Debezium实现MySQL数据监听
- 了解Debezium
- 本期主要内容
- 实现步骤
- 1. 新建Maven工程
- 2.导入依赖
- 3.核心代码编写
- 4.offset的存储
- 5.OffsetBackingStore实现jdbc模式
- 6.运行结果
- 总结
了解Debezium
官网:https://debezium.io/
Debezium是一组分布式服务,用于捕获数据库中的更改,以便应用程序可以看到这些更改并对其做出响应。Debezium在更改事件流中记录每个数据库表中的所有行级更改,应用程序只需读取这些流,以按更改事件发生的相同顺序查看更改事件。
简单来说,Debezium可以用来捕获变更数据,包括表结构or表数据的增删改,并将这些变更数据流式传递到下游,以便做进一步的操作。flink便是在此基础上实现的,但flink成本比较高昂。
本期主要内容
实现MySQL binlog数据监听功能:
- 支持无状态的全量、增量同步和有状态的全量、增量同步功能
- 通过自定义JdbcOffsetBackingStore将offset存储到数据库
实现步骤
这里使用Debezium 3.2.0.Final 版本进行测试。
1. 新建Maven工程
新建一个java项目,选择Maven构建,大家都是老司机,这里就不在赘述!
2.导入依赖
<!-- Debezium核心库 --><dependency><groupId>io.debezium</groupId><artifactId>debezium-embedded</artifactId><version>3.2.0.Final</version></dependency><!-- MySQL连接器 --><dependency><groupId>io.debezium</groupId><artifactId>debezium-connector-mysql</artifactId><version>3.2.0.Final</version></dependency><!-- 数据库驱动 (MySQL 8.0+) --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.2.0</version></dependency><dependency><groupId>com.alibaba.fastjson2</groupId><artifactId>fastjson2</artifactId><version>2.0.52</version></dependency>
3.核心代码编写
import com.alibaba.fastjson2.JSONObject;
import io.debezium.engine.ChangeEvent;
import io.debezium.engine.DebeziumEngine;
import io.debezium.engine.format.Json;import java.io.IOException;
import java.util.Objects;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;/*** @author lzq*/
public class DebeziumMysqlExample {public static void main(String[] args) {// 1. 配置Debezium连接器属性Properties props = configureDebeziumProperties();// 2. 创建Debezium引擎DebeziumEngine<ChangeEvent<String, String>> engine = DebeziumEngine.create(Json.class).using(props).notifying(DebeziumMysqlExample::processRecords).build();// 3. 启动引擎ExecutorService executor = Executors.newSingleThreadExecutor();executor.execute(engine);// 4. 注册关闭钩子,优雅退出Runtime.getRuntime().addShutdownHook(new Thread(() -> {try {System.out.println("正在关闭Debezium引擎...");engine.close();executor.shutdown();} catch (IOException e) {throw new RuntimeException(e);}}));}/*** 处理捕获到的变更事件*/private static void processRecords(ChangeEvent<String, String> record) {String value = record.value();System.out.println("捕获到变更事件 :" + value);try {if (value == null) {return;}JSONObject from = JSONObject.parse(value);JSONObject before = from.getJSONObject("before");JSONObject after = from.getJSONObject("after");String ddl = from.getString("ddl");// 操作类型 op: r(读取) c(创建), u(更新), d(删除)System.out.println("++++++++++++++++++++++++ MySQL Binlog Change Event ++++++++++++++++++++++++");System.out.println("op: " + from.getString("op"));System.out.println("change before: " + (Objects.nonNull(before) ? before.toJSONString() : "无"));System.out.println("change after: " + (Objects.nonNull(after) ? after.toJSONString() : "无"));System.out.println("ddl: " + (Objects.nonNull(ddl) ? ddl : "无"));} catch (Exception e) {e.printStackTrace();}}
}
最最重要的Debezium属性配置
/*** 配置Debezium连接器属性* */private static Properties configureDebeziumProperties() {Properties props = new Properties();// 连接器基本配置 // name可以是任务名称,任务启动后会生成相同名称的线程名props.setProperty("name", "mysql-connector");//必填项,指定topic名称前缀,虽然这里没用到kafka, 但是必须配置,否则会报错props.setProperty("topic.prefix", "bbb-");// mysql连接器全限定名,其他数据库类型时需要更换props.setProperty("connector.class", "io.debezium.connector.mysql.MySqlConnector");// 