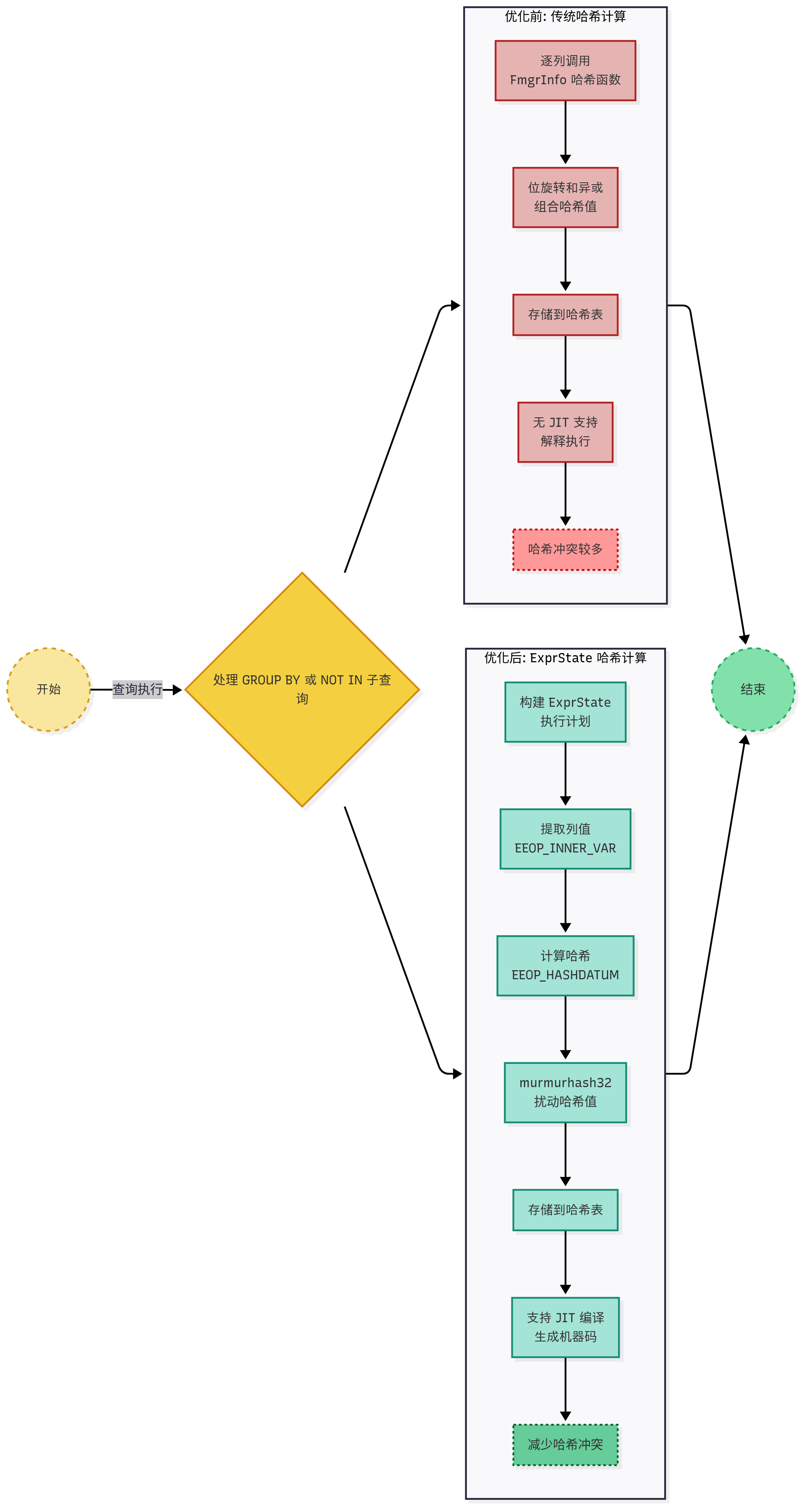
PostgreSQL 是一种功能强大的开源关系型数据库管理系统,广泛应用于企业级应用和数据分析场景。在 PostgreSQL 的查询执行引擎中,哈希操作是许多查询计划的核心组件,例如 GROUP BY 和 NOT IN 子查询中的哈希聚合(Hash Aggregate)和哈希表查找。这些操作依赖于高效的哈希计算和哈希表管理来实现快速的数据分组和查找。
然而,传统的哈希计算实现(如在 execGrouping.c 和 nodeSubplan.c 中)存在性能瓶颈,尤其是在处理大量数据或复杂查询时。哈希计算通常涉及逐列调用哈希函数(FmgrInfo),并通过位运算组合哈希值,这种方式会产生较多的函数调用和上下文切换开销。此外,传统的实现无法充分利用 PostgreSQL 的 JIT(即时编译)功能,限制了性能优化空间。
为了解决这些问题,PostgreSQL 社区引入了基于 ExprState(表达式状态)的哈希计算优化补丁。该补丁通过重构哈希计算逻辑,利用 ExprState 的表达式执行框架,减少函数调用开销,并支持 JIT 编译,从而显著提升哈希聚合和子查询的性能。此外,补丁改进了哈希值的扰动方式,减少哈希冲突,进一步优化哈希表操作。
补丁的意义
此补丁(提交标题为“Use ExprStates for hashing in GROUP BY and SubPlans”)是 PostgreSQL 性能优化的重要一步。它不仅提升了特定查询场景(如 GROUP BY 和 NOT IN 子查询)的执行效率,还为未来的 JIT 编译扩展奠定了基础。通过将哈希计算逻辑封装为 ExprState,补丁使得 PostgreSQL 的执行器能够更高效地处理复杂表达式,并为开发者提供了更灵活的优化空间。
补丁概述
JIT & LLVM
以下是针对JIT和LLVM定义的解释,帮助读者理解技术背景:
-
JIT编译(Just-In-Time Compilation):JIT编译是一种在程序运行时将代码(通常是中间表示或字节码)编译为本地机器码的技术,以提高执行效率。在PostgreSQL中,JIT编译基于LLVM(低级虚拟机)框架,用于优化查询执行计划中的表达式计算和哈希操作。- 传统的解释执行需要逐条解析和执行指令,而
JIT编译将这些指令提前转换为机器码,减少运行时开销,特别适用于高频重复执行的操作,如哈希计算。 - 参考:使用LLVM与JIT技术提升数据仓库性能的新探索、什么时候会用JIT?
