网络爬虫技术全栈指南:从入门到AI时代的数据采集革命
关键词:网络爬虫、Python爬虫、数据采集、反爬技术、分布式爬虫、AI爬虫、Scrapy框架、自动化数据提取、爬虫架构设计
摘要:本专栏是最全面的网络爬虫技术指南,涵盖从基础框架到AI驱动的智能爬虫全栈技术。通过66篇深度文章,带你掌握从传统爬虫到新一代AI爬虫的完整技术栈,包括30篇基础技术、10篇新一代框架、10篇高级反爬技术、10篇现代化架构设计,以及6篇特殊场景应用。无论你是初学者还是资深开发者,都能在这里找到适合的学习内容和实战案例。
文章目录
- 网络爬虫技术全栈指南:从入门到AI时代的数据采集革命
- 🚀 为什么这个专栏值得你订阅?
- 数据时代的机遇与挑战
- 这个专栏的独特价值
- 📊 专栏技术栈全景图
- 🎯 专栏内容体系
- 第一部分:爬虫基础技术栈(30篇)
- 核心库与框架
- 数据存储与处理
- 第二部分:新一代AI驱动爬虫(10篇)
- AI智能框架
- 现代化工具
- 第三部分:高级反爬与绕过技术(10篇)
- 指纹伪造技术
- 智能检测绕过
- 第四部分:现代化爬虫架构(10篇)
- 分布式集群
- 第五部分:特殊场景爬虫技术(6篇)
- 特殊场景应用
- 🎯 学习路线推荐
- 🌟 初级开发者(0-6个月经验)
- 🔥 中级开发者(6个月-2年经验)
- 🚀 高级开发者(2年+经验)
- 💡 核心技术预览
- 传统爬虫 vs AI爬虫
- 传统爬虫方式
- AI驱动爬虫方式
- 现代反爬技术示例
- TLS指纹伪造
- 设备指纹全方位伪造
- 🔍 专栏特色技术深度解析
- 1. 费曼学习法应用
- 2. 完整的代码示例
- 3. 前沿技术追踪
- 📈 学习收益预期
- 技术能力提升
- 职业发展助力
- 实际项目应用
- 🎁 专栏福利
- 完整源码仓库
- 技术交流社群
- 持续更新保障
- 🚀 立即开始你的爬虫技术进阶之旅
- 专栏订阅说明
- 试读文章推荐
🚀 为什么这个专栏值得你订阅?
数据时代的机遇与挑战
在这个信息爆炸的时代,数据就是新的石油。每天有数万亿字节的数据在互联网上流转,从电商网站的商品信息、社交媒体的用户动态,到新闻网站的实时资讯。如何高效、智能地获取这些数据,已经成为每个开发者、数据分析师,甚至企业决策者必须掌握的核心技能。
但是,网络爬虫技术正在经历一场前所未有的变革:
- 传统爬虫面临挑战:反爬技术越来越复杂,TLS指纹、设备指纹、行为分析等新技术层出不穷
- AI技术带来革命:大语言模型让爬虫具备了"理解"网页内容的能力
- 架构要求更高:企业级应用需要分布式、高可用、可监控的爬虫系统
这个专栏的独特价值
🎯 技术全面性:涵盖66个核心技术点,从基础到前沿一网打尽
🔥 实战导向:每篇文章都有完整的代码示例和实际案例
💡 紧跟趋势:深度解析AI驱动爬虫、现代反爬技术等前沿方向
🏗️ 架构思维:不仅教你写爬虫,更教你设计企业级爬虫系统
📚 系统学习:遵循费曼学习法,复杂概念简单化,易学易懂
📊 专栏技术栈全景图
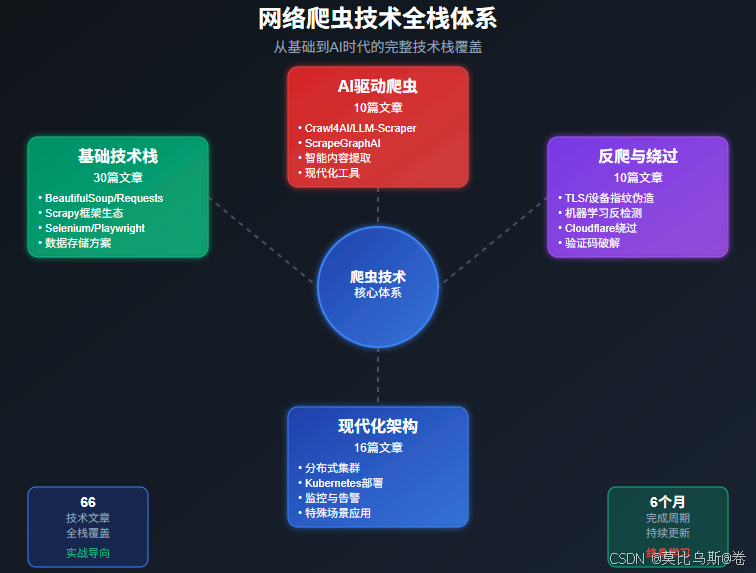
🎯 专栏内容体系
第一部分:爬虫基础技术栈(30篇)
从零基础到熟练掌握传统爬虫技术,这是每个爬虫开发者的必经之路。
核心库与框架
- BeautifulSoup:HTML解析的瑞士军刀