要监听的数据库连接信息props.setProperty("database.hostname", "localhost");props.setProperty("database.user", "debezium");props.setProperty("database.password", "123456");props.setProperty("database.port", "3306");//伪装成mysql从服务器的唯一Id,serverId冲突会导致其他进程被挤掉props.setProperty("database.server.id", "184055");props.setProperty("database.server.name", "mysql-server");// 监听的数据库props.setProperty("database.include.list", "course_db");// 监听的表props.setProperty("table.include.list", "course_db.course_2");// 快照模式// initial(历史+增量)// initial_only(仅读历史)// no_data(同schema_only) 仅增量,读取表结构的历史和捕获增量,以及表数据的增量// schema_only_recovery(同recovery) 从指定offset恢复读取,暂未实现props.setProperty("snapshot.mode", "initial");// 偏移量刷新间隔props.setProperty("offset.flush.interval.ms", "5000");// 偏移量存储 文件props.setProperty("offset.storage", "org.apache.kafka.connect.storage.FileOffsetBackingStore");// 会在项目目录下生成文件props.setProperty("offset.storage.file.filename", "mysql-offset.dat");// 是否包含数据库表结构层面的变更 默认值trueprops.setProperty("include.schema.changes", "false");// 是否仅监听指定表的ddl变更 默认值false, false会监听所有schema的表结构变更props.setProperty("schema.history.internal.store.only.captured.tables.ddl", "true");// 表结构历史存储(可选)props.setProperty("schema.history.internal", "io.debezium.storage.file.history.FileSchemaHistory");props.setProperty("schema.history.internal.file.filename", "schema-history.dat");// Debezium 3.2新特性: 启用新的记录格式props.setProperty("value.converter", "org.apache.kafka.connect.json.JsonConverter");props.setProperty("value.converter.schemas.enable", "false");return props;}
4.offset的存储
官网对于offset store 的介绍提供了这些实现讲解,但connect-runtime包中只提供了前3种实现分别是kafka、file、memory。
其中file方式适用于单机版和测试场景;memory方式适用于测试场景或短期任务,不适用生产环境;而kafka方式存在局限性,本人在使用过程中发现创建的topic 必须配置清除策略为压缩(即cleanup.policy=compact),而公司使用的是阿里云的kafka,暂无法创建压缩策略的topic。
所以这几种方式都无法满足生产要求,只能另谋他路,于是决定自己实现数据库存储offset。

5.OffsetBackingStore实现jdbc模式
我们看到file/kafka/memory 最终都实现了 OffsetBackingStore,所以我们也需要实现它来编写我们的 JdbcOffsetBackingStore。
这里实现逻辑是多个task共用一张表来存储offset,每个任务只存一条offset数据,其中上述配置中的name和topic.prefix不同,生成的offset_key 就不同,配置时要注意不要配置相同的name和topic.prefix的组合值。
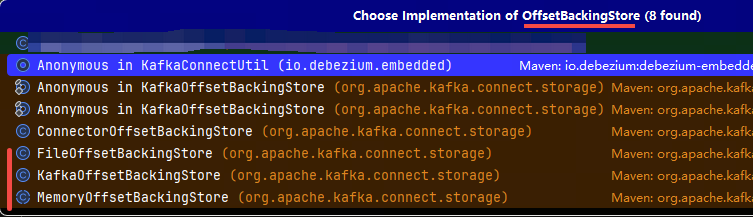
废话不多说,上代码
package com.kw.debzium.debeziumdemo.debez.storege;import com.md.util.Snowflake;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.connect.errors.ConnectException;
import org.apache.kafka.connect.runtime.WorkerConfig;
import org.apache.kafka.connect.storage.OffsetBackingStore;
import org.apache.kafka.connect.util.Callback;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
import java.sql.*;
import java.time.Instant;
import java.util.*;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.Future;/*** @author lzq*/
public class JdbcOffsetBackingStore implements OffsetBackingStore {private static final Logger log = LoggerFactory.getLogger(JdbcOffsetBackingStore.class);//这里使用雪花算法生成表主键Id,可根据实际情况调整public static final Snowflake SNOWFLAKE = new Snowflake(1, 1);private String tableName;private Connection connection;@Overridepublic void start() {log.info("Starting JdbcOffsetBackingStore");try {// 创建表结构createOffsetTableIfNotExists();} catch (SQLException e) {throw new ConnectException("Failed to start JdbcOffsetBackingStore", e);}}@Overridepublic void stop() {log.info("Stopping JdbcOffsetBackingStore");if (connection != null) {try {connection.close();} catch (SQLException e) {log.warn("Error while closing JDBC connection", e);}}}@Overridepublic Future<Map<ByteBuffer, ByteBuffer>> get(Collection<ByteBuffer> keys) {return CompletableFuture.supplyAsync(() -> {Map<ByteBuffer, ByteBuffer> result = new HashMap<>();for (ByteBuffer key : keys) {ByteBuffer value = getOffset(key);if (value != null) {result.put(key, value);}}return result;});}@Overridepublic Future<Void> set(Map<ByteBuffer, ByteBuffer> values, Callback<Void> callback) {return CompletableFuture.runAsync(() -> {for (Map.Entry<ByteBuffer, ByteBuffer> entry : values.entrySet()) {setOffset(entry.getKey(), entry.getValue());}if (callback != null) {callback.onCompletion(null, null);}});}@Overridepublic Set<Map<String, Object>> connectorPartitions(String connectorName) {return Set.of();}@Overridepublic void configure(WorkerConfig config) {Map<String, Object> originals = config.originals();String jdbcUrl = (String) originals.getOrDefault(JdbcWorkerConfig.OFFSET_STORAGE_JDBC_URL_CONFIG, "");String username = (String) originals.getOrDefault(JdbcWorkerConfig.OFFSET_STORAGE_JDBC_USER_CONFIG, "");String password = (String) originals.getOrDefault(JdbcWorkerConfig.OFFSET_STORAGE_JDBC_PASSWORD_CONFIG, "");tableName = (String) originals.getOrDefault(JdbcWorkerConfig.OFFSET_STORAGE_JDBC_TABLE_NAME_CONFIG, "");try {// 建立数据库连接connection = DriverManager.getConnection(jdbcUrl, username, password);} catch (SQLException e) {throw new ConnectException("Failed to configure JdbcOffsetBackingStore", e);}}/*** 创建offset存储表(如果不存在)** @throws SQLException SQL执行异常*/private void createOffsetTableIfNotExists() throws SQLException {String createTableSQL = String.format("CREATE TABLE IF NOT EXISTS %s (" +"id BIGINT(20) NOT NULL primary key ," +"offset_key VARCHAR(1255)," +"offset_val VARCHAR(1255)," +"record_insert_ts TIMESTAMP NOT NULL" +")", tableName);try (PreparedStatement stmt = connection.prepareStatement(createTableSQL)) {stmt.execute();}}/*** 从数据库获取指定key的offset值** @param key 键* @return 对应的offset值*/private ByteBuffer getOffset(ByteBuffer key) {String keyStr = bytesToString(key);String selectSQL = String.format("SELECT offset_val FROM %s WHERE offset_key = ? ORDER BY record_insert_ts desc limit 1", tableName);try (PreparedStatement stmt = connection.prepareStatement(selectSQL)) {stmt.setString(1, keyStr);ResultSet rs = stmt.executeQuery();if (rs.next()) {String valueStr = rs.getString(1);return StringUtils.isNotBlank(valueStr) ? ByteBuffer.wrap(valueStr.getBytes()) : null;}} catch (SQLException e) {log.error("Error getting offset for key: {}", keyStr, e);}return null;}/*** 将offset值存储到数据库* 这里插入和删除没有添加事务,是因为我这边想用一张表来存储多个task的 offset,测试当两个task同时删除数据时,会导致后者删除的操作失败* 在取数据时是按时间倒排,取最新一条,所以某次删除失败不影响最终结果* @param key 键* @param value 值*/private void setOffset(ByteBuffer key, ByteBuffer value) {if (Objects.isNull(key) || Objects.isNull(value)) {return;}String keyStr = bytesToString(key);byte[] valueBytes = value.array();String valueStr = new String(valueBytes, StandardCharsets.UTF_8);try {// 插入新的offsetinsertNewOffset(keyStr, valueStr);// 删除最旧的offsetdeleteOldestOffsetIfNeeded(keyStr);log.info("Offset stored success for key: {}, value: {}", keyStr, valueStr);} catch (SQLException e) {log.error("Error setting offset for key: {}", keyStr, e);}}private void insertNewOffset(String keyStr, String valueStr) throws SQLException {String upsertSQL = String.format("INSERT INTO %s(id, offset_key, offset_val, record_insert_ts) VALUES ( ?, ?, ?, ? )",tableName);try (PreparedStatement stmt = connection.prepareStatement(upsertSQL)) {long id = SNOWFLAKE.nextId();stmt.setLong(1, id);stmt.setString(2, keyStr);stmt.setString(3, valueStr);stmt.setTimestamp(4, Timestamp.from(Instant.now()));stmt.executeUpdate();}}private void deleteOldestOffsetIfNeeded(String