庖丁解牛:基于YOLO12与OpenCV的车辆部件级实例分割实战(附完整代码)
摘要: 告别“只见整车不见细节”!本文将带您深入实战,利用YOLO12-seg训练实例分割模型,结合OpenCV的强大图像处理能力,实现对车辆23个精细部件(从前后保险杠到左右后视镜、车轮等)的像素级精准识别与分割。我们将完整展示从模型加载、推理到结果可视化与信息提取的全流程,代码即学即用,助您构建下一代智能车辆分析系统!
关键词: YOLO12, 实例分割, 车辆部件检测, OpenCV, 计算机视觉, 深度学习, Python
【图像算法 - 16】庖丁解牛:基于YOLO12与OpenCV的车辆部件级实例分割实战
1. 引言:驶向精细化的车辆感知新时代
在自动驾驶、智能维修、保险定损、工业质检等前沿领域,对车辆的感知已从“有没有车”进化到“车的哪个部件出了问题”。传统的整车检测或粗略的目标检测已无法满足需求。我们需要一种技术,能够像“庖丁解牛”一样,精确地识别并分割出车辆的每一个独立部件。
实例分割 (Instance Segmentation) 技术正是为此而生。它不仅能告诉您“这里有辆车”,更能精确指出“这是左前大灯”、“那是右后轮”,并描绘出它们真实的、像素级的轮廓。
本文将揭秘:一个基于YOLO12架构、在自定义高质量数据集上训练的YOLO12-seg模型。该模型能够精准识别您提供的23个车辆部件类别。我们将结合OpenCV,将这一强大的AI能力转化为直观、可量化的视觉结果。
2. 我们的利器:YOLO12-seg模型与OpenCV
- YOLO12-seg 模型:
- 高度定制化: 该模型并非通用模型,而是专门针对车辆部件识别任务,在包含23个精细类别的数据集上进行端到端训练。模型深度理解了车辆部件的形态、纹理和空间关系。
- 卓越精度: YOLO12架构的先进性(如更高效的特征提取网络、优化的分割头设计)确保了在复杂场景下对细小部件(如车灯)和易混淆部件(如不同车门)的高精度分割。
- 生产就绪: 模型已通过充分验证,可直接部署于实际应用场景。
- OpenCV:
- 结果呈现大师: 负责将模型输出的抽象掩码数据,转化为人类可直观理解的彩色叠加图、清晰轮廓线。
- 信息提取引擎: 利用其强大的图像处理函数,我们可以轻松计算每个部件的面积、周长,甚至进行形态学分析。
- 流程集成枢纽: 作为连接AI模型与应用系统的桥梁,实现无缝的图像处理流水线。
3. 数据基石:23类精细车辆部件数据集
3.1数据集介绍
模型的卓越性能源于高质量的数据。训练数据集经过精心构建,包含:
-
车辆部件分割数据集中的数据分布组织如下(下载链接):
- 训练集: 包括 3156 张图像,每张图像都附有相应的注释。该集合用于训练深度学习模型。
- 测试集:包含 276 张图像,每张图像都与其各自的注释配对。此集合用于在使用测试数据进行训练后评估模型的性能。
- 验证集:包含 401 张图像,每张图像都有相应的注释。此集合在训练期间用于调整超参数,并使用验证数据防止过拟合。
-
类别 (23类):
覆盖了车辆的主要外部部件,定义清晰,无歧义。
