在 Linux 环境下进行开发,熟练掌握基础工具是提升效率、解决问题的核心前提。无论是软件安装、代码编辑,还是编译调试、版本管理,一套 “趁手” 的工具链能让开发过程事半功倍。本文将从 Linux 开发最核心的七大工具模块入手,一步步拆解每个工具的原理、操作方法与实战技巧,带你构建完整的 Linux 开发工具知识体系,即使是新手也能跟着操作,逐步掌握 Linux 开发的精髓。
一、软件包管理器:Linux 软件安装的 “应用商店”
在 Windows 或 macOS 上,我们习惯通过 “应用商店” 或.exe/.dmg 文件安装软件;而在 Linux 中,软件包管理器承担了类似的角色,它能自动解决软件依赖、下载编译好的软件包,让我们无需手动处理复杂的源码编译流程。目前主流的 Linux 发行版中,CentOS/RHEL 系列常用yum,Ubuntu/Debian 系列常用apt,两者核心逻辑一致,但操作细节略有差异。
1.1 什么是软件包与包管理器?
首先要明确两个核心概念:软件包和软件包管理器。
- 软件包:Linux 下的软件包,本质是 “预先编译好的可执行程序 + 依赖文件 + 配置脚本” 的压缩包,类似 Windows 的 “安装程序”。比如我们常用的
gcc编译器、vim编辑器,都以软件包的形式存在于远程服务器中。 - 软件包管理器:是连接 “用户” 与 “软件包服务器” 的工具,它的核心功能包括:搜索软件包、自动下载软件包、解决软件依赖(比如安装 A 软件需要先装 B 库,管理器会自动处理)、安装 / 卸载 / 更新软件。
简单来说,软件包与包管理器的关系,就像 “手机 APP” 与 “应用商店”—— 你不需要知道 APP 的安装文件存在哪里,只需在应用商店里搜索、点击安装,剩下的交给管理器即可。
1.2 Linux 软件生态:从 “请求” 到 “安装” 的完整流程
Linux 的软件生态是一个 “用户 - 包管理器 - 软件包服务器” 的三方体系,无论你用的是 CentOS、Ubuntu 还是其他发行版,软件安装的核心流程都大同小异:
- 用户发起请求:比如你想安装
lrzsz(一款文件传输工具),通过yum install lrzsz或apt install lrzsz向包管理器发送指令; - 包管理器解析依赖:包管理器会先检查
lrzsz需要哪些依赖库(比如libc.so等系统库),如果本地没有这些依赖,会自动从服务器下载; - 服务器下载软件包:包管理器连接预设的 “软件包服务器”(国内常用阿里云、清华源等镜像站),下载
lrzsz及其依赖的软件包; - 本地安装与配置:下载完成后,包管理器会自动解压软件包,将可执行文件放到
/usr/bin(系统可执行路径),配置文件放到/etc,并更新系统的软件注册表。
为什么会有 “国内镜像源”?因为默认的 Linux 软件包服务器大多在国外,下载速度慢且容易中断。国内高校(如清华、中科大)和企业(如阿里云、网易)会同步国外服务器的软件包,提供 “镜像服务”,让我们能快速下载软件。
1.3 国内优质镜像源推荐(附配置链接)
国内镜像源不仅下载速度快,还能避免因网络问题导致的安装失败。以下是经过长期验证的优质镜像源,涵盖主流 Linux 发行版:
| 镜像源名称 | 官方链接 | 支持的发行版 | 特点 |
|---|---|---|---|
| 阿里云开源镜像站 | 阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 | CentOS、Ubuntu、Debian 等 | 国内访问速度最快的镜像源之一,更新及时 |
| 清华大学开源软件镜像站 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror | 全系列发行版 + 编程语言扩展包 | 包含 Python、Perl 等语言库,文档丰富 |
| 中国科学技术大学镜像站 | USTC Open Source Software Mirror | 全系列发行版 + 开发工具 | 学术机构维护,稳定性高 |
| 北京交通大学镜像站 | 首页 - 北京交通大学自由与开源软件镜像站 | 主流发行版 + 开源软件仓库 | 提供详细配置指南,适合新手 |
| 网易开源镜像站 | 欢迎访问网易开源镜像站 | 主流发行版 + 常用软件 | 搜索功能便捷,支持快速定位软件包 |
注意:部分镜像站可能因政策或维护调整链接,使用前建议访问官网确认最新地址。
1.4 yum 操作详解(CentOS/RHEL 系列适用)
yum(Yellow dog Updater, Modified)是 CentOS/RHEL 系列的默认包管理器,操作简洁且自动化程度高。以下是yum的核心操作,每一步都附带实战例子。
1.4.1 查看软件包:确认软件是否可安装
在安装软件前,我们通常需要先确认 “软件包是否存在于当前源中”,这时候用yum list命令,配合grep筛选目标包(因为yum list会列出所有软件包,数量极多)。
命令格式:yum list | grep [软件包关键词]
实战例子:查看是否有lrzsz软件包
# 执行命令
yum list | grep lrzsz
- 第一列(软件包名):
lrzsz.x86_64,其中lrzsz是软件名,x86_64表示适配 64 位系统(32 位系统后缀为i686); - 第二列(版本信息):
0.12.20-36.el7,el7表示适配 CentOS 7/RHEL 7(el6对应 CentOS 6); - 第三列(软件源):
@base,表示该包来自系统默认的 “base” 源(类似 “官方应用商店”)。
如果想查看软件包的详细信息(如版本、维护者、依赖),可以用yum info [软件包名]:
yum info lrzsz

1.4.2 安装软件:一键搞定依赖与下载
安装软件是yum最常用的功能,核心命令是yum install,加上-y参数可以自动确认安装(无需手动输入y)。
命令格式:sudo yum install -y [软件包名]
实战例子:安装lrzsz工具
# 执行安装命令(sudo获取管理员权限,因为安装需写入系统目录)
sudo yum install -y lrzsz# 安装成功的标志
...
Installed:lrzsz.x86_64 0:0.12.20-36.el7 Complete! # 出现这个提示表示安装完成

注意事项:
- 普通用户必须用
sudo提权或切换到root用户:软件安装会修改/usr/bin、/lib等系统目录,普通用户无权限; - 安装时不能并行操作:如果同时用
yum安装两个软件,会提示 “另一个 yum 进程正在运行”,需等待前一个完成; - 确保网络通畅:可以用
ping www.baidu.com测试网络,若不通则无法下载软件包。
1.4.3 卸载软件:干净删除软件与配置
如果某个软件不再需要,可以用yum remove卸载,同样支持-y自动确认。
命令格式:sudo yum remove -y [软件包名]
实战例子:卸载lrzsz
sudo yum remove -y lrzsz# 卸载成功的标志
...
Removed:lrzsz.x86_64 0:0.12.20-36.el7 Complete!
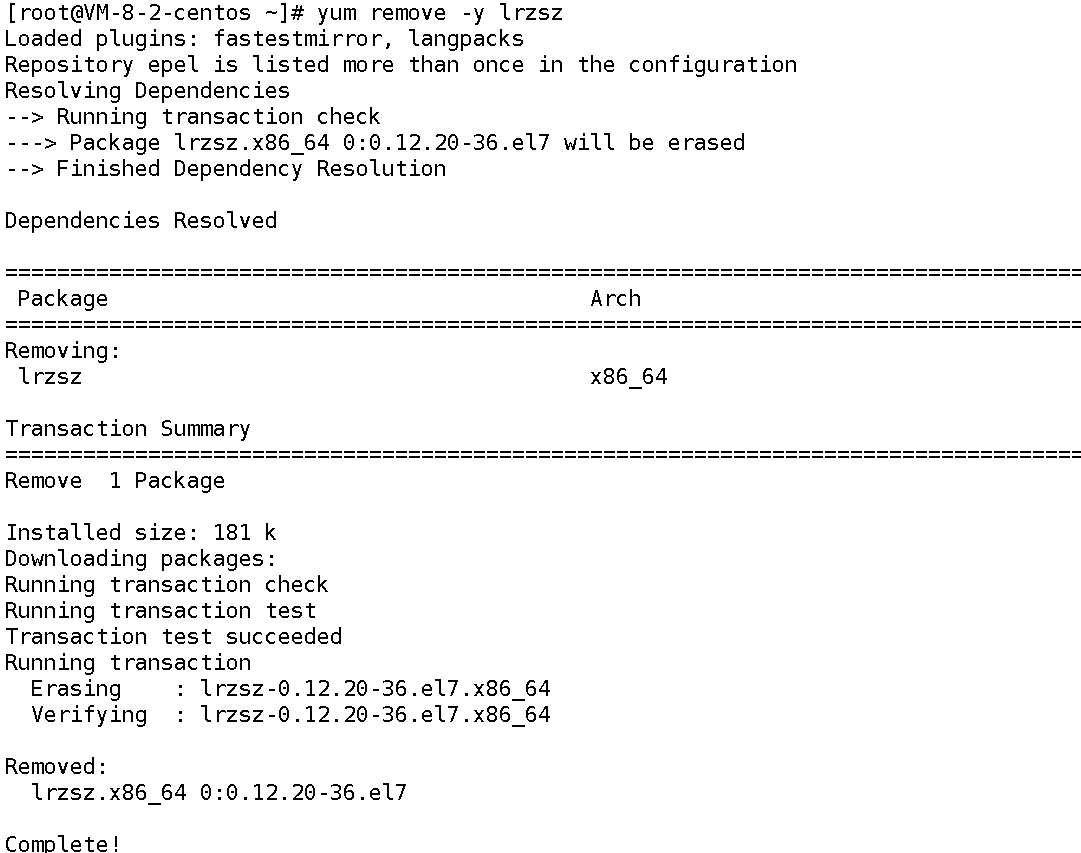
小贴士:yum remove会删除软件的可执行文件和依赖,但不会删除用户自己创建的配置文件(如~/.lrzszrc),如果需要彻底清理,需手动删除这些文件。
1.4.4 软件源配置:更换国内源(CentOS 7 为例)
默认的 CentOS 软件源在国外,下载速度慢,建议更换为国内镜像源(以阿里云为例),步骤如下(一般虚拟机上需要自己配置,各大平台的云服务器一般已经配置好了,大部分云服务器不需要配置):
-
备份原有源配置:先将系统默认的源文件移到备份目录,避免后续出错无法恢复;
sudo mkdir /etc/yum.repos.d/backup # 创建备份目录 sudo mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/backup/ # 移动原有源文件 -
下载阿里云源配置文件:通过
curl命令下载阿里云提供的 CentOS 7 源文件;sudo curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo -
清理并生成新缓存:
yum会缓存之前的软件包信息,更换源后需要清理旧缓存,生成新缓存;sudo yum clean all # 清理旧缓存 sudo yum makecache # 生成新缓存(这一步会耗时几分钟,耐心等待) -
验证源是否生效:通过
yum repolist查看当前生效的软件源,若出现阿里云的源名称(如aliyun-base),则配置成功;sudo yum repolist
1.5 apt 操作详解(Ubuntu/Debian 系列适用)
apt(Advanced Package Tool)是 Ubuntu/Debian 系列的包管理器,功能与yum类似,但命令略有不同。以下是apt的核心操作,同样附带实战例子。
1.5.1 查看软件包:搜索与查看详情
apt查看软件包有两个常用命令:apt search(搜索软件包)和apt show(查看详细信息)。
实战例子 1:搜索lrzsz软件包
apt search lrzsz# 输出结果(关键部分)
Sorting... Done
Full Text Search... Done
lrzsz/focal,now 0.12.21-10 amd64 [installed]Tools for zmodem/xmodem/ymodem file transfer
focal表示适配 Ubuntu 20.04(Ubuntu 版本代号,如 22.04 是jammy);[installed]表示该软件已安装(若未安装则无此标记)。
实战例子 2:查看lrzsz的详细信息
apt show lrzsz# 输出结果(关键部分)
Package: lrzsz
Version: 0.12.21-10
Priority: optional
Section: universe/comm
Origin: Ubuntu
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Description: Tools for zmodem/xmodem/ymodem file transferThis package provides tools for file transfer using the zmodem, xmodem,and ymodem protocols.
1.5.2 安装软件:更新缓存后再安装
apt安装软件前,建议先执行apt update更新软件包索引(类似 “刷新应用商店列表”),避免安装到旧版本。
命令格式:
sudo apt update # 更新软件包索引
sudo apt install -y [软件包名] # 安装软件
实战例子:安装lrzsz
sudo apt update
sudo apt install -y lrzsz# 安装成功的标志
...
Setting up lrzsz (0.12.21-10) ...
Processing triggers for man-db (2.9.1-1) ...
1.5.3 卸载软件:保留配置或彻底删除
apt remove会删除软件,但保留用户配置文件;如果想彻底删除(包括配置文件),可以用apt purge。
命令格式:
# 卸载软件,保留配置
sudo apt remove -y [软件包名]# 彻底卸载,删除配置
sudo apt purge -y [软件包名]
实战例子:彻底卸载lrzsz
sudo apt purge -y lrzsz
1.5.4 软件源配置:更换国内源(Ubuntu 20.04 为例)
Ubuntu 默认源同样在国外,更换为国内源(以清华源为例)的步骤如下:
-
备份原有源配置:
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak -
下载清华源配置文件:
sudo wget -O /etc/apt/sources.list https://mirrors.tuna.tsinghua.edu.cn/ubuntu/sources.list -
修改源文件适配 Ubuntu 20.04:清华源文件包含多个 Ubuntu 版本的配置,需要确保只保留
focal(Ubuntu 20.04 代号)相关的行;sudo nano /etc/apt/sources.list # 用nano编辑文件打开后,删除所有不含
focal的行,保留类似以下内容:deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse编辑完成后,按
Ctrl+O保存,Ctrl+X退出。 -
更新缓存验证:
sudo apt update # 更新缓存 sudo apt policy # 验证源是否生效(出现清华源地址即成功)
二、Vim 编辑器:Linux 下的 “代码编辑神器”
在 Linux 开发中,vim是最常用的编辑器之一 —— 它无需图形界面,仅通过命令就能完成代码的编辑、查找、替换等操作,且支持语法高亮、插件扩展,是服务器端开发的 “必备工具”。很多新手觉得vim难用,其实是没掌握它的 “模式思维”,只要理清三种核心模式的切换逻辑,就能快速上手。
