学习路径
一、环境准备与快速入门
- 搭建开发环境
○ 安装 CUDA Toolkit,适用于 Windows(如 Visual Studio)或 Linux,确保你的设备为 NVIDIA GPU 并支持 CUDA。(wholetomato.com)
○ 如果你偏好轻量工具,也可用 VS Code + Nsight 开发环境进行 CUDA 编程。(wholetomato.com) - 编写第一个 CUDA 程序
○ 阅读并实操《An Even Easier Introduction to CUDA》(2025 年更新),完成基础 C++ 数组加法示例,理解 global、kernel launch (<<<…>>>) 等核心概念。(NVIDIA Developer)
○ 参考 “Hello from CUDA” 教程,比较 C 和 CUDA 的 “Hello World” 实现,快速了解 host 与 device 代码结构的不同。(CUDA 教程)
二、核心概念与编程模型
- 理解 CUDA 编程抽象
○ 学会划分 thread、thread block 与 grid,掌握它们如何映射到 GPU 硬件执行单元、共享内存与同步机制。(维基百科)
○ 掌握**主机(Host)与设备(Device)**的协作流程:内存分配、数据拷贝、kernel 调用、结果回传等 — 这是 CUDA 程序的基本框架。(MolSSI Education, NVIDIA Docs) - 深入 CUDA API 与编程指南
○ 熟读 NVIDIA 官方的 CUDA C Programming Guide,了解编译工具 (nvcc)、运行时 API、性能优化建议等,是 CUDA 编程的权威指南。(NVIDIA Docs)
三、实战练习 — 从简单到复杂
- 基础练习
○ 编写基本数值运算:向量加法、矩阵–向量乘法、grid reduction 类练习,帮助你理解线程布局与数据并行。(NVIDIA Developer Forums) - 由串行向并行演进
○ 首先用传统循环实现算法,再逐步映射至 CUDA kernel;
○ 从使用 global memory 起步,再逐步优化至 shared memory 和寄存器;进阶时引入 Tensor Core (MMMA/ MMA) 优化。(黑客新闻) - Python & PyTorch 用户专用路径
○ 如果你熟悉 PyTorch,可参考 PyTorch 官方的 custom CUDA extension 教程:实现 kernel、绑定 C++,并在 Python 中调用。有用户评论称这是“一个很不错的入门途径”。(Reddit)
○ 综合实战可参考 GitHub 上的 GPU-Puzzles 项目,练习具体问题。(Reddit)
四、性能调优与工具应用
- 优化思路
○ 常用策略:先构建可运行结果,再逐步追求性能优化;
○ 精进路径:优化数据传输 → 使用 shared memory → 寄存器优化 → 高级特性(如 Tensor Core)优化。(黑客新闻) - 调试工具
○ 推荐使用 Nsight Systems / Nsight Compute 进行性能分析与调试;
○ 实战中要学会使用 compute-sanitizer,发现内存错误或线程同步问题,有开发者指出:“大多数时间会花在调试为什么速度比想象中慢”。(黑客新闻) - 高级抽象与工具
○ 在高需求场景下考虑使用 CUTLASS 或 ThunderKitten 等高水平 GPU 库;
○ 如果你使用的是 JAX 或 Torch 框架,也可以先用 Triton 专注自定义 GPU 原语,再深入 CUDA 层。(黑客新闻)
五、推荐学习路径一览表
学习阶段 核心任务/内容
环境搭建 安装 CUDA Toolkit,配置 IDE(如 Visual Studio / VS Code)
快速入门 阅读 NVIDIA 博文、执行第一个 CUDA kernel
基础核心 掌握 grid/block/thread 概念,理解 host-device 流程
实战演练 完成向量加法、矩阵乘等练习,逐步并行化代码
优化升级 使用 shared memory、Tensor Core,调试及性能分析练习
项目实战 PyTorch 自定义扩展 / GPU-Puzzles / 使用 CUDA 高级抽象库
六、拓展资源推荐
● nVIDIA Developer Blog:持续更新的 CUDA 教程与实践文章。(NVIDIA Developer)
● freeCodeCamp 的 CUDA 系列教程:结构完整,从基础语法到实战项目(如 MNIST 分类),适合循序练习。(FreeCodeCamp)
● NVIDIA 的 CUDA C Programming Guide:全面参考文档,用于深入理解架构及 API。(NVIDIA Docs)
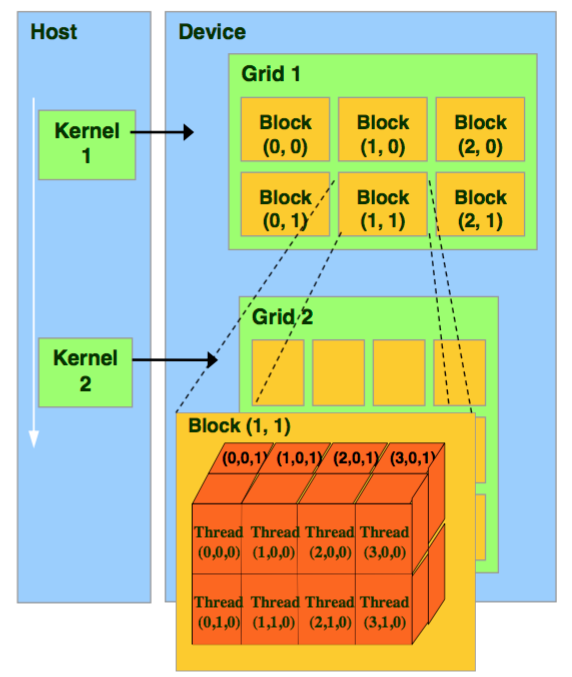
如何理解 CUDA 编程抽象
学会划分 thread、thread block 与 grid,掌握它们如何映射到 GPU 硬件执行单元、共享内存与同步机制。
