【引言】企业实时数据流转,迎来“集成+计算”新范式
企业 IT 架构的演进,从最初的数据孤岛,到集中式数据仓库,再到如今的实时数据驱动架构。在这一过程中,数据的集成(数据源→目标)与数据的计算(数据变化的处理与应用)成为两大核心需求。
TapData 和 Kafka,正是在这两大方向中最具代表性的技术:
- TapData:异构数据的整合、清洗、治理专家
- Kafka:消息传输与事件驱动计算的高速通道
企业在数据架构选型时,常将二者对比,甚至被问:“谁替代谁?”
答案是:两者并非替代,而是最佳拍档。
一、目标受众与常见痛点

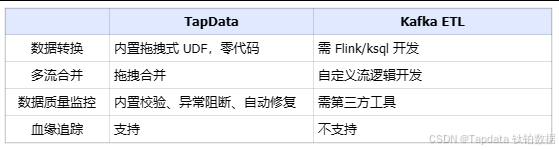
二、TapData vs Kafka ETL Pipeline:全面技术对比
Kafka 是一个分布式高吞吐消息队列,解决的是消息队列的性能瓶颈。 上游应用通过 Kafka 程序 API 向 Kafka topic 推送数据,下游应用通过 Kafka API 消费。

后来发现很多企业数据已经在数据库里需要集成, 于是在几年后推出了Kafka Connect 框架,可以更方便的在源和目标对接数据库系统。这个算是一个后来的功能点。

Kafka connect 的用法,恰恰与 TapData 的实时数据管道类似:

二者的关键的不同点在以下:

-
产品定位

关键区别:
TapData 面向业务系统数据的流转和治理,Kafka 面向应用事件流的高速传输。 -
数据源与 CDC 支持

案例说明:
性能举例,参考填充模板:某大型金融机构测试结果显示,TapData 的裸日志 CDC 在 Oracle 实例下对源库 TPS 影响低于 1%,而 Debezium 方案的 API 拉取方案最高可达 8% 性能下降。 -
数据处理与治理能力
用户痛点实录:
“传统 Kafka ETL,我们写了一堆 Flink 任务,开发复杂度高,维护代价也高。而 TapData,业务方自己拖拽配置就可以上线流合并与数据清洗了。” —— 某数据平台负责人 -
开发运维成本

实战反馈:
一家制造企业采用 Kafka ETL 的复杂链路部署后,5 人运维团队需要每天跟踪多个流任务状态,而切换 TapData 后,1 人即可维护全局数据同步与治理。
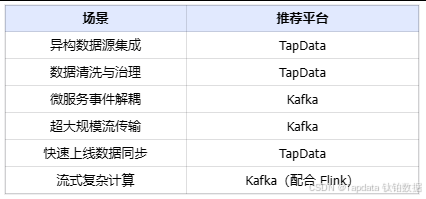
三、选择建议:你的场景匹配?
TapData 适用场景
- 异构数据库实时同步
- 数据清洗、治理(去重、转换、异常阻断)
- 实时数仓/BI 看板更新
- 低代码开发、快速上线
Kafka 适用场景
- 高吞吐、超大规模数据传输(IoT 日志、点击流)
- 微服务事件流解耦
- 需要复杂流式计算(Flink、CEP)
- 拥有成熟的大数据工程团队
经验法则:
业务数据同步与治理 → TapData
应用事件流传输与处理 → Kafka
四、TapData + Kafka:最佳组合架构与应用场景
很多企业并非二选一,而是TapData + Kafka 联合使用,典型场景如下:
协作模式 1:TapData → Kafka
TapData 担任 CDC 采集器,监听数据库变更,将事件推送至 Kafka Topic
优势:CDC 零侵入,Kafka 获得“即席”事件流
案例:某金融机构,TapData 监听核心账户变更,推送到 Kafka,供风控系统消费。
协作模式 2:Kafka → TapData
Kafka 收集来自微服务的事件流,TapData 消费数据并同步入目标数据库或数仓
优势:TapData 提供灵活的数据格式转换与错误处理
案例:一家保险公司,将用户行为事件通过 Kafka 收集,TapData 自动转换后写入实时分析平台(Doris)。
协作模式 3:混合部署,分工协作
- TapData:数据库间同步、数据治理
- Kafka:应用事件流传输与高吞吐消息管理
案例:
某大型电商,使用 TapData 实现订单系统与财务系统的数据同步,Kafka 用于用户行为日志的实时处理。
五、TapData + Kafka 架构示意
虽然 TapData 作为一个专门的实时数据管道工具,有其明显的优势。但是Kafka 作为一个极为流行的开源消息队列,很多企业已经部署了。在这样的情况下,TapData 可以作为 Kafka 的producer,以CDC 采集器角色,帮助把数据库的事件自动发送到Kafka Topic.

另外一个场景就是 从Kafka Topic 自动把事件消费入到数仓或者目标库内,这里Tapdata解决的更多的是数据格式自动转化,避免手工代码的方式

最后总结一下, TapData 和 Kafka,有多种方式协作:
1) TapData 作为 Kafka 的数据库CDC 采集器
2) TapData 作为 Kafka 的消费者自动写入到目标库
3) TapData 负责数据库之间的数据同步场景,Kafka 负责应用之间的数据交换场景,各司其职。
六、总结:TapData vs Kafka,不是替代,而是未来企业数据流的“分工协作”
最佳实践:
越来越多的企业,尤其是金融、电商、制造等行业,正在采用“TapData 数据集成治理 + Kafka 高效分发 + Flink 流计算”的复合架构,以实现真正的实时数据驱动业务。
七、行业视角:为什么现在必须考虑 TapData + Kafka 架构?
- 开发人力紧缺:企业不再愿意投入大量工程师开发/运维复杂的数据流。
- 异构数据激增:数据来源和格式多样化,治理需求上升。
- 决策时效要求提升:从日级、小时级提升至秒级响应。
- 国产替代趋势:特别是对国产数据库与消息系统的兼容能力提出更高要求。
八、下一步:如何快速评估你的场景?
企业可以做一个快速评估(PoC):
- 列出你的数据源与目标(数据库、消息队列、文件存储等)
- 明确需要的数据处理能力(CDC、清洗、转换、质量保障)
- 估算实时性与吞吐需求
- 确定你的团队可承担的开发/运维复杂度
如需进一步的架构建议或 PoC 咨询,可以联系我们的专家团队(team@tapdata.io)。
结语
TapData 与 Kafka,不是竞争者,而是时代共舞的伙伴。
在实时数据的世界里,“集成+传输+计算”的新范式正成为企业数据策略的主流,TapData 和 Kafka 的组合,是这个范式的最佳实践。


)




:数据库技术的发展、数据模型、数据库管理系统、数据库三级模式)





)


)


