BERT模型引入及详解
参考
-
视频:
- ELMo 模型(双向 LSTM 模型解决词向量多义问题
-
博客:
- BERT模型
- BERT详解:概念、原理与应用
- 一文读懂BERT
ELMo模型
参考:
- 视频:
- ELMo模型(双向LSTM模型解决词向量多义问题)
- 博客:
- 【自然语言处理】ELMo, GPT等经典模型的介绍与对比
引入
在Word Embedding中,词语都是由一个唯一的词向量进行表示的,不根据句子改变而改变
也就是说,Word Embedding表示词的方法是静态的,无法对多义词进行处理
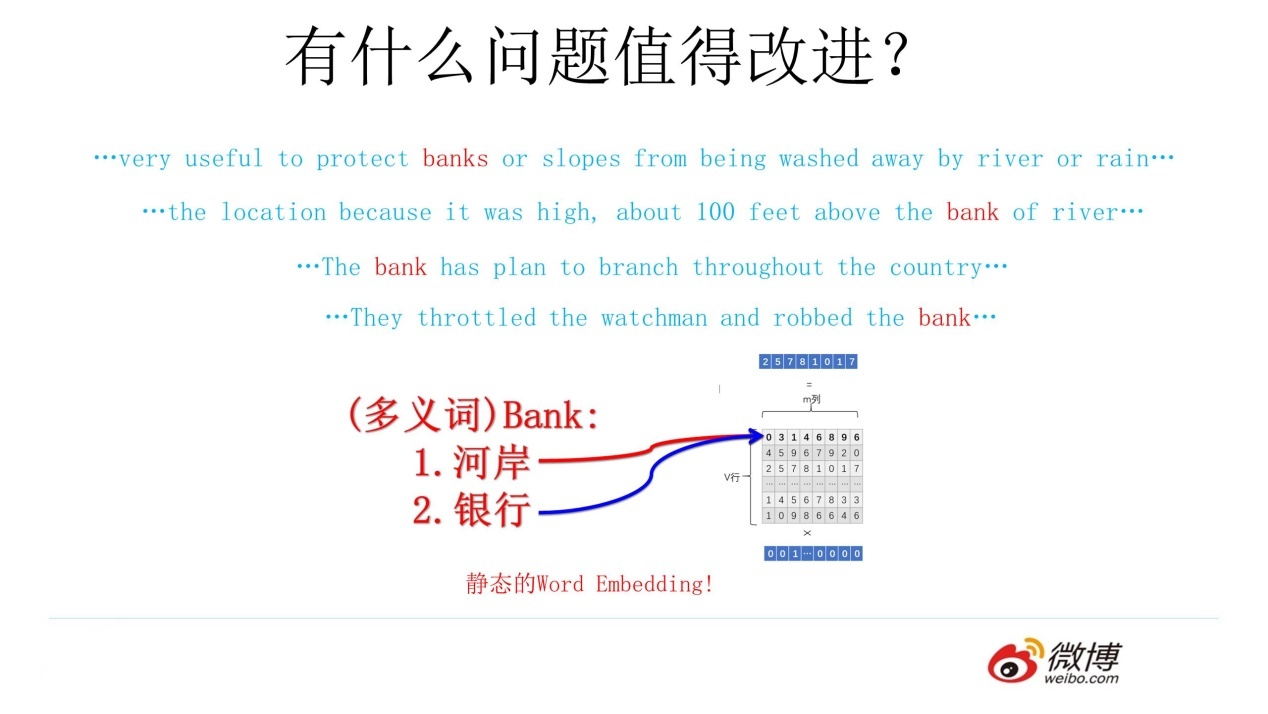
对于这个例子,尽管不同序列中的bank的上下文不同,但经语言模型训练时,无论什么序列经过Word2Vec,都是对bank这个词进行预测,因此占用的是嵌入矩阵中的同一行参数;这样会导致不同的语义被压缩到同一个Word Embedding空间,进而导致Word Embedding无法区分多义词
核心思想
事先用语言模型训练好了一个单词的Word Embedding,但是它此时还无法区分多义词语义,这没关系
当使用Word Embedding时,此时单词已经具有特定的上下文,这个时候我可以根据上下文单词的语义再去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达单词在这个上下文中的具体含义
ELMo模型的核心思想就是:根据当前上下文对Word Embedding进行动态调整
注意:ELMo是对Word2Vec的改进,模型的主要任务还是在于词向量而不是预测生成
不只是训练一个嵌入矩阵Q,还要把当前词的上下文信息融入到这个Q矩阵
两阶段过程
- 利用语言模型做预训练
- 做下游任务时,从预训练网络中提取对应单词的网络各层的
Word Embedding作为新特征补充到下游任务中
架构