-
LLVM (Low Level Virtual Machine)LLVM是一个 编译框架,提供了中间表示(IR)和优化、生成机器码的工具。- 数据库自己写一个
JIT编译器成本太高,所以直接拿LLVM做后端: - 数据库把
SQL表达式翻译成LLVM IR。 LLVM负责优化并生成机器码。- 数据库调用这些机器码函数,代替原来的解释器逻辑。
- 数据库自己写一个
实际例子(以 PostgreSQL 为例)
假设有个 SQL:
SELECT sum(salary * 1.2 + bonus)
FROM empsalary
WHERE deptno = 10;
没有 JIT 的情况
PostgreSQL执行salary * 1.2 + bonus时,会走解释器模式:
- 取出元组的
salary和bonus- 调用
ExecEvalFunc执行乘法函数- 再调用加法函数
- 逐行循环执行
- 整个过程函数调用层级很多
有 JIT + LLVM 的情况
PostgreSQL在执行计划时,发现表达式复杂度够高,就调用LLVMJIT。- 它会生成类似这样的
LLVM IR(简化过的):
define double @expr(double %salary, double %bonus) {
entry:%mul = fmul double %salary, 1.2%add = fadd double %mul, %bonusret double %add
}
LLVM把这段IR编译成机器码(比如x86的mulss,addss指令)。- 查询执行时,每行数据直接调用这个机器码函数计算 → 避开了解释层 → 性能提升。
如果表够大,你会看到执行计划里写着:
JIT:Functions: 3Options: Inlining true, Optimization true, Expressions true, Deforming true
提交信息
下面为本次优化的提交信息,hash值为:0f5738202b812a976e8612c85399b52d16a0abb6。对应的描述信息如下所示:
commit 0f5738202b812a976e8612c85399b52d16a0abb6
Author: David Rowley <drowley@postgresql.org>
Date: Wed Dec 11 13:47:16 2024 +1300Use ExprStates for hashing in GROUP BY and SubPlansThis speeds up obtaining hash values for GROUP BY and hashed SubPlans byusing the ExprState support for hashing, thus allowing JIT compilation forobtaining hash values for these operations.This, even without JIT compilation, has been shown to improve HashAggregate performance in some cases by around 15% and hashed NOT INqueries in one case by over 30%, however, real-world cases are likely tosee smaller gains as the test cases used were purposefully designed tohave high hashing overheads by keeping the hash table small to preventadditional memory overheads that would be a factor when working with largehash tables.In passing, fix a hypothetical bug in ExecBuildHash32Expr() so that theinitial value is stored directly in the ExprState's result field ifthere are no expressions to hash. None of the current users of thisfunction use an initial value, so the bug is only hypothetical.Reviewed-by: Andrei Lepikhov <lepihov@gmail.com>Discussion: https://postgr.es/m/CAApHDvpYSO3kc9UryMevWqthTBrxgfd9djiAjKHMPUSQeX9vdQ@mail.gmail.com
提交描述
该补丁通过以下方式优化了 PostgreSQL 的哈希计算性能:
引入 ExprState 进行哈希计算:
- 新增了
ExecBuildHash32FromAttrs函数,用于构建一个ExprState,以计算GROUP BY和哈希子查询(hashed SubPlans)中涉及的哈希值。 ExprState将哈希计算分解为一系列可优化的操作步骤(ExprEvalStep),例如提取列值(EEOP_INNER_VAR)、调用哈希函数(EEOP_HASHDATUM_FIRST或EEOP_HASHDATUM_NEXT32)和组合哈希值。- 传统的哈希计算方式直接调用
FmgrInfo的哈希函数,逐列计算并组合哈希值。新方法通过ExprState一次性执行所有列的哈希计算,减少了函数调用开销。
支持 JIT 编译:
ExprState的结构与PostgreSQL的JIT编译器(基于LLVM)兼容,允许将哈希计算逻辑编译为本地机器码,从而减少解释执行的开销。- 即使未启用
JIT编译,ExprState的优化仍然能带来性能提升,因为它通过更高效的内存管理和指令调度减少了函数调用的次数。
改进哈希值扰动:
- 传统方法通过位旋转(
pg_rotate_left32)和异或操作组合哈希值,可能导致哈希值分布不够均匀,增加冲突概率。 - 新方法在组合哈希值后,使用
murmurhash32进行额外的哈希扰动,生成更均匀的哈希值,从而减少哈希冲突,提高哈希表效率。
代码结构调整:
- 在
execGrouping.c中,TupleHashTableData结构中的tab_hash_funcs和in_hash_funcs被替换为tab_hash_expr和in_hash_expr,以使用ExprState表示哈希计算逻辑。 - 在
nodeSubplan.c中,SubPlanState结构中的lhs_hash_funcs被替换为lhs_hash_expr,支持子查询的哈希计算优化。 - 修改了
FindTupleHashEntry函数,支持跨类型比较,确保不同数据类型的哈希和比较操作正确执行。
优化目的
这个补丁通过优化 PostgreSQL 中 GROUP BY 和 NOT IN 子查询的哈希计算过程,显著提升了查询性能。传统方法在计算哈希值时,逐列调用哈希函数,导致大量函数调用和上下文切换开销,尤其在数据量大时效率低下。
补丁引入了 ExprState 机制,将哈希计算整合为一系列高效的执行步骤,减少了重复的函数调用,并支持即时编译(JIT),将计算逻辑转化为机器码以进一步加速处理。这种方式让哈希计算更加流畅,降低了性能瓶颈。
同时,补丁改进了哈希值的生成方式,通过 murmurhash32 算法对哈希值进行扰动,生成更均匀的分布,从而减少哈希表中的冲突。这提高了哈希表操作的效率,特别是在哈希表较小的场景下。此外,补丁修复了一个潜在问题,确保在没有需要哈希的表达式时,初始哈希值能正确存储,增强了代码的可靠性和扩展性。
例如,对于查询 SELECT region, SUM(amount) FROM sales GROUP BY region,优化前处理 1000 万行可能需要 100 秒,因为每行都需要多次调用哈希函数。优化后,ExprState 和 JIT 编译将计算过程简化为高效的机器码,时间可能缩短到 85 秒。对于 NOT IN 子查询,如 SELECT product_id FROM products WHERE product_id NOT IN (SELECT product_id FROM sales),性能提升可能更明显,时间从 100 秒减少到 70 秒。这些改进解决了哈希计算开销大、冲突频繁和缺乏 JIT 支持的问题,为复杂查询提供了更高效的执行方式,同时为未来优化奠定了基础。
优化前后的对比图如下所示:
源码解读
定义
ExprState(表达式状态):ExprState是PostgreSQL执行器中用于表示表达式执行计划的数据结构。它将复杂的SQL表达式分解为一系列操作步骤(ExprEvalStep),例如提取列值、调用函数或组合结果。ExprState支持高效的表达式计算,并与JIT编译器兼容,允许将表达式逻辑编译为机器码,从而减少解释执行的开销。
FmgrInfo(函数管理信息)FmgrInfo是PostgreSQL中用于存储函数调用信息的结构,包含函数的地址、参数数量和调用方式等信息。在传统的哈希计算中,FmgrInfo用于调用每个列的哈希函数(如hash_any用于字符串)。- 每次调用
FmgrInfo的函数都会产生一定的开销,尤其是在处理多列或大量数据时。
murmurhash32murmurhash32是一种高效的非加密哈希算法,用于生成均匀分布的32位哈希值。它在PostgreSQL中用于扰动(perturbation)哈希值,以减少哈希冲突。- 相比简单的位旋转和异或操作,
