目录
前言
解决思路
需求理解
MCP Server
LangGraph
本教程目标
技术栈
第一部分:构建 MCP Server - 工具服务化的基础架构
第二部分:Tools 实现
第三部分:基于 LangGraph 构建智能 Agent
第四部分:服务器和前端搭建
前言
差不多今年,"MCP""Agent" 一直都是 AI 领域的热点,尤其是 manus 的出现,显得 Agent 好像无所不能,极大的展现了 AI 的思考和执行决策的能力。
AI 不再只是单纯地回答问题,而是能够主动理解任务、规划步骤、调用工具,并最终完成目标。
但是在控件领域,控件产品基本都有很多 API, 有时候哪怕最熟练的开发者也很难清楚每个 API 的定义.
比如 SpreadJS :它提供了超过 2000 个 API,功能非常灵活,能够覆盖各种复杂场景。但对于开发者来说,光靠人工翻阅文档或记忆这些 API 显然效率不高。
如果用 LLM 帮助生成 SpreadJS API 代码,开发效率肯定会提高,不过,目前市面上常见的 LLM(ChatGPT、DeepSeek、Grok、Gemini ),在 SpreadJS 这种细分领域上能做的事情有限,简单 API 调用没什么问题,比如最基础的 setValue、getValue,但难度一上来它们很容易出现幻觉,生成一些看起来正确实则跑不了的代码。
比如从数据库取数据并构建一个仪表盘这种要调用多个 plugin 而且要进行深度使用,考虑 API 联合工作的结果的复杂需求
如果能通过一些人工投喂的知识,了解 SpreadJS 的一些冷门 API 和准确的使用方式,生成准确的代码,就可以稳定地提高开发的效率了。
那如何做呢?
解决思路
做类似 "知识库" 的功能,当 AI 想要知道什么它不懂的东西的时候,就去调用 "知识库" 来获取准确的信息,从而降低幻觉,提升代码准确度.
可以搭建一个 MCP Server 来暴露 SpreadJS 文档查询工具,再基于 LangGraph 搭建一个 Agent。该 Agent 能够自主决定是否查询文档,并在生成代码,执行代码之后进行结果校验,确保结果真正满足用户需求之后再结束逻辑。
需求理解
我们把 Agent 定义为:
能够自主理解任务、规划步骤、使用工具完成目标,并具备多轮对话和记忆能力的 AI 应用。
换句话说,如果一个 AI 能听懂需求,自行分析步骤,调用工具,并完成多轮消息处理直到完成任务,就可以算作一个 Agent。
在实现上,其实并不复杂,只需要两条:
- 支持多轮对话的 AI 对话框
- tool call (function call)
就能拼出一个基础的 Agent 原型。
那么,为什么要额外引入 MCP Server 和 LangGraph 呢?
MCP Server
Model Context Protocol(MCP)是一个 AI 工具调用的标准化协议,最核心的优势就是打通了不同 tool call 之间的差异,用标准化的协议完成通信,而且跟 Agent 解耦,Agent 只需要通过 getTools 这种接口获取可用工具列表即可.
因此,我们会把 SpreadJS 文档查询封装成一个独立的 MCP Server,不与本项目的其他部分耦合。未来即便是别的 AI 项目,也能直接使用这套服务。
当然,MCP 也有其劣势,例如,提供工具数量太多,AI 会陷入混乱,命名不标准,导致 AI 无法理解等,我们账号下有文章分析过其中的劣势,可以自行查找阅读。整体上来说,MCP 还是一个利大于弊的技术,所以才能被大家广泛接受。
LangGraph
选择 LangGraph 的原因在于它是一个 "搭建 Agent 的脚手架",就像我们在前端不会一直用 "原生 JS+HTML+CSS" 写所有项目,而会选择 React/Vue 这样的框架来提升效率一样,LangGraph 是一个构建 Agent 的框架,可以让我们用更简单的方式构建 Agent。
在我们这篇教程中,我们使用的是 Langgraph 的 TypeScript 版本,主要原因是 SpreadJS 主要面向的是前端开发者,对 Typescript 代码更熟悉,且可以直接在前端运行,如果你对 python 更熟悉,可以用 Langgraph 的 python 包,支持的更好更全面.