预训练过程
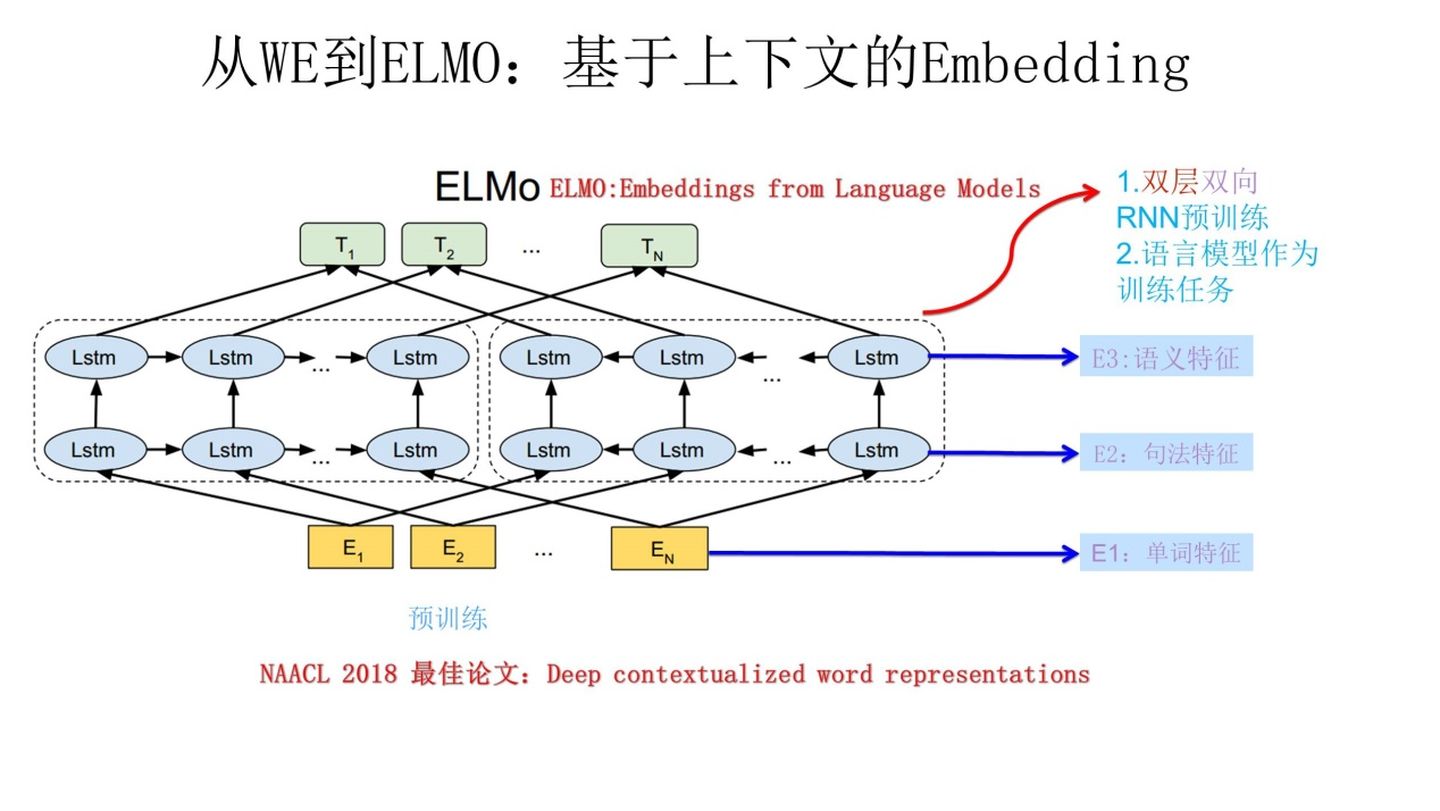
分为三部分:
- Embedding模块 - 提取单词特征
- 双层双向LSTM模块
- 第一层:提取句法特征
- 第二层:提取语义特征
- 词向量表征模块
- 使用若干参数融合每一层提取到的特征信息
Embedding模块
使用CNN去提取输入序列的文字特征,得到一个静态的Word Embedding作为整个网络的底层输入
双层双向LSTM模块
当前预训练语言模型的任务是:
根据当前词wiw_iwi的上下文去正确预测单词wiw_iwi,wiw_iwi之前的单词序列Context-before称为上文,wiw_iwi之后的单词序列Context-after称为下文
图中左侧的双层LSTM称为前向LSTM网络,输入顺序从左至右,输入除了wi以外的上文除了w_i以外的上文除了wi以外的上文
对于n个w,语言模型通过前k−1个w来计算第k个w出现的概率,构成双层前向LSTMP(w1,w2,⋯,wn)=∏k=1nP(wk∣w1,⋯,wk−1)\begin{align} 对于n个w,语言模型通过前k-1个w来计算第k个w出现的概率,构成双层前向LSTM\\ P(w_1,w_2,\cdots,w_n) = \prod_{k=1}^{n}P(w_k | w_1,\cdots,w_{k-1}) \end{align} 对于n个w,语言模型通过前k−1个w来计算第k个w出现的概率,构成双层前向LSTMP(w1,w2,⋯,wn)=k=1∏nP(wk∣w1,⋯,wk−1)
图中右侧的双层LSTM称为反向LSTM网络,输入顺序从右至左,输入除了wi以外的逆序下文除了w_i以外的逆序下文除了wi以外的逆序下文