murmurhash32能生成更均匀的哈希值,从而提高哈希表的性能。
- 哈希聚合(
Hash Aggregate):- 哈希聚合是
PostgreSQL中处理GROUP BY查询的一种执行策略。它通过构建一个哈希表,将数据按照分组键(group key)存储,并在表中累积聚合结果(如SUM、COUNT)。 - 哈希聚合的性能依赖于哈希计算的效率和哈希表的冲突率。
- 哈希聚合是
- 哈希子查询(
Hashed SubPlan):- 哈希子查询是指在子查询(如
NOT IN或IN)中使用哈希表来加速查找的执行策略。PostgreSQL将子查询的结果存储在哈希表中,然后对主查询的每一行进行哈希查找以检查匹配。 - 哈希子查询的性能同样受哈希计算效率和哈希表冲突的影响。
- 哈希子查询是指在子查询(如
新增函数 ExecBuildHash32FromAttrs
ExecBuildHash32FromAttrs 是 PostgreSQL 中新增的一个函数,旨在优化 GROUP BY 和 NOT IN 子查询中的哈希计算过程。传统方法通过逐列调用哈希函数(FmgrInfo)计算哈希值,导致函数调用开销较大,尤其在处理多列或大量数据时效率低下。
该函数通过构建一个 ExprState(表达式状态)对象,将哈希计算逻辑封装为一系列可执行的操作步骤(ExprEvalStep),从而减少函数调用次数,并支持即时编译(JIT),将计算逻辑转化为高效的机器码。此外,函数支持初始哈希值(init_value)的设置,并通过统一的执行计划优化多列哈希值的组合过程。函数源码如下所示:
/* * 构建一个 ExprState,用于对指定的列(attnums,由 keyColIdx 提供)调用哈希函数。* 当 numCols > 1 时,将每个哈希函数返回的哈希值组合成一个单一的哈希值。** desc: 要哈希的列的元组描述符* ops: 用于元组描述符的 TupleTableSlotOps 操作* hashfunctions: 每个列的哈希函数(FmgrInfo),数量与 numCols 对应,需保持分配状态* collations: 调用哈希函数时使用的排序规则* numCols: hashfunctions、collations 和 keyColIdx 的数组长度* parent: 评估 ExprState 的 PlanState 节点* init_value: 初始哈希值,通常为 0,非零值会略微降低性能,仅在必要时使用*/
ExprState *
ExecBuildHash32FromAttrs(TupleDesc desc, const TupleTableSlotOps *ops,FmgrInfo *hashfunctions, Oid *collations,int numCols, AttrNumber *keyColIdx,PlanState *parent, uint32 init_value)
{// 创建一个新的 ExprState 节点,用于存储哈希计算的执行计划ExprState *state = makeNode(ExprState);// 初始化一个临时的 ExprEvalStep 结构,用于构建执行步骤ExprEvalStep scratch = {0};// 初始化中间结果存储,用于存储多列哈希计算的中间值NullableDatum *iresult = NULL;// 定义操作码,用于指定当前步骤的类型(如提取列值或调用哈希函数)intptr_t opcode;// 记录最大列编号,用于确定需要解构的元组范围AttrNumber last_attnum = 0;// 断言列数非负,确保输入参数有效Assert(numCols >= 0);// 设置 ExprState 的父节点为传入的 PlanState,用于上下文关联state->parent = parent;/** 如果有多于一个列需要哈希,或者有一个列且有非零初始值,* 分配内存用于存储中间哈希值,以便在多列计算时进行组合*/if ((int64) numCols + (init_value != 0) > 1)iresult = palloc(sizeof(NullableDatum));/* 遍历所有列,找到最大的列编号,以便解构元组到该位置 */for (int i = 0; i < numCols; i++)last_attnum = Max(last_attnum, keyColIdx[i]);// 设置操作码为提取部分列值(EEOP_INNER_FETCHSOME),准备从元组中提取数据scratch.opcode = EEOP_INNER_FETCHSOME;// 指定需要提取的最大列编号scratch.d.fetch.last_var = last_attnum;// 设置非固定格式,允许动态解构元组scratch.d.fetch.fixed = false;// 指定元组操作类型(如 TTSOpsMinimalTuple)scratch.d.fetch.kind = ops;// 设置元组描述符,用于定义列的结构scratch.d.fetch.known_desc = desc;// 计算元组槽信息并检查是否需要添加提取步骤if (ExecComputeSlotInfo(state, &scratch))// 将提取步骤添加到 ExprState 的执行计划中ExprEvalPushStep(state, &scratch);// 如果初始哈希值为 0if (init_value == 0){/** 没有初始值,直接使用第一个列的哈希函数结果,无需与初始值组合* 设置操作码为 EEOP_HASHDATUM_FIRST,表示首次哈希计算*/opcode = EEOP_HASHDATUM_FIRST;}else{/** 设置初始哈希值的操作,存储到中间结果或 ExprState 的结果字段* 如果有列要哈希,存储到中间结果;否则直接存储到 ExprState*/scratch.opcode = EEOP_HASHDATUM_SET_INITVAL;// 将初始值转换为 Datum 类型scratch.d.hashdatum_initvalue.init_value = UInt32GetDatum(init_value);// 根据是否有列,选择存储位置(中间结果或最终结果)scratch.resvalue = numCols > 0 ? &iresult->value : &state->resvalue;scratch.resnull = numCols > 0 ? &iresult->isnull : &state->resnull;// 将初始值设置步骤添加到执行计划ExprEvalPushStep(state, &scratch);/** 使用初始值时,后续哈希计算使用 EEOP_HASHDATUM_NEXT32,* 以避免覆盖初始值(EEOP_HASHDATUM_FIRST 会覆盖)*/opcode = EEOP_HASHDATUM_NEXT32;}// 遍历每一列,构建哈希计算的执行步骤for (int i = 0; i < numCols; i++){// 获取当前列的哈希函数信息FmgrInfo *finfo;// 初始化函数调用信息结构FunctionCallInfo fcinfo;// 获取当前列的排序规则Oid inputcollid = collations[i];// 列编号从 1 开始,转换为 0 基索引AttrNumber attnum = keyColIdx[i] - 1;// 获取当前列的哈希函数finfo = &hashfunctions[i];// 分配并初始化函数调用信息结构,参数数量为 1fcinfo = palloc0(SizeForFunctionCallInfo(1));// 初始化函数调用信息,设置函数、参数数量和排序规则InitFunctionCallInfoData(*fcinfo, finfo, 1, inputcollid, NULL, NULL);/** 设置提取列值的步骤(EEOP_INNER_VAR),将指定列的值存储到哈希函数的第一个参数*/scratch.opcode = EEOP_INNER_VAR;// 设置存储目标为哈希函数的第一个参数scratch.resvalue = &fcinfo->args[0].value;scratch.resnull = &fcinfo->args[0].isnull;// 设置要提取的列编号scratch.d.var.attnum = attnum;// 设置列的数据类型scratch.d.var.vartype = TupleDescAttr(desc, attnum)->atttypid;// 将提取列值的步骤添加到执行计划ExprEvalPushStep(state, &scratch);// 设置调用哈希函数的步骤,使用之前确定的操作码scratch.opcode = opcode;// 如果是最后一列if (i == numCols - 1){/** 最后一列的哈希结果直接存储到 ExprState 的结果字段*/scratch.resvalue = &state->resvalue;scratch.resnull = &state->resnull;}else{// 确保中间结果已分配Assert(iresult != NULL);// 中间列的哈希结果存储到中间结果中scratch.resvalue = &iresult->value;scratch.resnull = &iresult->isnull;}/** 为 NEXT32 操作码设置中间结果,FIRST 操作码不会使用* 为安全起见,始终设置中间结果指针*/scratch.d.hashdatum.iresult = iresult;// 设置哈希函数信息scratch.d.hashdatum.finfo = finfo;// 设置函数调用信息scratch.d.hashdatum.fcinfo_data = fcinfo;// 设置函数地址scratch.d.hashdatum.fn_addr = finfo->fn_addr;// 设置跳转标志,初始为 -1scratch.d.hashdatum.jumpdone = -1;// 将哈希函数调用步骤添加到执行计划ExprEvalPushStep(state, &scratch);// 后续列使用 EEOP_HASHDATUM_NEXT32,以组合前面的哈希值opcode = EEOP_HASHDATUM_NEXT32;}// 设置终止步骤,清除结果指针scratch.resvalue = NULL;scratch.resnull = NULL;// 设置操作码为 EEOP_DONE,表示执行计划结束scratch.opcode = EEOP_DONE;// 将终止步骤添加到执行计划ExprEvalPushStep(state, &scratch);// 准备 ExprState,使其可执行ExecReadyExpr(state);// 返回构建完成的 ExprStatereturn state;
}

实例说明
假设有一个查询 SELECT region, SUM(amount) FROM sales GROUP BY region,其中 sales 表包含 region(字符串类型)和 amount(数值类型)两列。我们需要对 region 列进行哈希计算以构建哈希表。以下通过示例说明每行代码的作用:
示例场景
输入参数:
desc:sales表的元组描述符,包含region(列1,类型VARCHAR)和amount(列2,类型NUMERIC)。ops:TTSOpsMinimalTuple,用于操作最小元组。hashfunctions:包含一个哈希函数(如hash_any用于字符串)。collations:字符串的排序规则(如C排序)。numCols:1(仅对region列哈希)。keyColIdx:[1](表示哈希region列)。parent:HashAggregate节点的状态。init_value:0(无初始哈希值)。
每行代码的作用
- 创建
ExprState:
ExprState *state = makeNode(ExprState);
- 作用:创建一个新的
ExprState节点,用于存储哈希计算的执行计划。 - 示例:为
region列的哈希计算创建一个空的ExprState,后续将填充执行步骤。
- 初始化临时步骤和变量:
ExprEvalStep scratch = {0};
NullableDatum *iresult = NULL;
intptr_t opcode;
AttrNumber last_attnum = 0;
- 作用:初始化
scratch用于构建执行步骤,iresult用于存储中间哈希值,opcode指定步骤类型,last_attnum记录最大列编号。 - 示例:
scratch初始化为空,iresult初始为NULL(因为只有一列,暂不需要),opcode和last_attnum待后续赋值。
- 设置父节点:
state->parent = parent;
- 作用:将
ExprState的父节点设置为传入的PlanState,关联查询计划上下文。 - 示例:将
state关联到HashAggregate节点,确保执行时使用正确的上下文。
- 分配中间结果存储:
if ((int64) numCols + (init_value != 0) > 1)iresult = palloc(sizeof(NullableDatum));
- 作用:如果有多列或有初始值,分配内存存储中间哈希值。
- 示例:因为
numCols = 1且init_value = 0,无需分配iresult,保持为NULL。
- 确定最大列编号:
for (int i = 0; i < numCols; i++)last_attnum = Max(last_attnum, keyColIdx[i]);
- 作用:遍历
keyColIdx,找到最大列编号,用于解构元组。 - 示例:
keyColIdx = [1],last_attnum设置为1,表示只需解构到region列。
- 设置提取列值的步骤:
// 设置操作码为提取部分列值(EEOP_INNER_FETCHSOME),准备从元组中提取数据
scratch.opcode = EEOP_INNER_FETCHSOME;
// 指定需要提取的最大列编号
scratch.d.fetch.last_var = last_attnum;
// 设置非固定格式,允许动态解构元组
scratch.d.fetch.fixed = false;
// 指定元组操作类型(如 TTSOpsMinimalTuple)
scratch.d.fetch.kind = ops;
// 设置元组描述符,用于定义列的结构
scratch.d.fetch.known_desc = desc;
// 计算元组槽信息并检查是否需要添加提取步骤
if (ExecComputeSlotInfo(state, &scratch))// 将提取步骤添加到 ExprState 的执行计划中ExprEvalPushStep(state, &scratch);
- 作用:构建提取列值的步骤(
EEOP_INNER_FETCHSOME),指定最大列编号、元组操作类型和描述符,并添加到执行计划。 - 示例:生成一个步骤,解构元组到列
1(region),使用TTSOpsMinimalTuple操作,确保能提取region的值。
- 检查初始值并设置操作码:
if (init_value == 0)
{opcode = EEOP_HASHDATUM_FIRST;
}
else
{...
}
- 作用:如果初始值为
0,设置操作码为EEOP_HASHDATUM_FIRST,直接使用第一个列的哈希值;否则设置初始值步骤(本例不触发)。 - 示例:
init_value = 0,设置opcode = EEOP_HASHDATUM_FIRST,表示直接计算region的哈希值。
- 遍历列,构建哈希计算步骤:
for (int i = 0; i < numCols; i++)
{FmgrInfo *finfo;FunctionCallInfo fcinfo;Oid inputcollid = collations[i];AttrNumber attnum = keyColIdx[i] - 1;finfo = &hashfunctions[i];fcinfo = palloc0(SizeForFunctionCallInfo(1));InitFunctionCallInfoData(*fcinfo, finfo, 1, inputcollid, NULL, NULL);
- 作用:为每一列初始化哈希函数和函数调用信息,设置排序规则和列编号。
- 示例:为
region列(keyColIdx[0] = 1)获取哈希函数hash_any,初始化函数调用信息,设置排序规则为C。
- 提取列值步骤:
scratch.opcode = EEOP_INNER_VAR;
scratch.resvalue = &fcinfo->args[0].value;
scratch.resnull = &fcinfo->args[0].isnull;
scratch.d.var.attnum = attnum;
scratch.d.var.vartype = TupleDescAttr(desc, attnum)->atttypid;
ExprEvalPushStep(state, &scratch);
- 作用:生成提取列值的步骤(
EEOP_INNER_VAR),将值存储到哈希函数的第一个参数。 - 示例:生成步骤提取
region列(attnum = 0)的值,存储到fcinfo->args[0],类型为VARCHAR。
- 提取列值步骤:
scratch.opcode = opcode;
if (i == numCols - 1)
{scratch.resvalue = &state->resvalue;scratch.resnull = &state->resnull;
}
else
{Assert(iresult != NULL);scratch.resvalue = &iresult->value;scratch.resnull = &iresult->isnull;
}
scratch.d.hashdatum.iresult = iresult;
scratch.d.hashdatum.finfo = finfo;
scratch.d.hashdatum.fcinfo_data = fcinfo;
scratch.d.hashdatum.fn_addr = finfo->fn_addr;
scratch.d.hashdatum.jumpdone = -1;
ExprEvalPushStep(state, &scratch);
opcode = EEOP_HASHDATUM_NEXT32;
- 作用:生成调用哈希函数的步骤(