本教程目标
构建一个可以理解自然语言并操作 SpreadJS 表格的智能助手,用户只需输入类似添加一个表格,范围为 A1:C4 的需求,AI 即可自主判断是否需要文档帮助,是否可以生成代码,是否已经完成目标,实现用户的任务。
技术栈
- 后端: TypeScript + LangGraph + MCP Server
- 前端: 原生 HTML/CSS/JavaScript(前端代码不是我们这次教程的重点,能跑就行)
- 通信: WebSocket(实现实时双向通信)
- AI: Langchain ChatOpenAI SDK
我们项目设置三个端口:
- 3000 端口:前端服务,网页
- 3001 端口: Agent 服务,AI
- 3002 端口: MCP Server 服务
第一部分:构建 MCP Server - 工具服务化的基础架构
MCP Server 实现
首先我们来实现 MCP Server
看看核心代码:
export class MCPServer {private server: http.Server;constructor() {this.server = this.createHTTPServer();}private createHTTPServer(): http.Server {return http.createServer(async (req, res) => {const parsedUrl = url.parse(req.url!, true);if (req.method === 'GET' && parsedUrl.pathname === '/tools') {res.end(JSON.stringify({success: true,tools: this.getTools()}));} else if (req.method === 'POST' && parsedUrl.pathname === '/execute') {const { toolName, args } = await this.parseBody(req);const result = await this.executeTool(toolName, args);res.end(JSON.stringify({ success: true, result }));}});}
}
这里的设计思路很简单:getTools 拿工具列表,execute 执行工具,实现了一个 MCP Server 最基础的功能
核心 API 设计
// 获取可用工具列表
public getTools() {return Object.entries(toolDefinitions).map(([name, definition]) => ({name,description: definition.description,schemaDescription: definition.schema}));
}// 执行指定的工具
public async executeTool(toolName: string, args: any): Promise<any> {const toolImpl = toolImplementations[toolName];if (!toolImpl) {throw new Error(`Tool ${toolName} not found`);}console.log(`[MCP Server] Executing tool: ${toolName}`);const result = await toolImpl(args);return result;
}
第二部分:Tools 实现
定义与实现分离
我可以在 Agent 里写工具逻辑,但这样做有几个问题,但是我们使用的 MCP 服务不总是自己写的,所以在教程里,就养成用网络请求调用 MCP Server 是个好习惯。而且解耦之后,重构成本也更小.
包括工具的定义和实现,也考虑分开,定义用 JSON Schema 就可以了,不需要沾逻辑,在实现上再写逻辑,这样不变的定义永远不用改,逻辑上有 BUG 去改逻辑就行了。
// 工具定义层
export const toolDefinitions: Record<string, ToolDefinition> = {"api-doc-search": {description: "搜索SpreadJS相关的技术文档和API信息",schema: {type: "object",properties: {keyword: {type: "string",description: "需要搜索SpreadJS如何使用的关键词"}},required: ["keyword"]}}
};// 工具实现层
export const toolImplementations: Record<string, ToolFunction> = {"api-doc-search": async ({ keyword }: { keyword: string }) => {const encodedTopic = encodeURIComponent(keyword);const url = `https://context7.com/api/v1/llmstxt/...`;const res = await fetch(url, { /* 请求配置 */ });const data = await res.json();return processedResults;}
};
我们实现了两个核心工具:
api-doc-search:基于 Context7 的文档检索
"api-doc-search": async ({ keyword }: { keyword: string }) => {const encodedTopic = encodeURIComponent(keyword);const url = `https://context7.com/api/v1/llmstxt/developer_mescius_com-spreadjs-docs-llms.txt?type=json&tokens=100000&topic=${encodedTopic}`;const res = await fetch(url, {method: "GET",headers: {"accept": "*/*","content-type": "application/json",}});const data = await res.json();if (data && data.snippets && Array.isArray(data.snippets)) {return data.snippets.slice(0, 8).map((snippet: any, index: number) => {let content = `**${snippet.codeTitle}**\n\n`;if (snippet.codeDescription) {content += `描述: ${snippet.codeDescription}\n\n`;}if (snippet.codeList && snippet.codeList.length > 0) {content += `代码示例:\n\`\`\`javascript\n`;content += snippet.codeList[0].code;content += '\n```';}return {id: index + 1,title: snippet.codeTitle,content: content,code: snippet.codeList?.[0]?.code || '',source: snippet.pageTitle};});}
}
这个工具通过 Context7 API 搜索 SpreadJS 文档,返回结构化的搜索结果。每个结果包含标题、描述、代码示例等信息,AI 可以基于这些信息生成更准确的代码。
context7 是一个工具网站,可以通过 llms.txt 构建 RAG 索引,SpreadJS 的 docs 站点提供了 llms.txt, context7 就自动根据 llms.txt 爬取了 SpreadJS 的文档库,构建了 RAG 索引,通过 contetx7 搜索就可以拿到文档中的信息. context7 也提供了一个独立的 MCP Server, 有兴趣可以把它装到自己的 IDE 里试试.
execute-spreadjs:生成 SpreadJS API 代码
"execute-spreadjs": async ({ execute_logic, query_logic }: {execute_logic: string;query_logic: string
}) => {console.log(`[Tool Call: execute-SpreadJS] Generating code...`);const responseToFrontend = JSON.stringify({execute: execute_logic,query: query_logic,});return responseToFrontend;
}
这个工具负责生成 SpreadJS 代码。它接收两个参数:
- execute_logic:要执行的操作代码
- query_logic:用于验证结果的查询代码
这个思想其实是很好的,不局限于这个工具,我们写这种执行逻辑的时候,都可以想到,这种网络请求式的操作,都可以强制要求返回一个确认操作,即一个 write 操作,一个 read 操作,进行结果校验,这比单独写个 query_spreadjs 的工具再去校验一次,不就省了很多 token, 请求的时间也省下了吗.
另外,在 initSpreadJS 的时候,我们把一些变量暴露在了 window 下,这样 AI 生成的代码就可以直接 new Function 执行了,但是实际 production 环境,还是要用隔离沙箱去做,不要这样 hackcode.