- Requests:HTTP请求处理的最佳实践
- Scrapy系列:从单机到分布式的完整生态
- Selenium & Playwright:动态网页的终极解决方案
数据存储与处理
- MongoDB、Elasticsearch、Kafka:现代数据存储方案
- 分布式架构设计:多机协同与任务分配
- 性能优化技巧:并发控制与资源管理
第二部分:新一代AI驱动爬虫(10篇)
这是爬虫技术的未来趋势,也是本专栏的核心亮点。
AI智能框架
- Crawl4AI:让AI理解网页内容
- LLM-Scraper:大语言模型驱动的智能提取
- ScrapeGraphAI:基于图神经网络的网页解析
现代化工具
- Trafilatura:高效网页正文提取
- ScrapeFly:云端爬虫服务
- Crawlee:TypeScript驱动的现代爬虫
第三部分:高级反爬与绕过技术(10篇)
深入反爬与反反爬的技术对抗,掌握最前沿的绕过技术。
指纹伪造技术
- TLS指纹伪造:ja3、ja4指纹模拟
- 设备指纹全方位伪造:硬件特征、字体、插件模拟
- Canvas与WebGL指纹:浏览器特征伪造
智能检测绕过
- 机器学习反爬检测:行为模式识别与绕过
- 验证码进化史:从reCAPTCHA到GeeTest的破解
- Cloudflare绕过:5秒盾与Bot Fight Mode突破
第四部分:现代化爬虫架构(10篇)
企业级爬虫系统的设计与实现,让你的爬虫从玩具变成生产力工具。
分布式集群
- Scrapy-Cluster:大规模分布式爬虫
- Kubernetes部署:云原生爬虫管理
- 监控与告警:Prometheus + Sentry完整监控体系
第五部分:特殊场景爬虫技术(6篇)
从移动端到区块链的各种特殊场景爬虫技术应用。
特殊场景应用
- 移动端App爬虫:Android/iOS数据提取
- 小程序爬虫:微信、支付宝生态数据采集
- 实时数据流:WebSocket、GraphQL、gRPC协议处理
- 区块链数据:以太坊、比特币链上数据采集
- 社交媒体API:Twitter、Instagram、TikTok数据获取
- 电商平台:亚马逊、淘宝、京东商品信息采集
🎯 学习路线推荐
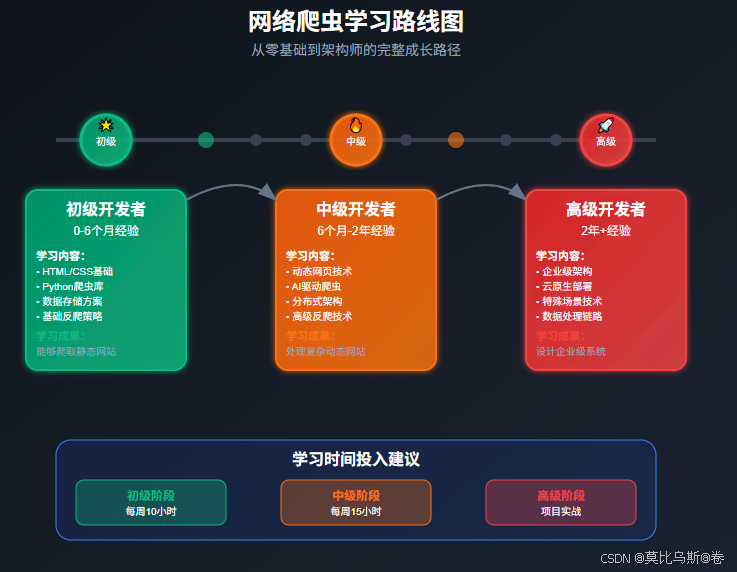
🌟 初级开发者(0-6个月经验)
目标:掌握基础爬虫技术,能够独立完成简单的数据采集任务
学习路径:
- 基础技术栈(第1-20篇):从BeautifulSoup到Scrapy基础
- 数据存储(第21-25篇):掌握常用数据存储方案
- 简单反爬(第26-30篇):应对基础的反爬策略
学习成果:能够爬取静态网站、处理简单的反爬机制、将数据存储到数据库
🔥 中级开发者(6个月-2年经验)
目标:掌握动态网页爬取和分布式技术,能够设计中等复杂度的爬虫系统
学习路径:
- 基础技术深化(第21-30篇):Selenium、Playwright深度应用
- AI驱动爬虫(第31-40篇):体验新一代爬虫技术
- 高级反爬技术(第41-50篇):掌握现代反爬绕过技术
学习成果:能够处理复杂的动态网站、使用AI技术提升爬虫效率、突破大部分反爬机制
🚀 高级开发者(2年+经验)
目标:设计企业级爬虫系统,掌握前沿技术,具备架构思维