EEOP_HASHDATUM_FIRST或EEOP_HASHDATUM_NEXT32),存储结果到ExprState(最后一列)或中间结果(非最后一列),设置函数信息并添加到执行计划。 - 示例:为
region列生成步骤,使用EEOP_HASHDATUM_FIRST,调用hash_any,结果存储到state->resvalue(因为是最后一列),设置函数信息并添加步骤。
- 添加终止步骤:
scratch.resvalue = NULL;
scratch.resnull = NULL;
scratch.opcode = EEOP_DONE;
ExprEvalPushStep(state, &scratch);
- 作用:添加终止步骤(
EEOP_DONE),表示执行计划结束。 - 示例:生成一个终止步骤,确保
ExprState执行到此结束。
- 准备并返回 ExprState:
ExecReadyExpr(state);
return state;
- 作用:准备
ExprState使其可执行,并返回给调用者。 - 示例:完成
ExprState的初始化,返回包含提取region值和调用hash_any的执行计划。
执行计划示例
生成的
ExprState包含以下步骤:
EEOP_INNER_FETCHSOME:解构元组,提取region列。EEOP_INNER_VAR:提取region值,存储到哈希函数参数。EEOP_HASHDATUM_FIRST:调用hash_any,生成哈希值,存储到state->resvalue。EEOP_DONE:结束执行。
当执行 SELECT region, SUM(amount) FROM sales GROUP BY region 时,ExprState 会被 ExecEvalExpr 调用,快速计算 region 的哈希值,用于哈希表操作。如果启用 JIT,LLVM 会将这些步骤编译为机器码,减少执行时间。
ExprState 结构体
ExprEvalStep 是 PostgreSQL 执行器中用于定义 ExprState 执行计划中单个步骤的数据结构。每个步骤通过 opcode 指定操作类型(如提取列值、调用函数、处理条件等),并通过 resvalue 和 resnull 存储结果。d 联合体根据操作类型存储特定的上下文数据(如哈希函数信息、跳转目标等),支持多种表达式操作,包括哈希计算、类型转换、聚合函数等。
在补丁中,ExecBuildHash32FromAttrs 使用 ExprEvalStep 定义了提取列值(EEOP_INNER_VAR)、设置初始哈希值(EEOP_HASHDATUM_SET_INITVAL)和调用哈希函数(EEOP_HASHDATUM_FIRST 或 EEOP_HASHDATUM_NEXT32)的步骤。这些步骤支持高效执行,并可通过 JIT 编译优化为机器码,提升性能。
typedef struct ExprState
{// 节点类型,标识这是 ExprState 节点NodeTag type;// 标志位,存储 EEO_FLAG_* 位掩码,用于控制表达式执行行为uint8 flags; /* bitmask of EEO_FLAG_* bits, see above *//** 用于存储标量表达式的结果值,或由 ExecBuildProjectionInfo() 构建的表达式中各列的结果*/
#define FIELDNO_EXPRSTATE_RESNULL 2// 结果是否为 NULLbool resnull;
#define FIELDNO_EXPRSTATE_RESVALUE 3// 结果值,存储为 Datum 类型Datum resvalue;/** 如果表达式生成元组结果,则存储结果的 TupleTableSlot;否则为 NULL*/
#define FIELDNO_EXPRSTATE_RESULTSLOT 4TupleTableSlot *resultslot;/** 计算表达式返回值的指令序列,存储一系列 ExprEvalStep*/struct ExprEvalStep *steps;/** 实际执行表达式的函数指针,根据表达式复杂度设置为不同函数*/ExprStateEvalFunc evalfunc;// 原始表达式树,仅用于调试Expr *expr;// 执行函数的私有状态数据void *evalfunc_private;/** 以下字段仅在编译期间(ExecInitExpr)需要,之后可丢弃*/// 当前步骤数量int steps_len; /* number of steps currently */// 步骤数组的分配长度int steps_alloc; /* allocated length of steps array */#define FIELDNO_EXPRSTATE_PARENT 11// 父 PlanState 节点,若存在则关联查询计划上下文struct PlanState *parent; /* parent PlanState node, if any */// 外部参数信息,用于编译 PARAM_EXTERN 节点ParamListInfo ext_params; /* for compiling PARAM_EXTERN nodes */// 最内层 CASE 表达式的值Datum *innermost_caseval;// 最内层 CASE 表达式是否为 NULLbool *innermost_casenull;// 最内层域约束的值Datum *innermost_domainval;// 最内层域约束是否为 NULLbool *innermost_domainnull;/** 用于支持软错误处理的上下文。如果调用者希望抛出错误,设为 NULL;* 若不希望抛出错误,调用者在调用 ExecInitExprRec() 前设置有效的 ErrorSaveContext*/ErrorSaveContext *escontext;
} ExprState;
ExprEvalStep 结构体
以下是 PostgreSQL 中 ExprEvalStep 结构体的每一行代码添加中文注释,解释每个字段的作用。ExprEvalStep 是 ExprState 中用于定义表达式执行计划中单个步骤的数据结构,描述了执行操作的类型、输入输出以及相关上下文信息。在补丁(如 ExecBuildHash32FromAttrs)中,它用于构建哈希计算的步骤,支持高效执行和 JIT 编译。
typedef struct ExprEvalStep
{/** 要执行的指令。在准备阶段为 ExprEvalOp 枚举值,* 之后可能改为其他类型(如计算跳转的指针),因此使用 intptr_t*/intptr_t opcode;// 存储当前步骤结果的指针Datum *resvalue;// 存储当前步骤结果是否为 NULL 的指针bool *resnull;/** 操作的内联数据,访问速度快但会增加指令大小。* 联合体大小控制在 64 位系统上不超过 40 字节,确保整个结构不超过 64 字节(单缓存行)*/union{// 用于 EEOP_INNER/OUTER/SCAN_FETCHSOME,提取元组列值struct{// 要提取的最高列编号(包含)int last_var;// 每次调用时槽类型是否固定bool fixed;// 已知的元组描述符TupleDesc known_desc;// 槽类型,仅当 fixed 为 true 时可信const TupleTableSlotOps *kind;} fetch;// 用于 EEOP_INNER/OUTER/SCAN_[SYS]VAR[_FIRST],提取单个列值struct{// 列编号(普通变量为 attr 编号 - 1,系统变量为负值)int attnum;// 变量的数据类型 OIDOid vartype; /* type OID of variable */} var;// 用于 EEOP_WHOLEROW,处理整行引用struct{// 原始 Var 节点Var *var; /* original Var node in plan tree */// 是否首次执行,需要初始化bool first; /* first time through, need to initialize? */// 是否需要运行时检查 NULL 值bool slow; /* need runtime check for nulls? */// 结果元组的描述符TupleDesc tupdesc; /* descriptor for resulting tuples */// 移除无关列的过滤器JunkFilter *junkFilter; /* JunkFilter to remove resjunk cols */} wholerow;// 用于 EEOP_ASSIGN_*_VAR,赋值列值到结果槽struct{// 目标在结果槽中的索引int resultnum;// 源列编号 - 1int attnum;} assign_var;// 用于 EEOP_ASSIGN_TMP[_MAKE_RO],赋值临时值struct{// 目标在结果槽中的索引int resultnum;} assign_tmp;// 用于 EEOP_CONST,处理常量值struct{// 常量的值Datum value;// 常量是否为 NULLbool isnull;} constval;// 用于 EEOP_FUNCEXPR_* / NULLIF / DISTINCT,调用函数struct{// 函数查找信息FmgrInfo *finfo; /* function's lookup data */// 函数调用参数等信息FunctionCallInfo