names:0: back_bumper # 后保险杠1: back_door # 后车门 (整体)2: back_glass # 后挡风玻璃3: back_left_door # 左后车门4: back_left_light # 左后尾灯5: back_light # 后尾灯 (整体,若存在)6: back_right_door # 右后车门7: back_right_light # 右后尾灯8: front_bumper # 前保险杠9: front_door # 前车门 (整体)10: front_glass # 前挡风玻璃11: front_left_door # 左前车门12: front_left_light # 左前大灯13: front_light # 前大灯 (整体,若存在)14: front_right_door # 右前车门15: front_right_light # 右前大灯16: hood # 发动机盖17: left_mirror # 左后视镜18: object # (可能为背景或其他物体,使用时注意)19: right_mirror # 右后视镜20: tailgate # 后备箱门 (SUV/两厢车)21: trunk # 行李箱盖 (三厢车)22: wheel # 车轮 (所有)
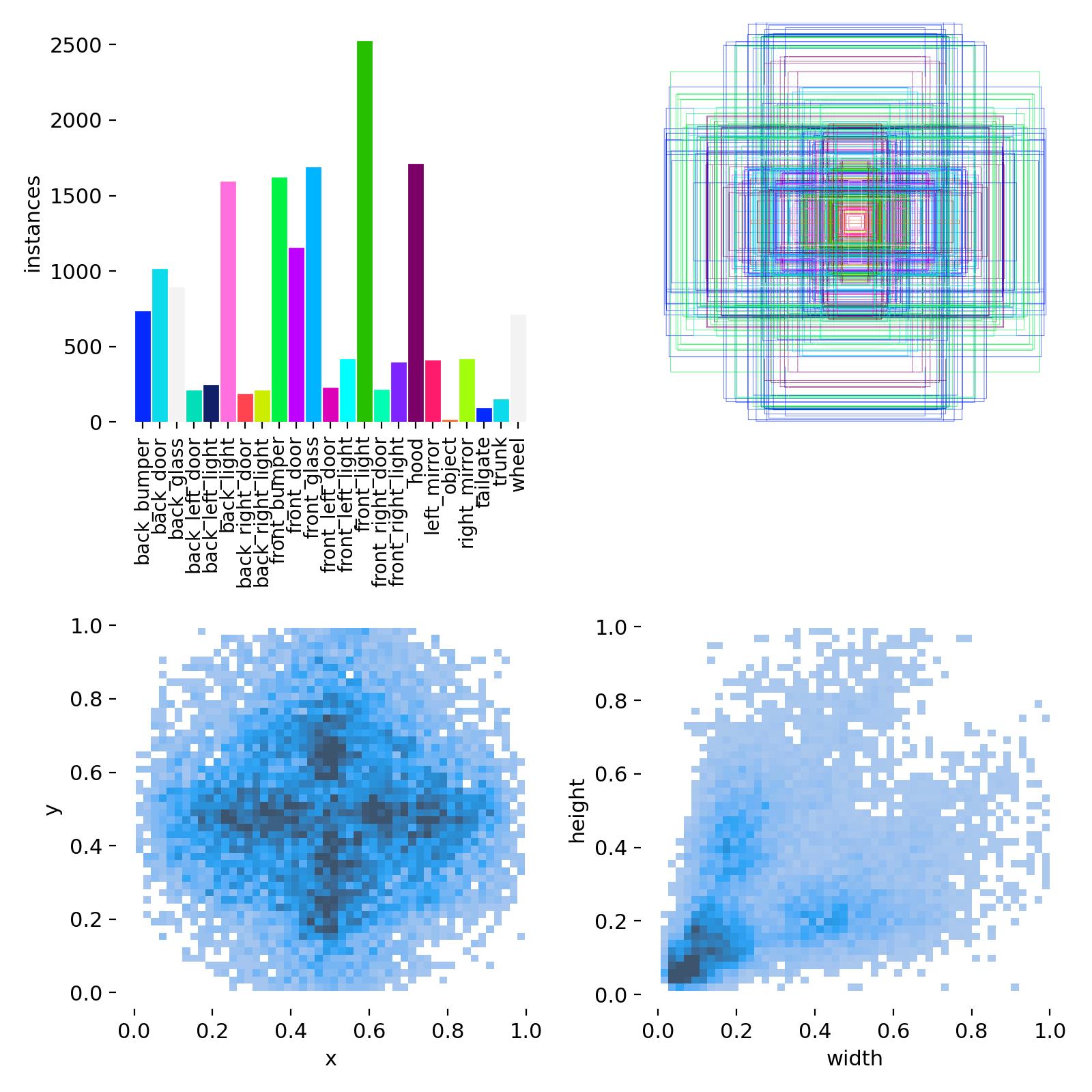
-
标注质量: 采用多边形工具进行像素级精确标注,确保掩码边缘与部件真实边界高度吻合。
-
数据多样性: 包含不同品牌、型号、颜色、光照条件、拍摄角度(正面、侧面、斜角、俯视)和部分遮挡场景的车辆图像,保证了模型的泛化能力。


4.2 数据标注(如需)
- 工具推荐: LabelMe, CVAT, Roboflow。
- labelme数据标注保姆级教程:从安装到格式转换全流程,附常见问题避坑指南(含视频讲解)
- 标注要求: 为每一张图像中的每一个汽车部件绘制精确的多边形轮廓(Polygon)。标注工具会生成对应的JSON或COCO格式的标注文件。
- 数据格式: YOLO12支持 COCO格式 或其自定义的 YOLO格式(文本文件,每行代表一个实例:
class_id center_x center_y width height+ 多个x y坐标对表示分割点)。我们通常使用COCO格式。
4.3 数据增强 (Data Augmentation)
YOLO12在训练时默认应用了强大的数据增强策略(如Mosaic, MixUp, 随机旋转、缩放、裁剪、色彩抖动等),这有助于提高模型的泛化能力,防止过拟合,尤其在数据量有限时效果显著。
- Mosaic
- 当你看到 mosaic: 1.0,这意味着在数据增强过程中使用了 Mosaic 技术,并且其强度或概率设置为最大值(1.0)。Mosaic 数据增强方法通过将四张图片随机裁剪并拼接成一张图片来创建新的训练样本。这有助于模型学习如何在不同的环境中识别目标,特别是当对象只占据了图像的一部分时。
- MixUp
- 对于 mixup: 0.0,这表示不使用 Mixup 方法或者该方法的应用概率为最低(0.0)。Mixup 是一种更温和的数据增强策略,它通过线性插值的方式在两张图片及其标签之间生成新的训练样本。例如,如果你有两张图片 A 和 B,Mixup 可能会生成一个新的图片 C,其中 C 的像素是 A 和 B 像素的加权平均值,
