1. 调度器在 K8s 中的位置与核心流程
API Server ←→ etcd ←→ kube-scheduler ←→ kubelet
创建:用户提交 Pod 描述(YAML/Helm/Operator)。
监听:调度器通过 Watch 机制捕获到
spec.nodeName=""的 Pod。过滤:根据资源、污点、亲和性等“硬性条件”过滤出可行节点(Feasible Nodes)。
打分:对可行节点按策略打分,最高分胜出。
绑定:将
spec.nodeName写入 Pod 对象,目标节点的 kubelet 开始真正启动容器。重调度:节点故障或资源不足 → 删除原 Pod → 回到步骤 2。
调度器是控制面唯一的“决策大脑”,但它不做网络/存储分配;它只是给 Pod 选“座位”。
2. 调度方式全景图
| 级别 | 方法 | 典型场景 | 备注 |
|---|---|---|---|
| 强制 | nodeName | 排障、DaemonSet | 优先级最高,绕过调度器 |
| 标签 | nodeSelector | 指定 gpu=true、ssd=true | 简单,功能有限 |
| 亲和 | nodeAffinity | 软/硬亲和 | 支持 In/NotIn/Gt/Lt/Exists |
| Pod 间 | podAffinity / podAntiAffinity | 同域部署、打散 | 需大量计算,大集群慎用 |
| 污点 | taint + toleration | 隔离生产/测试、驱逐 | NoSchedule / PreferNoSchedule / NoExecute |
| 高级 | 多调度器、扩展器、Score 插件 | 自定义算法 | 自 1.19 支持 Scheduling Framework |
3. 手把手实战:从简单到高阶
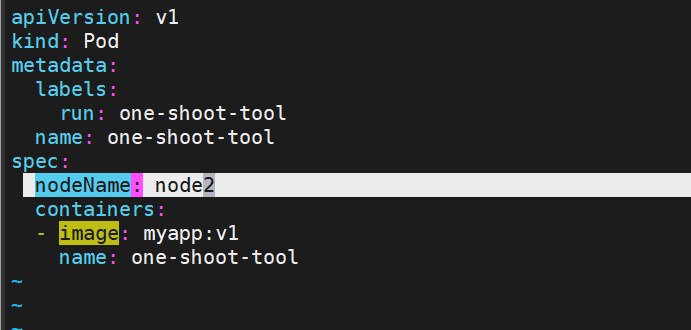
3.1 nodeName —— 一把梭,但风险高
apiVersion: v1
kind: Pod
metadata:name: one-shot-tool
spec:nodeName: k8s-node2 # 直接绑定,不经过调度器containers:- name: debugimage: alpine:latestcommand: ["sleep", "3600"]缺点:节点不存在或资源不足时直接 Pending,调度器不会帮你重试。

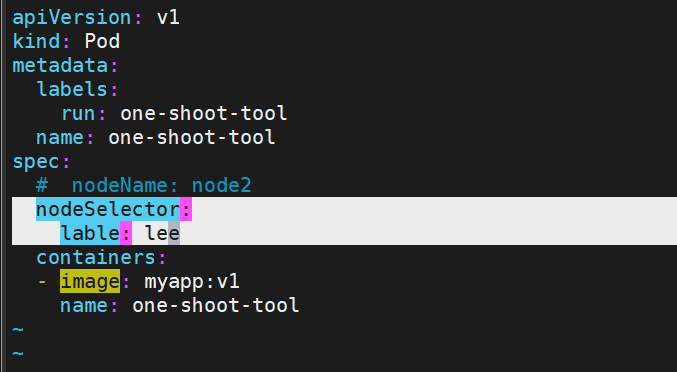
3.2 nodeSelector —— 80% 场景已够用
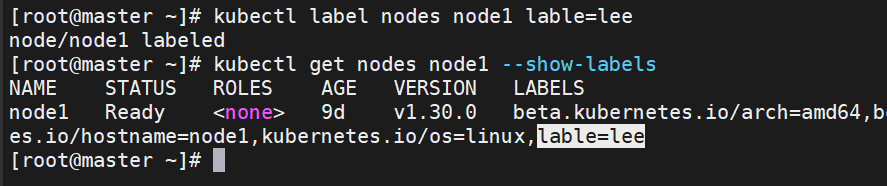
# 给节点打标签
kubectl label node k8s-node1 disktype=ssd zone=beijing
spec:nodeSelector:disktype: ssdzone: beijing小技巧:对同一类节点批量打标签
kubectl label node -l node-role.kubernetes.io/worker= tier=frontend

