大型语言模型(Large Language Models, LLMs)如GPT-OSS、GPT-4、LLaMA和Mixtral的快速发展显著提升了人工智能的能力边界,但同时也带来了严峻的内存资源挑战。以1200亿参数的模型为例,在FP16精度下仅权重存储就需要约240GB的内存空间,这远超单个NVIDIA A100或H100 GPU的容量限制。
面对这一技术瓶颈,GPT-OSS通过创新的量化技术实现了突破性进展。该系统能够在单个80GB GPU上运行1200亿参数模型,同时保持竞争性的基准测试性能。其核心技术基于Mixture-of-Experts (MoE) 权重的训练后量化,将权重精度降低至MXFP4格式,实现每参数仅需4.25位的存储效率。
本文将从量化的数学理论基础出发,深入分析硬件层面的技术影响,并探讨实际部署策略的实现细节,全面阐述这一技术突破的实现机制。
大规模模型的内存约束分析
内存需求的数学建模
对于包含P个参数的神经网络模型,其内存需求与数据精度呈线性关系。在FP32精度下,每个参数需要4字节存储空间,因此总内存需求为:
Memory = P × 4 bytes
当采用FP16精度时,内存需求减半:
Memory = P × 2 bytes
针对1200亿参数的模型,不同精度下的内存需求对比显示:FP32精度需要480GB内存空间,在单GPU环境下无法实现;FP16精度虽然将需求降至240GB,但仍然超出现有单GPU的容量限制。
传统解决方案的局限性
传统的模型分片技术虽然可以将大型模型分布在多个GPU上,但这种方法引入了新的技术挑战。高速互连带宽(如NVLink或InfiniBand)成为系统性能的关键瓶颈,同时显著增加了硬件成本、部署复杂性以及跨设备通信延迟。这些因素限制了大规模模型在资源受限环境中的实际应用。
量化技术的理论基础
量化技术通过减少每个参数的表示位数来实现内存压缩。其数学表达式可以形式化为:
Q(w) = clip(round(w/Δ), −2^(b−1), 2^(b−1)−1) × Δ
其中,w表示原始权重值,b表示量化位数(FP4格式为4位),Δ表示量化比例因子。这一过程通过离散化连续的权重分布来实现压缩,同时需要在精度损失和存储效率之间找到最优平衡点。