2.1 Vim 与 Vi 的区别:为什么选 Vim?
首先要区分vi和vim:
vi是 Linux 系统自带的基础编辑器,功能简单,无语法高亮、可视化操作;vim是vi的升级版本,兼容vi的所有命令,同时增加了语法高亮、代码折叠、插件支持等功能,还能在 Windows、macOS 等系统上运行。
简单来说,vim是vi的 “增强版”,日常开发中我们优先使用vim。
2.2 Vim 的三种核心模式:一切操作的基础
vim的核心特点是 “多模式编辑”,不同模式下的键盘操作含义完全不同。对于新手,首先要掌握三种核心模式:命令模式(Normal Mode)、插入模式(Insert Mode)、底行模式(Last Line Mode)。
三种模式的切换逻辑如下图所示:
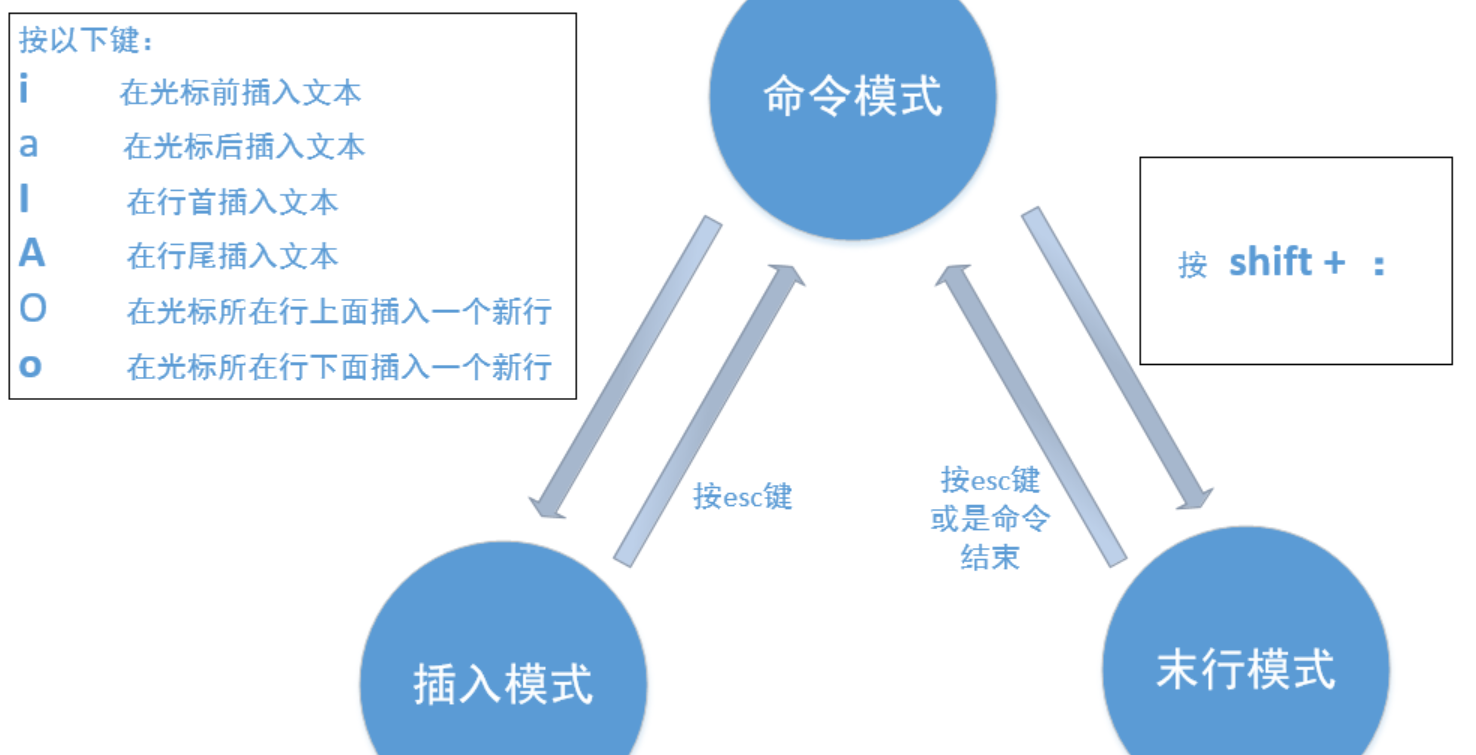
各模式的核心作用:
-
命令模式(默认模式):
- 打开
vim后默认进入该模式,无法直接输入文字; - 主要功能:移动光标、删除 / 复制文字、切换到其他模式。
- 打开
-
插入模式(编辑模式):
- 只有在该模式下才能输入文字,类似记事本的编辑状态;
- 进入方式:在命令模式下按
i(光标前插入)、a(光标后插入)、o(新行插入); - 退出方式:按
ESC键回到命令模式。
-
底行模式(命令行模式):
- 用于执行 “全局操作”,如保存文件、退出
vim、查找文字、列出行号; - 进入方式:在命令模式下按
Shift+;(即输入:); - 退出方式:按
ESC键回到命令模式。
- 用于执行 “全局操作”,如保存文件、退出
2.3 Vim 基础操作:从打开文件到保存退出
掌握了模式切换,我们先从最基础的 “打开文件 - 编辑 - 保存退出” 流程入手,熟悉vim的基本操作。
2.3.1 打开文件:启动 Vim 并指定文件
命令格式:vim [文件名]
- 如果文件存在,
vim会打开该文件; - 如果文件不存在,
vim会创建一个新文件(需保存后才会在磁盘上生成)。
实战例子:打开(或创建)test.c文件
vim test.c

执行后会进入vim的命令模式,屏幕上会显示文件内容(若为空则显示空白)。
2.3.2 编辑文件:进入插入模式输入代码
在命令模式下,按i进入插入模式(屏幕左下角会显示-- INSERT --),此时可以像记事本一样输入代码:

#include <stdio.h>int main() {printf("Hello Vim!\n");return 0;
}
输入完成后,按ESC键回到命令模式(-- INSERT --消失)。
2.3.3 保存与退出:底行模式的核心命令
回到命令模式后,按Shift+;进入底行模式,输入以下命令完成保存或退出:
| 底行命令 | 功能描述 | 场景举例 |
|---|---|---|
:w | 保存当前文件(不退出) | 编辑过程中定期保存 |
:q | 退出vim(需先保存,否则报错) | 保存后退出 |
:wq | 保存并退出vim | 编辑完成后退出 |
:q! | 强制退出vim(不保存) | 编辑错误,放弃修改 |
:w [新文件名] | 另存为新文件 | 将test.c另存为test_bak.c |
实战例子:保存test.c并退出vim
- 在命令模式下按
Shift+:进入底行模式; - 输入
wq,按回车键; vim会退出,回到 Linux 命令行,此时test.c已保存到磁盘。
2.4 命令模式核心命令:高效编辑的关键
命令模式是vim的 “核心操作区”,掌握以下命令能大幅提升编辑效率,这些命令无需进入底行模式,在命令模式下直接输入即可。
2.4.1 光标移动:精准定位代码位置
vim的光标移动命令非常丰富,除了用方向键,还可以用字母键实现更灵活的移动:
| 命令 | 功能描述 | 实战例子 |
|---|---|---|
h | 光标向左移动 1 格 | 按h一次,光标左移 1 格 |
j | 光标向下移动 1 行 | 按j一次,光标下移 1 行 |
k | 光标向上移动 1 行 | 按k一次,光标上移 1 行 |
| l | 光标向右移动 1 格 | 按l一次,光标右移 1 格 |
G | 光标跳转到文件最后一行 | 按G,直接到文件末尾 |
gg | 光标跳转到文件第一行 | 按gg,直接到文件开头 |
$ | 光标跳转到当前行的行尾 | 按$,光标到行末 |
^ | 光标跳转到当前行的行首(非空格) | 按^,光标到行首第一个字符 |
w | 光标跳转到下一个单词的开头 | 按w,从 “Hello” 跳转到 “Vim” |
e | 光标跳转到当前单词的末尾 | 按e,从 “Hel” 跳转到 “lo” |
b | 光标跳转到上一个单词的开头 | 按b,从 “Vim” 跳转到 “Hello” |
#| | 光标跳转到当前行的第 #个字符 | 按5|,光标到当前行第 5 个字符 |
小贴士:可以在命令前加 “数字” 实现 “批量操作”,比如3j表示 “向下移动 3 行”,5w表示 “向右跳 5 个单词”。
2.4.2 删除操作:快速删除文字
vim的删除命令以d为核心,配合 “范围指令” 可以删除不同长度的内容:
| 命令 | 功能描述 | 例子 |
|---|---|---|
x | 删除光标所在位置的 1 个字符 | 光标在 “a” 上,按x删除 “a” |
#x | 删除光标后 #个字符(含当前) | 按3x,删除光标后 3 个字符 |
X | 删除光标前 1 个字符 | 光标在 “a” 后,按X删除 “a” |
#X | 删除光标前 #个字符 | 按2X,删除光标前 2 个字符 |
dd | 删除光标所在的整行 | 按dd,删除当前行 |
#dd | 从当前行开始,删除 #行 | 按5dd,删除当前行及以下 4 行 |
dw | 删除从光标到下一个单词开头的内容 | 光标在 “Hel”,按dw删除 “Hel” |
d$ | 删除从光标到当前行末尾的内容 | 光标在 “Hel”,按d$删除 “Hello Vim!” |
d^ | 删除从光标到当前行开头的内容 | 光标在 “Vim”,按d^删除 “Hello” |
#:代表一个数字
例子:删除test.c中printf那一行
- 用
gg跳转到文件开头,再用j移动到printf行; - 按
dd,整行被删除。
2.4.3 复制与粘贴:复用代码片段
vim的复制命令以y为核心,粘贴命令是p,操作逻辑与删除类似:
| 命令 | 功能描述 | 实战例子 |
|---|---|---|
yw | 复制从光标到下一个单词开头的内容 | 光标在 “Hel”,按yw复制 “Hel” |
#yw | 复制 #个单词 | 按2yw,复制 2 个单词 |
yy | 复制光标所在的整行 | 按yy,复制当前行 |
#yy | 从当前行开始,复制 #行 | 按3yy,复制当前行及以下 2 行 |
p | 将复制的内容粘贴到光标后 | 复制后按p,粘贴到光标下方 |
P | 将复制的内容粘贴到光标前 | 复制后按P,粘贴到光标上方 |
#:代表一个数字
实战例子:复制printf行并粘贴到下方
- 光标移动到
printf行,按yy复制; - 按
p,复制的行会粘贴到当前行下方。
2.4.4 替换与撤销:修正编辑错误
编辑过程中难免出错,vim提供了替换和撤销命令,快速修正错误:
| 命令 | 功能描述 | 实战例子 |
|---|---|---|
r | 替换光标所在位置的 1 个字符 | 光标在 “a” 上,按r再按 “b”,将 “a” 改为 “b” |
R | 进入 “替换模式”,持续替换光标后的字符 | 按R,输入 “123”,光标后的字符会被 “123” 替换 |
u | 撤销上一次操作 | 误删一行后,按u恢复 |
Ctrl+r | 恢复被撤销的操作(反撤销) | 按u撤销后,按Ctrl+r重新执行 |
cw | 更改从光标到当前单词末尾的内容 | 光标在 “Hel”,按cw,输入 “Hi”,将 “Hello” 改为 “Hi” |
#cw | 更改 #个单词 | 按2cw,更改 2 个单词 |
例子:将printf("Hello Vim!")改为printf("Hello Linux!")
- 光标移动到 “V” 上;
- 按
cw,删除 “Vim” 并进入插入模式; - 输入 “Linux”,按
ESC回到命令模式。
2.5 底行模式核心命令:全局操作与高级功能
底行模式主要用于执行 “全局性” 操作,比如查找文字、列出行号、替换内容等,所有命令都以:开头。
2.5.1 列出行号:方便定位代码行
在调试代码时,我们常需要知道代码的行号,底行模式下输入set nu(nu=number)即可显示行号:
:set nu # 显示行号
:set nonu # 关闭行号
执行set nu后,文件每行前会显示行号,比如:

2.5.2 查找文字:快速定位关键词
在大文件中查找关键词,用/或?命令,两者的区别是查找方向不同:
| 命令格式 | 功能描述 | 操作步骤 |
|---|---|---|
/关键词 | 从光标位置向后查找关键词 | 1. 输入/printf;2. 按回车开始查找;3. 按n找下一个,N找上一个 |
?关键词 | 从光标位置向前查找关键词 | 1. 输入?main;2. 按回车开始查找;3. 按n找上一个,N找下一个 |
例子:在test.c中查找printf
- 进入底行模式,输入
/printf,按回车; - 光标会跳转到第一个
printf的位置; - 按
n,光标跳转到下一个printf(若只有一个则无反应)。
2.5.3 替换内容:批量修改关键词
底行模式的替换命令格式为:%s/旧关键词/新关键词/[选项],其中:
%表示 “整个文件”;s表示 “替换”;- 选项:
g(全局替换,不加则只替换每行第一个匹配项)、c(替换前确认)。
常用替换命令:
| 命令格式 | 功能描述 | 实战例子 |
|---|---|---|
:%s/旧/新/g | 整个文件全局替换旧关键词为新关键词 | :%s/Vim/Linux/g,将所有 “Vim” 改为 “Linux” |
:%s/旧/新/gc | 全局替换,每次替换前确认 | :%s/Hello/Hi/gc,替换前会提示 “是否替换” |
:行号1,行号2s/旧/新/g | 替换指定行范围内的关键词 | :3,5s/printf/puts/g,替换 3-5 行的 “printf” 为 “puts” |
例子:将test.c中所有 “Hello” 改为 “Hi”
- 进入底行模式,输入
:%s/Hello/Hi/g; - 按回车,
vim会提示 “替换了 1 处”(因文件中只有一个 “Hello”)。
2.5.4 跳转到指定行:快速定位行号
如果知道目标行号,底行模式下直接输入行号即可跳转:
:10 # 跳转到第10行
:5 # 跳转到第5行
配合set nu使用,能快速定位到需要修改的代码行。
2.6 Vim 配置:打造个性化编辑环境
默认的vim配置比较简陋(无语法高亮、缩进不统一),我们可以通过修改配置文件,让vim更符合自己的使用习惯。vim的配置文件分为两种:系统级配置和用户级配置。
2.6.1 配置文件的位置(可以再Git上去找别人已经配置好的文件)
- 系统级配置:
/etc/vimrc,对所有用户生效,修改需root权限; - 用户级配置:
~/.vimrc(~表示当前用户的主目录),只对当前用户生效,普通用户即可修改。
推荐修改用户级配置(避免影响其他用户),如果~/.vimrc不存在,直接创建即可:
vim ~/.vimrc
2.6.2 常用配置选项:基础优化
在~/.vimrc中添加以下配置,能大幅提升vim的使用体验,每一行配置后都有注释说明:
" 语法高亮(打开后代码会按语法显示不同颜色)
syntax on" 显示行号
set nu" 设置缩进为4个空格(开发C/C++常用)
set shiftwidth=4" 按Tab键时,实际插入4个空格(避免Tab键在不同编辑器中显示不一致)
set expandtab
set tabstop=4" 光标行高亮(当前光标所在行显示背景色,方便定位)
set cursorline" 搜索时忽略大小写(输入“printf”和“PRINTF”都能找到)
set ignorecase" 搜索时实时显示匹配结果(输入关键词时,实时高亮匹配项)
set incsearch" 自动缩进(新行的缩进与上一行保持一致,写代码时很有用)
set autoindent" 显示光标位置(在状态栏显示当前光标所在的行号和列号)
set ruler" 启用鼠标支持(在终端中也能用鼠标移动光标、选择文字)
set mouse=a
添加完成后,保存~/.vimrc并退出,下次打开vim时,配置会自动生效。
2.6.3 插件扩展:增强 Vim 功能
原生vim的功能有限,通过安装插件可以实现 “文件浏览器”“代码标签” 等高级功能。这里介绍两个常用插件的安装方法:
插件 1:TagList(代码标签列表)
TagList 能在vim中显示代码的函数、变量列表,方便快速跳转。安装步骤如下:
-
下载 TagList 插件:目前 TagList 插件可从 Vim 官方脚本网站获取,其下载地址为taglist.vim - Source code browser (supports C/C++, java, perl, python, tcl, sql, php, etc) : vim online
 http://www.vim.org/scripts/script.php?script_id=273该网站提供的版本相对较新,能适配当前 Vim 的发展,具备更好的稳定性和功能性。
http://www.vim.org/scripts/script.php?script_id=273该网站提供的版本相对较新,能适配当前 Vim 的发展,具备更好的稳定性和功能性。 -
解压插件到指定目录:
vim插件需要放在~/.vim目录下(若不存在则创建):mkdir -p ~/.vim/doc ~/.vim/plugin # 创建插件存放目录 unzip taglist_xxx.zip -d ~/.vim # 将插件解压到~/.vim目录解压后,