工具注册与对接
在 MCP Server 中,工具的注册过程很简单:
public getTools() {return Object.entries(toolDefinitions).map(([name, definition]) => ({name,description: definition.description,schemaDescription: definition.schema}));
}
当 Agent 需要执行工具时:
public async executeTool(toolName: string, args: any): Promise<any> {const toolImpl = toolImplementations[toolName];const result = await toolImpl(args);return result;
}
更好的搜索
如果需要更强的 RAG 检索效果,可以引入 GC QA RAG, 利用这个 RAG 项目,可以生成 QA 对检测,可以自己部署,效果很好,可以自己部署一下试试.
只需要替换 api-doc-search 的实现,接口保持不变,Agent 端无需任何修改。
context7 使用的 RAG 技术我不太清楚,但是肯定用的不是 QA 对方案,其实对于查询来说,用 QA 对 query string 进行向量匹配,效果要比用原文档对 query string 进行向量匹配肯定要好的多,甚至不需要 reranking 这些步骤.
这些概念对于不了解 RAG 的人可能会稍显有些费解,如果有兴趣可以阅读一下我们账号发布的关于 RAG 的一些文章了解.
第三部分:基于 LangGraph 构建智能 Agent
LangGraph 介绍
LangGraph 的核心概念主要有几个:node、edge 和 state。
可以把它想象成一个状态机,每个 node 是一个步骤,edge 决定步骤之间怎么流转,而 state 记录上下文。这样一来,就能自然地实现多轮对话和工具调用。
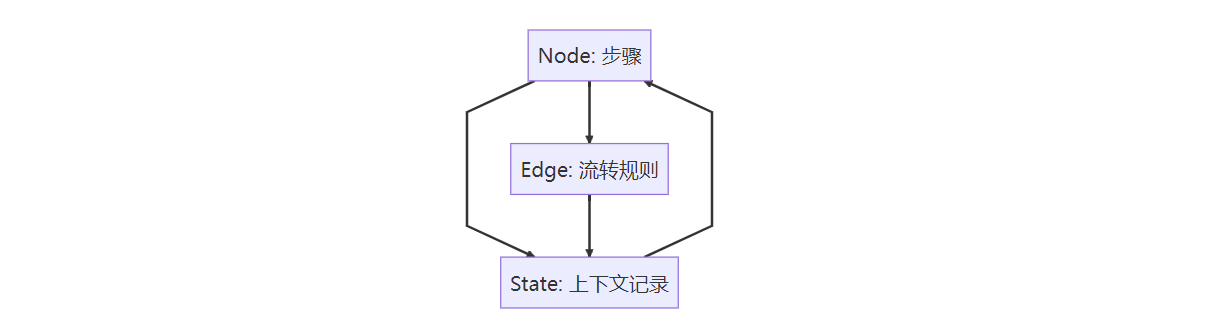
Node、Edge 与 ConditionalEdge
- Node:工作流中的一个步骤,可以是 LLM 调用、工具执行,或者任何异步操作
- Edge:边 - 固定的流转路径,A 节点执行完总是去 B 节点
- ConditionalEdge:条件边 - 带条件的流转路径,根据运行时状态决定去哪个节点
Agent 状态管理
状态是什么
在 LangGraph 中,state 保存着对话历史与工具调用结果。对我们来说,messages 是最核心的上下文数据:
type AgentState = {messages: BaseMessage[];
};const workflow = new StateGraph<AgentState>({channels: {messages: {value: (x: BaseMessage[], y: BaseMessage[]) => x.concat(y),default: () => [],}},
});
这里的设计很巧妙:新的 messages 会自动追加到现有 messages 后面,形成完整的对话历史。这样 AI 就能记住之前的交互内容。
streamEvents API
streamEvents 是 LangGraph 提供的一个强大功能,让我们能够实时监控 Agent 的执行过程。相比只看最终结果,实时过程对用户体验来说更重要:
const eventStream = compiledGraph.streamEvents(initialState, {version: "v2" as const,recursionLimit: 10
});for await (const event of eventStream) {switch (event.event) {case 'on_chat_model_stream':// AI 思考的流式输出if (event.data.chunk?.content) {yield {type: 'agent_message',data: { content: event.data.chunk.content }};}break;case 'on_tool_start':// 工具开始执行yield {type: 'agent_step',data: {step: 'tools',output: { lastToolCall: { name: event.name, args: event.data.input } }}};break;case 'on_tool_end':// 工具执行完成yield {type: 'agent_step',data: {step: 'tools',output: { toolResult: event.data.output }}};break;}
}
LangChain 还推出了一个名为 LangSmith 的工具,它专门用于监控和分析 Agent 的状态以及工作流执行情况。 虽然我在本教程中没有使用它,但如果你希望更直观地观察 state 变化、事件流和决策路径,可以把 langsmith 接入项目试试。
Langgraph 工作流设计
我们采用了一个经典的 action-check 模式:
// 节点 1: action - 执行工具调用和LLM推理
workflow.addNode("action", this.actionNode.bind(this));
// 节点 2: check - AI自主决策下一步行动
workflow.addNode("check", this.checkNode.bind(this));// 设置工作流的入口node
workflow.setEntryPoint("action");// action 执行后总是去 check 进行决策
workflow.addEdge("action", "check");// check 节点执行后进行AI自主决策是执行action, 还是结束
workflow.addConditionalEdges("check", async (state: AgentState) => {const decision = await this.aiDecideNextAction(state);if (decision === "__end__") {return "__end__";} else {return "action"; // 继续执行}
});
在这个 workflow 中,我们设计了 2 个 Node, 2 个 Edge, 并将入口设置为了 action 节点.