语言模型通过后n−k个w来计算第k个w出现的概率,构成双层反向LSTMP(w1,w2,⋯,wn)=∏k=1nP(wk∣wk+1,⋯,wn)\begin{align} 语言模型通过后n-k个w来计算第k个w出现的概率,构成双层反向LSTM\\ P(w_1,w_2,\cdots,w_n) = \prod_{k=1}^{n}P(w_k | w_{k+1},\cdots,w_{n}) \end{align} 语言模型通过后n−k个w来计算第k个w出现的概率,构成双层反向LSTMP(w1,w2,⋯,wn)=k=1∏nP(wk∣wk+1,⋯,wn)
ELMo的训练目标是最大化下面这个函数
∑k=1n(P(wk∣w1,⋯,wk−1;Θx,Θ→LSTM,Θs)+P(wk∣wk+1,⋯,wn;Θx,Θ←LSTM,Θs))Θx:词的输入表示参数(CNN中的参数)Θ→LSTM:双层前向LSTM的参数Θ←LSTM:双层反向LSTM的参数Θs:输出层参数\begin{align} \sum_{k=1}^{n}(P(w_k|w_1,\cdots,w_{k-1};\Theta_{x},{\overrightarrow{\Theta}_{LSTM}},\Theta_{s})+P(w_k|w_{k+1},\cdots,w_{n};\Theta_{x},{{\overleftarrow{\Theta}}_{LSTM}},\Theta_{s}))\\ \Theta_{x}:词的输入表示参数(CNN中的参数)\\ \overrightarrow{\Theta}_{LSTM}:双层前向LSTM的参数\\ \overleftarrow{\Theta}_{LSTM}:双层反向LSTM的参数\\ \Theta_{s}:输出层参数\\ \end{align} k=1∑n(P(wk∣w1,⋯,wk−1;Θx,ΘLSTM,Θs)+P(wk∣wk+1,⋯,wn;Θx,ΘLSTM,Θs))Θx:词的输入表示参数(CNN中的参数)ΘLSTM:双层前向LSTM的参数ΘLSTM:双层反向LSTM的参数Θs:输出层参数
词向量表征模块