~/.vim/doc目录下会出现taglist.txt等帮助文件,~/.vim/plugin目录下会有taglist.vim脚本文件。 -
配置 TagList:
在~/.vimrc中添加以下配置:" TagList配置:只显示当前文件的标签 let Tlist_Show_One_File=1 " 关闭TagList窗口时,同时关闭vim(若只有TagList一个窗口) let Tlist_Exit_OnlyWindow=1 " TagList窗口显示在右侧 let Tlist_Use_Right_Window=1 -
使用 TagList:
打开一个 C 文件(如test.c),在命令模式下输入:Tlist,右侧会显示代码的标签列表(如main函数),光标移动到标签上按回车,即可跳转到对应的代码位置。
插件 2:WinManager(文件浏览器 + 窗口管理)
WinManager 能整合 “文件浏览器” 和 “TagList”,在vim中同时显示文件目录和代码标签。安装步骤如下:
-
下载 WinManager 插件:
下载winmanager.zip(2.X 版本以上)。 -
解压插件到指定目录:
unzip winmanager.zip -d ~/.vim -
配置 WinManager:
在~/.vimrc中添加以下配置:" WinManager窗口布局:左侧显示文件浏览器,右侧显示TagList let g:winManagerWindowLayout='FileExplorer|TagList' " 快捷键:在命令模式下按“wm”打开/关闭WinManager nmap wm :WMToggle<cr> -
使用 WinManager:
打开test.c,在命令模式下输入wm,左侧会显示文件浏览器(当前目录的文件列表),右侧显示 TagList,再次输入wm可关闭。
2.7 Vim 操作实战:编辑一个完整的 C 程序
通过一个实战例子,巩固前面学到的vim操作:编写一个计算 1 到 100 求和的 C 程序sum.c。
步骤 1:打开 Vim 并创建文件
vim sum.c
步骤 2:进入插入模式输入代码
在命令模式下按i,输入以下代码:
#include <stdio.h>// 计算从s到e的和
int sum(int s, int e) {int result = 0;for (int i = s; i <= e; i++) {result += i;}return result;
}int main() {int start = 1;int end = 100;int total = sum(start, end);printf("Sum from %d to %d is: %d\n", start, end, total);return 0;
}
步骤 3:保存并退出
按ESC回到命令模式,按Shift+;进入底行模式,输入wq保存退出。
步骤 4:重新打开文件,进行修改
vim sum.c
- 按
gg跳转到文件开头,按j移动到sum函数; - 按
dd删除sum函数的注释行(// 计算从s到e的和); - 按
u撤销删除,恢复注释行; - 进入底行模式,输入
:%s/sum/Sum/g,将所有小写sum改为大写Sum; - 输入
:wq保存退出。
三、GCC/G++ 编译器:将代码转化为可执行程序
编写完代码后,需要通过编译器将人类可读的源代码(如.c/.cpp文件)转化为计算机可执行的二进制文件。在 Linux 下,C 语言常用gcc编译器,C++ 常用g++编译器,两者操作逻辑一致,核心是掌握 “编译四步骤” 与常用选项。
3.1 编译的四个核心步骤
无论是gcc还是g++,编译过程都分为四个步骤:预处理、编译、汇编、链接。每个步骤对应不同的功能,生成不同的中间文件,最终输出可执行程序。
我们以sum.c(前面编写的求和程序)为例,一步步拆解每个步骤的作用。
3.1.1 预处理:展开代码,处理宏与注释
作用:
- 展开
#include头文件(比如将stdio.h的内容插入到sum.c中); - 处理
#define宏定义(替换宏名为宏值); - 去除代码中的注释(
//和/* */注释会被删除); - 处理条件编译(如
#if/#else/#endif)。
gcc 选项:-E(只执行预处理,不进行后续步骤),-o(指定输出文件名,预处理后的文件通常以.i为后缀)。
实战命令:
gcc -E sum.c -o sum.i

查看结果:执行后生成sum.i文件,用cat sum.i查看,会发现文件开头有大量stdio.h的内容(头文件展开),注释已被删除,宏(若有的话)已被替换。
3.1.2 编译:将预处理代码转化为汇编指令
作用:
- 对预处理后的
.i文件进行语法检查(若有语法错误,会在此步骤报错); - 将 C 代码转化为对应的汇编语言指令(
.s文件)。
gcc 选项:-S(只执行预处理和编译,不进行汇编),输出文件以.s为后缀。
实战命令:
gcc -S sum.i -o sum.s
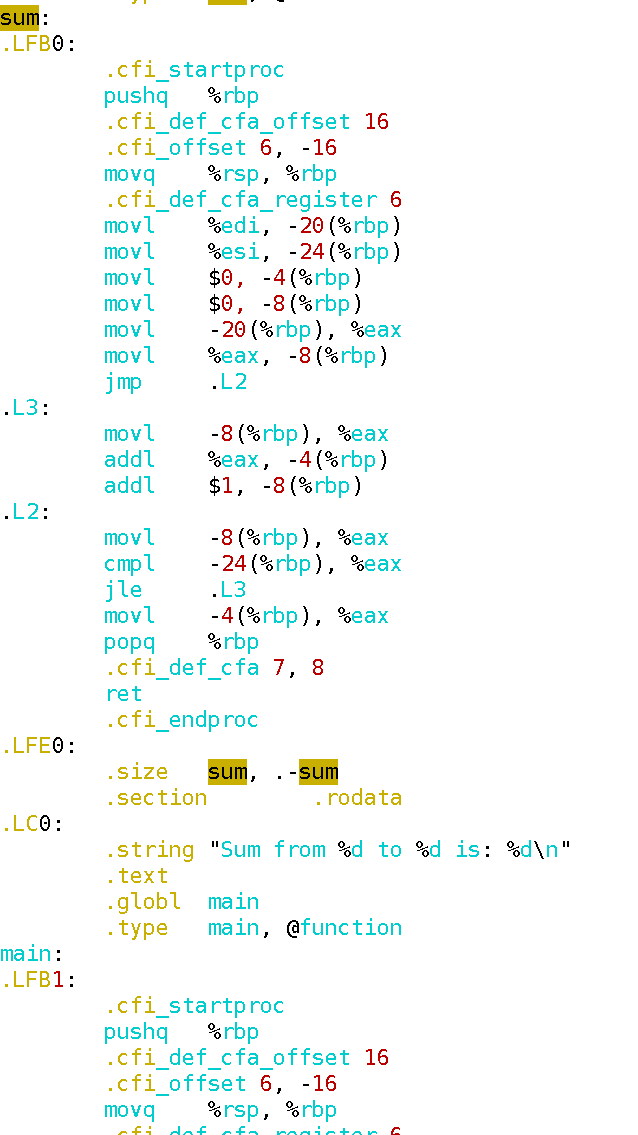
查看结果:生成sum.s文件,用vim sum.s查看,内容是汇编指令,比如:
3.1.3 汇编:将汇编指令转化为二进制目标代码
作用:
- 将汇编语言
.s文件转化为计算机可识别的二进制目标代码(.o文件); - 此时的
.o文件是 “可重定位目标文件”,还不能直接执行(缺少依赖库)。
gcc 选项:-c(执行预处理、编译、汇编,不进行链接),输出文件以.o为后缀。
实战命令:
gcc -c sum.s -o sum.o
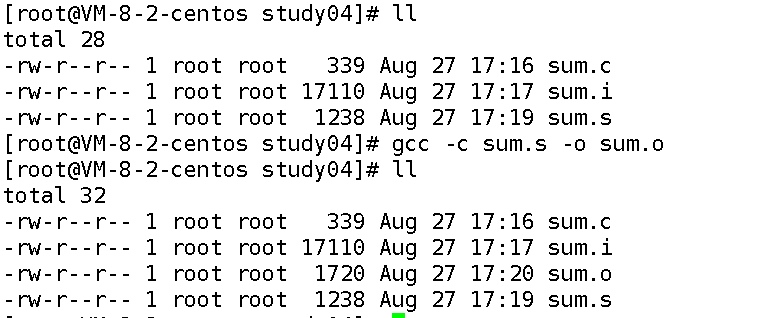
查看结果:生成sum.o文件,用file sum.o查看文件类型,会显示 “ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV)”,表示这是 64 位的可重定位目标文件。
3.1.4 链接:将目标文件与库文件结合,生成可执行程序
作用:
- 将
.o目标文件与系统库文件(如libc.so,包含printf等函数的实现)链接起来; - 解决函数依赖(比如
sum.c中调用了printf,链接时会找到libc.so中的printf实现); - 生成最终的可执行程序(无后缀,Linux 下可执行文件通常无后缀)。
gcc 选项:无特殊选项(默认执行链接),-o指定可执行程序名。
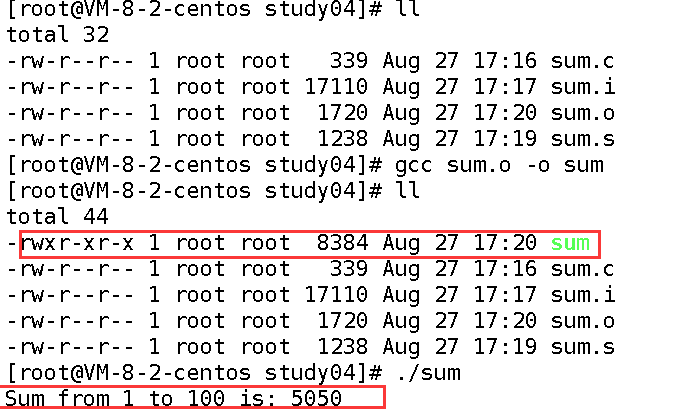
实战命令:
gcc sum.o -o sum
查看结果:生成sum可执行程序,用./sum运行,输出结果:
./sum
Sum from 1 to 100 is: 5050
3.2 一键编译:跳过中间步骤
实际开发中,我们不需要手动执行四个步骤,gcc支持 “一键编译”,直接从.c文件生成可执行程序:
命令格式:gcc [源文件] -o [可执行程序名]
实战例子:直接编译sum.c生成sum
gcc sum.c -o sum
这条命令会自动执行 “预处理 - 编译 - 汇编 - 链接” 四个步骤,省略中间文件(.i/.s/.o)的生成,直接输出可执行程序。
3.3 动态链接与静态链接:程序运行的两种依赖方式
在链接步骤中,gcc默认使用动态链接,但也支持静态链接。两者的核心区别在于 “是否将库文件的代码嵌入可执行程序”,这会影响程序的大小、运行速度和可移植性。
3.3.1 动态链接(默认)
原理:动态链接时,gcc不会将库文件(如libc.so)的代码嵌入可执行程序,而是在程序运行时,由系统的 “动态链接器” 加载库文件到内存中,供程序调用。
特点:
- 可执行程序体积小(只包含自己的代码,不包含库代码);
- 多个程序可共享同一个库文件(比如多个程序都调用
printf,只需加载一次libc.so),节省内存; - 程序运行时依赖系统中的库文件(若系统中没有对应的库,程序会报错 “找不到库文件”)。
验证动态链接:用ldd命令查看可执行程序依赖的动态库:
ldd sum# 输出结果(关键部分)
linux-vdso.so.1 => (0x00007fffeb1ab000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff776af5000) # 依赖libc.so.6
/lib64/ld-linux-x86-64.so.2 (0x00007ff776ec3000)

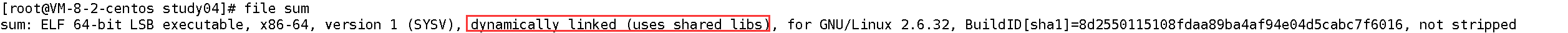
可以看到,sum依赖系统的libc.so.6动态库。
3.3.2 静态链接
原理:静态链接时,gcc会将库文件的代码完整嵌入到可执行程序中,程序运行时不再依赖外部库文件。(有些系统可能没有安装静态库,需要自己安装:sudo yum/apt install -y glibc-static)
gcc 选项:-static(指定静态链接:gcc sum.c -o sum_static -static)。
实战命令:静态编译sum.c
特点:
- 可执行程序体积大(包含库代码,比如
sum_static会比sum大很多); - 程序运行时不依赖外部库(可移植性强,复制到其他 Linux 系统即可运行);
- 多个程序会重复包含同一库代码,浪费磁盘和内存空间;
- 库文件更新后,需要重新编译程序才能使用新库(动态链接只需更新库文件)。
验证静态链接:用ldd查看sum_static,会提示 “不是动态可执行文件”:
ldd sum_staticnot a dynamic executable
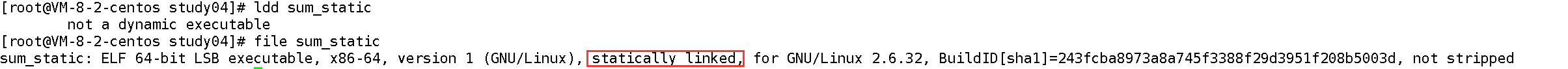
3.3.3 两种链接方式的对比
| 对比维度 | 动态链接(默认) | 静态链接(-static) |
|---|---|---|
| 程序体积 | 小 | 大 |
| 运行依赖 | 依赖系统库文件 | 不依赖外部库 |
| 内存占用 | 多个程序共享库,节省内存 | 每个程序单独加载库,占用内存多 |
| 可移植性 | 差(需目标系统有对应库) | 好(复制即可运行) |
| 库更新 | 无需重新编译程序 | 需重新编译程序 |
| 适用场景 | 日常开发、服务器程序 | 嵌入式设备、无依赖环境的程序 |
3.4 GCC 常用选项:优化、调试与警告
除了前面提到的-E/-S/-c/-o/-static,gcc还有很多实用选项,用于调试、优化代码和生成警告信息。
3.4.1 调试选项:生成调试信息(供 GDB 使用)
如果需要用gdb调试程序,必须在编译时添加-g选项,生成调试信息(包含代码行号、变量信息等)。
命令格式:gcc -g [源文件] -o [可执行程序名]
实战例子:编译sum.c并生成调试信息
gcc -g sum.c -o sum_debug
验证调试信息:用file命令查看sum_debug,会显示 “with debug_info”:
file sum_debug
sum_debug: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, with debug_info, not stripped
3.4.2 优化选项:提升程序运行效率
gcc提供四个优化级别,通过-O0/-O1/-O2/-O3指定(O是大写字母 O,不是数字 0):
-O0:无优化(默认,编译速度快,适合调试);-O1:基础优化(优化代码大小和运行速度,编译时间适中);-O2:高级优化(比-O1更全面,优化循环、函数内联等,推荐日常使用);-O3:最高级优化(在-O2基础上增加更多优化,如循环展开,可能导致程序体积增大)。
实战例子:用-O2优化编译sum.c
gcc -O2 sum.c -o sum_opt
优化效果:sum_opt的运行速度会比未优化的sum快(对于简单程序可能不明显,但复杂程序效果显著)。
3.4.3 警告选项:提前发现代码隐患
gcc的警告选项能帮助我们发现代码中的潜在问题(如未使用变量、类型不匹配等),常用选项:
-w:关闭所有警告(不推荐);-Wall:开启所有常用警告(推荐,能发现大部分潜在问题);-Werror:将警告视为错误(只要有警告,编译就会失败,强制修正所有问题)。
实战例子:开启所有警告编译sum.c
gcc -Wall sum.c -o sum_warn
效果:如果代码中有未使用的变量,gcc会输出警告信息,比如:
sum.c: In function ‘main’:
sum.c:12:9: warning: unused variable ‘x’ [-Wunused-variable]int x = 0;^
3.4.4 其他常用选项
| 选项 | 功能描述 | 实战例子 |
|---|---|---|
-std=c99 | 指定 C 语言标准(如 C99、C11) | gcc -std=c99 sum.c -o sum |
-I[目录] | 指定头文件搜索目录(非标准目录) | gcc -I./include sum.c -o sum(从./include 目录找头文件) |
-L[目录] | 指定库文件搜索目录(非标准目录) | gcc sum.o -L./lib -lm -o sum(从./lib 目录找库文件) |
-l[库名] | 链接指定的库文件 | gcc math.c -o math -lm(链接数学库 libm.so) |
3.5 G++ 编译器:C++ 程序的编译工具(与gcc用法类似)
g++是 C++ 程序的编译器,操作逻辑与gcc完全一致,唯一区别是g++会自动链接 C++ 标准库(libstdc++.so),而gcc编译 C++ 程序时需要手动链接(如果后缀为*.cpp,则不是必须;只有后缀是*.c,内容为C++的代码,就必须手动链接)。
实战例子 1:编译 C++ 程序hello.cpp
// hello.cpp
#include <iostream>
using namespace std;int main() {cout << "Hello C++!" << endl;return 0;
}
用 g++ 编译:
g++ hello.cpp -o hello_cpp
./hello_cpp # 运行
Hello C++!