5. 环境准备
【图像算法 - 01】保姆级深度学习环境搭建入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍+文末有视频讲解)
5.1模型训练
5.1.1 配置文件 (carparts-seg.yaml) 创建一个 carparts-seg.yaml 文件,描述数据集路径和类别信息:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]path: ../datasets/carparts-seg # dataset root dir
train: images/train # train images (relative to 'path') 3516 images
val: images/val # val images (relative to 'path') 276 images
test: images/test # test images (relative to 'path') 401 images# Classesnames:0: back_bumper1: back_door2: back_glass3: back_left_door4: back_left_light5: back_light6: back_right_door7: back_right_light8: front_bumper9: front_door10: front_glass11: front_left_door12: front_left_light13: front_light14: front_right_door15: front_right_light16: hood17: left_mirror18: object19: right_mirror20: tailgate21: trunk22: wheel
5.1.2 开始训练 使用一行命令即可启动训练!Ultralytics提供了丰富的参数供调整。
from ultralytics import YOLO# 加载已训练的YOLO12分割模型
model = YOLO('yolo12-seg.yaml') # 推荐使用s或m版本在精度和速度间平衡# 开始训练
results = model.train(data='carparts-seg.yaml', # 指定数据配置文件epochs=100, # 训练轮数imgsz=640, # 输入图像尺寸batch=16, # 批次大小 (根据GPU显存调整)name='carparts_seg_v1', # 实验名称,结果保存在 runs/segment/carparts_seg_v1/device=0, # 使用GPU 0, 多GPU用 [0, 1, 2]# 以下为可选高级参数# optimizer='AdamW', # 优化器# lr0=0.01, # 初始学习率# lrf=0.01, # 最终学习率 (lr0 * lrf)# patience=20, # EarlyStopping 耐心值# augment=True, # 是否使用Mosaic等增强 (默认True)# fraction=1.0, # 使用数据集的比例# project='my_projects', # 结果保存的项目目录