对于每个w,通过一个L层的双向LSTM网络,可以计算出2L+1个表示向量对于第k个词wk,第j层的双向LSTM网络Rk={xkLM,hk,jLM→,hk,jLM←∣j=1,⋯,L}={hk,j∣j=1,2,⋯,L}hk,jLM→:第j层正向LSTM对wk的隐藏状态hk,jLM←:第j层反向LSTM对wk的隐藏状态\begin{align} 对于每个w,通过一个L层的双向LSTM网络,可以计算出2L+1个表示向量\\ 对于第k个词w_k,第j层的双向LSTM网络\\ R_k = \{{x_k^{LM},\overrightarrow{h_{k,j}^{LM}},\overleftarrow{h_{k,j}^{LM}}}\ \ |\ \ j=1,\cdots,L\} = \{h_{k,j}\ \ |\ \ j=1,2,\cdots,L\}\\ \overrightarrow{h_{k,j}^{LM}}:第j层正向LSTM对w_k的隐藏状态\\ \overleftarrow{h_{k,j}^{LM}}:第j层反向LSTM对w_k的隐藏状态 \end{align} 对于每个w,通过一个L层的双向LSTM网络,可以计算出2L+1个表示向量对于第k个词wk,第j层的双向LSTM网络Rk={xkLM,hk,jLM,hk,jLM ∣ j=1,⋯,L}={hk,j ∣ j=1,2,⋯,L}hk,jLM:第j层正向LSTM对wk的隐藏状态hk,jLM:第j层反向LSTM对wk的隐藏状态
Feature-based Pre-Training
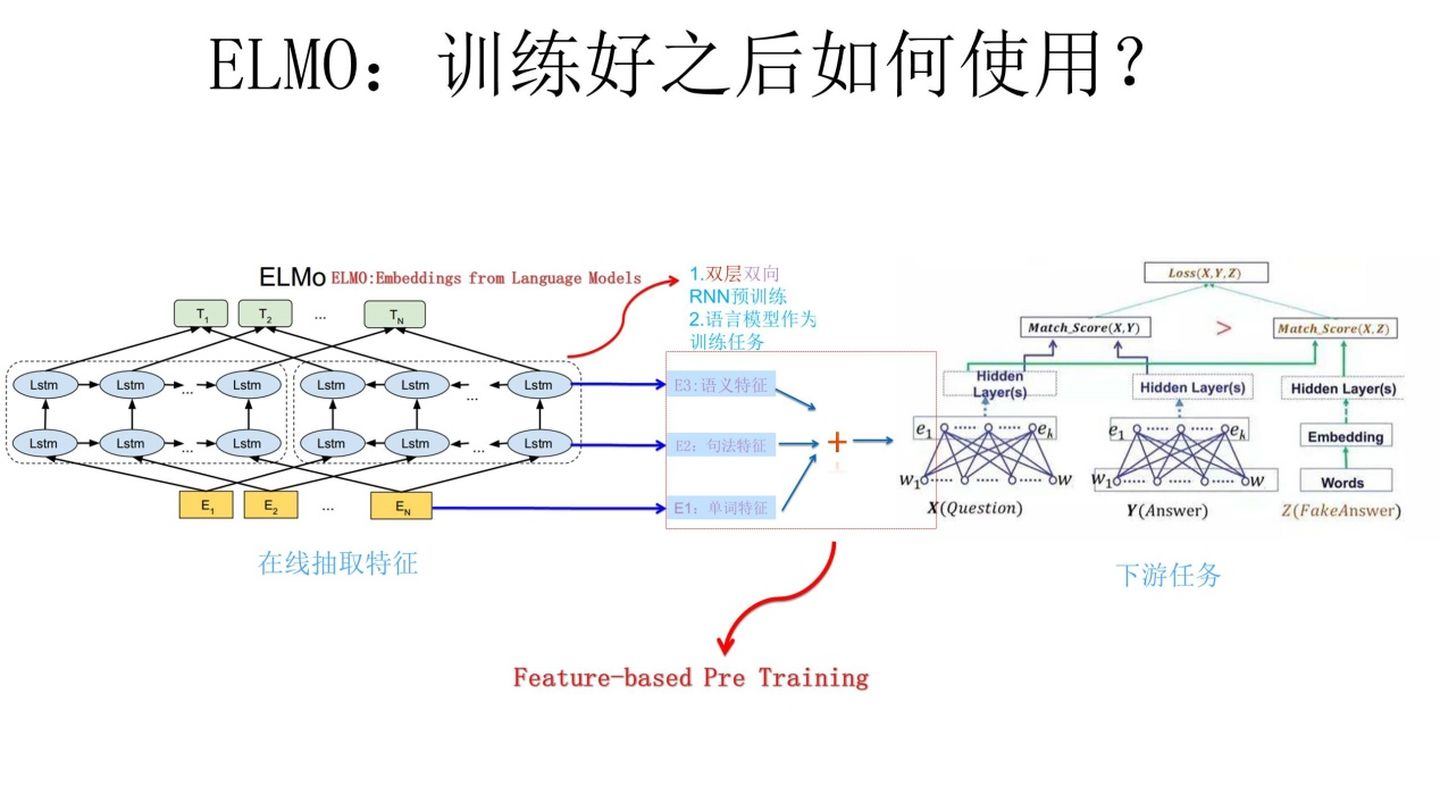
上图展示了下游任务的使用过程
比如我们的下游任务是QA,此时对于问句X:
- 将这个X作为预训练好的
ELMo网络的输入,这样X中的每个单词在ELMo网络中都能获取对应的3个embedding - 分别给予这3个
embedding权重a,这个权重可以学习得来; - 根据各自权重累加求和,将三个