掌握主机(Host)与设备(Device)的协作流程:内存分配、数据拷贝、kernel 调用、结果回传等 — 这是 CUDA 程序的基本框架。
这是一张清晰直观的 CUDA 编程抽象示意图,展示了 Host(主机) 与 Device(设备) 的合作结构,以及线程组织方式(thread、thread block、grid)如何映射到 GPU 硬件执行单元,并体现共享内存及同步机制的关键关系。
一、CUDA 编程抽象:层级结构与硬件映射
Thread → Thread Block → Grid:逻辑抽象与硬件执行
● Thread:CUDA 编程的最小执行单元,每个线程执行 kernel 函数中的一部分。
● Thread Block(线程块):将多个线程组织在一起。线程块中的线程可共享Shared Memory(共享内存),并使用 __syncthreads() 同步执行 (维基百科, 维基百科)。
● Grid(网格):由多个线程块组成,是 kernel 启动时的最高级逻辑结构。Grid 可以是一维、二维或三维 (Modal, 维基百科)。
在运行时,Grid 中的线程块会被调度到不同的 Streaming Multiprocessors(SM) 上执行,每个 SM 可以同时运行多个线程块,取决于资源(如寄存器、共享内存)的可用性 (维基百科, eximia.co)。
线程层级与索引计算
CUDA 为每个线程和线程块提供内建三维索引变量:
● threadIdx.{x,y,z}
● blockIdx.{x,y,z}
● blockDim
● gridDim
通过索引计算,线程可以映射到数组/数据结构中的具体位置。例如,对于一维情况:
i = blockIdx.x * blockDim.x + threadIdx.x
如此,每个线程处理数组中的一个元素 (维基百科, Modal)。
多维索引(2D 或 3D)也可以类似构建,便于处理矩阵或体素数据结构 (维基百科, Modal)。
二、Host 与 Device 的协作流程
CUDA 程序遵循一个清晰的主-设备协作流程,主要包括以下阶段:
- 内存分配
○ 在 Host(CPU)侧分配内存(例如 malloc 或 cudaHostAlloc)。
○ 在 Device(GPU)侧分配内存(使用 cudaMalloc)(umiacs.umd.edu, Medium)。 - 主机至设备的数据拷贝(Host → Device)
○ 使用 cudaMemcpy(dst, src, size, cudaMemcpyHostToDevice) 将初始化数据传送给 GPU (umiacs.umd.edu, enccs.github.io)。
○ 若使用 Pinned Memory(页锁定内存),可以通过 DMA 加速传输,减少开销 (engineering.purdue.edu, Medium)。 - Kernel Launch(kernel 调用)
○ 使用 kernel<<<gridDim, blockDim>>>(…) 语法启动 GPU 上的并行计算。
○ Grid 与 Block 的组织决定了线程并行的粒度与并发度 (维基百科, blog.damavis.com)。 - 计算执行
○ GPU 执行 kernel,线程在各 SM 上并行运行,线程块共享数据,可同步协作。
○ 每个线程负责数据处理的一部分,完成后写入 Device memory。 - 设备至主机的数据拷贝(Device → Host)
○ 使用 cudaMemcpy(dst, src, size, cudaMemcpyDeviceToHost) 将结果传回 Host (enccs.github.io, umiacs.umd.edu)。
○ 同样建议使用页锁定内存以提升性能 (engineering.purdue.edu, Medium)。 - 清理资源
○ 使用 cudaFree 释放 Device 内存,使用 free 或 cudaFreeHost 释放 Host 内存 (engineering.purdue.edu, Medium)。
三、总结一览表
模块 核心概念与说明
线程层级 Thread → Thread Block → Grid,三层组织结构,支持多维索引
硬件映射 每个 Thread Block 映射到一个 SM,多个 Block 可并发执行,Warp 为调度单位
内存与同步 同一 Block 内线程共享 Shared Memory 并可同步;不同 Block 不能直接通信
Host-Device 协作 包含内存分配、数据传输(Host→Device、Device→Host)、kernel 调用与执行、资源释放
优化建议 使用 Pinned Memory 与 DMA 优化拷贝性能;合理设置 gridDim/blockDim,确保并发高效
如何配合共享内存编写同步代码、计算索引扩展到二维/三维情形,或围绕性能优化与实际案例设计练习
一、共享内存与线程同步基础示例
NVIDIA 官方博客提供了一个经典示例,演示如何利用共享内存和 __syncthreads() 实现数组数据的反转操作:
global void staticReverse(int *d, int n) {