用 gcc 编译 C++ 程序(需手动链接 C++ 标准库):
//hello.cpp
gcc hello.cpp -o hello_cpp_gcc
./hello_cpp_gcc
Hello C++!//hello.c
gcc hello.cc -o hello_c_gcc -libstdc++.so
./hello_cpp_gcc
Hello C++!四、Makefile:自动化构建项目的 “脚本”
当项目只有 1-2 个源文件时,用gcc手动编译没问题;但如果项目有几十个甚至上百个源文件,手动输入gcc命令会非常繁琐(比如要指定所有源文件、头文件目录、库文件)。此时,Makefile就派上用场了 —— 它是一个 “自动化构建脚本”,定义了源文件的依赖关系和编译命令,只需执行make命令,就能自动完成整个项目的编译。
4.1 为什么需要 Makefile?
举个例子:假设我们有一个项目,包含main.c、sum.c、sum.h三个文件:
sum.h:声明sum函数;sum.c:实现sum函数;main.c:调用sum函数。
如果手动编译,需要执行:
gcc -c sum.c -o sum.o
gcc -c main.c -o main.o
gcc sum.o main.o -o app
如果后续修改了sum.c,需要重新编译sum.o和app;如果修改了sum.h,需要重新编译sum.o、main.o和app—— 手动操作很容易遗漏,导致程序运行错误。
而 Makefile 能解决这些问题:
- 自动识别 “哪些文件被修改过”,只重新编译修改过的文件及其依赖;
- 只需执行
make命令,自动完成所有编译步骤; - 支持 “项目清理”,只需执行
make clean,就能删除所有编译生成的文件。
4.2 Makefile 的基本语法:依赖关系与依赖方法
Makefile 的核心是 “规则”,每个规则由三部分组成:目标(Target)、依赖(Prerequisites)、依赖方法(Commands),语法格式如下:
目标: 依赖1 依赖2 ...依赖方法(命令)...
- 目标:要生成的文件(如
app、sum.o),或 “伪目标”(如clean,不是实际文件,只是一个命令标签); - 依赖:生成目标需要的文件(如生成
app需要sum.o和main.o); - 依赖方法:生成目标的命令(如
gcc sum.o main.o -o app),必须以Tab 键开头(不能用空格)。
4.3 简单 Makefile 实战:编译多文件项目
以刚才的main.c+sum.c+sum.h项目为例,编写第一个 Makefile。
4.3.1 项目文件结构
project/
├── main.c
├── sum.c
├── sum.h
└── Makefile # 我们要编写的文件
4.3.2 编写 Makefile
在project目录下创建Makefile(文件名首字母大写,或小写makefile,make命令会优先找大写的):
# 目标:app(最终可执行程序),依赖:sum.o main.o
app: sum.o main.ogcc sum.o main.o -o app # 生成app的命令(Tab开头)# 目标:sum.o,依赖:sum.c sum.h
sum.o: sum.c sum.hgcc -c sum.c -o sum.o # 生成sum.o的命令# 目标:main.o,依赖:main.c sum.h(main.c包含sum.h,所以依赖sum.h)
main.o: main.c sum.hgcc -c main.c -o main.o # 生成main.o的命令# 伪目标:clean,用于清理编译生成的文件
.PHONY: clean
clean:rm -f app sum.o main.o # 删除app、sum.o、main.o(Tab开头)
4.3.3 使用 Makefile 编译项目
-
首次编译:在
project目录下执行make命令,make会自动执行 Makefile 中的规则:cd project make# 输出结果(按依赖关系执行命令) gcc -c sum.c -o sum.o gcc -c main.c -o main.o gcc sum.o main.o -o app执行后生成
sum.o、main.o、app三个文件。 -
运行程序:
./app Sum from 1 to 100 is: 5050 -
修改文件后重新编译:比如修改
sum.c中的求和逻辑,再执行make:# 修改sum.c后执行make make# 输出结果(只重新编译修改过的sum.o和app) gcc -c sum.c -o sum.o gcc sum.o main.o -o appmake会对比 “目标文件” 和 “依赖文件” 的修改时间:如果依赖文件的修改时间比目标文件新,就重新执行依赖方法生成目标文件。 -
清理项目:执行
make clean,删除编译生成的文件:make clean# 输出结果 rm -f app sum.o main.o
4.3.4 伪目标(.PHONY)的作用
在上面的 Makefile 中,clean是一个 “伪目标”,用.PHONY: clean声明。伪目标的核心特点是:
- 它不是一个实际存在的文件(
clean不会生成名为clean的文件); - 执行
make clean时,make会忽略 “是否存在clean文件”,直接执行rm -f ...命令。
如果不声明.PHONY: clean,当目录下存在名为clean的文件时,make clean会报错:“make: clean' is up to date.”,因为make会认为“clean文件已存在,且没有依赖,无需执行”。因此,所有“非文件目标”(如clean、test)都应该用.PHONY声明(意思就是被声明成伪目标后会一直执行)。
4.4 Makefile 的推导过程:自动寻找依赖
make有一个强大的特性:自动推导规则。对于.o目标文件,make会自动推导其依赖的.c文件和编译命令,无需手动编写。
比如,我们可以简化前面的 Makefile,删除sum.o和main.o的规则:
# 简化后的Makefile
app: sum.o main.ogcc sum.o main.o -o app# 无需手动编写sum.o和main.o的规则,make会自动推导
.PHONY: clean
clean:rm -f app sum.o main.o
执行make,make会自动推导:
- 生成
sum.o需要sum.c,编译命令是gcc -c sum.c -o sum.o; - 生成
main.o需要main.c,编译命令是gcc -c main.c -o main.o。
推导结果与之前完全一致,这大大简化了 Makefile 的编写,尤其适合源文件多的项目。
4.5 Makefile 语法扩展:变量、函数与自动变量
当项目源文件增多时,手动写所有源文件名会很繁琐。Makefile 支持变量、函数和自动变量,能进一步简化脚本,让 Makefile 更灵活、可维护。
4.5.1 变量:统一管理文件名与编译选项
Makefile 中的变量类似编程语言的变量,用于存储重复出现的内容(如源文件名、编译选项),格式为变量名=值,引用变量时用$(变量名)。
实战例子:用变量简化 Makefile
# 定义变量:可执行程序名
BIN = app# 定义变量:源文件列表(所有.c文件)
SRC = sum.c main.c# 定义变量:目标文件列表(将SRC中的.c替换为.o)
OBJ = $(SRC:.c=.o)# 定义变量:编译器
CC = gcc# 定义变量:编译选项(开启警告、调试信息)
CFLAGS = -Wall -g# 目标:$(BIN),依赖:$(OBJ)
$(BIN): $(OBJ)$(CC) $(OBJ) -o $(BIN) # 引用变量# 伪目标:clean
.PHONY: clean
clean:rm -f $(BIN) $(OBJ) # 引用变量
优点:
- 如果需要修改可执行程序名,只需改
BIN = app为BIN = myapp; - 如果新增源文件(如
add.c),只需改SRC = sum.c main.c add.c; - 编译选项统一管理,如需添加优化,只需改
CFLAGS = -Wall -g -O2。
4.5.2 函数:动态获取文件列表
Makefile 提供了一些内置函数,用于动态处理文件列表,最常用的是wildcard函数 —— 它能获取指定目录下的所有匹配文件。
比如,项目中有多个.c文件,用wildcard *.c可以自动获取所有.c文件,无需手动列出:
# 用wildcard函数获取当前目录下所有.c文件
SRC = $(wildcard *.c)# 目标文件列表:将所有.c替换为.o
OBJ = $(SRC:.c=.o)# 其他变量与规则不变
BIN = app
CC = gcc
CFLAGS = -Wall -g$(BIN): $(OBJ)$(CC) $(OBJ) -o $(BIN).PHONY: clean
clean:rm -f $(BIN) $(OBJ)
如果项目新增add.c,SRC会自动包含add.c,OBJ会自动包含add.o,无需修改 Makefile。
4.5.3 自动变量:简化依赖方法
Makefile 提供了自动变量,用于指代规则中的 “目标”“依赖” 等,避免重复书写。常用的自动变量如下:
| 自动变量 | 含义 | 适用场景 |
|---|---|---|
$@ | 规则中的 “目标” 文件名 | 生成目标文件时引用 |
$^ | 规则中的 “所有依赖” 文件名 | 链接时引用所有依赖文件 |
$< | 规则中的 “第一个依赖” 文件名 | 编译时引用单个源文件 |
实战例子:用自动变量简化 Makefile
BIN = app
SRC = $(wildcard *.c)
OBJ = $(SRC:.c=.o)
CC = gcc
CFLAGS = -Wall -g# $@ = app,$^ = sum.o main.o
$(BIN): $(OBJ)$(CC) $^ -o $@ # 等价于 gcc sum.o main.o -o app# 手动编写.o规则,用自动变量$@和$<
# $@ = sum.o(或main.o),$< = sum.c(或main.c)
%.o: %.c$(CC) $(CFLAGS) -c $< -o $@ # 等价于 gcc -Wall -g -c sum.c -o sum.o.PHONY: clean
clean:rm -f $(BIN) $(OBJ)
这里的%.o: %.c是 “模式规则”,%是通配符,表示 “所有.o文件依赖对应的.c文件”,配合自动变量$@和$<,实现了所有.o文件的编译。
4.6 复杂 Makefile 实战:多目录项目
实际项目中,源文件通常按功能放在不同目录(如src放源文件,include放头文件,obj放目标文件)。下面以一个多目录项目为例,编写更贴近实际开发的 Makefile。
4.6.1 项目文件结构
complex_project/
├── include/ # 头文件目录
│ └── sum.h
├── src/ # 源文件目录
│ ├── main.c
│ └── sum.c
├── obj/ # 目标文件目录(存放.o)
└── Makefile # 主Makefile
4.6.2 编写 Makefile
# 1. 定义变量
# 可执行程序名
BIN = app
# 目录定义(使用绝对路径或相对路径,这里用相对路径)
SRC_DIR = ./src # 源文件目录
INC_DIR = ./include # 头文件目录
OBJ_DIR = ./obj # 目标文件目录
# 源文件列表(获取src目录下所有.c文件)
SRC = $(wildcard $(SRC_DIR)/*.c)
# 目标文件列表(将src/xxx.c转换为obj/xxx.o)
OBJ = $(patsubst $(SRC_DIR)/%.c, $(OBJ_DIR)/%.o, $(SRC))
# 编译器与选项
CC = gcc
# 编译选项:-I指定头文件目录,-Wall开启警告,-g生成调试信息
CFLAGS = -I$(INC_DIR) -Wall -g
# 链接选项(此处无特殊链接需求,暂为空)
LFLAGS = # 2. 主规则:生成可执行程序
$(BIN): $(OBJ)$(CC) $(OBJ) -o $(BIN) $(LFLAGS)@echo "Build success! Executable: $(BIN)" # @开头的命令不回显# 3. 模式规则:生成目标文件(obj/xxx.o依赖src/xxx.c和include下的头文件)
$(OBJ_DIR)/%.o: $(SRC_DIR)/%.c# 先判断obj目录是否存在,不存在则创建@if [ ! -d $(OBJ_DIR) ]; then mkdir -p $(OBJ_DIR); fi$(CC) $(CFLAGS) -c $< -o $@@echo "Compiled $< -> $@"# 4. 伪目标:清理项目
.PHONY: clean
clean:rm -rf $(OBJ_DIR) $(BIN) //-rf 用于强制删除目录($(OBJ_DIR)),//-f 用于强制删除文件 ($(BIN)),避免误删时提示确认@echo "Clean success! Removed: $(OBJ_DIR) $(BIN)"# 5. 伪目标:测试(可选,用于验证变量是否正确)
.PHONY: test
test:@echo "SRC: $(SRC)"@echo "OBJ: $(OBJ)"@echo "INC_DIR: $(INC_DIR)"
4.6.3 编译与测试
-
首次编译:在
complex_project目录下执行make:cd complex_project make# 输出结果 Compiled ./src/sum.c -> ./obj/sum.o Compiled ./src/main.c -> ./obj/main.o gcc ./obj/sum.o ./obj/main.o -o app Build success! Executable: app执行后,
obj目录会自动创建,里面生成sum.o和main.o,根目录生成app。 -
验证变量(可选):执行
make test,查看变量是否正确:make test# 输出结果 SRC: ./src/main.c ./src/sum.c OBJ: ./obj/main.o ./obj/sum.o INC_DIR: ./include -
运行程序:
./app Sum from 1 to 100 is: 5050 -
清理项目:执行
make clean:make clean# 输出结果 rm -rf ./obj app Clean success! Removed: ./obj app
4.7 Makefile 的工作原理:从 “找目标” 到 “执行命令”
很多人用 Makefile 只知道 “执行make就会编译”,但不了解其背后的工作逻辑。make的工作过程可以分为 7 个步骤,理解这些步骤能帮助我们排查 Makefile 的错误。
-
寻找 Makefile 文件:
make会在当前目录下查找名为Makefile或makefile的文件,如果找不到,会报错 “make: *** No targets specified and no makefile found. Stop.”。 -
确定终极目标:
make会将 Makefile 中第一个规则的目标作为 “终极目标”(通常是可执行程序,如app),所有操作都是为了生成这个终极目标。 -
检查目标与依赖的关系:
make会检查终极目标是否存在:- 如果终极目标不存在,执行依赖方法生成它;
- 如果终极目标存在,对比 “终极目标的修改时间” 和 “所有依赖文件的修改时间”:
- 若任一依赖文件的修改时间比终极目标新,重新执行依赖方法生成终极目标;
- 若所有依赖文件的修改时间都比终极目标旧,说明终极目标已 “最新”,无需执行任何命令。
-
递归检查依赖文件:如果终极目标的依赖文件(如
sum.o)不存在,make会在 Makefile 中寻找以该依赖文件为目标的规则,重复步骤 3,直到找到所有 “最底层依赖”(通常是.c/.h文件,这些文件由用户维护,make默认认为它们存在)。 -
执行依赖方法:当所有依赖文件都准备就绪(存在且最新),
make会按规则顺序执行依赖方法,生成目标文件。 -
处理错误:如果在执行依赖方法时出现错误(如语法错误导致编译失败),
make会立即停止,不再执行后续命令。 -
完成终极目标:当所有规则执行完毕,终极目标生成,
make退出。
4.8 Makefile 常见问题与解决方法
4.8.1 问题 1:依赖方法前用空格,导致 “*** missing separator. Stop.”
错误现象:
Makefile:2: *** missing separator. Stop.
原因:依赖方法必须以Tab 键开头,不能用空格(make对缩进格式要求严格)。
解决方法:将依赖方法前的空格替换为 Tab 键。在vim中,可以按Ctrl+v再按Tab插入一个可见的 Tab 字符,避免与空格混淆。
4.8.2 问题 2:伪目标未声明,导致 “make: `clean' is up to date.”
错误现象:
make: `clean' is up to date.