学习路径:
- 现代化架构(第51-60篇):分布式集群、云原生部署
- 特殊场景技术(第61-66篇):移动端、区块链、社交媒体爬虫
学习成果:能够设计和实现企业级爬虫系统、掌握前沿技术、具备技术选型和架构设计能力
💡 核心技术预览
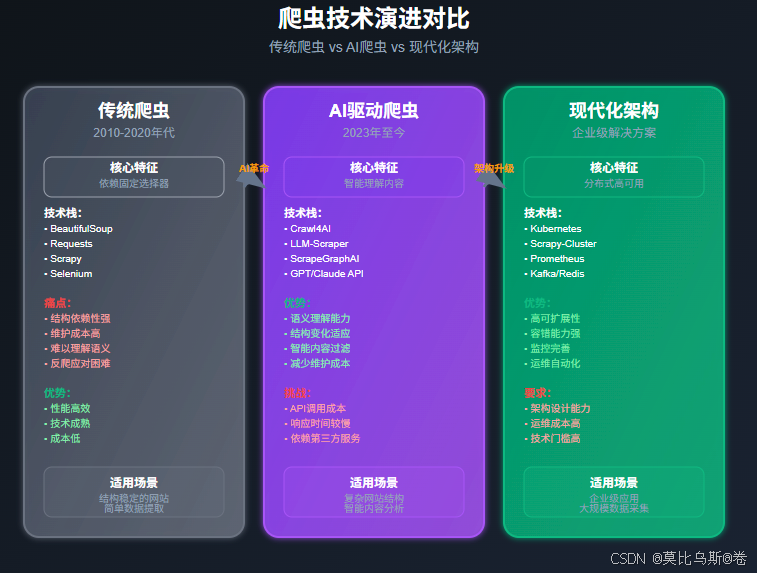
传统爬虫 vs AI爬虫
让我们通过一个简单的例子来看看传统爬虫和AI爬虫的区别:
传统爬虫方式
import requests
from bs4 import BeautifulSoup# 传统方式:依赖固定的CSS选择器
url = "https://news.example.com"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')# 如果网站结构改变,这些选择器就失效了
titles = soup.select('.news-title')
contents = soup.select('.news-content')
AI驱动爬虫方式
import asyncio
from crawl4ai import AsyncWebCrawlerasync def ai_crawl():async with AsyncWebCrawler() as crawler:# AI自动理解网页内容,无需固定选择器result = await crawler.arun(url="https://news.example.com",extraction_strategy=LLMExtractionStrategy(provider="ollama/llama2",instruction="提取所有新闻标题和内容"))return result.extracted_content
看到区别了吗?AI爬虫不再依赖脆弱的CSS选择器,而是通过理解网页内容来提取数据!
现代反爬技术示例
TLS指纹伪造
import tls_client# 模拟真实浏览器的TLS指纹
session = tls_client.Session(client_identifier="chrome_110",random_tls_extension_order=True
)# 现在你的请求看起来就像真实的Chrome浏览器
response = session.get("https://protected-site.com")
设备指纹全方位伪造
from undetected_chromedriver import Chrome
from fake_useragent import UserAgent# 创建难以检测的浏览器实例
options = webdriver.ChromeOptions()
options.add_argument(f"--user-agent={UserAgent().random}")# 随机化浏览器指纹
driver = Chrome(options=options)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined,})"""
})
🔍 专栏特色技术深度解析
1. 费曼学习法应用
每篇文章都采用费曼学习法,复杂概念简单化:
- 从问题出发:为什么需要这个技术?