我们用一张图来理解这个 workflow
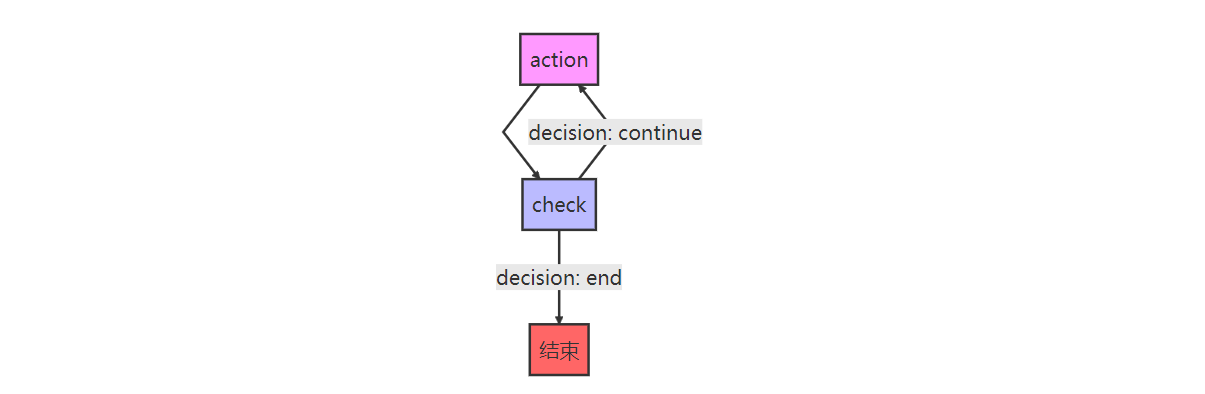
Node 的搭建
action node:这是主要的执行节点,负责 AI 推理和工具调用
private async actionNode(state: AgentState): Promise<{ messages: BaseMessage[] }> {const response = await this.model.invoke(state.messages);// 如果模型决定调用工具if (response.tool_calls && response.tool_calls.length > 0) {const toolMessages: ToolMessage[] = await Promise.all(response.tool_calls.map(async (toolCall) => {const tool = this.tools.find((t) => t.name === toolCall.name);const output = await tool.invoke(toolCall.args);return new ToolMessage({tool_call_id: toolCall.id!,content: typeof output === 'string' ? output : JSON.stringify(output),name: toolCall.name});}));return { messages: [response, ...toolMessages] };}return { messages: [response] };
}
check node:这个节点很简单,主要作用是触发 AI 决策,也就是把逻辑放在了条件边中,可以在这里记一些 log 之类的。
private checkNode(state: AgentState): { messages: [] } {return { messages: [] };
}
为什么使用 action-check 模式
action-check 模式的核心思想是执行与决策解耦:
- action 节点:专注于执行任务,包括调用 AI、执行工具、处理结果等操作。
- check 节点:专注于决策,根据当前状态分析并决定下一步的行动方向。
逻辑与可维护性优势
- 逻辑清晰:执行和决策分开,代码结构直观,易于维护。
- 可控性高:可以在 check 节点加入复杂决策逻辑,而不干扰执行逻辑。
- 便于调试:每个决策点都有明确日志和状态记录,方便排查问题。
发挥 Agent 自主性
这种模式能更好的发挥 AI 自主决策的能力,我们下面讨论。
AI 自主决策机制
这是整个系统的核心部分。我们让 AI 基于完整的对话历史自主决策下一步行动:
private async aiDecideNextAction(state: AgentState): Promise<string> {const decisionPrompt = `
基于以上完整的对话历史,决定下一步最合适的行动:1. CONTINUE_SEARCH - 如果需要更多SpreadJS技术信息
2. EXECUTE_CODE - 如果有足够信息可以生成SpreadJS代码
3. TASK_COMPLETE - 如果用户请求已完全满足请只回复上述选项之一,不需要其他解释。
`;const decisionModel = new ChatOpenAI({ /* 配置 */ });// 将决策提示添加到现有对话历史中const decisionMessages = [...state.messages, new HumanMessage(decisionPrompt)];const response = await decisionModel.invoke(decisionMessages);const decision = response.content.trim();// 根据AI决策返回路由switch (decision) {case 'CONTINUE_SEARCH':case 'EXECUTE_CODE':return "action";case 'TASK_COMPLETE':return "__end__";default:return "__end__"; // 安全默认:避免无限循环}
}
这里的关键是将决策判断交给 AI,而不是用硬编码的规则。AI 能够理解上下文,做出更智能的判断。注意要 default 直接结束避免循环.