3.3 nodeAffinity —— 软/硬策略组
nodeaffinity支持多种规则匹配条件的配置如
| 匹配规则 | 功能 |
|---|---|
| ln | label 的值在列表内 |
| Notln | label 的值不在列表内 |
| Gt | label 的值大于设置的值,不支持Pod亲和性 |
| Lt | label 的值小于设置的值,不支持pod亲和性 |
| Exists | 设置的label 存在 |
| DoesNotExist | 设置的 label 不存在 |
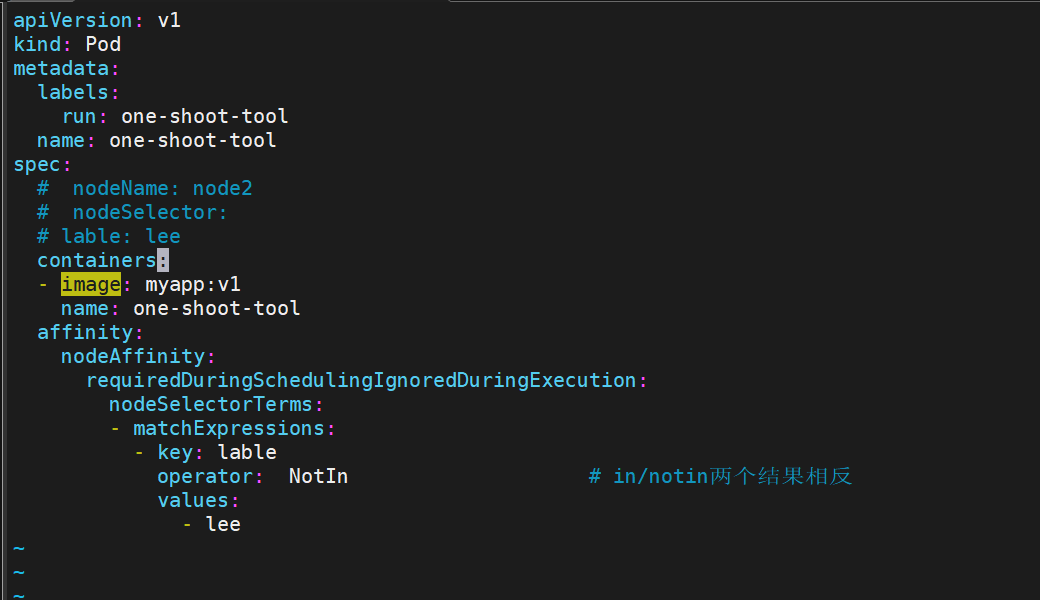
affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution: # 必须满足nodeSelectorTerms:- matchExpressions:- {key: disktype, operator: In/NotIn(#在节点中或不在), values: ["ssd"]}preferredDuringSchedulingIgnoredDuringExecution: # 尽量满足- weight: 50preference:matchExpressions:- {key: zone, operator: In, values: ["beijing"]}IgnoreDuringExecution:节点标签变更后,已运行 Pod 不动。
支持
Gt/Lt做资源范围筛选,如 cpu 核数大于 32。