fcinfo_data; /* arguments etc */// 直接访问的函数调用地址,减少间接调用开销PGFunction fn_addr; /* actual call address */// 参数数量int nargs; /* number of arguments */// 是否将第一个参数设为只读(仅用于 NULLIF)bool make_ro; /* make arg0 R/O (used only for NULLIF) */} func;// 用于 EEOP_BOOL_*_STEP,布尔表达式处理struct{// 跟踪是否有输入为 NULLbool *anynull; /* track if any input was NULL */// 结果确定时跳转的目标int jumpdone; /* jump here if result determined */} boolexpr;// 用于 EEOP_QUAL,条件判断struct{// 条件为假或 NULL 时跳转的目标int jumpdone; /* jump here on false or null */} qualexpr;// 用于 EEOP_JUMP[_CONDITION],无条件或条件跳转struct{// 跳转目标指令的索引int jumpdone; /* target instruction's index */} jump;// 用于 EEOP_NULLTEST_ROWIS[NOT]NULL,检查整行是否为 NULLstruct{// 复合类型的缓存描述符,运行时填充ExprEvalRowtypeCache rowcache;} nulltest_row;// 用于 EEOP_PARAM_EXEC/EXTERN 和 EEOP_PARAM_SET,处理参数struct{// 参数的数字 IDint paramid; /* numeric ID for parameter */// 参数的数据类型 OIDOid paramtype; /* OID of parameter's datatype */} param;// 用于 EEOP_PARAM_CALLBACK,参数回调处理struct{// 附加的评估子程序ExecEvalSubroutine paramfunc; /* add-on evaluation subroutine */// 子程序的私有数据void *paramarg; /* private data for same */// 参数的数字 IDint paramid; /* numeric ID for parameter */// 参数的数据类型 OIDOid paramtype; /* OID of parameter's datatype */} cparam;// 用于 EEOP_CASE_TESTVAL/DOMAIN_TESTVAL,CASE 或域测试值struct{// 要返回的值Datum *value; /* value to return */// 值是否为 NULLbool *isnull;} casetest;// 用于 EEOP_MAKE_READONLY,将值设为只读struct{// 要强制设为只读的值Datum *value; /* value to coerce to read-only */// 值是否为 NULLbool *isnull;} make_readonly;// 用于 EEOP_IOCOERCE,输入/输出类型转换struct{// 源类型的输出函数查找和调用信息FmgrInfo *finfo_out;FunctionCallInfo fcinfo_data_out;// 目标类型的输入函数查找和调用信息FmgrInfo *finfo_in;FunctionCallInfo fcinfo_data_in;} iocoerce;// 用于 EEOP_SQLVALUEFUNCTION,SQL 值函数struct{// SQL 值函数的原始节点SQLValueFunction *svf;} sqlvaluefunction;// 用于 EEOP_NEXTVALUEEXPR,序列的下一个值struct{// 序列的 OIDOid seqid;// 序列的数据类型 OIDOid seqtypid;} nextvalueexpr;// 用于 EEOP_ARRAYEXPR,数组表达式struct{// 元素值的存储数组Datum *elemvalues; /* element values get stored here */// 元素是否为 NULL 的标志数组bool *elemnulls;// 元素数量int nelems; /* length of the above arrays */// 数组元素类型Oid elemtype; /* array element type */// 元素类型的存储长度int16 elemlength; /* typlen of the array element type */// 元素类型是否按值传递bool elembyval; /* is the element type pass-by-value? */// 元素类型的对齐方式char elemalign; /* typalign of the element type */// 是否为多维数组bool multidims; /* is array expression multi-D? */} arrayexpr;// 用于 EEOP_ARRAYCOERCE,数组类型转换struct{// 每个元素的表达式状态,空则无需元素处理ExprState *elemexprstate; /* null if no per-element work */// 结果数组的元素类型Oid resultelemtype; /* element type of result array */// 数组映射的工作空间struct ArrayMapState *amstate; /* workspace for array_map */} arraycoerce;// 用于 EEOP_ROW,构造行struct{// 结果元组的描述符TupleDesc tupdesc; /* descriptor for result tuples */// 构成行的值的工作空间Datum *elemvalues;// 构成行的值的 NULL 标志bool *elemnulls;} row;// 用于 EEOP_ROWCOMPARE_STEP,行比较步骤struct{// 列比较函数的查找和调用数据FmgrInfo *finfo;FunctionCallInfo fcinfo_data;// 比较函数的调用地址PGFunction fn_addr;// 比较结果为 NULL 时的跳转目标int jumpnull;// 比较结果不等时的跳转目标int jumpdone;} rowcompare_step;// 用于 EEOP_ROWCOMPARE_FINAL,行比较最终结果struct{// 行比较类型(如等于、大于)RowCompareType rctype;} rowcompare_final;// 用于 EEOP_MINMAX,计算最小/最大值struct{// 参数值的工作空间Datum *values;// 参数是否为 NULL 的标志bool *nulls;// 参数数量int nelems;// 操作类型(GREATEST 或 LEAST)MinMaxOp op;// 比较函数的查找和调用数据FmgrInfo *finfo;FunctionCallInfo fcinfo_data;} minmax;// 用于 EEOP_FIELDSELECT,字段选择struct{// 要提取的字段编号AttrNumber fieldnum; /* field number to extract */// 字段的类型Oid resulttype; /* field's type */// 复合类型的缓存描述符,运行时填充ExprEvalRowtypeCache rowcache;} fieldselect;// 用于 EEOP_FIELDSTORE_DEFORM / FIELDSTORE_FORM,字段存储struct{// 原始 FieldStore 表达式节点FieldStore *fstore;// 复合类型的缓存描述符,运行时填充(DEFORM 和 FORM 共享)ExprEvalRowtypeCache *rowcache;// 列值的工作空间Datum *values;// 列值的 NULL 标志bool *nulls;// 列数量int ncolumns;} fieldstore;// 用于 EEOP_SBSREF_SUBSCRIPTS,下标引用struct{// 下标评估子程序ExecEvalBoolSubroutine subscriptfunc; /* evaluation subroutine */// 下标状态数据(过大,无法内联)struct SubscriptingRefState *state;// NULL 值时的跳转目标int jumpdone; /* jump here on null */} sbsref_subscript;// 用于 EEOP_SBSREF_OLD / ASSIGN / FETCH,下标引用操作struct{// 下标评估子程序ExecEvalSubroutine subscriptfunc; /* evaluation subroutine */// 下标状态数据(过大,无法内联)struct