工具集成
Agent 启动时会从 MCP Server 获取工具列表,然后创建本地的工具代理:
private async fetchMCPTools(): Promise<StructuredTool[]> {const response = await this.httpRequest('GET', '/tools');const mcpTools = response.tools;return mcpTools.map((mcpTool: any) => {const schema = this.buildZodSchema(mcpTool.schemaDescription);return new DynamicStructuredTool({name: mcpTool.name,description: mcpTool.description,schema: schema as any,func: async (args: any) => {// 转发给MCP Server执行return await this.executeMCPTool(mcpTool.name, args);},});});
}
这里做了一个重要的架构决定:Agent 端的工具只是 "代理",真正的执行逻辑在 MCP Server 中。注意接入 tools 之后用 zod 做了个 shcema 绑定,可以规定 AI 返回的格式,做 response_format.
第四部分:服务器和前端搭建
WebSocket 服务架构设计
如前面所说,有两个服务端口
- Agent Server(3001 端口):处理 AI 请求,管理 WebSocket 连接
- MCP Server(3002 端口):提供工具服务,纯 HTTP API
Agent Server 实现
private async fetchMCPTools(): Promise<StructuredTool[]> {const response = await this.httpRequest('GET', '/tools');const mcpTools = response.tools;return mcpTools.map((mcpTool: any) => {const schema = this.buildZodSchema(mcpTool.schemaDescription);return new DynamicStructuredTool({name: mcpTool.name,description: mcpTool.description,schema: schema as any,func: async (args: any) => {// 转发给MCP Server执行return await this.executeMCPTool(mcpTool.name, args);},});});
}
服务间协作机制
Agent Server 通过 HTTP 请求与 MCP Server 通信:
// Agent 初始化时获取工具列表
const response = await this.httpRequest('GET', '/tools');// Agent 执行工具时调用 MCP Server
const result = await this.httpRequest('POST', '/execute', {toolName: toolName,args: args
});
这种设计让两个服务完全解耦,可以独立部署和扩容。
前端页面搭建
主要包含两个部分:
- 左侧:SpreadJS 表格组件
<div class="spreadjs-container"><div id="ss" style="width: 100%; height: 100%;"></div>
</div>
2. 我们用 cdn 去拉去 SpreadJS 的 all 包,这个包在 localhost 域名下是可以运行的,不需要 license, 只是会有水印。具体见项目代码.
3. 右侧:聊天对话窗口
<div class="chat-messages" id="chatMessages"><!-- 消息展示区域 -->
</div><div class="input-area"><input type="text" id="userInput" placeholder="输入你的需求..." /><button id="sendButton">发送</button>
</div>
- 这个就是个 chatbox, 怎么实现都可以,拉个三方库也可以.
WebSocket 客户端实现
class SpreadJSAgentClient {constructor() {this.ws = new WebSocket('ws://localhost:3001');this.sessionId = this.generateSessionId();this.connectWebSocket();this.setupSpreadJS();}setupSpreadJS() {// 初始化SpreadJSconst spread = new GC.Spread.Sheets.Workbook(document.getElementById('ss'));// 把一些变量暴露在全局, 方便execute_spreadjs调用window.GC = GC;window.workbook = window.spread = spread;window.sheet = window.activeSheet = spread.getActiveSheet();}handleServerMessage(message) {const { type, data } = message;switch (type) {case 'agent_message':// AI 思考内容this.addAgentMessage(data.content);break;case 'agent_step':// 工具调用过程if (data.output.lastToolCall) {this.displayToolCall(data.output.lastToolCall);}if (data.output.toolResult) {this.displayToolResult(data.output.toolResult);}break;}}
}
SpreadJS 代码执行
当 AI 生成 SpreadJS 代码时,前端会安全地执行这些代码:
executeSpreadJSCode(executionPackage) {try {// Execute the generated codeconst func = new Function('workbook', 'GC', executionPackage.executeCode);func(window.workbook, window.GC);// Run query to get resultsconst queryFunc = new Function('workbook', 'GC', 'return ' + executionPackage.queryCode);const result = queryFunc(window.workbook, window.GC);// Send result back to agentthis.sendExecutionResult(executionPackage.id, result);} catch (error) {console.error('Code execution failed:', error);this.sendExecutionResult(executionPackage.id, { error: error.message });}
}
new Function 还是比较危险的,这只是个教程,不要直接使用.
效果展示
运行 npm run dev 启动三个服务,打开 localhost:3000 访问前端页面,就可以输入需求了.