shared int s[64];
int t = threadIdx.x;
int tr = n - t - 1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
这里:
● 使用 shared 定义共享内存数组 s,供同一线程块内所有线程访问;
● 写入操作完成后调用 __syncthreads(),确保所有线程都已将数据写入共享内存,再统一读取进行反转;避免了数据竞争问题。(NVIDIA Developer)
NVIDIA 文档还指出:共享内存大约比未经缓存的全局内存访问快 100 倍,前提是没有 bank conflict(内存银行冲突) (NVIDIA Developer)。
二、复杂示例:块内归约操作(Reduction)
Oak Ridge 实验室的课程讲义中提供了一个用共享内存做向量点积及归约操作的完整示例:
global void dot(float *a, float *b, float *c) {
shared float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
__syncthreads();
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i];
}
__syncthreads();
i /= 2;
}
if (cacheIndex == 0) {
c[blockIdx.x] = cache[0];
}
}
该代码逻辑为:
- 每个线程累加若干元素的乘积,并写入共享内存;
- 同步所有线程后,进行并行归约(两两相加),使用 __syncthreads() 保证阶段性同步;
- 最后,每个线程块将结果写入全局内存,由主机端完成最终归约。(edoras.sdsu.edu)
三、索引扩展到二维/三维网格
CUDA 支持多维的线程块和网格布局。线程可通过以下常见内建变量获取其逻辑位置:
● threadIdx.x/y/z
● blockIdx.x/y/z
● blockDim.x/y/z
● gridDim.x/y/z
例如,二维索引可通过:
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
同样可用于三维结构,非常适合图像处理、体素计算等任务。
四、提升性能的练习案例
练习:使用共享内存优化二维矩阵乘法
核心步骤:
- 每个线程块负责矩阵乘法中的一个 tile(子块);
- 将矩阵 A 和 B 的相关子块从全局内存加载到共享内存;
- __syncthreads() 后,线程执行子块局部计算;
- 多次迭代合并结果,然后写回全局输出矩阵。
这种 tiling 技术减少了低速全局内存访问,提升性能。(edoras.sdsu.edu)
扩展优化可包含:
● 控制共享内存大小;
● 使用动态共享内存(extern shared);
● 避免 bank conflicts,或针对特定架构调整 bank 配置 (NVIDIA Developer, Medium)。
总结概览表
技术点 说明
共享内存声明 使用 shared
,线程块内部共享
线程同步 使用 __syncthreads()
在共享内存访问前后同步所有线程
归约操作 共享内存 + 同步实现高效并行简化计算
索引扩展 多维索引通过内建变量构建,适合矩阵和图像处理
优化策略 利用 tiling、动态共享内存、优化访问模式避免 bank conflict
示例代码:Tiled 矩阵乘法(Shared Memory + Tiling)
该代码基于 Medium 博客解析,用于演示如何使用共享内存将大矩阵分割为小块(tiles),然后并行计算子矩阵乘法。这种设计显著减少了全局内存访问次数,从而提升计算性能(Medium)。
// 定义 tile 大小(可根据硬件共享内存大小调整)
#define TILE_SIZE 16// CUDA kernel:矩阵乘法 C = A * B(N×N 矩阵)
__global__ void MatrixMultiShared(float* A, float* B, float* C, int N) {// 在每个线程块中声明共享内存 tile__shared__ float tile_A[TILE_SIZE][TILE_SIZE];__shared__ float tile_B[TILE_SIZE][TILE_SIZE];// 计算当前线程对应的全局行、列索引int row = threadIdx.y + blockIdx.y * TILE_SIZE;int col = threadIdx.x + blockIdx.x * TILE_SIZE;float value = 0.0f;// 对整个矩阵按 tile 块进行遍历for (int m = 0; m < (N + TILE_SIZE - 1) / TILE_SIZE; ++m) {// 边界检查后将 A 和 B 子块加载到共享内存if (row < N && (m * TILE_SIZE + threadIdx.x
)











)

)