3.4 Pod 间亲和与反亲和
那个节点有符合条件的POD就在那个节点运行
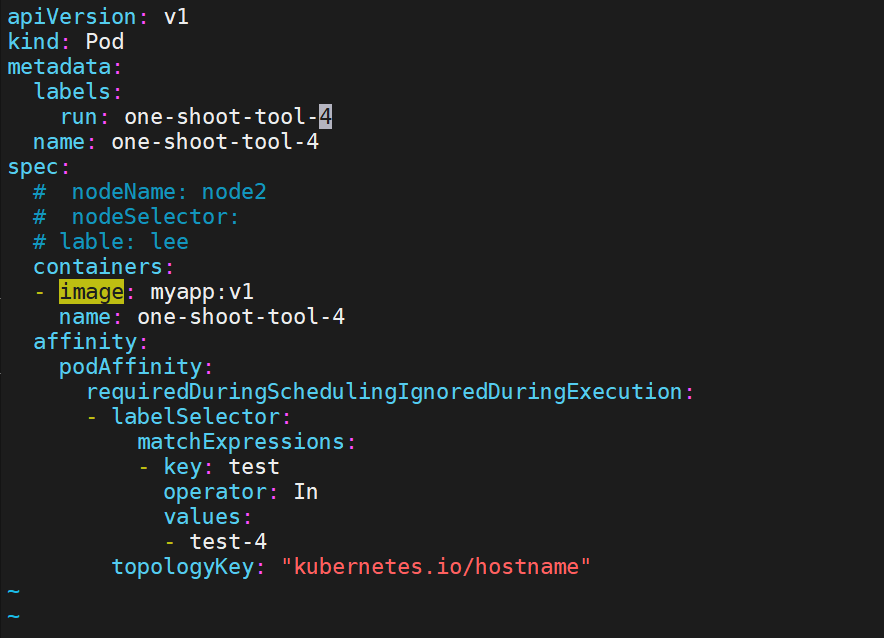
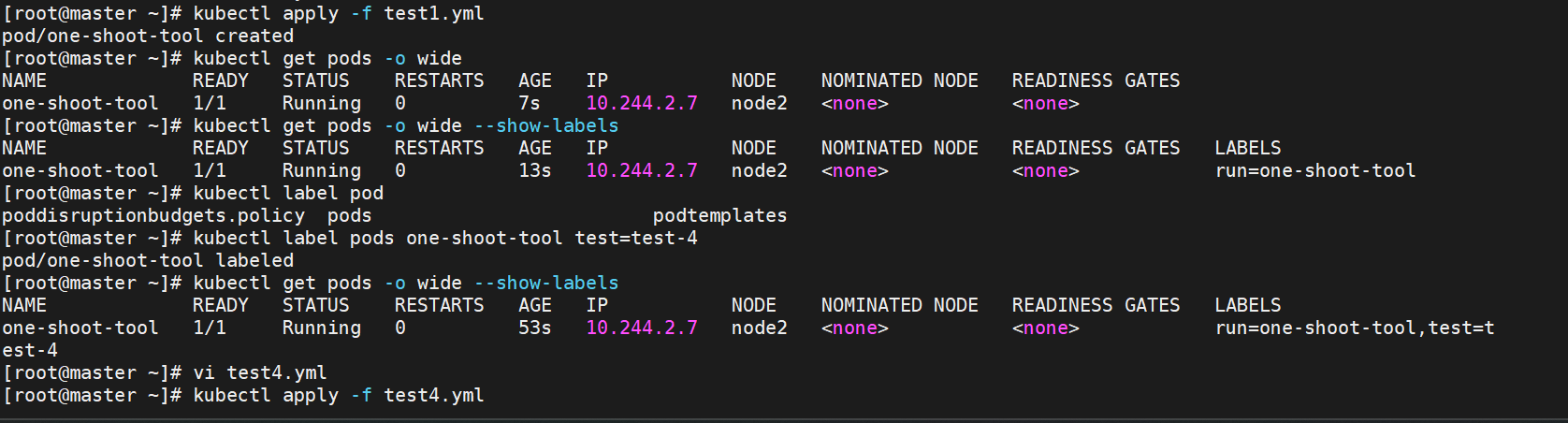
podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
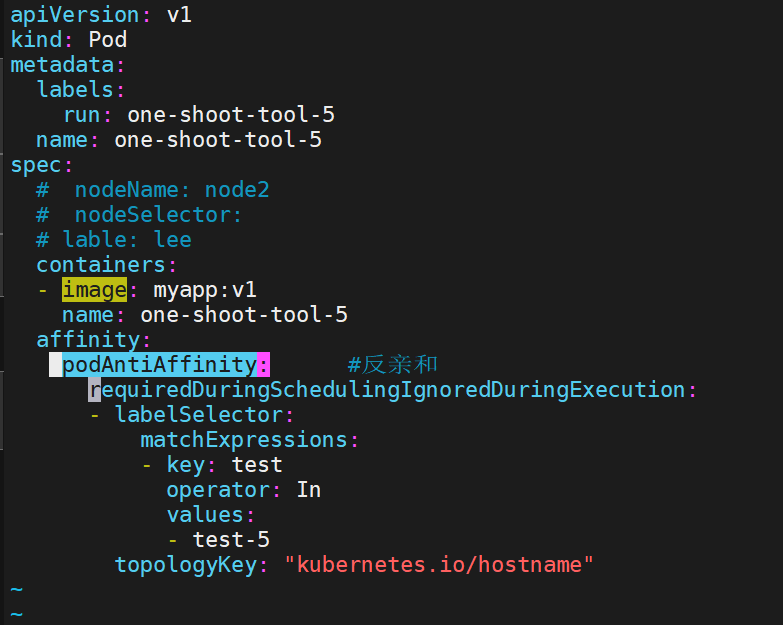
podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,
Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。
3.4.1 亲和:主要解决POD可以和哪些POD部署在同一个节点中的问题