SubscriptingRefState *state;} sbsref;// 用于 EEOP_DOMAIN_NOTNULL / DOMAIN_CHECK,域约束检查struct{// 约束名称char *constraintname;// CHECK 约束结果的存储位置Datum *checkvalue;// CHECK 约束结果是否为 NULLbool *checknull;// 域类型的 OIDOid resulttype;// 错误处理上下文ErrorSaveContext *escontext;} domaincheck;// 用于 EEOP_HASH_SET_INITVAL,设置初始哈希值struct{// 初始哈希值Datum init_value;} hashdatum_initvalue;// 用于 EEOP_HASHDATUM_(FIRST|NEXT32)[_STRICT],哈希计算struct{// 哈希函数查找信息FmgrInfo *finfo; /* function's lookup data */// 哈希函数调用参数等信息FunctionCallInfo fcinfo_data; /* arguments etc */// 直接访问的哈希函数调用地址,减少间接调用开销PGFunction fn_addr; /* actual call address */// NULL 值时的跳转目标int jumpdone; /* jump here on null */// 中间哈希结果的存储位置NullableDatum *iresult; /* intermediate hash result */} hashdatum;// 用于 EEOP_CONVERT_ROWTYPE,行类型转换struct{// 输入复合类型Oid inputtype; /* input composite type */// 输出复合类型Oid outputtype; /* output composite type */// 输入类型的缓存,运行时填充ExprEvalRowtypeCache *incache; /* cache for input type */// 输出类型的缓存,运行时填充ExprEvalRowtypeCache *outcache; /* cache for output type */// 列映射TupleConversionMap *map; /* column mapping */} convert_rowtype;// 用于 EEOP_SCALARARRAYOP,标量数组操作struct{// 元素类型,运行时填充Oid element_type; /* InvalidOid if not yet filled */// 使用 OR 或 AND 语义bool useOr; /* use OR or AND semantics? */// 数组元素类型的存储长度int16 typlen; /* array element type storage info */// 元素类型是否按值传递bool typbyval;// 元素类型的对齐方式char typalign;// 函数查找信息FmgrInfo *finfo; /* function's lookup data */// 函数调用参数等信息FunctionCallInfo fcinfo_data; /* arguments etc */// 直接访问的函数调用地址,减少间接调用开销PGFunction fn_addr; /* actual call address */} scalararrayop;// 用于 EEOP_HASHED_SCALARARRAYOP,哈希标量数组操作struct{// 是否包含 NULL 值bool has_nulls;// IN 或 NOT IN 操作bool inclause; /* true for IN and false for NOT IN */// 元素哈希表struct ScalarArrayOpExprHashTable *elements_tab;// 函数查找信息FmgrInfo *finfo; /* function's lookup data */// 函数调用参数等信息FunctionCallInfo fcinfo_data; /* arguments etc */// 标量数组操作的原始节点ScalarArrayOpExpr *saop;} hashedscalararrayop;// 用于 EEOP_XMLEXPR,XML 表达式struct{// 原始 XML 表达式节点XmlExpr *xexpr; /* original expression node */// 命名参数的工作空间Datum *named_argvalue;// 命名参数的 NULL 标志bool *named_argnull;// 未命名参数的工作空间Datum *argvalue;// 未命名参数的 NULL 标志bool *argnull;} xmlexpr;// 用于 EEOP_JSON_CONSTRUCTOR,JSON 构造函数struct{// JSON 构造函数状态struct JsonConstructorExprState *jcstate;} json_constructor;// 用于 EEOP_AGGREF,聚合函数引用struct{// 聚合函数编号int aggno;} aggref;// 用于 EEOP_GROUPING_FUNC,分组函数struct{// 列编号的整数列表List *clauses; /* integer list of column numbers */} grouping_func;// 用于 EEOP_WINDOW_FUNC,窗口函数struct{// 窗口函数状态,由 nodeWindowAgg.c 修改WindowFuncExprState *wfstate;} window_func;// 用于 EEOP_SUBPLAN,子查询struct{// 子查询状态,由 nodeSubplan.c 创建SubPlanState *sstate;} subplan;// 用于 EEOP_AGG_*DESERIALIZE,聚合反序列化struct{// 函数调用信息FunctionCallInfo fcinfo_data;// NULL 值时的跳转目标int jumpnull;} agg_deserialize;// 用于 EEOP_AGG_STRICT_INPUT_CHECK_NULLS / STRICT_INPUT_CHECK_ARGS,严格输入检查struct{/** EEOP_AGG_STRICT_INPUT_CHECK_ARGS:args 指向需要检查 NULL 的 NullableDatum* EEOP_AGG_STRICT_INPUT_CHECK_NULLS:nulls 指向需要检查 NULL 的布尔值* 两种情况分别处理 TupleTableSlot 和 FunctionCallInfo 的 NULL 检查*/NullableDatum *args;bool *nulls;// 参数数量int nargs;// NULL 值时的跳转目标int jumpnull;} agg_strict_input_check;// 用于 EEOP_AGG_PLAIN_PERGROUP_NULLCHECK,聚合分组 NULL 检查struct{// 分组集的偏移量int setoff;// NULL 值时的跳转目标int jumpnull;} agg_plain_pergroup_nullcheck;// 用于 EEOP_AGG_PRESORTED_DISTINCT_{SINGLE,MULTI},预排序去重检查struct{// 聚合转换状态AggStatePerTrans pertrans;// 聚合上下文ExprContext *aggcontext;// 去重失败时的跳转目标int jumpdistinct;} agg_presorted_distinctcheck;// 用于 EEOP_AGG_PLAIN_TRANS_[INIT_][STRICT_]{BYVAL,BYREF} 和 EEOP_AGG_ORDERED_TRANS_{DATUM,TUPLE},聚合转换struct{// 聚合转换状态AggStatePerTrans pertrans;// 聚合上下文ExprContext *aggcontext;// 集合编号int setno;// 转换编号int transno;// 集合偏移量int setoff;} agg_trans;// 用于 EEOP_IS_JSON,JSON 类型检查struct{// 原始 JSON 谓词节点JsonIsPredicate *pred; /* original expression node */} is_json;// 用于 EEOP_JSONEXPR_PATH,JSON 路径表达式struct{// JSON 表达式状态struct JsonExprState *jsestate;} jsonexpr;// 用于 EEOP_JSONEXPR_COERCION,JSON 表达式类型转换struct{// 目标类型Oid targettype;// 目标类型的模式int32 targettypmod;// 是否省略引号bool omit_quotes;// 仅用于 JSON_EXISTS_OP 的字段bool exists_coerce;bool exists_cast_to_int;bool exists_check_domain;// JSON 类型转换缓存void *json_coercion_cache;// 错误处理上下文ErrorSaveContext *escontext;} jsonexpr_coercion;} d;