)
训练结束后内容生成:
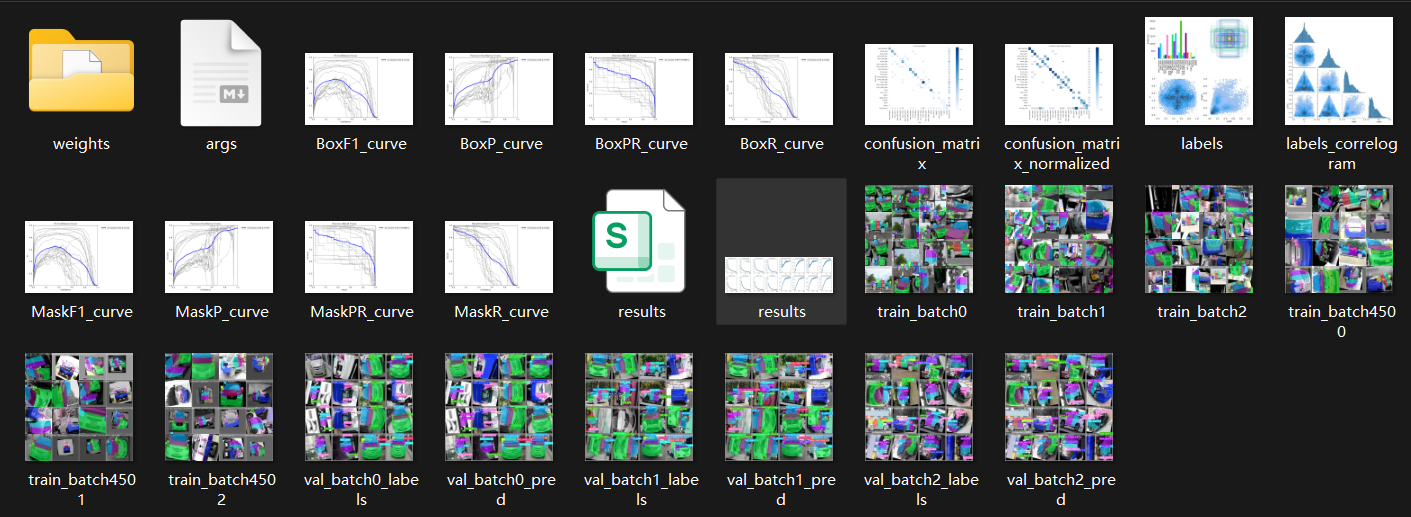
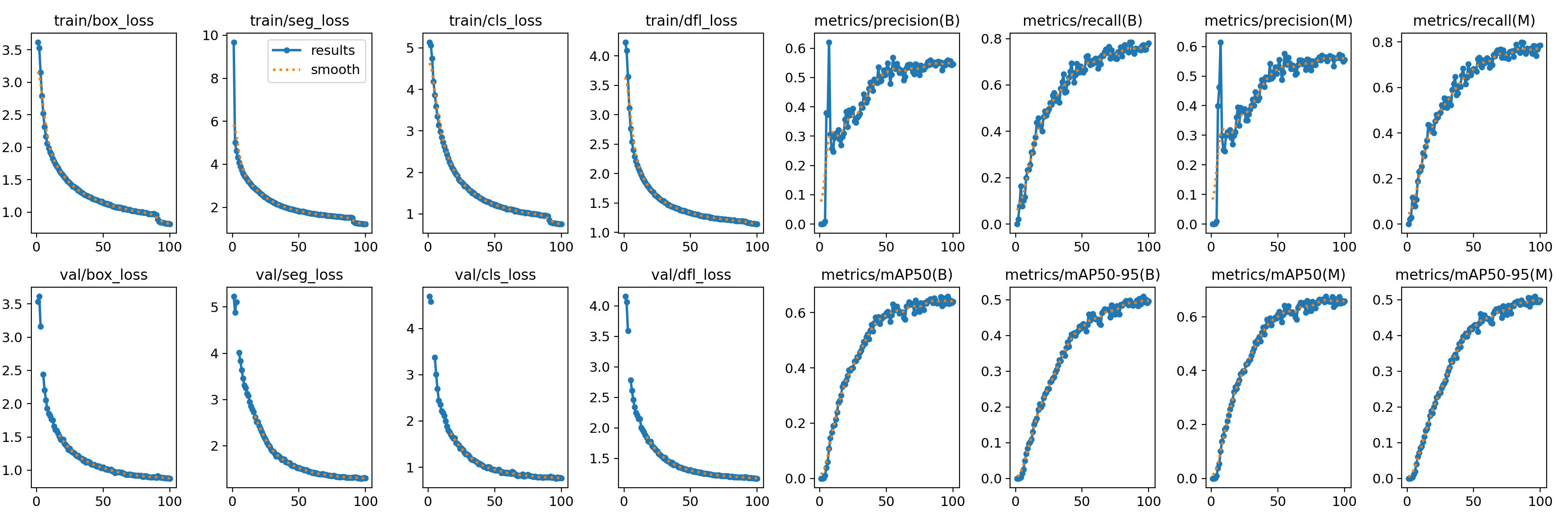
5.1.3 训练过程监控
- 训练过程中,Ultralytics会实时打印损失值(
box_loss,seg_loss,cls_loss,dfl_loss)和评估指标(precision,recall,mAP50,mAP50-95)。 - 在
runs/segment/carparts_seg_v1/目录下会生成详细的训练日志、指标曲线图(如results.png)和最佳权重文件(weights/best.pt)。
6. 核心代码实现:车辆部件分割全流程
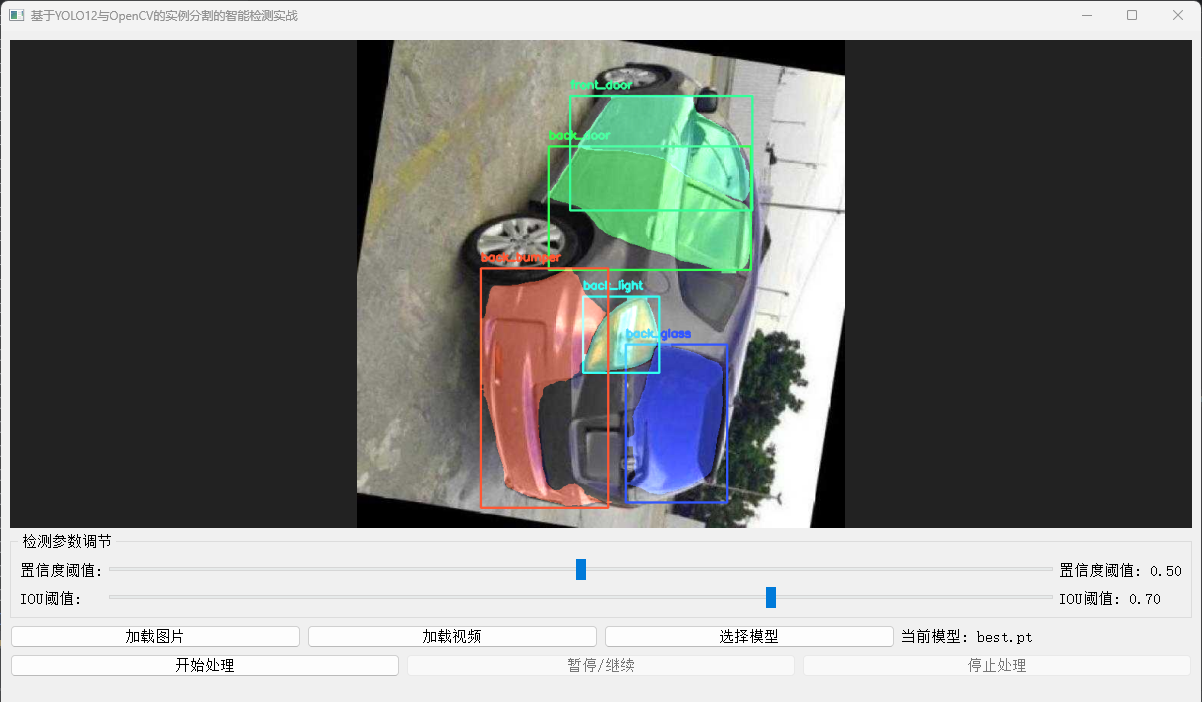
以下代码展示了如何加载我们的模型并进行推理与可视化。
car_parts_with_colors = {0: {"name": "back_bumper", "color": (51, 87, 255)}, # 橙色 (BGR)1: {"name": "back_door", "color": (87, 255, 51)}, # 绿色2: {"name": "back_glass", "color": (255, 87, 51)}, # 蓝色3: {"name": "back_left_door", "color": (51, 255, 243)},# 黄色4: {"name": "back_left_light", "color": (243, 51, 255)},# 粉色5: {"name": "back_light", "color": (243, 255, 51)}, # 青色6: {"name": "back_right_door", "color": (255, 51, 243)},# 紫色7: {"name": "back_right_light", "color": (51, 153, 255)},# 橙黄色8: {"name": "front_bumper", "color": (255, 51, 153)}, # 紫罗兰色9: {"name": "front_door", "color": (153, 255, 51)}, # 青绿色10: {"name": "front_glass", "color": (51, 255, 153)}, # 淡绿色11: {"name": "front_left_door", "color": (51, 51, 255)},# 红色12: {"name": "front_left_light", "color": (255, 51, 51)},# 深蓝色13: {"name": "front_light", "color": (255, 51, 102)}, # 靛蓝色14: {"name": "front_right_door", "color": (102, 255, 51)},# 浅绿色15: {"name": "front_right_light", "color": (51, 