embedding整合成一个 - 将整合后的
embedding作为X句在自己任务中的对应单词的输入,以此作为补充的新特征给下游任务使用
因为 ELMo 给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为 “Feature-based Pre-Training”
GPT模型
GPT(Generative Pre-Training)是指生成式的预训练模型
不同于ELMo模型的基于特征融合的预训练方法,GPT采用了一种叫 Fine-tuning(微调) 的预训练方法
GPT也采用两阶段过程:
- 阶段1:利用语言模型进行预训练
- 阶段2:通过
Fine-tuning模型解决下游任务
预训练
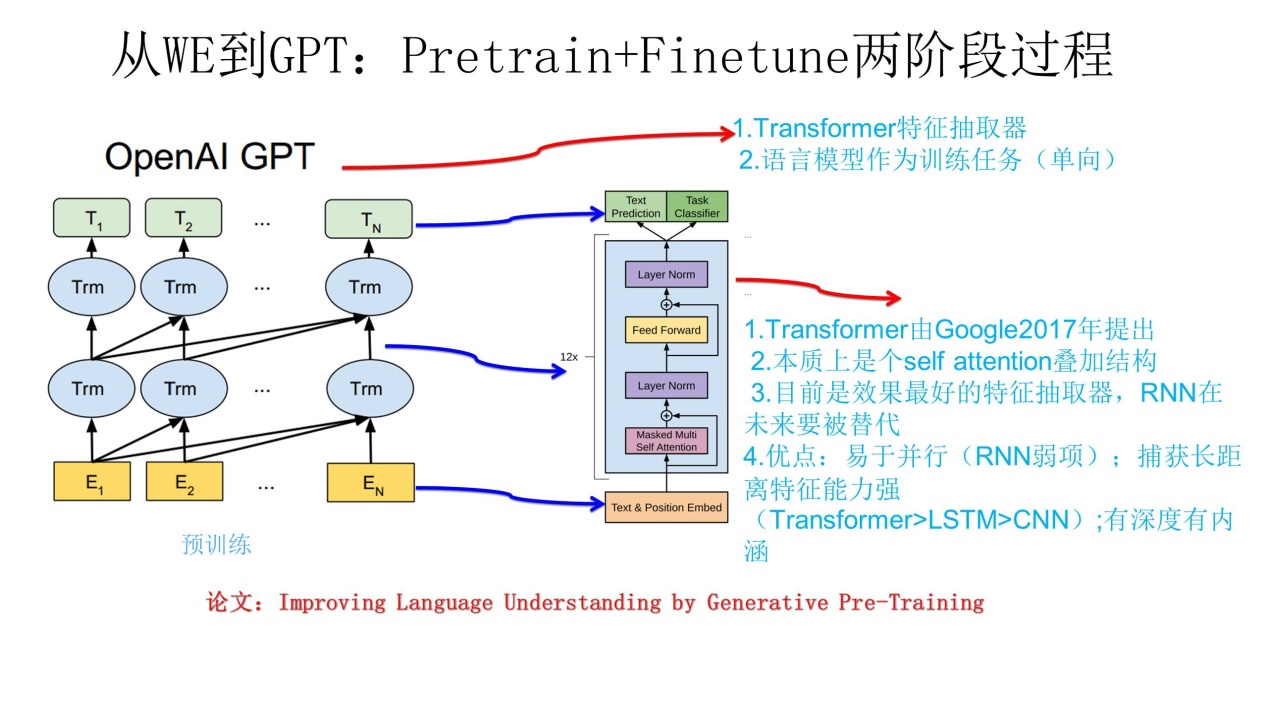
这个结构乍一看,和ELMo模型很像,但是有以下不同:
- 特征抽取器使用了双层
Transfomer,而不是双层LSTM,有利于学习长序列和并行运行 GPT使用单向语言模型;特征抽取时不同时使用上文下文,仅使用上文预测;而ELMo的双层双向LSTM则是同时使用上文和下文进行预测
缺点:从现在来看,使用单向语言模型,没有融合单词的下文,在一些应用场景受限,比如完成阅读理解任务,这个任务允许同时看到上文和下文来进行决策
Fine-tuning解决下游任务
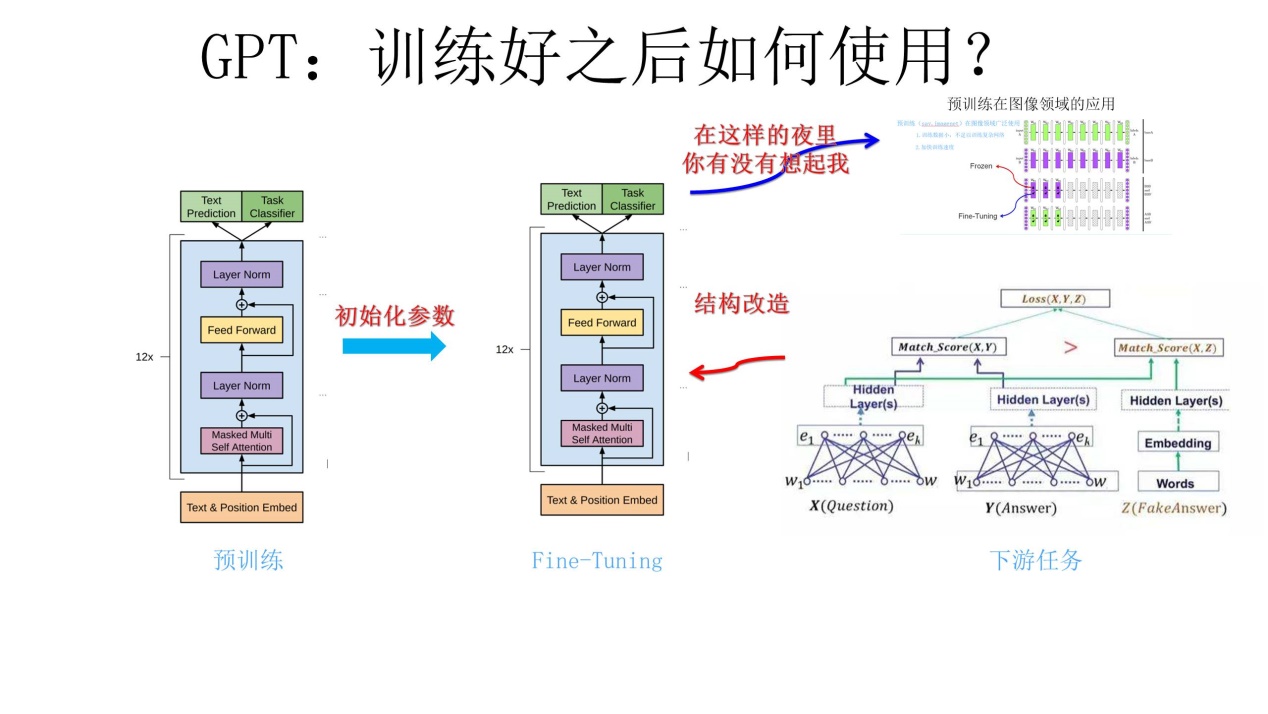
- 对于下游网络来说,要将网络结构改造成与
GPT一样的网络结构 - 做下游任务时,利用第一步预训练好的参数去初始化下游任务网络(与
GPT结构一样)的网络结构,这样一来,预训练学到的语言学知识就被引入到当前任务中了 - 用当前任务再去训练这个网络,对参数进行
Fine-tuning,使这个网络更适合解决当前问题
那么到底什么是Fine-tuning呢?