keyStr) {//count > 2 执行删除最旧的offsetint count = 0;try (PreparedStatement stmt = connection.prepareStatement("SELECT COUNT(*) FROM " + tableName + " WHERE offset_key = ?")) {stmt.setString(1, keyStr);ResultSet rs = stmt.executeQuery();if (rs.next()) {count = rs.getInt(1);}} catch (SQLException e) {log.error("Error counting offsets", e);}if (count > 1) {String deleteSQL = String.format("DELETE FROM %s WHERE offset_key = ? " +"AND id < (SELECT * FROM (SELECT MAX(id) FROM %s WHERE offset_key = ?) AS tmp)",tableName, tableName);try (PreparedStatement stmt = connection.prepareStatement(deleteSQL)) {stmt.setString(1, keyStr);stmt.setString(2, keyStr);int deletedRows = stmt.executeUpdate();if (deletedRows > 0) {log.info("Deleted oldest offset");}} catch (SQLException e) {log.error("Error deleting oldest offset", e);}}}/*** 将ByteBuffer转换为字符串表示** @param buffer ByteBuffer对象* @return 字符串表示*/private String bytesToString(ByteBuffer buffer) {if (Objects.isNull(buffer)) {return null;}byte[] bytes = new byte[buffer.remaining()];buffer.duplicate().get(bytes);return new String(bytes);}
}
配置类继承WorkerConfig
import org.apache.kafka.common.config.ConfigDef;
import org.apache.kafka.connect.runtime.WorkerConfig;import java.util.Map;/*** Worker config for JdbcOffsetBackingStore* @author lzq*/
public class JdbcWorkerConfig extends WorkerConfig {private static final ConfigDef CONFIG;/*** The jdbc info of the offset storage jdbc.*/public static final String OFFSET_STORAGE_JDBC_URL_CONFIG = "offset.storage.jdbc.connection.url";private static final String OFFSET_STORAGE_JDBC_URL_DOC = "database to store source connector offsets";public static final String OFFSET_STORAGE_JDBC_USER_CONFIG = "offset.storage.jdbc.connection.user";private static final String OFFSET_STORAGE_JDBC_USER_DOC = "database of user to store source connector offsets";public static final String OFFSET_STORAGE_JDBC_PASSWORD_CONFIG = "offset.storage.jdbc.connection.password";private static final String OFFSET_STORAGE_JDBC_PASSWORD_DOC = "database of password to store source connector offsets";public static final String OFFSET_STORAGE_JDBC_TABLE_NAME_CONFIG = "offset.storage.jdbc.table.name";private static final String OFFSET_STORAGE_JDBC_TABLE_NAME_DOC = "table name to store source connector offsets";static {CONFIG = baseConfigDef().define(OFFSET_STORAGE_JDBC_URL_CONFIG,ConfigDef.Type.STRING,ConfigDef.Importance.HIGH,OFFSET_STORAGE_JDBC_URL_DOC).define(OFFSET_STORAGE_JDBC_USER_CONFIG,ConfigDef.Type.STRING,ConfigDef.Importance.HIGH,OFFSET_STORAGE_JDBC_USER_DOC).define(OFFSET_STORAGE_JDBC_PASSWORD_CONFIG,ConfigDef.Type.STRING,ConfigDef.Importance.HIGH,OFFSET_STORAGE_JDBC_PASSWORD_DOC).define(OFFSET_STORAGE_JDBC_TABLE_NAME_CONFIG,ConfigDef.Type.STRING,ConfigDef.Importance.HIGH,OFFSET_STORAGE_JDBC_TABLE_NAME_DOC);}public JdbcWorkerConfig(Map<String, String> props) {super(CONFIG, props);}
}6.运行结果
去掉文件offset配置,将offset.storage配置调整为
// 偏移量存储 数据库 包路径、数据库信息改成自己的props.setProperty("offset.storage", "com.kw.debzium.debeziumdemo.storege.JdbcOffsetBackingStore");props.setProperty("offset.storage.jdbc.connection.url", "jdbc:mysql://localhost:3306/course_db");props.setProperty("offset.storage.jdbc.connection.user", "debezium");props.setProperty("offset.storage.jdbc.connection.password", "123456");props.setProperty("offset.storage.jdbc.table.name", "course_db.tbl_offset_storage");

这里是两个任务只有 name和topic.prefix 、server.id不同,一个main方法,监听的同一个表,启了两次,所以pos ,gtids是一样的.