102, 255)},# 橙红色16: {"name": "hood", "color": (51, 255, 102)}, # 淡黄绿色17: {"name": "left_mirror", "color": (255, 102, 51)}, # 天蓝色18: {"name": "object", "color": (153, 153, 153)}, # 灰色19: {"name": "right_mirror", "color": (153, 153, 255)},# 淡红色20: {"name": "tailgate", "color": (153, 255, 153)}, # 淡青色21: {"name": "trunk", "color": (255, 153, 153)}, # 淡紫色22: {"name": "wheel", "color": (0, 0, 0)} # 黑色
}def process_frame(self, frame, conf=None, iou=None):"""处理单帧图像并统计目标数量"""current_conf = conf if conf is not None else self.confcurrent_iou = iou if iou is not None else self.iouoriginal_h, original_w = frame.shape[:2]# 目标检测results = self.model(frame,conf=current_conf,iou=current_iou,stream=False)carparts_count = 0# 绘制边界框并计数for result in results:boxes = result.boxes.xyxy.cpu().numpy()classes = result.boxes.cls.cpu().numpy().astype(int)# 检查是否有掩码if result.masks is not None:masks = result.masks.data.cpu().numpy() # (N, 640, 640)else:masks = []for i, (box, cls_id) in enumerate(zip(boxes, classes)):x1, y1, x2, y2 = map(int, box)label = car_parts_with_colors[cls_id]['name']carparts_count+= 1# 绘制边界框cv2.rectangle(frame, (x1, y1), (x2, y2), car_parts_with_colors[cls_id]['color'], 2)# # ✅ 使用 masks.data 绘制掩码if i < len(masks): # 安全检查mask640 = masks[i] # (H, W),值为 0~1# mask = (mask > 0.5).astype(np.uint8) * 255 # 二值化mask = cv2.resize(mask640, (original_w, original_h), interpolation=cv2.INTER_NEAREST)mask = (mask > 0.5).astype(np.uint8) * 255color_mask = np.zeros_like(frame)color_mask[mask == 255] = car_parts_with_colors[cls_id]['color']frame = cv2.addWeighted(frame, 1.0, color_mask, 0.5, 0)cv2.putText(frame, label, (x1, y1 - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.5, car_parts_with_colors[cls_id]['color'], 2)# 发送统计结果self.update_stats_signal.emit(carparts_count)return frame, results6. 代码详解与关键点
- 模型加载 (
YOLO(MODEL_PATH)): 这是核心,MODEL_PATH必须指向您训练好的.pt文件。Ultralytics库会自动识别YOLO12架构。 - 掩码尺寸调整 (
cv2.resize): 这是最容易出错的地方。masks.data的尺寸是模型的输入尺寸(如640x640),必须使用cv2.resize并配合INTER_NEAREST插值法,将其精确缩放到原始输入图像的尺寸(original_width, original_height),否则可视化和面积计算将完全错误。 - 类别处理: 代码中
names字典直接来自您训练模型时的数据配置,包含了全部23个类别。通过interested_ids可以灵活筛选关注的部件。 - 可视化融合:
cv2.addWeighted实现了优雅的半透明叠加。cv2.drawContours绘制的黄色轮廓线使得部件边界在复杂背景下依然清晰可辨。 - 信息量化:
mask_resized.sum()给出了该部件在图像中的像素覆盖面积,这是进行后续分析(如相对大小比较、损伤评估)的基础。
7. 应用场景与价值
- 智能维修诊断: 上传车辆照片,AI自动识别所有部件并高亮,维修人员可快速定位问题区域。计算破损部件的面积以估算维修成本。
- 保险定损自动化: 快速、客观地评估事故车辆的损伤部件和程度,生成标准化报告,减少人为争议。
- 自动驾驶感知增强: 让自动驾驶系统“看清”周围车辆的细节,例如判断前车是否打转向灯(通过识别对应侧尾灯状态)、是否开启双闪等。
- 车辆生产与质检: 在生产线终端自动检测车辆部件是否齐全、安装是否正确、有无划痕或凹陷。
- AR汽车展示/改装: 在手机或平板上,用户可以看到车辆各部件的名称,并预览更换不同部件(如轮毂、车灯)后的效果。
8. 总结
本文成功展示了如何利用我们自主训练的YOLO12-seg实例分割模型和OpenCV,实现对车辆23个精细部件的精准识别与分割。这套方案不仅提供了“是什么”的答案,更给出了“在哪里”和“有多大”的精确信息。



详解和完整示例)




变量的梯度)



摘自Openloong社区)
 查找速度深度对比)

)

包括机器学习方法预测缺失值的实践)