3.4.2 反亲和:主要解决POD不能和哪些POD部署在同一个节点中的问题

经验值:大规模集群开启
topologyKey: topology.kubernetes.io/zone可实现跨可用区打散。
3.5 Taint & Toleration —— 隔离与驱逐双杀
3.5.1 概念
Taints(污点)是Node的一个属性,设置了Taints后,默认Kubernetes是不会将Pod调度到这个Node上
Kubernetes如果为Pod设置Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去
可以使用命令 kubectl taint 给节点增加一个 taint:
$ kubectl taint nodes <nodename> key=string:effect #命令执行方法
$ kubectl taint nodes node1 key=value:NoSchedule #创建
$ kubectl describe nodes server1 | grep Taints #查询
$ kubectl taint nodes node1 key- #删除其中[effect] 可取值:
| effect | 作用 | 常用场景 |
|---|---|---|
| NoSchedule | 新 Pod 不来 | GPU 节点仅跑 AI 任务 |
| PreferNoSchedule | 尽量不调度 | 线上节点留有余量 |
| NoExecute | 已运行 Pod 驱逐 | 节点维护、内核升级 |
3.5.2 实战:


测试污点容忍,node1,node2都设置为NoSchedule
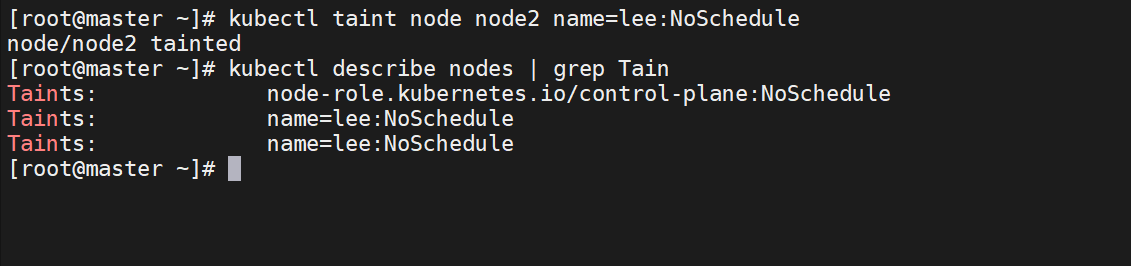
未设置容忍的则显示为pending



4. 调度器扩展:自定义策略与性能
4.1 多调度器
当默认调度器无法满足业务场景(如 GPU Binpack、Spark 动态资源)时,可部署自定义调度器并指定:
spec:schedulerName: volcano4.2 Scheduling Framework(1.19+)
通过插件链在 PreFilter / Filter / Score / Reserve / Permit / Bind 阶段插入自定义逻辑,无需重编 kube-scheduler。
示例:NodeResourcesFit、PodTopologySpread、Coscheduling(gang scheduling)。
4.3 性能调优
大规模集群建议开启
percentageOfNodesToScore(默认 50%),减少打分节点数量。监控指标:
scheduler_binding_duration_seconds、scheduler_scheduling_attempt_duration_seconds。
5. 排查 Pod 无法调度的一页速查
| 现象 | 可能原因 | 排查命令 |
|---|---|---|
| Pending | 资源不足 | kubectl describe pod → Events |
| Pending | 节点污点 | kubectl get node -o json | jq '.items[].spec.taints' |
| Pending | 亲和冲突 | kubectl get pod -o wide 查标签 |
| Pending | PVC 未绑定 | kubectl get pvc |
| Node Lost | 节点 NotReady | kubectl get node, 查 kubelet / 网络 / 磁盘 |
6. 总结与最佳实践
90% 场景
nodeSelector + nodeAffinity + podAntiAffinity 即可满足。污点策略
• 生产节点:dedicated=production:NoSchedule
• 测试节点:env=test:PreferNoSchedule大规模集群
• 避免 topologyKey 过细,减少计算量。
• 使用 namespace + 污点做物理隔离,而非反亲和暴力打散。持续治理
• 每个季度 review 节点标签、污点、调度策略。
• 用 Gatekeeper / Kyverno 做策略即代码(Policy as Code)。
附录:一键清理实验资源
kubectl delete pod,deploy --all --grace-period=0 --force









:Oracle 11g LISTAGG函数使用陷阱,缺失WITHIN子句解决方案)








)
)