重启任务,发现已从数据库加载到了上次消费到的offset记录
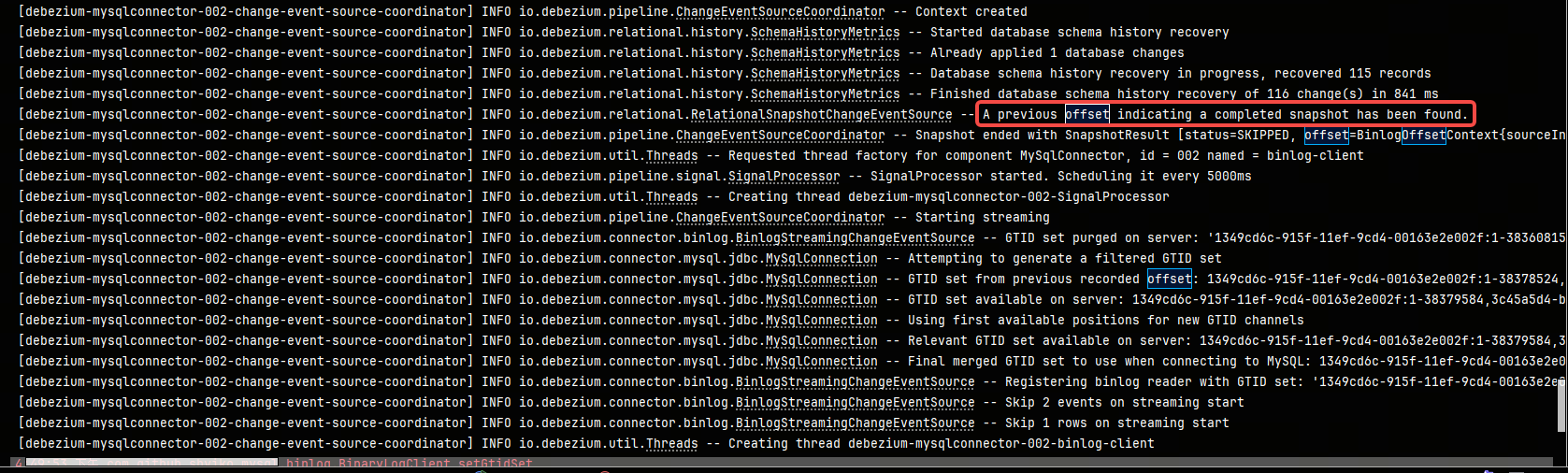
至此已实现断点续传功能!
总结
根据官网说明,通过一些配置,即可实现从mysql binlog中监听数据,并实时打印数据变更结果。根据offset实现状态存储到数据库,最终实现断点续传功能。
接下来,将结合spring boot 实现多任务启动,并实现sink到kafka or db ,敬请期待!
)



)



 |)


 的界面和功能)
![[NCTF2019]True XML cookbook](http://pic.xiahunao.cn/[NCTF2019]True XML cookbook)