原因:目录下存在名为clean的文件,make将其视为 “目标文件”,且该文件没有依赖,因此认为 “已最新,无需执行”。
解决方法:在 Makefile 中用.PHONY: clean声明clean为伪目标,即使存在clean文件,make也会执行对应的命令。
4.8.3 问题 3:头文件修改后,源文件未重新编译
错误现象:修改了sum.h,执行make,make提示 “make: app' is up to date.”,未重新编译sum.o和main.o。
原因:Makefile 中sum.o和main.o的规则未添加sum.h作为依赖,make不知道 “头文件修改会影响源文件编译”。
解决方法:在.o目标的依赖中添加对应的头文件,例如:
sum.o: sum.c include/sum.hgcc -Iinclude -c sum.c -o sum.o
或在模式规则中通过-MMD选项自动生成依赖(进阶用法,需配合include命令,此处暂不展开)。
4.8.4 问题 4:新增源文件后,Makefile 未自动识别
错误现象:新增add.c,执行make,make未编译add.o,链接时提示 “undefined reference to `add'”。
原因:SRC变量未包含add.c,如果SRC是手动列出的(如SRC = sum.c main.c),新增文件后需要手动添加;如果用SRC = $(wildcard src/*.c),则可能是路径错误。
解决方法:
- 若用
wildcard函数,检查路径是否正确(如src/*.c是否包含新增文件); - 若手动列出,在
SRC中添加新增文件(如SRC = sum.c main.c add.c)。
五、Linux 第一个系统程序:进度条的实现与原理
掌握了编辑、编译、构建工具后,我们可以动手编写第一个 Linux 系统程序 ——进度条。进度条看似简单,却涉及 “行缓冲区”“回车与换行的区别”“终端输出控制” 等 Linux 系统编程的基础概念,通过实现进度条,能帮助我们更深入理解 Linux 的 IO 机制。
5.1 基础概念:回车与换行的区别
在编写进度条前,首先要理清 “回车”(\r)和 “换行”(\n)的区别 —— 很多人误以为两者是同一个功能,实则不然,这是从老式打字机继承下来的设计。
- 换行(
\n,Line Feed):将光标垂直向下移动一行,但光标水平位置不变; - 回车(
\r,Carriage Return):将光标水平移动到当前行的开头,但光标垂直位置不变。
在 Windows 系统中,\n会同时实现 “换行 + 回车” 的功能;但在 Linux 系统中,\n只表示换行,\r只表示回车,两者需要配合使用才能实现 “光标移动到下一行开头” 的效果(实际开发中,\n在 Linux 终端中会默认触发回车,但在缓冲区控制场景下,必须明确区分)。
举个例子:执行以下代码,观察输出效果:
#include <stdio.h>
#include <unistd.h>int main() {printf("Hello\r"); // 输出Hello后,光标回到行首sleep(1);printf("World\n"); // 输出World,覆盖Hello,然后换行return 0;
}
编译运行后,屏幕会先显示Hello,1 秒后Hello被World覆盖,最终输出World—— 这就是\r的 “覆盖当前行” 功能,也是进度条实现的核心原理。
5.2 关键机制:行缓冲区与刷新
Linux 下的标准输出(stdout,对应printf)默认是 “行缓冲” 模式,即:
- 当输出内容中包含
\n时,缓冲区会立即刷新,内容显示到终端; - 当输出内容中不包含
\n时,内容会暂存到缓冲区,直到缓冲区满(约 4096 字节)或程序退出,才会刷新到终端。
这个机制会影响进度条的显示效果,我们通过三个实验来验证:
实验 1:包含\n,缓冲区立即刷新
#include <stdio.h>
#include <unistd.h>int main() {printf("Hello Linux!\n"); // 包含\nsleep(3); // 睡眠3秒return 0;
}
现象:程序运行后,立即显示Hello Linux!,然后睡眠 3 秒退出。
原因:\n触发行缓冲区刷新,内容立即显示。
实验 2:不包含\n,缓冲区未刷新
#include <stdio.h>
#include <unistd.h>int main() {printf("Hello Linux!"); // 不包含\nsleep(3); // 睡眠3秒return 0;
}
现象:程序运行后,先睡眠 3 秒,退出时才显示Hello Linux!。
原因:无\n,内容暂存缓冲区,程序退出时才刷新。
实验 3:不包含\n,手动刷新缓冲区
#include <stdio.h>
#include <unistd.h>int main() {printf("Hello Linux!"); // 不包含\n//stdout 缓冲模式依赖输出目标:终端输出为行缓冲(\n 触发刷新),//文件输出为全缓冲(需 fflush 或缓冲区满才刷新)//进度条若需支持重定向,必须添加 fflush(stdout)fflush(stdout); sleep(3); // 睡眠3秒return 0;
}
现象:程序运行后,立即显示Hello Linux!,然后睡眠 3 秒退出。
原因:fflush(stdout)强制刷新缓冲区,内容立即显示。
进度条需要 “实时更新当前行的进度”,不能换行,因此必须用\r回到行首,同时用fflush(stdout)手动刷新缓冲区,确保进度实时显示。
5.3 练手:实现一个简单的倒计时程序
在编写进度条前,先通过 “倒计时程序” 熟悉\r和fflush的使用,功能是:从 10 倒计时到 0,每秒更新一次,倒计时过程中不换行,数字覆盖显示。
5.3.1 倒计时代码
#include <stdio.h>
#include <unistd.h> // 包含sleep函数int main() {int i = 10; // 从10开始倒计时while (i >= 0) {// %-2d:左对齐,占2个字符宽度(避免数字从10变9时,末尾残留空格)// \r:回到行首,覆盖当前行printf("%-2d\r", i);fflush(stdout); // 手动刷新缓冲区,确保实时显示sleep(1); // 睡眠1秒,模拟倒计时间隔i--; // 倒计时减1}printf("\n"); // 倒计时结束,换行,避免后续输出与倒计时重叠return 0;
}
5.3.2 编译与运行
gcc count_down.c -o count_down
./count_down
现象:终端中会从10开始,每秒减少 1,直到0,然后换行 —— 整个过程数字在同一行更新,没有多余的换行。
5.4 实战:实现两种版本的进度条
进度条的核心需求是:
- 显示进度百分比(0%~100%);
- 显示进度条填充(如
======); - 显示动态加载符号(如
|///-/\,模拟 “正在加载” 的效果); - 实时更新,不换行,进度覆盖显示。
下面实现两种版本的进度条:基础版(固定进度增长)和进阶版(根据实际任务进度更新)。
5.4.1 版本 1:基础版进度条(固定增长)
基础版进度条的进度从 0% 固定增长到 100%,每 50 毫秒更新一次,适合演示基本原理。
1. 代码实现(process_v1.c)
#include <stdio.h>
#include <string.h>
#include <unistd.h> // 包含usleep函数(微秒级睡眠)#define NUM 101 // 进度条缓冲区大小(100个字符+1个结束符)
#define STYLE '=' // 进度条填充字符void process_v1() {char buffer[NUM]; // 存储进度条填充内容memset(buffer, 0, sizeof(buffer)); // 初始化缓冲区为0(清空)const char *lable = "|/-\\"; // 动态加载符号(注意:\需要转义,所以用\\)int len = strlen(lable); // 加载符号的长度(4)int cnt = 0; // 进度计数器(0~100)while (cnt <= 100) {// 格式化输出:// %-100s:左对齐,占100个字符(进度条填充)// %d%%:显示百分比(%%转义为%)// %c:显示动态加载符号// \r:回到行首,覆盖当前行printf("[%-100s][%d%%][%c]\r", buffer, cnt, lable[cnt % len]);fflush(stdout); // 手动刷新缓冲区buffer[cnt] = STYLE; // 填充进度条(每增加1%,多一个=)cnt++; // 进度+1usleep(50000); // 睡眠50毫秒(50000微秒),控制更新速度}printf("\n"); // 进度条结束,换行
}int main() {printf("Downloading...\n");process_v1(); // 调用进度条函数printf("Download completed!\n");return 0;
}
2. 关键代码解释
buffer[NUM]:进度条填充的缓冲区,大小为 101(100 个填充字符 + 1 个字符串结束符\0),确保进度条最多显示 100 个=;lable = "|/-\\":动态加载符号,cnt % len(len=4)会循环取 0~3,对应符号|///-/\,模拟 “旋转” 效果;usleep(50000):微秒级睡眠,50000 微秒 = 50 毫秒,控制进度条更新速度,避免刷新过快导致闪烁;printf格式化:%-100s确保进度条占 100 个字符宽度,左对齐,即使进度未填满,右侧也会用空格填充,避免进度条 “晃动”。
3. 编译与运行
gcc process_v1.c -o process_v1
./process_v1
现象:
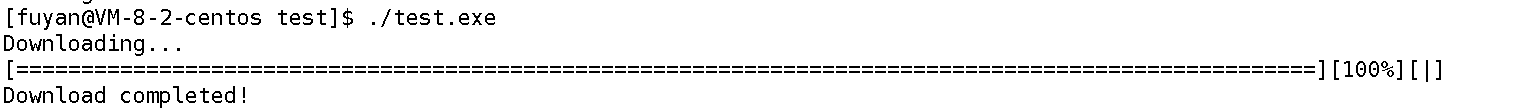
Downloading...
[====================================================================================================][100%][\]
Download completed!
进度条会从 0% 开始,逐步填充=,动态符号旋转,直到 100% 后换行。
5.4.2 版本 2:进阶版进度条(按实际任务更新)
基础版进度条的进度是 “固定增长”,实际开发中,进度条需要根据 “任务完成比例” 更新(如文件下载进度、数据处理进度)。进阶版进度条接收 “总任务量” 和 “已完成任务量”,计算进度比例并更新。
1. 代码结构
进阶版进度条采用 “多文件结构”,分为 3 个文件:
process.h:声明进度条函数;process.c:实现进度条函数;main.c:模拟任务(如下载),调用进度条函数。
2. 头文件(process.h)
#ifndef PROCESS_H // 防止头文件重复包含 也可用#pragma once
#define PROCESS_H#include <stdio.h>// 进度条函数:total=总任务量,current=已完成任务量
void FlushProcess(double total, double current);#endif
3. 进度条实现(process.c)
#include "process.h"
#include <string.h>
#include <unistd.h>#define NUM 101 // 进度条缓冲区大小
#define STYLE '=' // 进度条填充字符void FlushProcess(double total, double current) {char buffer[NUM];memset(buffer, 0, sizeof(buffer));const char *lable = "|/-\\";int len = strlen(lable);static int cnt = 0; // 静态变量:记录加载符号的位置(不重置)int num = (int)(current * 100 / total); // 计算进度百分比(0~100)// 填充进度条(根据百分比填充=)int i = 0;for (; i < num; i++) {buffer[i] = STYLE;}double rate = current / total; // 任务完成比例(0~1)cnt %= len; // 循环更新加载符号位置// 格式化输出:显示1位小数的百分比(%.1f%%)printf("[%-100s][%.1f%%][%c]\r", buffer, rate * 100, lable[cnt]);fflush(stdout);cnt++; // 加载符号位置+1
}
4. 主程序(main.c):模拟下载任务
#include "process.h"
#include <stdio.h>
#include <unistd.h>#define TOTAL_SIZE 1024.0 // 总任务量(模拟1024MB的文件)
#define SPEED 1.0 // 任务完成速度(每秒完成1MB)// 模拟下载函数
void DownLoad() {double current = 0; // 已完成任务量(初始为0)while (current <= TOTAL_SIZE) {FlushProcess(TOTAL_SIZE, current); // 调用进度条,更新进度usleep(3000); // 睡眠3毫秒,模拟下载耗时(控制任务速度)current += SPEED; // 已完成任务量+1(模拟下载1MB)}printf("\n"); // 单个下载任务结束,换行
}int main() {// 模拟多次下载任务for (int i = 0; i < 3; i++) {printf("Download task %d...\n", i + 1);DownLoad();printf("Task %d completed!\n\n", i + 1);}return 0;
}
5. 编译与运行(用 Makefile)
为了方便编译多文件项目,编写一个简单的 Makefile:
SRC = $(wildcard *.c) # 获取所有.c文件
OBJ = $(SRC:.c=.o) # 目标文件列表
BIN = processbar # 可执行程序名
CC = gcc # 编译器$(BIN): $(OBJ)$(CC) $^ -o $@%.o: %.c$(CC) -c $< -o $@.PHONY: clean
clean:rm -f $(OBJ) $(BIN)
编译运行:
make
./processbar
现象:
Download task 1...
[====================================================================================================][100.0%][\]
Task 1 completed!Download task 2...
[====================================================================================================][100.0%][|]
Task 2 completed!Download task 3...
[====================================================================================================][100.0%][/]
Task 3 completed!
每次下载任务都会实时更新进度条,进度根据 “已完成任务量 / 总任务量” 计算,更贴近实际开发场景。
5.5 进度条优化:解决常见问题
5.5.1 问题 1:进度条闪烁
原因:进度条更新速度过快(如usleep时间过短),或终端刷新频率不匹配。
解决方法:
- 调整
usleep时间,建议在 50~100 毫秒(50000~100000 微秒),平衡 “实时性” 和 “流畅度”; - 减少不必要的输出(如避免在进度条循环中打印其他信息)。
5.5.2 问题 2:进度条超出 100%
原因:任务完成量current超过总任务量total,导致num = current*100/total大于 100,buffer填充超出 100 个字符。
解决方法:在计算num时添加判断,确保num不超过 100:
int num = (int)(current * 100 / total);
if (num > 100) num = 100; // 限制进度不超过100%
5.5.3 问题 3:动态符号不旋转
原因:lable字符串中的\未转义,导致符号解析错误;或cnt未用static修饰,每次调用函数时cnt重置为 0。
解决方法:
lable必须写成"|/-\\"(\转义为\\);cnt用static修饰,确保函数调用时cnt的值不重置(仅初始化一次)。
六、版本控制器 Git:代码管理的 “时光机”
在开发过程中,我们经常会遇到这样的场景:修改代码后发现 bug,想恢复到之前的版本;多人协作开发时,需要合并各自的代码;需要记录每次修改的内容,方便后续追溯。这些问题都可以通过Git解决 ——Git 是目前最流行的分布式版本控制系统,能跟踪代码的每一次修改,支持版本回滚、分支管理、多人协作,是开发团队的必备工具。
6.1 为什么需要版本控制?