量化技术带来的优势体现在三个关键方面:内存节省通过减少每个权重的存储空间实现显著的容量优化;计算加速利用低位矩阵乘法操作提升运算效率;带宽减少降低了显存与流式多处理器之间的数据传输负载。
低精度浮点格式的技术特征
FP4格式的结构与特性
FP4(4位浮点)格式采用符号-指数-尾数的布局结构:
| S | EE | M | | 1 | 2 | 1 |
在相关研究文献中,FP4格式通常采用radix-4结构,包含1位符号位、3位指数位和0位尾数位。然而,根据Hugging Face的研究分析,采用2位指数和1位尾数的组合能够在实际应用中获得更优的性能表现。FP4格式相比FP32实现了8倍的存储压缩,但其较窄的动态范围对高方差权重的表示构成了技术挑战。
FP8格式的平衡设计
FP8(8位浮点)格式提供了两种主要的布局方案:E4M3格式在数值范围和精度之间实现良好平衡,适用于大多数深度学习场景;E5M2格式在极端数值范围下表现更优,特别适合处理异常值分布。NVIDIA Hopper GPU架构对FP8格式提供了广泛的硬件支持,使其成为压缩效率和计算精度之间的理想折衷方案。
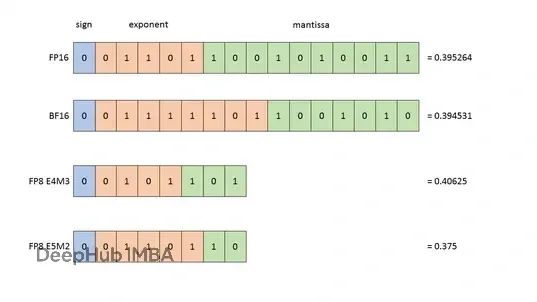
MXFP4的智能化设计
MXFP4(混合精度FP4)代表了量化技术的重要进步。该格式通过动态调整权重块的缩放因子,实现了精度和压缩率的优化平衡。虽然其位数略有增加(约4.25位),但通过更细粒度的敏感参数编码,有效降低了量化误差对模型性能的影响。
Mixture-of-Experts架构的量化优势
Mixture-of-Experts架构通过专家网络的稀疏激活实现计算效率的提升。在包含N个专家的系统中,路由器机制为每个输入token仅激活k个专家(其中k远小于N),从而在保持模型容量的同时显著减少单次前向传播的计算量。
MoE架构的一个重要特征是其参数分布的不均匀性:超过90%的模型参数集中在专家网络的权重中。这种分布特性为量化技术的应用创造了理想条件。通过对MoE权重进行激进量化,可以实现巨大的内存节省,同时路由器和嵌入层可以保持高精度表示,确保模型的核心功能不受影响。
GPT-OSS的内存优化计算分析
基于GPT-OSS的具体配置参数:总参数数量为1200亿,其中MoE参数占1080亿(90%),非MoE参数为120亿(10%),我们可以进行详细的内存需求分析。
在未应用量化技术的FP16配置下,MoE权重需要216GB存储空间(108B × 2B),非MoE参数需要24GB空间(12B × 2B),总计240GB,超出单GPU容量限制。
采用MXFP4量化技术后(4.25位等效于0.53125字节),MoE权重的存储需求降至57.4GB(108B × 0.53125),而非MoE参数仍保持FP16精度的24GB。经过优化后的总内存需求为81.4GB,通过少量运行时优化即可适配80GB A100 GPU的容量限制。
硬件实现的技术挑战与解决方案
当前GPU架构中的tensor core对FP4格式的原生支持仍然有限,这要求系统采用位切片操作或开发自定义CUDA内核来实现高效计算。虽然NVIDIA的Hopper架构为FP8格式提供了更好的硬件支持,但FP4格式的计算通常需要通过软件模拟实现,这在一定程度上影响了计算效率。
内存带宽是影响大规模模型推理性能的关键因素。传统的1200亿参数FP16模型推理需要约1.9TB/s的内存带宽,而MXFP4量化技术将这一需求降低约3.8倍,至500GB/s左右,使其完全处于A100 GPU的带宽承受范围内。
精度与压缩效率的量化分析
不同量化格式在内存压缩和精度保持方面的性能表现存在显著差异。FP16格式相对于FP32实现2倍内存减少,精度损失几乎为零;FP8格式实现4倍压缩,精度下降控制在0.1%至0.3%之间;传统FP4格式虽然实现8倍压缩,但精度损失可能达到1%至3%;而MXFP4格式在实现约7.5倍压缩的同时,将精度损失控制在0.3%以内,展现了卓越的技术平衡。
总结
GPT-OSS通过MoE权重的MXFP4量化技术实现了大规模语言模型部署的重要突破。该技术方案使80GB GPU能够托管1200亿参数模型,在几乎不损失精度的前提下显著降低了内存带宽需求,为资源受限的团队和组织提供了新的部署可能性。
随着人工智能模型规模向数万亿参数发展,类似的量化优化技术将成为实现AI技术民主化访问的关键支撑。这些技术创新不仅解决了当前的资源约束问题,更为未来更大规模模型的实际应用奠定了重要的技术基础。
参考文献:
introduces new methods that allow training with FP4 while maintaining accuracy comparable to BF16/FP8 for up to 13B-parameter models.
Training LLMs with MXFP4” details training strategies using MXFP4 GEMMs with stochastic rounding and transforms for variance reduction — showing that MXFP4 can nearly match BF16 with speedups.
“LLM-FP4: 4-Bit Floating-Point Quantized Transformers” presents post-training quantization of LLMs to 4 bits, discussing challenges, exponent bit allocations, and activation quantization techniques.
MxMoE: Mixed-precision Quantization for MoE with Accuracy and Performance Co-Design”explores how MoE models lend themselves to ***\mixed-precision quantization strategies, optimizing for expert activation frequency and hardware dynamics.(https://arxiv.org/abs/2505.05799)
https://avoid.overfit.cn/post/462b6fb63ffa41b3828a7be09b041843

)

)





:nvidia与cuda介绍)
)

)