Fine-tuning
其实上面解决下游任务的过程已经对Fine-tuning简单地描述了一遍
Fine-tuning其实就是在已经训练好的模型的基础上,针对特定任务,再对模型的部分/全部参数进行训练,以使模型更适应当前任务(很像迁移学习)
优点
- 解决小规模数据集的训练问题
- 节省训练时间和成本
- 提升模型在目标任务上的性能
BERT模型
参考
定义
BERT模型(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 架构的预训练语言模型
它的特殊之处并不是说它有什么很突出的创新点,而是集大成者
所谓集大成者:
- 借鉴了
ELMo模型双向双层LSTM同时使用上文下文预测的思路 - 与
GPT类似,使用Transformer作为特征提取器 - 采用了
Word2Vec的CBOW模型
结构 & 对比
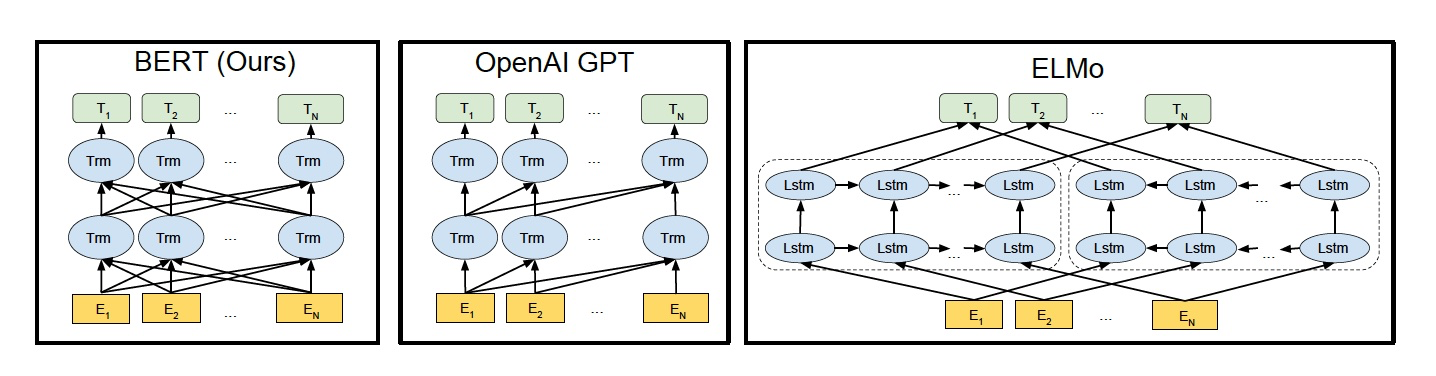
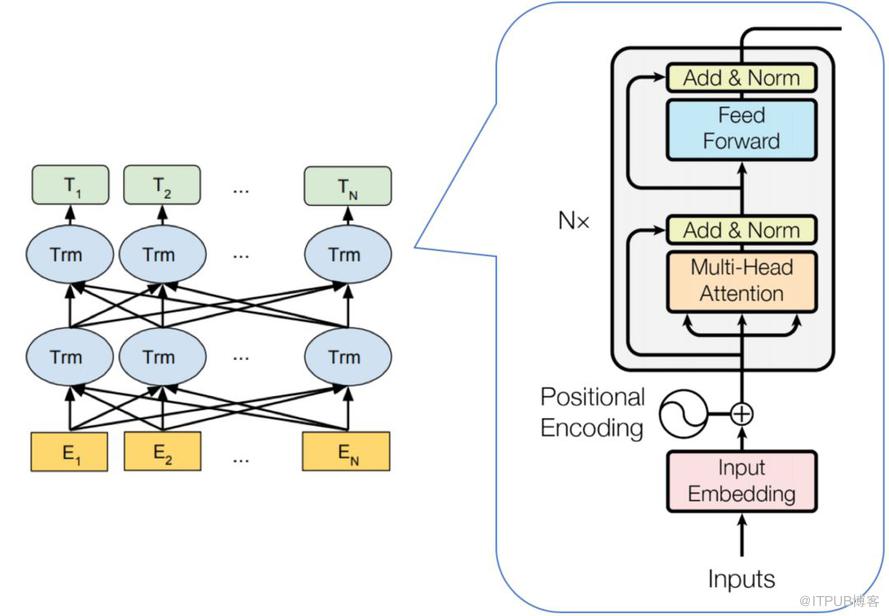
ELMo使用从左向右和从右向左的两个LSTM网络,分别以 P(wi∣w1,⋯,wi−1)和 P(wi∣wi+1,⋯,wn)P(w_i|w_1,\cdots,w_{i-1})\ 和\ P(w_i|w_{i+1},\cdots,w_{n})P(wi∣w1,⋯,wi−1) 和 P(wi∣wi+1,⋯,wn)作为目标函数独立训练,将训练得到的特征向量用拼接实现双向编码,其实本质上还是相当于单向编码GPT使用Transformer Decoder作为Transformer Block,以P(wi∣w1,⋯,wi−1)P(w_i|w_1,\cdots,w_{i-1})P(wi∣w1,⋯,wi−1)为目标函数,使用Transformer Block代替LSTM进行特征提取,实现了单向编码,是一个标准的预训练语言模型BERT也是一个标准的预训练语言模型,以P(wi∣w1,⋯,wn)P(w_i|w_1,\cdots,w_n)P(wi∣w1,⋯,wn)作为目标函数进行训练;使用Transformer Encoder作为Transformer Block,将GPT的单向编码改为双向编码;也就是说,BERT舍弃了文本生成能力,换来了更强的语义理解能力
BERT的模型其实就是Transformer Encoder的堆叠,在模型参数上,官方一开始提供了两个版本:
BERTBASE:L=12,H=768,A=12BERTLARGE:L=24,H=1024,A=16L:TransformerBlock的层数H:特征向量的维度A:多头自注意力机制的头数\begin{align} BERT_{BASE}:L=12,H=768,A=12\\ BERT_{LARGE}:L=24,H=1024,A=16\\ L:Transformer\ Block的层数\\ H:特征向量的维度\\ A:多头自注意力机制的头数\\ \end{align} BERTBASE:L=12,H=768,A=12BERTLARGE:L=24,H=1024,A=16L:Transformer Block的层数H:特征向量的维度A:多头自注意力机制的头数