没有版本控制时,我们通常会通过 “复制文件 + 重命名” 的方式管理版本,比如:
- “project-v1.0.c”
- “project-v2.0.c”
- “project-final.c”
- “project-final-ultimate.c”
这种方式存在三个严重问题:
- 版本混乱:文件越来越多,无法清晰记录每个版本的修改内容(比如 “v2.0 比 v1.0 改了哪个函数”);
- 恢复困难:如果修改后引入 bug,需要手动查找之前的版本文件,效率极低;
- 协作冲突:多人同时修改同一个文件时,容易覆盖彼此的代码,导致冲突。
而 Git 通过以下功能解决这些问题:
- 版本跟踪:记录每次修改的作者、时间、内容,形成 “版本历史”,可随时查看;
- 版本回滚:可一键恢复到任意历史版本,无需手动保存旧文件;
- 分支管理:多人协作时,每人在自己的 “分支” 上开发,避免直接修改主代码;
- 冲突解决:自动检测多人修改的冲突,提供工具辅助解决冲突。
6.2 Git 的核心概念:分布式与本地仓库
Git 是 “分布式版本控制系统”,与早期的 “集中式版本控制系统”(如 SVN)相比,最大的区别是 “每个用户都有完整的代码仓库”,核心概念包括:
6.2.1 仓库(Repository)
仓库是 Git 存储代码和版本历史的目录,分为两种:
- 本地仓库:存放在用户本地电脑上,包含所有代码和版本历史,即使没有网络也能提交修改;
- 远程仓库:存放在远程服务器上(如 GitHub、GitLab),用于多人协作时同步代码(如将本地修改上传到远程,或从远程下载他人的修改)。
6.2.2 工作区(Working Directory)
工作区是我们实际编写代码的目录,比如project/目录,里面包含.c/.h/Makefile等文件 —— 工作区的文件分为两种状态:
- 未跟踪(Untracked):Git 未管理的文件(新创建的文件,未添加到 Git);
- 已跟踪(Tracked):Git 已管理的文件(已添加到 Git,包含未修改、已修改、已暂存三种状态)。
6.2.3 暂存区(Staging Area)
暂存区是 Git 的 “中间过渡区”,用于临时存放待提交的修改。当我们修改文件后,需要先将修改 “添加到暂存区”,再从暂存区 “提交到本地仓库”—— 这样做的好处是:可以选择性地提交部分修改,而不是一次性提交所有修改。
6.2.4 本地仓库(Local Repository)
本地仓库是 Git 存储版本历史的核心,包含所有提交记录(每次提交对应一个版本)。提交到本地仓库的修改会被永久保存,可随时回滚到任意提交版本。
6.2.5 远程仓库(Remote Repository)
远程仓库是多人协作的 “桥梁”,比如 GitHub 上的仓库。用户可以将本地仓库的修改 “推送到远程”(git push),也可以从远程仓库 “拉取最新修改”(git pull),实现多人代码同步。
6.3 Git 的安装:Linux 下的快速部署
Linux 下安装 Git 非常简单,通过包管理器即可完成,CentOS 和 Ubuntu 的安装命令如下:
6.3.1 CentOS/RHEL 系列
# 安装Git
sudo yum install git -y# 验证安装(查看Git版本)
git --version
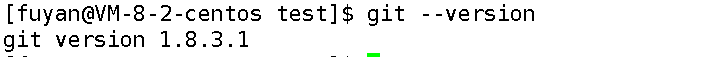
安装成功后,会输出类似git version 1.8.3.1的信息。
6.3.2 Ubuntu/Debian 系列
# 更新apt索引(可选,确保安装最新版本)
sudo apt update# 安装Git
sudo apt install git -y# 验证安装
git --version
安装成功后,输出类似git version 2.25.1的信息。
6.3.3 首次使用配置
安装完成后,需要配置用户信息(用户名和邮箱),Git 会将这些信息添加到每次提交记录中,用于标识修改作者:
# 配置用户名(替换为你的用户名,如"Zhang San")
git config --global user.name "Your Name"# 配置邮箱(替换为你的邮箱,如"zhangsan@example.com")
git config --global user.email "your.email@example.com"# 验证配置(查看当前Git配置)
git config --list
输出结果中会包含user.name=Your Name和user.email=your.email@example.com,表示配置成功。
注意:--global选项表示 “全局配置”,即所有 Git 仓库都会使用这个配置;如果需要为某个仓库单独配置,可进入仓库目录,去掉--global选项执行命令。
6.4 Git 基础操作:从 “初始化” 到 “提交”
Git 的基础操作围绕 “工作区 - 暂存区 - 本地仓库” 的流程展开,核心是 “三板斧”:git add(添加到暂存区)、git commit(提交到本地仓库)、git push(推送到远程仓库)。我们先从本地仓库的操作开始,逐步熟悉 Git 的使用。
6.4.1 初始化本地仓库(git init)
要使用 Git 管理项目,首先需要将项目目录初始化为 Git 仓库。
实战例子:创建一个test-git项目,并初始化为 Git 仓库:
# 1. 创建项目目录
mkdir test-git
cd test-git# 2. 初始化Git仓库(在当前目录创建.git子目录,存储Git的配置和版本历史)
git init# 输出结果
Initialized empty Git repository in /home/yourname/test-git/.git/

执行git init后,当前目录会生成一个隐藏的.git目录(不要手动修改或删除),表示 Git 仓库初始化成功。
6.4.2 查看文件状态(git status)
git status用于查看工作区和暂存区的文件状态,是 Git 最常用的命令之一,帮助我们了解当前哪些文件被修改、哪些文件未跟踪。
实战例子:在test-git目录下创建一个main.c文件,查看状态:
# 1. 创建main.c文件
vim main.c # 输入任意内容,如"#include <stdio.h>"# 2. 查看文件状态
git status# 输出结果(关键部分)
On branch master
No commits yetUntracked files:(use "git add <file>..." to include in what will be committed)main.cnothing added to commit but untracked files present (use "git add" to track)
结果显示main.c是 “Untracked files”(未跟踪文件),需要用git add添加到暂存区。
6.4.3 添加文件到暂存区(git add)
git add的作用是将工作区的文件添加到暂存区,支持添加单个文件、多个文件或整个目录。
常用命令:
| 命令格式 | 功能描述 | 实战例子 |
|---|---|---|
git add 文件名 | 添加单个文件到暂存区 | git add main.c |
git add 文件名1 文件名2 | 添加多个文件到暂存区 | git add main.c sum.c |
git add 目录名 | 添加整个目录到暂存区 | git add src/ |
git add . | 添加当前目录下所有未跟踪 / 修改的文件到暂存区 | git add . |
实战例子:将main.c添加到暂存区,再查看状态:
# 1. 添加main.c到暂存区
git add main.c# 2. 查看状态
git status# 输出结果(关键部分)
On branch master
No commits yetChanges to be committed:(use "git rm --cached <file>..." to unstage)new file: main.c
结果显示main.c已进入 “Changes to be committed”(待提交状态),表示已添加到暂存区。
6.4.4 提交到本地仓库(git commit)
git commit的作用是将暂存区的文件提交到本地仓库,生成一个新的版本记录。提交时必须添加 “提交信息”,描述本次修改的内容(如 “新增 main.c 文件,实现入口函数”),方便后续查看版本历史。
命令格式:git commit -m "提交信息"(-m选项指定提交信息)
实战例子:将暂存区的main.c提交到本地仓库:
# 提交到本地仓库,添加提交信息
git commit -m "init: add main.c file"# 输出结果(关键部分)
[master (root-commit) 8f3a4d2] init: add main.c file1 file changed, 1 insertion(+)create mode 100644 main.c
结果说明:
master:当前所在分支(默认分支);8f3a4d2:提交的唯一标识(哈希值,用于后续回滚或查看该版本);1 file changed, 1 insertion(+):本次提交修改了 1 个文件,新增了 1 行内容。
6.4.5 查看提交历史(git log)
git log用于查看本地仓库的提交历史,包括每次提交的作者、时间、哈希值、提交信息。
常用命令:
| 命令格式 | 功能描述 |
|---|---|
git log | 查看完整提交历史(按时间倒序) |
git log --oneline | 简洁显示提交历史(一行一个版本) |
git log -n 数字 | 查看最近 n 次提交历史 |
git log --author=用户名 | 查看指定作者的提交历史 |
实战例子:查看test-git仓库的提交历史:
# 简洁查看提交历史
git log --oneline# 输出结果
8f3a4d2 (HEAD -> master) init: add main.c file
结果显示当前只有 1 次提交,哈希值为8f3a4d2,提交信息为 “init: add main.c file”。
6.4.6 修改文件后重新提交
如果修改了已提交的文件(如修改main.c的内容),需要重新执行 “git add→git commit” 的流程,将修改提交到本地仓库。
实战例子:修改main.c,添加main函数,然后提交:
# 1. 修改main.c(添加main函数)
vim main.c
# 修改后的内容:
#include <stdio.h>int main() {printf("Hello Git!\n");return 0;
}# 2. 查看状态(此时main.c处于"已修改"状态)
git status# 3. 添加到暂存区
git add main.c# 4. 提交到本地仓库
git commit -m "feat: add main function to main.c"# 5. 查看提交历史
git log --oneline# 输出结果
a7b2c9d (HEAD -> master) feat: add main function to main.c
8f3a4d2 init: add main.c file
现在提交历史中有两个版本,最新版本的哈希值为a7b2c9d,记录了 “添加 main 函数” 的修改。
6.5 远程仓库协作:GitHub 的使用(国内可使用gitee)
本地仓库只能自己使用,要实现多人协作,需要将代码上传到远程仓库。GitHub 是目前最流行的远程仓库平台,支持免费创建公开仓库,下面介绍如何在 GitHub 上创建仓库,并将本地代码推送到远程。
6.5.1 步骤 1:注册 GitHub 账号
- 访问 GitHub 官网(https://github.com/),点击 “Sign up”;
- 输入用户名、邮箱、密码,完成注册(需要验证邮箱);
- 登录 GitHub,进入个人主页。
6.5.2 步骤 2:创建 GitHub 远程仓库
- 点击右上角的 “+” 图标,选择 “New repository”(新建仓库);
- 填写仓库信息:
- Repository name:仓库名称(如
test-git,需唯一,不能与他人重复); - Description(可选):仓库描述(如 “Git test project”);
- Visibility:仓库可见性(选择 “Public”,公开仓库,免费);
- 取消勾选 “Initialize this repository with a README”(暂时不初始化 README,避免与本地仓库冲突);
- Repository name:仓库名称(如
- 点击 “Create repository”,创建远程仓库。
6.5.3 步骤 3:获取远程仓库地址
仓库创建成功后,会进入仓库主页,点击 “Code” 按钮,复制远程仓库的 HTTPS 地址(如https://github.com/YourUsername/test-git.git)—— 这个地址用于本地仓库与远程仓库关联。
6.5.4 步骤 4:本地仓库关联远程仓库(git remote)
git remote用于管理本地仓库与远程仓库的关联,常用命令:
git remote add 远程仓库名 远程仓库地址:添加远程仓库关联;git remote -v:查看当前关联的远程仓库。
实战例子:将本地test-git仓库关联到 GitHub 远程仓库:
# 进入本地test-git目录
cd test-git# 关联远程仓库(远程仓库名通常用"origin",表示"默认远程仓库")
git remote add origin https://github.com/YourUsername/test-git.git# 查看关联结果
git remote -v# 输出结果
origin https://github.com/YourUsername/test-git.git (fetch)
origin https://github.com/YourUsername/test-git.git (push)
结果显示已成功关联名为origin的远程仓库,支持 “拉取(fetch)” 和 “推送(push)” 操作。
6.5.5 步骤 5:将本地代码推送到远程仓库(git push)
git push用于将本地仓库的提交推送到远程仓库,命令格式为git push 远程仓库名 分支名(默认分支为master或main,GitHub 新版默认分支为main,需注意分支名一致)。
实战例子:将本地master分支推送到origin远程仓库:
# 推送本地master分支到origin远程仓库
git push origin master# 首次推送时,可能需要输入GitHub用户名和密码(或token)
Username for 'https://github.com': YourUsername
Password for 'https://YourUsername@github.com': YourPassword/Token
注意:GitHub 从 2021 年起不再支持密码登录,需使用 “个人访问令牌(Personal Access Token)” 代替密码:
- 登录 GitHub → 点击头像 → Settings → Developer settings → Personal access tokens → Generate new token;
- 填写 Note(如 “Linux 开发推送”),勾选
repo权限组(包含repo:status/repo_deployment等子权限); - 点击 Generate token,复制令牌并保存(刷新页面后无法再次查看);
- 推送时,密码处粘贴该令牌。
推送成功后,刷新 GitHub 仓库主页,会看到本地的main.c文件已上传到远程仓库。
6.5.6 步骤 6:从远程仓库拉取代码(git pull)
如果远程仓库有更新(如他人推送了新代码),需要用git pull将远程修改拉取到本地,保持本地与远程同步。
命令格式:git pull 远程仓库名 分支名
实战例子:拉取origin远程仓库master分支的最新修改:
git pull origin master
如果本地仓库与远程仓库无冲突,会自动合并远程修改;若有冲突,需要先解决冲突再拉取(后续会讲解冲突解决)。
6.6 Git 进阶操作:版本回滚与分支管理
6.6.1 版本回滚:恢复到之前的版本
如果修改代码后引入 bug,需要恢复到之前的稳定版本,可通过git reset命令实现版本回滚。
常用命令:
git reset --hard 提交哈希值:彻底回滚到指定版本,删除当前版本到指定版本之间的所有修改(多人协作场景下,禁止用git push -f回滚远程版本;正确做法是用git revert 哈希值生成‘撤销提交’,保留历史记录,避免覆盖他人修改);git reset --soft 提交哈希值:回滚到指定版本,但保留当前版本的修改(修改会进入暂存区,可重新提交);git log --oneline:查看提交哈希值,找到需要回滚的版本。
实战例子:回滚到最初的 “添加 main.c” 版本(哈希值8f3a4d2):
# 1. 查看提交历史,获取目标版本的哈希值
git log --oneline# 输出结果
a7b2c9d (HEAD -> master, origin/master) feat: add main function to main.c
8f3a4d2 init: add main.c file# 2. 回滚到8f3a4d2版本(--hard选项,彻底回滚)
git reset --hard 8f3a4d2# 输出结果
HEAD is now at 8f3a4d2 init: add main.c file# 3. 查看main.c内容,确认已回滚
cat main.c
# 输出:#include <stdio.h>(已恢复到最初版本,main函数被删除)
注意:如果已将修改推送到远程仓库,回滚本地版本后,需要用git push -f origin master强制推送回滚后的版本到远程(-f选项表示强制推送,谨慎使用,避免覆盖他人的修改)。
6.6.2 分支管理:并行开发的核心
分支是 Git 的核心功能之一,用于实现 “并行开发”—— 比如在master分支(主分支,保持稳定)外,创建dev分支(开发分支)开发新功能,功能完成后再合并到master分支,避免直接修改主分支代码。
常用分支命令:
| 命令格式 | 功能描述 |
|---|---|
git branch | 查看当前所有分支(* 表示当前分支) |
git branch 分支名 | 创建新分支 |
git checkout 分支名 | 切换到指定分支 |
git checkout -b 分支名 | 创建并切换到新分支 |
git merge 分支名 | 将指定分支合并到当前分支 |
git branch -d 分支名 | 删除指定分支(需先切换到其他分支) |
实战例子:创建dev分支,在dev分支上开发新功能,再合并到master分支:
-
查看当前分支:
git branch # 输出:* master(当前在master分支) -
创建并切换到 dev 分支:
git checkout -b dev # 输出:Switched to a new branch 'dev' -
在 dev 分支上修改代码:比如在
main.c中添加sum函数声明:vim main.c # 修改后的内容: #include <stdio.h> int sum(int a, int b); // 新增sum函数声明 -
提交 dev 分支的修改:
git add main.c git commit -m "feat: add sum function declaration in main.c" -
切换回 master 分支:
git checkout master # 输出:Switched to branch 'master' # 查看main.c,sum函数声明已消失(因为master分支未修改) cat main.c -
将 dev 分支合并到 master 分支:
git merge dev # 输出结果(关键部分) Updating 8f3a4d2..e5f6g7h Fast-forwardmain.c | 1 +1 file changed, 1 insertion(+)“Fast-forward” 表示快速合并,因为
master分支在dev分支创建后没有修改,直接将master指针指向dev分支的最新版本。 -
查看合并后的 main.c:
cat main.c # 输出包含sum函数声明,合并成功 -
删除 dev 分支(功能已合并,分支不再需要):
git branch -d dev # 输出:Deleted branch dev (was e5f6g7h).