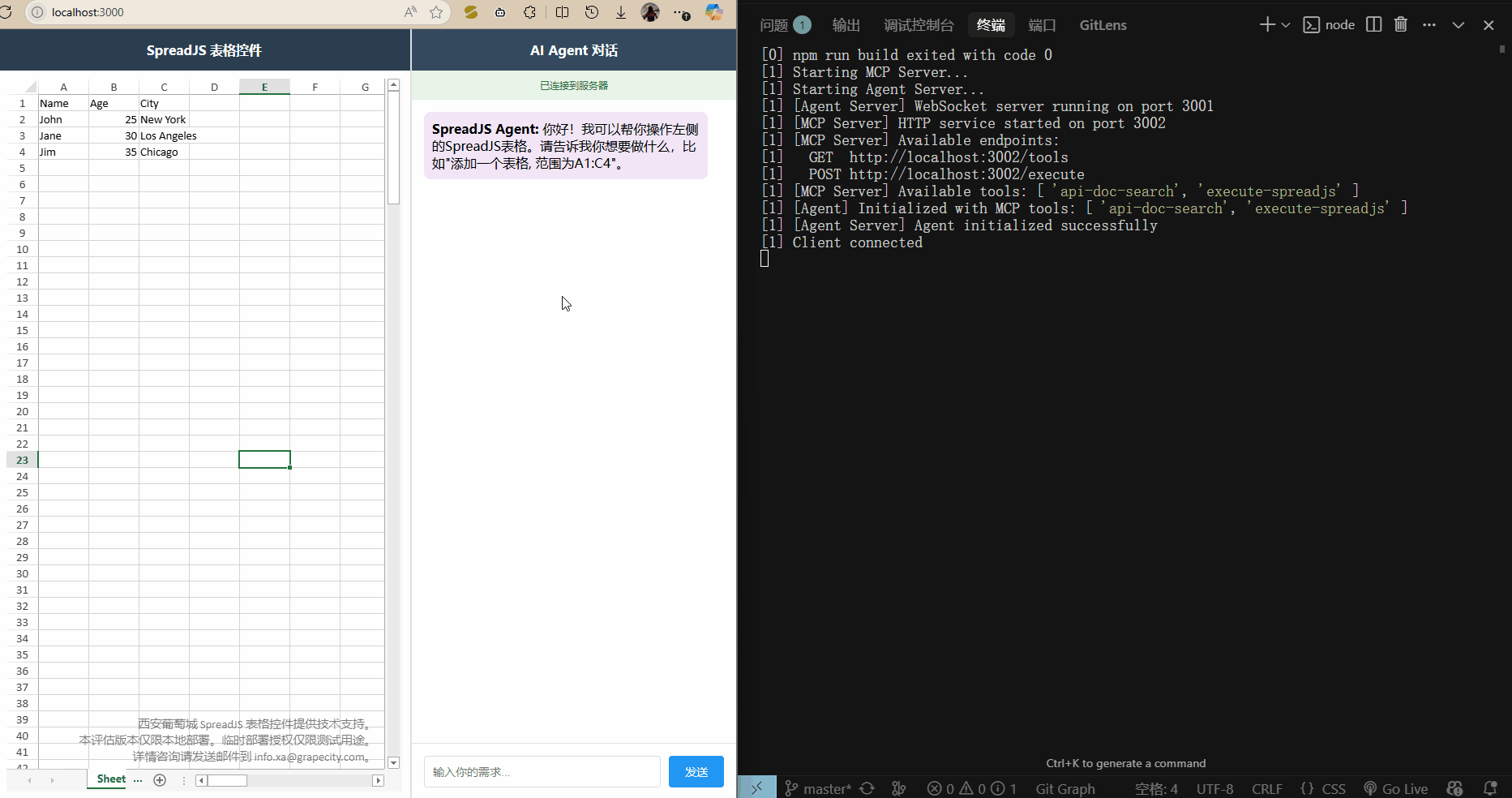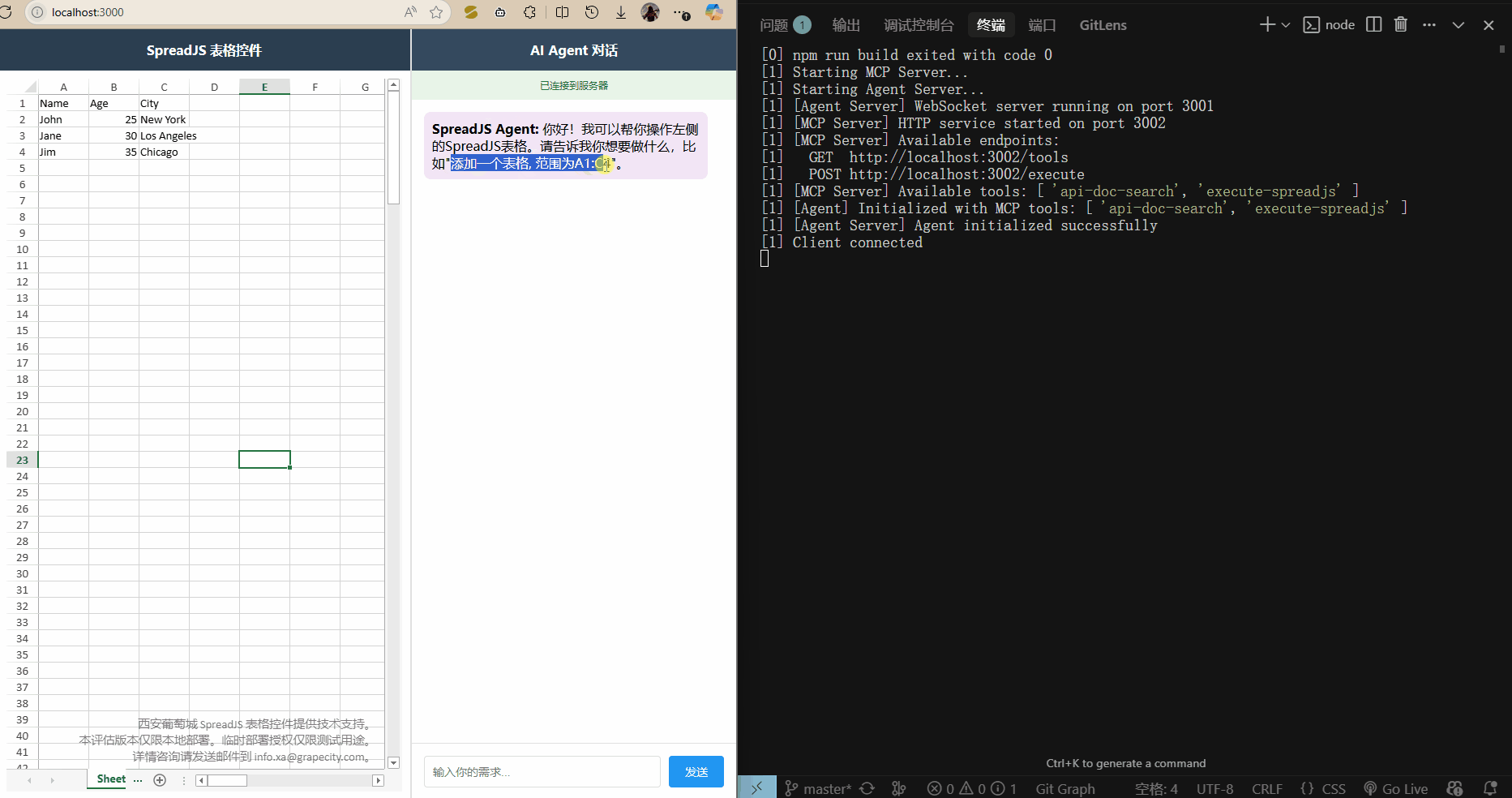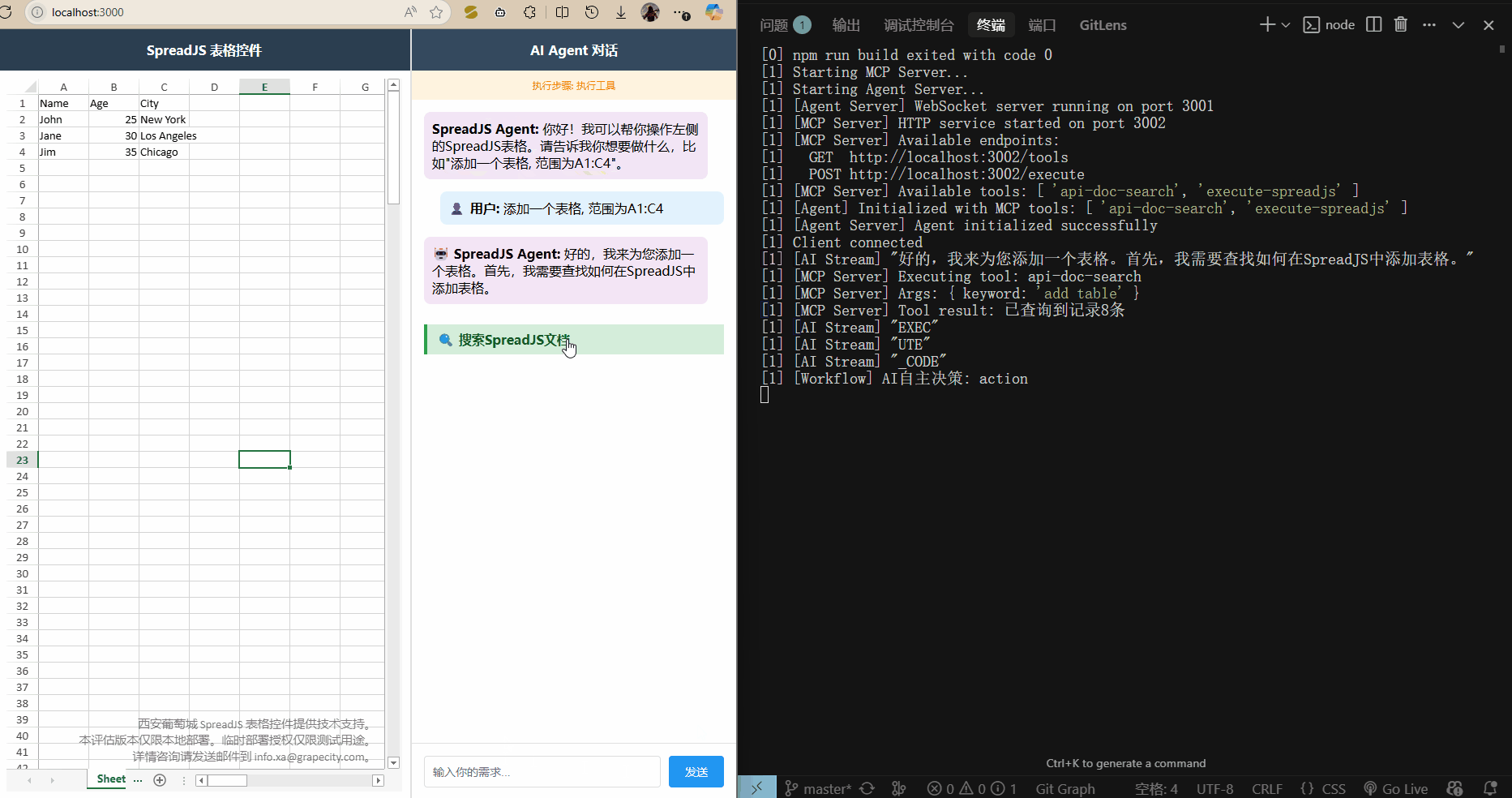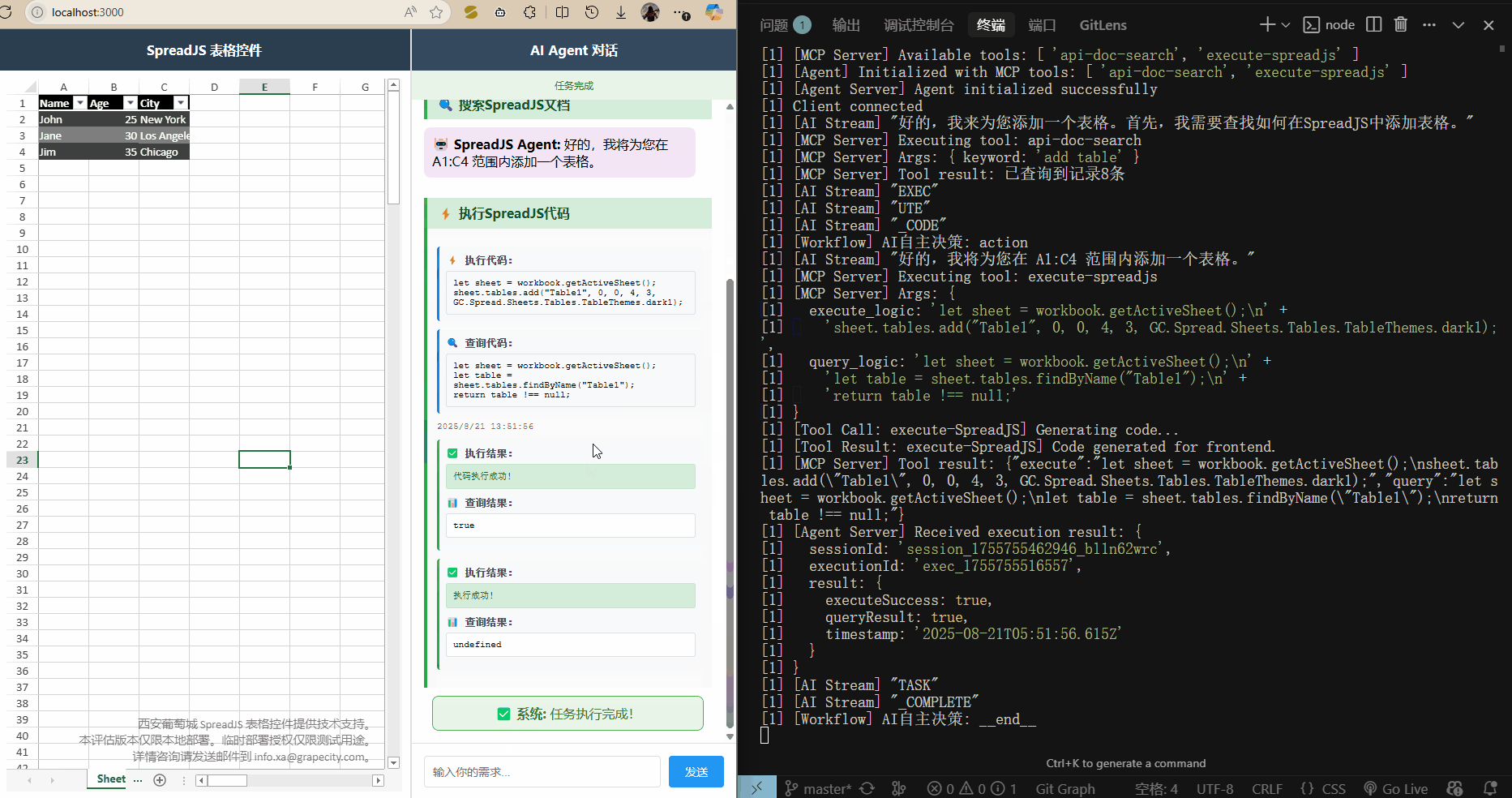

)




![[灵动微电子 MM32BIN560CN MM32SPIN0280]读懂电机MCU之比较器](http://pic.xiahunao.cn/[灵动微电子 MM32BIN560CN MM32SPIN0280]读懂电机MCU之比较器)




)

![[光学原理与应用-321]:皮秒深紫外激光器产品不同阶段使用的工具软件、对应的输出文件](http://pic.xiahunao.cn/[光学原理与应用-321]:皮秒深紫外激光器产品不同阶段使用的工具软件、对应的输出文件)



:深度强化学习的里程碑式突破)