无监督训练
方法
BERT也采用二阶段预训练方法:
- 第一阶段:使用易获取的大规模无标签语料,训练基础语言模型
- 第二阶段:使用指定任务的少量带标签数据进行
Fine-tuning
任务
- 使用语言掩码模型(MLM)方法训练词的语义理解能力
- 用下句预测(NSP)方法训练句子之间的理解能力,从而更好支持下游任务
语言掩码模型MLM
由来
BERT作者认为自左向右和自右向左的单向编码器拼成的双向编码器,在性能,参数规模,效率等方面都不如深度双向编码器
这就是为什么BERT使用Transformer Encoder作为特征提取器,而不是使用从左至右编码和从右至左编码的两个Transformer Decoder
由于无法使用标准语言模型的训练模式(?),BERT使用MLM进行训练模型,MLM借鉴了完形填空和CBOW的思想
回答:传统的语言模型(基于循环神经网络构建的语言模型)都是单向的,比如ELMo(两个单向拼接成一个双向);而BERT是双向语言模型,所以需要使用全新的训练方式
- AR模型(自回归模型)
- 根据上文预测下一个单词,或根据下文预测前一个单词,只能考虑单侧信息
- AE模型(自编码模型)
- 从损坏的输入数据中预测重构原始数据,可以使用上下文信息,
BERT采用的就是AE模型
- 从损坏的输入数据中预测重构原始数据,可以使用上下文信息,
做法
在原始句子中,随机抽取15%的token进行掩盖,用其上下文去判断[mask]位置被掩盖的token原本应该是什么
由于BERT使用AE模型,MLM的做法会有个问题,15%的掩盖率其实很高了,会导致掩码词在下游任务Fine-tuning阶段从未被见过,导致了预训练和Fine-tuning的不一致
简单理解就是:在预训练学习阶段,模型已经习惯了[mask],那么MLM学到的一些表达就可能依赖于[mask];但是在下游任务中[mask]可能从未出现,这就导致了一些表达无法很好的迁移
为了解决这个问题,对于被选取的作为掩码词的15%的token,不是全用[mask]代替,而是采取以下做法来解决上述弊端:
- 对于80%的训练样本:
- 将选取的
token直接替换成[mask]
- 将选取的
用[]表示选取中的token比如:我好饿啊,我想吃[饭]↓我好饿啊,我想吃[mask]
- 对于10%的训练样本:
- 选中的词原封不动,为了缓解训练文本和预测文本的偏差带来的性能损失
- 对于最后10%的训练样本:
- 将选中的词随机替换成一个新词,这样是为了让
BERT学会根据上下文纠错
- 将选中的词随机替换成一个新词,这样是为了让
用[]表示选取中的token比如:我好饿啊,我想吃[饭]↓我好饿啊,我想吃电脑