七、调试器 GDB:定位代码 bug 的 “显微镜”
编写代码时,难免会遇到 bug(如逻辑错误、变量值异常),单纯通过 “打印日志” 调试效率很低。GDB(GNU Debugger)是 Linux 下最常用的 C/C++ 调试工具,支持断点设置、单步执行、变量查看、内存查看等功能,能帮助我们精准定位 bug 的位置和原因,是开发过程中排查问题的 “利器”。
7.1 GDB 的前提:编译时生成调试信息
GCC/G++ 默认编译生成的程序是 “Release 模式”(无调试信息),无法用 GDB 调试。要使用 GDB,必须在编译时添加-g选项,生成 “Debug 模式” 的程序(包含调试信息,如代码行号、变量名、函数信息)。
实战例子:编译sum.c生成带调试信息的程序:
// sum.c
#include <stdio.h>int Sum(int s, int e) {int result = 0;for (int i = s; i <= e; i++) {result += i;}return result;
}int main() {int start = 1;int end = 100;printf("I will begin\n");int n = Sum(start, end);printf("running done, result is: [%d-%d]=%d\n", start, end, n);return 0;
}
编译命令:
# 编译时添加-g选项,生成带调试信息的程序sum_debug
gcc sum.c -o sum_debug -g# 验证调试信息(用file命令查看)
file sum_debug# 输出结果(关键部分)
sum_debug: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, with debug_info, not stripped
结果中的 “with debug_info” 表示程序包含调试信息,可以用 GDB 调试。
7.2 GDB 基础操作:从启动到退出
GDB 的操作通过命令行完成,常用命令分为 “启动与退出”“断点设置”“执行控制”“变量查看” 四类,下面逐一介绍。
7.2.1 启动与退出 GDB
- 启动 GDB:
gdb 可执行程序名,进入 GDB 调试界面; - 退出 GDB:在 GDB 界面中输入
quit(或q),或按Ctrl+d。
实战例子:启动 GDB 调试sum_debug:
7.2.2 查看源代码(list/l)
list(缩写l)用于在 GDB 界面中查看源代码,支持按行号、函数名查看。
常用命令:
| 命令格式 | 功能描述 | 实战例子 |
|---|---|---|
list/l | 从当前位置开始显示 10 行代码 | l |
list 行号/l 行号 | 显示指定行号附近的代码 | l 5(显示第 5 行附近代码) |
list 函数名/l 函数名 | 显示指定函数的代码 | l Sum(显示 Sum 函数代码) |
list 文件名:行号 | 显示指定文件的指定行代码 | l sum.c:10 |
实战例子:在 GDB 中查看Sum函数的代码:
(gdb) l Sum
4 int Sum(int s, int e) {
5 int result = 0;
6 for (int i = s; i <= e; i++) {
7 result += i;
8 }
9 return result;
10 }
11
12 int main() {
13 int start = 1;
14 int end = 100;
(gdb)
按回车键会继续显示后续代码,直到文件结束。
7.2.3 设置断点(break/b)
断点是调试的核心,用于 “暂停程序执行”,让我们在指定位置查看变量值、执行流程。break(缩写b)用于设置断点,支持按行号、函数名设置。
常用命令:
| 命令格式 | 功能描述 | 实战例子 |
|---|---|---|
break 行号/b 行号 | 在指定行设置断点 | b 20(在第 20 行设置断点) |
break 函数名/b 函数名 | 在指定函数的开头设置断点 | b main(在 main 函数开头设置断点) |
break 文件名:行号 | 在指定文件的指定行设置断点 | b sum.c:6 |
info break/info b | 查看当前所有断点的信息 | info b |
delete 断点编号/d 断点编号 | 删除指定编号的断点 | d 1(删除编号为 1 的断点) |
disable 断点编号 | 禁用指定断点(不删除,可重新启用) | disable 1 |
enable 断点编号 | 启用指定断点 | enable 1 |
实战例子:在main函数的第 20 行(int n = Sum(start, end);)设置断点,并查看断点信息:
# 设置断点(假设第20行是调用Sum函数的行)
(gdb) b 20
Breakpoint 1 at 0x400543: file sum.c, line 20.# 查看断点信息
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400543 in main at sum.c:20

断点信息说明:
Num:断点编号(1);Type:断点类型(breakpoint);Enb:是否启用(y = 启用,n = 禁用);Address:断点在内存中的地址;What:断点位置(main 函数,sum.c 第 20 行)。
7.2.4 执行控制:运行与单步执行
设置断点后,需要通过执行命令控制程序运行,常用命令包括 “运行程序”“单步执行”“继续执行” 等。
常用命令:
| 命令格式 | 功能描述 | 实战例子 |
|---|---|---|
run/r | 从程序开头开始执行,直到遇到断点或程序结束 | r |
next/n | 单步执行,不进入函数内部(逐过程,类似 F10) | n |
step/s | 单步执行,进入函数内部(逐语句,类似 F11) | s |
continue/c | 从当前位置继续执行,直到遇到下一个断点或程序结束 | c |
finish | 执行到当前函数返回,然后暂停 | finish(在函数内部执行,直到返回调用处) |
until 行号/u 行号 | 执行到指定行号,然后暂停 | u 25 |
实战例子:运行程序,在断点处单步执行,进入Sum函数:
# 1. 运行程序,直到遇到断点(第20行)
(gdb) r
Starting program: /home/yourname/sum_debug
I will beginBreakpoint 1, main () at sum.c:20
20 int n = Sum(start, end);# 2. 单步执行,进入Sum函数(用s命令)
(gdb) s
Sum (s=1, e=100) at sum.c:5
5 int result = 0;# 3. 单步执行,不进入循环内部(用n命令)
(gdb) n
6 for (int i = s; i <= e; i++) {# 4. 继续单步执行,查看result变量值
(gdb) n
7 result += i;
(gdb) n
6 for (int i = s; i <= e; i++) {
7.2.5 查看与修改变量值
在程序暂停时,需要查看变量值是否符合预期,甚至修改变量值验证逻辑,常用命令包括print、display、set var。
常用命令:
| 命令格式 | 功能描述 | 实战例子 |
|---|---|---|
print 变量名/p 变量名 | 打印指定变量的值 | p result(打印 result 的值) |
print 表达式/p 表达式 | 打印表达式的结果 | p start + end(打印 1+100=101) |
display 变量名 | 跟踪显示指定变量的值(每次暂停时自动显示) | display i |
undisplay 编号 | 取消跟踪指定编号的变量 | undisplay 1(取消编号 1 的跟踪) |
set var 变量名=值 | 修改变量的值 | set var i=50(将 i 改为 50) |
info locals/i locals | 查看当前函数的所有局部变量值 | info locals(在 Sum 函数中查看局部变量) |
实战例子:在Sum函数中查看、修改变量值:
# 1. 在Sum函数中,查看局部变量值
(gdb) info locals
result = 0
i = 1# 2. 打印result的值
(gdb) p result
$1 = 0# 3. 跟踪显示i的值(每次暂停时自动显示)
(gdb) display i
1: i = 1# 4. 单步执行,查看i和result的变化
(gdb) n
7 result += i;
1: i = 1
(gdb) n
6 for (int i = s; i <= e; i++) {
1: i = 1
(gdb) p result
$2 = 1 # result已变为1(1累加)# 5. 修改i的值为50,加速循环
(gdb) set var i=50
(gdb) p i
$3 = 50
(gdb) n
7 result += i;
1: i = 50
(gdb) p result
$4 = 51 # result = 1 + 50 = 51
7.3 GDB 进阶技巧:条件断点与变量监视
7.3.1 条件断点:
7.3 GDB 进阶技巧:条件断点与变量监视
在复杂程序调试中,单纯的 “行断点” 可能无法满足需求 —— 比如循环执行 100 次,我们只需要在第 30 次循环时暂停;或者某个变量值异常时需要立即定位。此时,GDB 的条件断点和变量监视功能就能发挥作用,帮助我们更精准地捕捉 bug。
7.3.1 条件断点:满足特定条件才暂停
条件断点是 “带触发条件的断点”,只有当指定条件成立时(如变量i==30、result>1000),程序才会在断点处暂停,避免无意义的暂停,大幅提升调试效率。
7.3.1.1 新增条件断点
新增条件断点的语法为:break 行号/函数名 if 条件,其中 “条件” 是一个 C 语言表达式(如i==30、s>e)。
实战例子:在Sum函数的循环体内(第 7 行,result += i)设置条件断点,仅当i==30时暂停:
-
启动 GDB 并查看代码:
gdb sum_debug (gdb) l Sum # 查看Sum函数代码,确认循环体行号(假设第7行是result += i) 4 int Sum(int s, int e) { 5 int result = 0; 6 for (int i = s; i <= e; i++) { 7 result += i; 8 } 9 return result; 10 } -
设置条件断点:
# 在第7行设置断点,条件为i==30 (gdb) b 7 if i==30 Breakpoint 1 at 0x40052c: file sum.c, line 7. -
运行程序并触发断点:
(gdb) r # 运行程序 Starting program: /home/yourname/sum_debug I will beginBreakpoint 1, Sum (s=1, e=100) at sum.c:7 7 result += i;程序会直接在
i==30时暂停,跳过前 29 次循环,无需手动单步执行到第 30 次。 -
查看变量值验证:
(gdb) p i # 查看i的值,确认触发条件 $1 = 30 (gdb) p result # 查看此时result的值(1+2+...+29=435) $2 = 435
7.3.1.2 为已有断点添加条件
如果已创建普通断点(无条件),可以通过condition 断点编号 条件为其追加条件,无需重新创建断点。
实战例子:为已有的第 2 号断点(假设在第 7 行)添加 “i==50” 的条件:
-
查看当前断点:
(gdb) info b # 查看断点列表,确认断点编号 Num Type Disp Enb Address What 2 breakpoint keep y 0x000000000040052c in Sum at sum.c:7 -
为断点添加条件:
# 为2号断点添加条件i==50 (gdb) condition 2 i==50 -
验证条件是否生效:
(gdb) info b 2 # 查看2号断点的详细信息 Num Type Disp Enb Address What 2 breakpoint keep y 0x000000000040052c in Sum at sum.c:7stop only if i==50 # 条件已生效 -
运行程序触发条件:
(gdb) r Starting program: /home/yourname/sum_debug I will beginBreakpoint 2, Sum (s=1, e=100) at sum.c:7 7 result += i; (gdb) p i $3 = 50 # 确认触发条件 (gdb) p result # 1+2+...+49=1225 $4 = 1225
7.3.1.3 条件断点的注意事项
- 条件表达式必须是合法的 C 语言表达式,可以使用当前作用域内的变量(如函数参数、局部变量);
- 如果条件表达式语法错误,GDB 会提示 “Invalid condition”,需检查表达式格式(如变量名是否正确、运算符是否合法);
- 条件断点的触发依赖 “变量在断点行可见”—— 如果变量在断点行未定义(如在循环外引用循环变量
i),GDB 会提示 “No symbol "i" in current context.”,需调整断点位置或条件。
7.3.2 变量监视(watch):跟踪变量值变化
在调试中,我们常需要关注 “某个变量何时被修改”(如result本应递增却突然变为 0)。GDB 的watch命令可以 “监视变量”,当变量的值被修改时,程序会自动暂停,并显示变量的 “旧值” 和 “新值”,帮助定位修改变量的代码位置。
7.3.2.1 监视普通变量
watch 变量名用于监视普通变量(如result、i),支持在变量被修改时暂停。
实战例子:监视Sum函数中的result变量,跟踪其值变化:
-
启动 GDB 并运行到 Sum 函数:
gdb sum_debug (gdb) b Sum # 在Sum函数开头设置断点,确保进入函数后再监视变量 Breakpoint 1 at 0x40051d: file sum.c, line 5. (gdb) r # 运行程序,进入Sum函数断点 Starting program: /home/yourname/sum_debug I will beginBreakpoint 1, Sum (s=1, e=100) at sum.c:5 5 int result = 0; -
设置变量监视:
# 监视result变量(此时result尚未初始化,需先执行到变量定义后) (gdb) n # 单步执行到第6行,确保result已定义 6 for (int i = s; i <= e; i++) { (gdb) watch result # 开始监视result Hardware watchpoint 2: resultGDB 会创建 “硬件监视点”(Hardware watchpoint),通过硬件支持跟踪变量修改,效率更高。
-
继续执行,观察变量变化:
(gdb) c # 继续执行 Continuing.Hardware watchpoint 2: result # 变量被修改,触发监视Old value = 0 # 修改前的值 New value = 1 # 修改后的值 Sum (s=1, e=100) at sum.c:6 6 for (int i = s; i <= e; i++) {第一次循环中,
result从 0 变为 1,程序暂停并显示值变化。 -
多次继续执行,跟踪后续变化:
(gdb) c # 继续执行下一次修改 Continuing.Hardware watchpoint 2: resultOld value = 1 New value = 3 # 1+2=3 Sum (s=1, e=100) at sum.c:6 6 for (int i = s; i <= e; i++) {(gdb) c Continuing.Hardware watchpoint 2: resultOld value = 3 New value = 6 # 3+3=6 Sum (s=1, e=100) at sum.c:6 6 for (int i = s; i <= e; i++) {每次
result被修改,程序都会暂停,清晰展示变量的变化过程。
7.3.2.2 监视表达式值变化
除了普通变量,watch还支持监视 “表达式”(如result+i、i*2),当表达式的值被修改时,程序同样会暂停。
实战例子:监视表达式result+i的值变化:
# 在Sum函数中,监视表达式result+i
(gdb) watch result+i
Hardware watchpoint 3: result+i# 继续执行
(gdb) c
Continuing.Hardware watchpoint 3: result+iOld value = 6+4=10 # 假设此时result=6,i=4,表达式值为10
New value = 6+5=11 # i变为5,表达式值变为11
Sum (s=1, e=100) at sum.c:6
6 for (int i = s; i <= e; i++) {
7.3.2.3 变量监视的注意事项
- 监视时机:必须在变量 “已定义且在当前作用域内” 时设置监视 —— 如果在变量定义前(如
result未声明时)使用watch result,GDB 会提示 “No symbol "result" in current context.”; - 硬件监视点限制:部分环境下硬件监视点数量有限(通常为 4 个),如果需要监视多个变量,可使用 “软件监视点”(
watch -location 变量名),但软件监视点效率较低,适合变量修改不频繁的场景; - 取消监视:使用
delete 监视点编号(如delete 2)删除监视点,或disable 监视点编号暂时禁用监视点。
7.3.3 修改变量值(set var):验证 bug 原因
调试中,我们可能怀疑 “某个变量值异常导致 bug”(如flag=0导致结果乘以 0),此时可以用set var 变量名=值手动修改变量值,验证假设是否成立 —— 这能快速定位 “变量值错误” 类 bug,无需修改代码重新编译。
实战例子:假设Sum函数中新增flag变量,返回result*flag,但flag被错误设为 0,导致结果为 0,通过set var验证:
-
修改 Sum 函数代码(模拟 bug):
#include <stdio.h>int flag = 0; // 错误:flag应为1,却设为0int Sum(int s, int e) {int result = 0;for (int i = s; i <= e; i++) {result += i;}return result * flag; // 结果乘以flag,导致返回0 }int main() {int start = 1;int end = 100;printf("I will begin\n");int n = Sum(start, end);printf("running done, result is: [%d-%d]=%d\n", start, end, n);return 0; } -
编译带调试信息的程序:
gcc sum_bug.c -o sum_bug -g -
GDB 调试,定位 bug:
gdb sum_bug (gdb) b Sum # 在Sum函数开头设置断点 Breakpoint 1 at 0x400522: file sum_bug.c, line 6. (gdb) r # 运行程序 Starting program: /home/yourname/sum_bug I will beginBreakpoint 1, Sum (s=1, e=100) at sum_bug.c:6 6 int result = 0;# 单步执行到return语句,查看result和flag的值 (gdb) n # 执行result初始化 7 for (int i = s; i <= e; i++) { (gdb) until 11 # 执行到return语句(第11行) Sum (s=1, e=100) at sum_bug.c:11 11 return result * flag;# 查看变量值,发现flag=0 (gdb) p result # result=5050(1+2+...+100) $1 = 5050 (gdb) p flag # flag=0,导致结果为0 $2 = 0# 修改变量flag的值为1,验证是否是bug原因 (gdb) set var flag=1 (gdb) p flag # 确认flag已改为1 $3 = 1# 继续执行,查看返回结果 (gdb) n # 执行return语句 main () at sum_bug.c:17 17 printf("running done, result is: [%d-%d]=%d\n", start, end, n);# 查看最终结果,确认bug修复 (gdb) p n # n=5050,正确 $4 = 5050
通过set var修改flag的值后,结果从 0 变为 5050,验证了 “flag=0是导致 bug 的原因”,无需修改代码重新编译,大幅提升调试效率。
7.3.4 查看函数调用栈(backtrace/bt):定位调用关系
当程序崩溃(如段错误)或在深层函数中暂停时,我们需要知道 “当前函数是被哪个函数调用的”“调用时传递的参数是什么”。GDB 的backtrace(缩写bt)命令可以显示 “函数调用栈”,清晰展示函数的调用关系和参数值。
实战例子:在Sum函数中查看调用栈:
gdb sum_debug
(gdb) b Sum # 在Sum函数设置断点
Breakpoint 1 at 0x40051d: file sum.c, line 5.
