背景与意义
- 计算机视觉 (Computer Vision, CV) 需要对图像和视频进行处理、特征提取和模型训练,计算量巨大。
- GPU (图形处理单元) 擅长并行计算,非常适合深度学习、卷积操作、矩阵乘法等场景。
- NVIDIA 作为 GPU 领域的领导者,推出了 CUDA (Compute Unified Device Architecture) 计算架构,使得 GPU 能够进行通用计算(GPGPU),推动了计算机视觉的快速发展。
NVIDIA 在计算机视觉中的角色
- 硬件方面
- GPU 产品线:RTX (消费级)、A100/H100 (数据中心)、Jetson (边缘计算)。
- 提供高吞吐量、低延迟的并行计算能力。
- 张量核心 (Tensor Core) 专门优化深度学习矩阵运算。
- 软件生态
- CUDA Toolkit:核心开发工具包,支持 GPU 编程。
- cuDNN (CUDA Deep Neural Network library):深度学习加速库。
- TensorRT:推理优化框架,用于 CV 模型的高效部署。
- DeepStream SDK:流式视频分析框架,适合 CV 应用。
- NVIDIA Isaac/Omniverse:机器人与仿真,计算机视觉场景建模。
NVIDIA 驱动与CUDA的关系
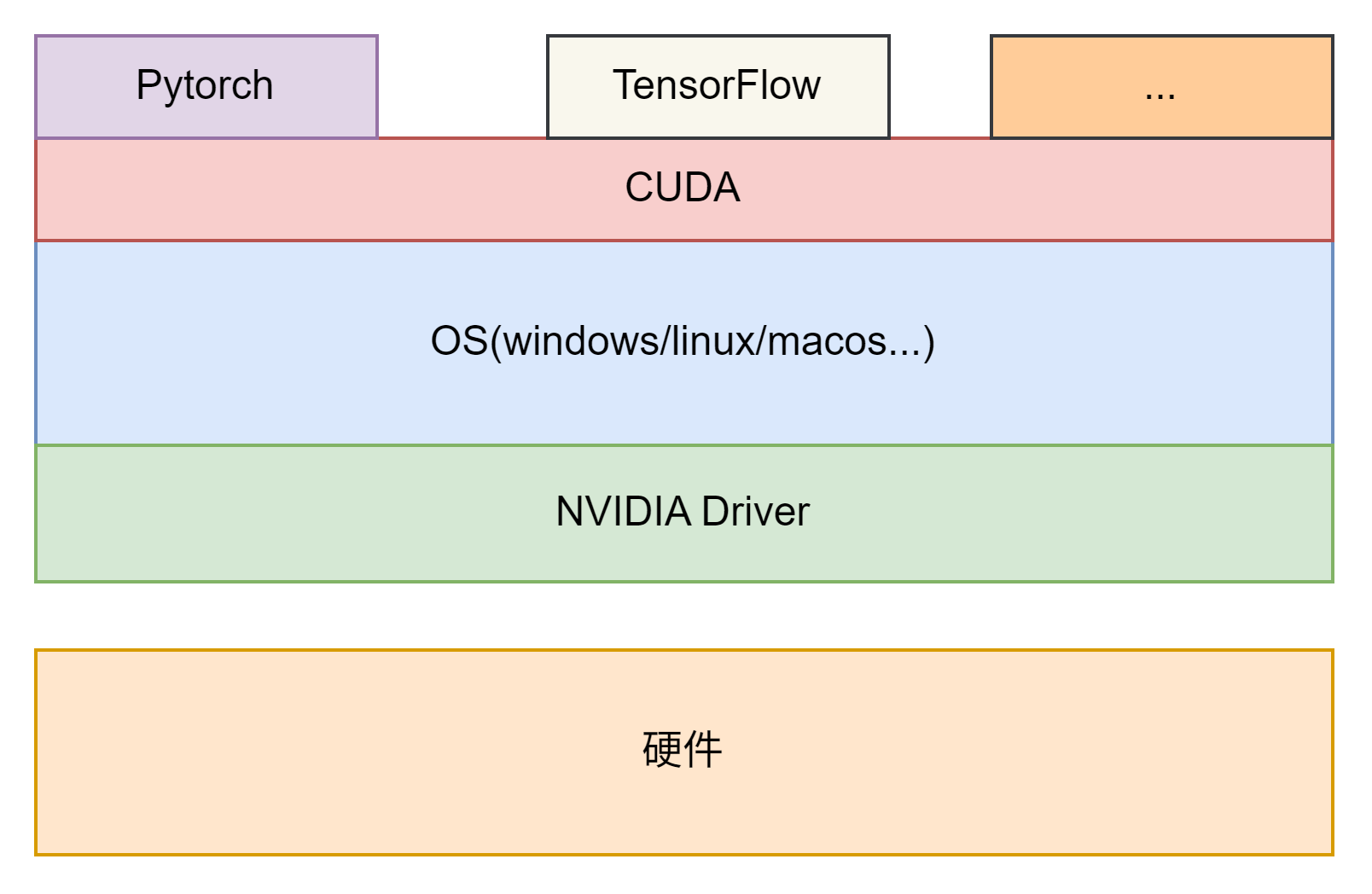
CUDA架构和编程模型
CUDA架构
CUDA 架构是 NVIDIA GPU 的底层硬件设计,核心目标是支持大规模并行计算。
GPU 硬件组成
- SM (Streaming Multiprocessor,流式多处理器)
- GPU 的核心计算单元,相当于 CPU 的“多核”。
- 每个 SM 包含多个 CUDA 核心 (CUDA Core),专门执行并行计算。
- 还包含寄存器、共享内存、Warp 调度器、Tensor Core 等。
- CUDA Core
- 执行最基本的整数/浮点运算。
- 大量 CUDA Core 并行工作,支持数千线程同时运行。
- Tensor Core (张量核心)
- 针对矩阵运算优化,特别适合深度学习的矩阵乘法。
- 内存层次结构
- 寄存器(速度最快,线程私有)
- 共享内存 (Shared Memory)(线程块内共享)
- L1/L2 Cache(自动缓存)
- 全局内存 (Global Memory)(显存,访问慢)
Warp 执行模型
- 一个 Warp = 32 个线程(在 CUDA 硬件中是调度的基本单位)。
- Warp 内线程同步执行,若存在分支,会导致 Warp Divergence (分支发散) → 性能下降。
CUDA 编程模型 (Programming Model)
主机-设备模型
- Host (主机):CPU,负责程序逻辑与调度。
- Device (设备):GPU,负责大规模并行计算。
- 程序运行模式:
- CPU 端执行一般逻辑。
- GPU 端执行核函数 (Kernel)。
线程层次结构
CUDA 提供三层线程组织方式:
Grid (网格) → Block (线程块) → Thread (线程)
- 线程 (Thread):最小计算单元。
- 线程块 (Block):多个线程组成(1D、2D、3D)。
- 网格 (Grid):多个 Block 组成(1D、2D、3D)。
每个线程可通过内置变量获得自己的 ID:
threadIdx // 线程在 Block 内的索引
blockIdx // Block 在 Grid 内的索引
blockDim // 每个 Block 的维度 (线程数)
gridDim // Grid 的维度 (Block 数)
常用公式:
int thread_id = blockIdx.x * blockDim.x + threadIdx.x;
内存编程模型
CUDA 提供不同作用域的存储:
- 寄存器 (Registers):线程私有,速度最快。
- 共享内存 (Shared Memory):Block 内共享,延迟低,适合数据交换。
- 全局内存 (Global Memory):所有线程可访问,但延迟高。
- 常量内存 (Constant Memory):只读缓存,适合广播数据。
- 纹理/表面内存 (Texture/Surface Memory):为图像/视频处理优化。
CUDA 执行流程
- CPU 分配内存 →
cudaMalloc。 - CPU 将数据拷贝到 GPU →
cudaMemcpy。 - CPU 启动核函数 →
kernel<<<Grid, Block>>>(...)。 - GPU 执行计算(数千线程并行)。
- GPU 将结果拷贝回 CPU。
- CPU 释放内存。
CUDA 优化要点
- 内存优化
- 内存访问对齐 (Coalesced Memory Access)。
- 充分利用共享内存,减少全局内存访问。
- 使用页锁定内存 (Pinned Memory) 提升传输速度。
- 并行优化
- 提高线程并发数,避免 SM 空闲。
- 减少 Warp 分支发散。
- 使用 Streams 实现异步计算与数据传输重叠。
- 计算优化
- 使用 Tensor Core/FMA 指令提升矩阵乘法性能。
- 精度混合 (FP32/FP16/INT8) 提升吞吐。
示例
// 向量加法 (Hello CUDA)
#include <stdio.h>// CUDA 核函数
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N) {C[idx] = A[idx] + B[idx];}
}int main() {int N = 1<<20; // 1Msize_t size = N * sizeof(float);// 分配内存 (Host)float *h_A = (float*)malloc(size);float *h_B = (float*)malloc(size);float *h_C = (float*)malloc(size);// 初始化数据for (int i = 0; i < N; i++) {h_A[i] = 1.0f;h_B[i] = 2.0f;}// 分配内存 (Device)float *d_A, *d_B, *d_C;cudaMalloc((void**)&d_A, size);cudaMalloc((void**)&d_B, size);cudaMalloc((void**)&d_C, size);// 拷贝 Host → DevicecudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);// 启动核函数int threadsPerBlock = 256;int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);// 拷贝 Device → HostcudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// 验证结果printf("C[0] = %f\n", h_C[0]);// 释放内存cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);free(h_A); free(h_B); free(h_C);return 0;
}
)

)













)