这样的好处是:编码器不知道哪些词是需要预测的,哪些词是错误的,因此被迫学习每一个token的表示向量
下句预测NSP
在很多自然语言处理的下游任务(如问答,自然语言推断)中,都基于两个句子做逻辑推理,但模型本身并不具备直接捕获句
子之间语义联系的能力,或者说,单词预测的训练(比如GPT,ELMo,都是基于上下文对单词预测)达不到句子关系这个层级
为了学会捕捉句子之间的语义联系,BERT 采用了下句预测(NSP)作为无监督预训练的一部分。
NSP的具体做法是:BERT的输入由两个句子(A,B)组成,其中:
- 50%的概率为这两个句子是连续的,即B是真实文本中A的下一句话
- 另外50%的概率为这两个句子是随机抽取的
句子的形式:
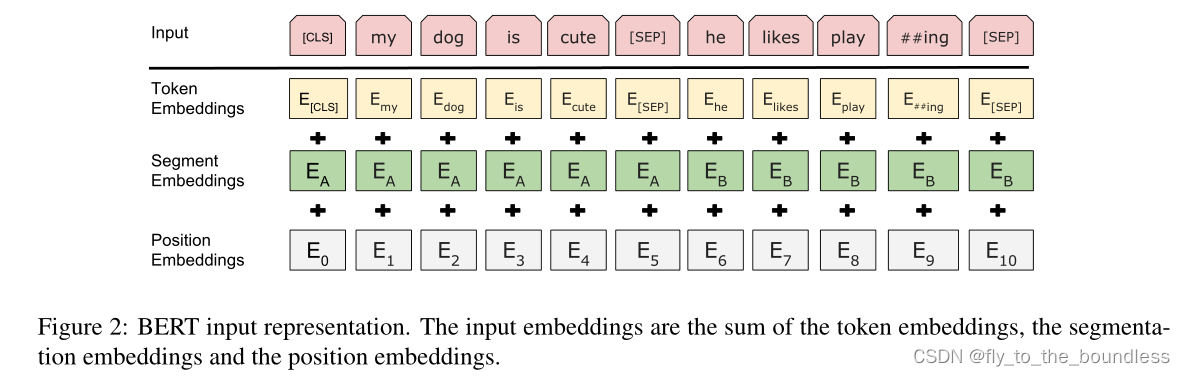
[CLS] A [SEP] B [SEP]
[SEP]标签表示分隔符
[CLS]标签用于类别预测,结果为1时,表示输入连续句对(isNext),为0时表示随机句对(notNext)
通过训练[CLS]编码后的输出标签,BERT可以学会捕捉两个输入句对的文本语义
eg:
Input: [CLS]The man went to [MASK] [SEP] He bought a bottle of Coke[SEP]
Label: isNextInput: [CLS]The man [MASK] to store[SEP] I'm going to sleep[SEP]
Label: notNext
输入表示
BERT的预训练方法有以上两种,但是实际使用中通常是两种方法混合使用
由于BERT模型通过Transformer Encoder堆叠组成,因此BERT的输入需要两套embedding操作:
- Token Embeddings
- 将各个词转换为固定维度的向量表示;
- 在BERT中,每个单词会先进行
Tokenization后再输入Token Embeddings层中 - 插入两个特殊的
Token,在Tokenization的结果开头加上[CLS],结尾加上[SEP] - 最终转换为768维的向量
- 在BERT中,每个单词会先进行
- 将各个词转换为固定维度的向量表示;
- Position Embeddings
- 不同于
Transformer中用三角函数固定表示每个位置的位置编码,BERT中的位置编码是预训练过程中通过学习得来的,训练思想类似于Word2Vec中嵌入矩阵Q
- 不同于
- Segment Embeddings
- 用于区分一个单词属于句子对中的哪个句子
- 赋0:第一个句子中的各个
Token - 赋1:第二个句子中的各个
Token
- 赋0:第一个句子中的各个
- 用于区分一个单词属于句子对中的哪个句子
这3个向量都是768维的,最后将其按元素相加,得到最终的Input Embedding
自定义绘图控件--波形图)




)

----PromptPilot (助手)答问之2)




)