} ExprEvalStep;
需要注意的是,并非每个参数或子结构都会在每次使用 ExprEvalStep 时被用到。联合体的设计使得在任一时刻,只有与当前 opcode 对应的子结构会被使用,其余子结构的内容未定义且不会被访问。
例如,在补丁中的 ExecBuildHash32FromAttrs 函数,生成的步骤可能包括:
EEOP_INNER_FETCHSOME:使用fetch子结构提取元组列值。EEOP_INNER_VAR:使用var子结构提取单个列值。EEOP_HASHDATUM_FIRST或EEOP_HASHDATUM_NEXT32:使用hashdatum子结构调用哈希函数。
其他子结构(如 wholerow、arrayexpr)在哈希计算场景中不会被使用。
TupleHashTableHash_internal 函数
该函数用于为哈希表中的元组计算 32 位哈希值,支持 GROUP BY 和 NOT IN 子查询的哈希计算,结合 ExprState 优化性能并使用 murmurhash32 扰动哈希值以减少冲突。它支持两种场景:
- 输入元组(
tuple == NULL):从输入槽(inputslot)中提取数据,调用in_hash_expr(ExprState)计算哈希值,适用于新插入哈希表的元组。 - 已存储元组(
tuple != NULL):从表槽(tableslot)中提取数据,调用tab_hash_expr计算哈希值(注释指出此情况实际不发生,因哈希值已存储)。 最终,通过murmurhash32扰动哈希值,优化分布,减少哈希冲突。该函数与补丁中的ExecBuildHash32FromAttrs配合,构建高效的哈希计算计划,支持JIT编译。
/** 如果 tuple 为 NULL,则使用输入槽(input slot)代替。这种约定避免了* 在不需要复制到哈希表时物化虚拟输入元组。** 调用者必须为运行哈希函数选择适当的内存上下文。*/
static uint32
TupleHashTableHash_internal(struct tuplehash_hash *tb,const MinimalTuple tuple)
{// 将 tb 的私有数据转换为 TupleHashTable 结构,存储哈希表元数据TupleHashTable hashtable = (TupleHashTable) tb->private_data;// 定义变量存储计算的哈希值uint32 hashkey;// 定义变量存储元组槽,用于提取列值TupleTableSlot *slot;// 定义变量跟踪哈希计算结果是否为 NULLbool isnull;// 判断输入元组是否为 NULLif (tuple == NULL){/* 处理哈希表的当前输入元组 */// 将输入槽设置为表达式上下文的内层元组槽hashtable->exprcontext->ecxt_innertuple = hashtable->inputslot;// 使用输入哈希表达式(in_hash_expr)计算哈希值,结果转换为 uint32hashkey = DatumGetUInt32(ExecEvalExpr(hashtable->in_hash_expr,hashtable->exprcontext,&isnull));}else{/** 处理已存储在哈希表中的元组。* (由于 simplehash.h 的使用方式,哈希值存储在条目中,此情况实际不发生)*/// 将表槽设置为表达式上下文的内层元组槽slot = hashtable->exprcontext->ecxt_innertuple = hashtable->tableslot;// 将元组存储到表槽中,不复制(shouldFree = false)ExecStoreMinimalTuple(tuple, slot, false);// 使用表哈希表达式(tab_hash_expr)计算哈希值,结果转换为 uint32hashkey = DatumGetUInt32(ExecEvalExpr(hashtable->tab_hash_expr,hashtable->exprcontext,&isnull));}/** 上述哈希计算,即使使用初始值,也难以生成良好的哈希扰动。* 通过 murmurhash32 对哈希值进行扰动,可获得接近完美的哈希分布。*/return murmurhash32(hashkey);
}
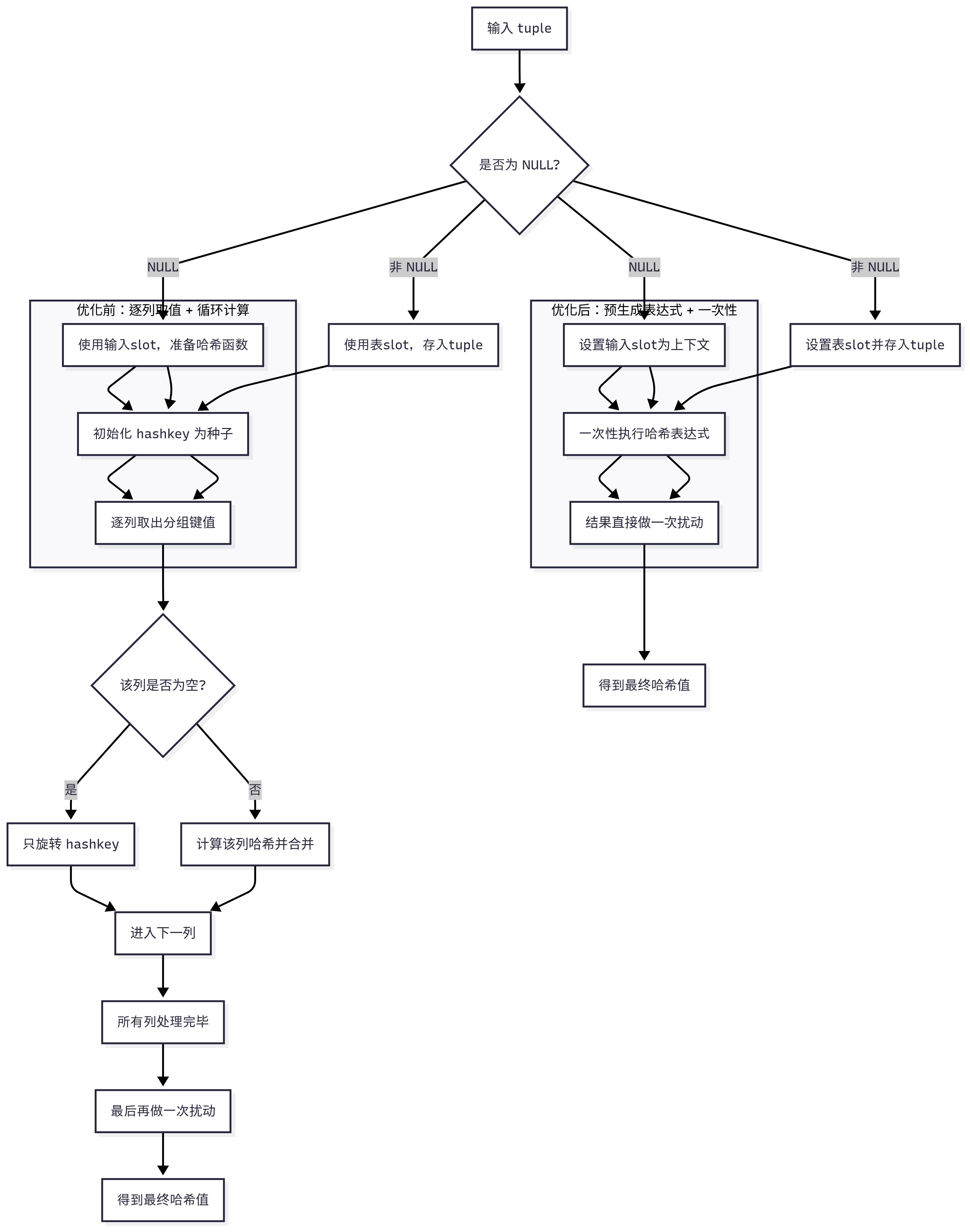
下层调用 ExecJustHashVarImpl 函数
ExecJustHashVarImpl 是一个内联函数(pg_attribute_always_inline),用于对单个变量(列)执行高效哈希计算,为 ExecBuildHash32FromAttrs 生成的 ExprState 的求值函数(evalfunc)。
它处理 ExprState 中的三个步骤(EEOP_INNER_FETCHSOME、EEOP_INNER_VAR、EEOP_HASHDATUM_FIRST),从输入元组槽提取列值并调用哈希函数(如 hash_any),返回 32 位哈希值(Datum 类型)。该函数与优化补丁相关,旨在减少函数调用开销并支持 JIT 编译。
在本次哈希优化补丁(“Use ExprStates for hashing in GROUP BY and SubPlans”)中,ExecJustHashVarImpl 是 ExecBuildHash32FromAttrs 生成的 ExprState 的核心求值函数。它通过预定义的 ExprEvalStep 序列(fetchop、var、hashop)高效提取列值并计算哈希,替代传统逐列调用 FunctionCall1Coll 的方式,减少开销并支持 JIT 编译。hashop->d.hashdatum 使用 ExprEvalStep 的 hashdatum 子结构存储哈希函数信息,与补丁的优化目标一致。
/* ExecJustHash(Inner|Outer)Var 的实现 */
static pg_attribute_always_inline Datum
// 内联函数,计算单个变量的哈希值,返回 Datum 类型结果
ExecJustHashVarImpl(ExprState *state, TupleTableSlot *slot, bool *isnull)
{// 获取 ExprState 的第一个步骤(EEOP_INNER_FETCHSOME),用于提取元组列ExprEvalStep *fetchop = &state->steps[0];// 获取第二个步骤(EEOP_INNER_VAR),用于获取特定列值ExprEvalStep *var = &state->steps[1];// 获取第三个步骤(EEOP_HASHDATUM_FIRST),用于执行哈希函数ExprEvalStep *hashop = &state->steps[2];// 获取哈希函数的调用信息(FunctionCallInfo)FunctionCallInfo fcinfo = hashop->d.hashdatum.fcinfo_data;// 获取列编号(attnum,列索引从 0 开始)int attnum = var->d.var.attnum;// 检查元组槽与 fetchop 的兼容性,确保槽类型匹配CheckOpSlotCompatibility(fetchop, slot);// 提取元组中的列值,至少到 last_var 指定的列编号slot_getsomeattrs(slot, fetchop->d.fetch.last_var);// 设置哈希函数的第一个参数值为 slot 中的列值fcinfo->args[0].value = slot->tts_values[attnum];// 设置哈希函数的第一个参数是否为 NULLfcinfo->args[0].isnull = slot->tts_isnull[attnum];// 初始化输出参数 isnull 为 false(假设结果非 NULL)*isnull = false;// 检查列值是否为 NULLif (!fcinfo->args[0].isnull)// 如果非 NULL,调用哈希函数(fn_addr)计算哈希值并转换为 uint32return DatumGetUInt32(hashop->d.hashdatum.fn_addr(fcinfo));else// 如果为 NULL,返回哈希值 0(Datum 类型)return (Datum) 0;
}
参数
state:ExprState *,表达式执行计划,包含步骤序列(steps),其中 -steps[0]为提取元组操作,steps[1]为获取列值,steps[2]为哈希计算。slot:TupleTableSlot *,输入元组槽,包含列值(tts_values)和NULL标志(tts_isnull)。isnull:bool *,输出参数,指示结果是否为NULL(始终设为false,因为哈希值0代表NULL输入)。
返回值
Datum:列值的哈希值(uint32类型),如果列值为NULL,则返回0。

)


)




》)


![[HFCTF2020]EasyLogin](http://pic.xiahunao.cn/[HFCTF2020]EasyLogin)