- 通俗解释:用生活中的类比来解释技术原理
- 实际案例:通过真实项目展示技术应用
- 深度思考:技术的局限性和发展方向
2. 完整的代码示例
不是简单的API介绍,而是完整的、可运行的项目代码:
# 例如:企业级Scrapy分布式爬虫架构
class DistributedSpider(Spider):name = 'enterprise_spider'def __init__(self):# Redis集群配置self.redis_client = RedisCluster.from_url("redis://cluster.example.com:7000")# 监控系统配置self.prometheus_client = CollectorRegistry()async def parse(self, response):# 智能数据提取extractor = AIContentExtractor(model="gpt-3.5-turbo",schema=ProductSchema)products = await extractor.extract(response.text)for product in products:yield {'name': product.name,'price': product.price,'timestamp': datetime.now(),'source': response.url}
3. 前沿技术追踪
紧跟技术发展趋势,涵盖最新的爬虫技术:
- AI驱动爬虫:Crawl4AI、LLM-Scraper等新兴框架
- 现代协议支持:HTTP/3、WebSocket、gRPC数据采集
- 云原生部署:Kubernetes、Docker容器化爬虫
- 实时数据处理:Kafka、Redis Stream数据流处理
📈 学习收益预期
技术能力提升
- ✅ 掌握95%的爬虫应用场景解决方案
- ✅ 具备企业级爬虫系统设计能力
- ✅ 了解并应用最新的AI爬虫技术
- ✅ 掌握复杂反爬机制的绕过方法
职业发展助力
- 📊 数据工程师:爬虫是数据获取的重要手段
- 🔍 爬虫工程师:专业的爬虫开发和维护工作
- 🤖 AI工程师:AI时代的数据采集和处理能力
- 💼 技术架构师:大规模数据采集系统的设计能力
实际项目应用
- 🛒 电商数据分析:商品价格监控、竞品分析
- 📰 新闻资讯聚合:多源新闻采集和处理
- 💰 金融数据采集:股票、期货、虚拟货币数据获取
- 🏠 房产信息监控:楼盘信息、价格趋势分析
🎁 专栏福利
完整源码仓库
- 📁 66个完整项目的源代码
- 🔧 开箱即用的配置文件
- 📖 详细的部署文档
- 🐛 持续的Bug修复和功能更新
技术交流社群
- 💬 专属技术交流群
- 🎯 定期技术分享会
- 🤝 一对一技术答疑
- 📚 独家学习资料分享
持续更新保障
- 🔄 跟随技术发展持续更新
- 📝 新技术第一时间补充
- 🎯 根据读者反馈优化内容
- 📈 定期发布技术趋势报告
🚀 立即开始你的爬虫技术进阶之旅
在这个数据驱动的时代,掌握高效的数据采集技术就是掌握了未来。无论你是想要:
- 📊 为数据分析获取更多数据源
- 🔍 构建智能的信息收集系统
- 🤖 探索AI与爬虫结合的新可能
- 💼 提升职场竞争力和技术深度
这个专栏都将是你最好的技术伙伴。
专栏订阅说明
本专栏采用付费订阅模式,确保内容质量和持续更新:
- 💎 专栏价格:一次付费,终身学习
- 📚 内容数量:66篇深度技术文章
- 🔄 更新频率:每周2-3篇新文章
- 🎯 完成时间:预计6个月内完成全部内容
试读文章推荐
为了让你更好地了解专栏内容质量,建议你先阅读以下免费试读文章:
- 【网络与爬虫 01】BeautifulSoup从入门到精通**:了解传统爬虫基础
- 【网络与爬虫 31】AI驱动的网页内容提取革命**:体验AI爬虫的强大
准备好开启你的爬虫技术进阶之旅了吗?点击订阅,让我们一起探索数据采集的无限可能! 🚀
💡 温馨提示:如果你对专栏内容有任何疑问,欢迎通过评论区或私信联系我。我会根据大家的反馈持续优化专栏内容,确保每一位读者都能获得最大的学习价值!
文章
![[Chat-LangChain] 前端用户界面 | 核心交互组件 | 会话流管理](http://pic.xiahunao.cn/[Chat-LangChain] 前端用户界面 | 核心交互组件 | 会话流管理)


