(gdb) r # 运行程序
Starting program: /home/yourname/sum_debug
I will beginBreakpoint 1, Sum (s=1, e=100) at sum.c:5
5 int result = 0;# 查看函数调用栈
(gdb) bt
#0 Sum (s=1, e=100) at sum.c:5 # 当前函数:Sum,参数s=1,e=100
#1 0x0000000000400557 in main () at sum.c:20 # 调用者:main,在sum.c第20行调用
调用栈说明:
#0:当前正在执行的函数(最顶层函数Sum);#1:调用#0函数的函数(main函数);- 后续编号依次为更上层的调用函数(若有多层调用,如
A调用B,B调用C,则#0=C,#1=B,#2=A)。
进阶用法:bt N显示前 N 层调用栈,bt -N显示后 N 层调用栈,适合调用栈较深的场景:
(gdb) bt 1 # 只显示顶层调用函数
#0 Sum (s=1, e=100) at sum.c:5
7.4 CGDB:可视化 GDB 调试工具
GDB 默认是纯命令行界面,调试时需要频繁输入list查看代码,操作不够直观。CGDB是 GDB 的可视化增强工具,支持 “代码窗口 + GDB 命令窗口” 分屏显示,无需频繁输入list,能实时看到代码和调试状态,大幅提升调试体验。
7.4.1 安装 CGDB
CGDB 可通过包管理器直接安装,CentOS 和 Ubuntu 的安装命令如下:
- CentOS/RHEL 系列:
sudo yum install -y cgdb - Ubuntu/Debian 系列:
sudo add-apt-repository ppa:ubuntu-toolchain-r/test sudo apt updatesudo apt install -y ncurses-dev git clone https://github.com/cgdb/cgdb.git cd cgdb && ./configure && make && sudo make install
安装完成后,输入cgdb --version验证:

7.4.2 CGDB 基本操作
CGDB 的核心是 “分屏显示”:上半屏显示源代码,下半屏显示 GDB 命令行,操作与 GDB 兼容,同时新增了代码窗口的控制快捷键。
7.4.2.1 启动 CGDB
启动 CGDB 的命令与 GDB 类似:cgdb 可执行程序名:
cgdb sum_debug
启动后,界面分为两部分:
- 上半屏:显示源代码,当前执行行用箭头标记;
- 下半屏:GDB 命令窗口,支持输入所有 GDB 命令(如
r、b、n)。 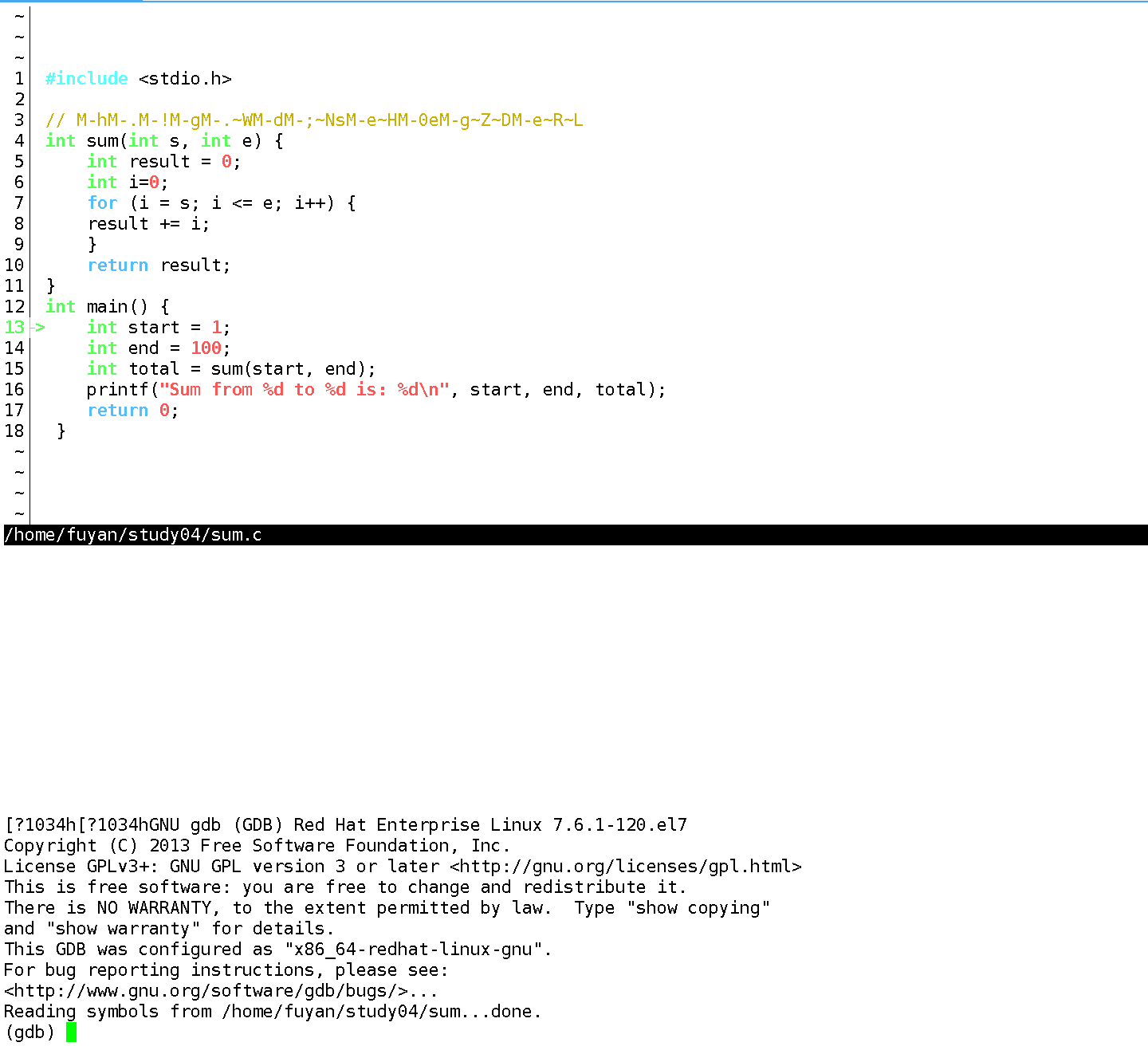
7.4.2.2 代码窗口控制快捷键
CGDB 在 GDB 命令的基础上,新增了代码窗口的控制快捷键(需先按ESC进入代码窗口模式):
| 快捷键 | 功能描述 |
|---|---|
ESC | 切换到代码窗口模式(此时可操作代码窗口) |
i | 切换回 GDB 命令窗口模式(此时可输入 GDB 命令) |
上下箭头 | 在代码窗口中滚动代码 |
PageUp/PageDown | 代码窗口翻页 |
Ctrl+f | 代码窗口向前翻页 |
Ctrl+b | 代码窗口向后翻页 |
gg | 跳转到代码开头 |
G | 跳转到代码结尾 |
7.4.2.3 CGDB 调试实战
用 CGDB 调试sum_debug,体验可视化调试:
-
启动 CGDB:
cgdb sum_debug上半屏显示
sum.c源代码,下半屏为 GDB 命令窗口。 -
设置断点并运行:
# 在GDB命令窗口输入(需先按i切换到命令模式) (gdb) b 20 # 在main函数第20行设置断点 (gdb) r # 运行程序程序运行到断点处时,上半屏代码窗口会用箭头标记当前执行行(第 20 行),无需输入
list即可看到代码。 -
单步执行并查看变量:
(gdb) s # 进入Sum函数 (gdb) n # 单步执行 (gdb) p result # 查看变量值每执行一步,代码窗口的箭头会同步移动,变量值显示在命令窗口,直观且高效。
7.5 GDB 常见问题与解决方法
7.5.1 问题 1:程序无法用 GDB 调试,提示 “No debugging symbols found”
现象:启动 GDB 后,输入l查看代码,提示 “No debugging symbols found in sum_debug”,无法查看源代码。
原因:编译程序时未添加-g选项,未生成调试信息,GDB 无法识别代码行号和变量。
解决方法:重新编译程序,添加-g选项:
gcc sum.c -o sum_debug -g # 带调试信息编译
7.5.2 问题 2:设置断点时提示 “Breakpoint address adjusted from 0x... to 0x...”
现象:设置断点时,GDB 提示 “Breakpoint 1 at 0x40052c: file sum.c, line 7. (2 locations)” 或 “Breakpoint address adjusted from 0x40052d to 0x40052c”。
原因:断点行是 “非执行语句”(如注释、空行、变量声明),GDB 会自动将断点调整到下一条可执行语句(如赋值、函数调用)。
解决方法:将断点设置在 “可执行语句” 行(如result += i、printf(...)),避免设置在空行或注释行。
7.5.3 问题 3:watch 命令提示 “Cannot watch variable ‘xxx’”
现象:使用watch result时,GDB 提示 “Cannot watch variable ‘result’”。
原因:变量result未在当前作用域内定义(如在变量声明前设置监视,或在函数外监视局部变量)。
解决方法:确保变量已定义且在当前作用域内 —— 如在Sum函数中,需执行到int result = 0后,再使用watch result。
7.5.4 问题 4:程序崩溃时 GDB 未显示崩溃位置
现象:程序运行时崩溃(如段错误),GDB 仅提示 “Program received signal SIGSEGV, Segmentation fault.”,未显示崩溃的代码行。
原因:程序崩溃时未触发断点,GDB 默认不会自动显示崩溃位置。
解决方法:使用bt命令查看函数调用栈,定位崩溃位置:
(gdb) r # 运行程序,触发崩溃
Program received signal SIGSEGV, Segmentation fault.
0x000000000040053a in Sum (s=1, e=100) at sum.c:8
8 }
(gdb) bt # 查看调用栈,定位崩溃函数和行号
#0 0x000000000040053a in Sum (s=1, e=100) at sum.c:8
#1 0x0000000000400557 in main () at sum.c:20
八、总结
本文围绕 Linux 基础开发工具展开,从 “软件安装 - 代码编辑 - 编译构建 - 版本管理- 程序调试” 的完整开发流程,系统讲解了核心工具的原理与实战操作,形成了一套覆盖 Linux 开发全链路的工具知识体系,核心要点总结如下:
1. 软件包管理器:解决 “软件安装与依赖” 问题
- 核心工具:CentOS/RHEL 用
yum,Ubuntu/Debian 用apt,两者均能自动解决软件依赖、下载编译好的软件包,替代繁琐的源码编译流程; - 关键操作:查看软件包(
yum list|grep 包名/apt search 包名)、安装(sudo yum install -y 包名/sudo apt install -y 包名)、卸载(yum remove/apt remove)、更换国内源(阿里云、清华源等,提升下载速度); - 核心价值:标准化软件安装流程,避免 “手动找依赖、编译出错” 的问题,是 Linux 开发的 “基础保障”。
2. Vim 编辑器:Linux 下的 “代码编辑核心”
- 核心特性:多模式编辑(命令模式、插入模式、底行模式),兼容
vi所有指令,支持语法高亮、插件扩展; - 关键操作:模式切换(
i进入插入模式、ESC返回命令模式、Shift+;进入底行模式)、光标移动(h/j/k/l、gg/G)、编辑操作(删除dd、复制yy、粘贴p、撤销u)、全局功能(查找/关键词、替换:%s/旧/新/g、列出行号set nu); - 核心价值:无需图形界面,仅通过命令即可高效编辑代码,是服务器端开发、远程调试的 “必备工具”,个性化配置(
.vimrc)可进一步提升编辑体验。
3. GCC/G++ 编译器:实现 “源码到可执行程序” 的转化
- 核心流程:预处理(
-E,展开头文件 / 去注释)→ 编译(-S,生成汇编代码)→ 汇编(-c,生成二进制目标文件)→ 链接(生成可执行程序),四步流程可通过gcc 源文件 -o 目标文件一键完成; - 关键选项:
-g(生成调试信息,供 GDB 使用)、-O0~-O3(编译优化级别)、-Wall(开启所有警告,提前发现隐患)、-static(静态链接,不依赖系统库); - 核心价值:将人类可读的源码转化为计算机可执行的二进制文件,支持 C/C++ 等多种语言,是 Linux 开发的 “核心转化工具”,理解编译流程有助于排查链接错误、优化程序性能。
4. Makefile:实现 “项目自动化构建”
- 核心逻辑:通过 “规则” 定义目标文件与依赖文件的关系,以及生成目标的命令(格式:
目标: 依赖\n\t命令),make命令自动解析规则,仅重新编译修改过的文件; - 关键特性:伪目标(
.PHONY,如clean,避免与文件重名)、变量(如CC=gcc、SRC=$(wildcard *.c),统一管理配置)、自动变量($@目标、$^依赖、$<第一个依赖,简化命令)、模式规则(%.o:%.c,批量处理目标文件); - 核心价值:解决多文件项目 “手动输入编译命令繁琐、易遗漏” 的问题,支持复杂项目的依赖管理与一键构建,是大型工程开发的 “效率保障”。
5. 进度条程序:Linux 系统编程的 “实战入门”
- 核心原理:利用 “回车
\r(回到行首)+ 行缓冲区刷新(fflush(stdout))” 实现 “同一行实时更新”,避免换行导致的进度条混乱; - 关键技术:区分回车与换行(
\r仅回行首,\n仅换行,Linux 下需配合使用)、行缓冲区机制(printf默认行缓冲,无\n时需手动fflush)、动态加载符号(循环显示|/-\,模拟加载动画); - 核心价值:融合 Linux IO 机制、缓冲区控制、终端输出等基础概念,是理解 Linux 系统编程的 “入门实战案例”,可扩展到下载进度、任务进度等实际场景。
6. Git 版本控制器:代码管理的 “时光机”
- 核心概念:分布式仓库(本地仓库 + 远程仓库,如 GitHub)、工作区(代码编辑目录)、暂存区(临时存放待提交修改)、提交(
commit,生成版本记录); - 关键操作:基础流程(
git init初始化→git add暂存→git commit提交→git push推送到远程)、版本管理(git log查看历史、git reset --hard 哈希值回滚版本)、分支操作(git branch创建、git checkout切换、git merge合并)、多人协作(git pull拉取远程修改、解决冲突); - 核心价值:跟踪代码修改历史,支持版本回滚、分支管理、多人协作,避免 “手动复制版本文件混乱、协作覆盖代码” 的问题,是团队开发的 “必备工具”。
7. GDB 调试器:定位 bug 的 “显微镜”
- 核心前提:编译时需添加
-g选项生成调试信息,否则无法调试; - 关键操作:基础功能(
l查看代码、b设置断点、r运行、n单步(不进函数)、s单步(进函数)、p查看变量)、进阶功能(条件断点b 行号 if 条件、变量监视watch 变量、修改变量set var 变量=值、查看调用栈bt)、可视化增强(CGDB 分屏显示,提升操作直观性); - 核心价值:精准定位代码逻辑错误、变量异常,支持 “断点拦截、单步跟踪、变量监视”,替代 “printf 打印日志” 的低效调试方式,是解决复杂 bug 的 “核心工具”。
8. 工具链的协同关系
这些工具并非孤立存在,而是形成 “协同工作流”:
Vim编辑源码 → GCC/G++编译(带-g调试信息) → Makefile自动化构建 → GDB/CGDB调试 → Git管理版本并推送到GitHub,软件包管理器(yum/apt)则为整个流程提供工具安装支持(如安装vim、gcc、git)。
掌握这套工具链,不仅能解决 Linux 开发中的基础问题,更能建立 “标准化、高效化” 的开发思维,为后续深入 Linux 系统编程、服务器开发、嵌入式开发等领域奠定坚实基础。
附录:CentOS 7 与 Ubuntu 更新软件源
附录 1:CentOS 7 更新 Yum 源
CentOS 7 默认 Yum 源在国外,下载速度慢,建议更换为国内镜像源(如阿里云、清华源),步骤如下:
-
备份现有 Yum 源:
sudo mkdir /etc/yum.repos.d/backup # 创建备份目录 sudo mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/backup/ # 移动原有源文件 -
下载国内 Yum 源配置文件:
- 阿里云源:
sudo curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo - 清华源:
sudo curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.tuna.tsinghua.edu.cn/centos/7/os/x86_64/CentOS-Base.repo
- 阿里云源:
-
清理并生成新缓存:
sudo yum clean all # 清理旧缓存 sudo yum makecache # 生成新缓存 -
验证 Yum 源:
sudo yum repolist # 查看当前生效的源,确认包含国内源
附录 2:Ubuntu 更新 APT 源
Ubuntu 默认 APT 源在国外,更换为国内源(如阿里云、清华源)可提升下载速度,以 Ubuntu 20.04(Focal Fossa)为例:
-
备份现有 APT 源:
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak # 备份原有源文件 -
下载国内 APT 源配置文件:
- 阿里云源:
sudo wget -O /etc/apt/sources.list http://mirrors.aliyun.com/repo/ubuntu-sources.list - 清华源:
sudo wget -O /etc/apt/sources.list https://mirrors.tuna.tsinghua.edu.cn/ubuntu/sources.list
- 阿里云源:
-
调整源文件适配 Ubuntu 版本:
编辑源文件,确保所有行包含focal(Ubuntu 20.04 代号),删除或注释其他版本(如bionic、jammy)的配置:sudo nano /etc/apt/sources.list # 编辑源文件正确配置示例:
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse -
更新 APT 缓存:
sudo apt update # 更新缓存,使新源生效 -
验证 APT 源:
sudo apt policy # 查看当前APT源,确认包含国内源



)




:数据库技术的发展、数据模型、数据库管理系统、数据库三级模式)





)


)

