一、deepseek-app-1.0
1、系统要求
- CentOS 7.9
- Python 3.8+
- Node.js 16+
- MySQL 8.0
2、部署步骤
- 运行初始化脚本:
./scripts/setup.sh - 初始化数据库:
mysql -u root -p < scripts/init_db.sql - 启动服务:
./scripts/start.sh
3、访问地址
- 前端:http://服务器IP:3000
- 后端API:http://服务器IP:5001/api/subjects
4、项目网盘
- 主链接:https://www.123684.com/s/kPEvTd-0K7d3提取码:podL
- 备用链接:https://www.123912.com/s/kPEvTd-0K7d3提取码:podL
- 二维码:

5、项目地址
https://github.com/bei-chen-1/AI
bei-chen-1/AI: 存放AI相关的项目/Store AI-related projects
6、系统架构
- 前端:React
- 后端:Flask
- 数据库:MySQL
- 大模型:DeepSeek-R1:1.5B
7、项目目录
- /opt/deepseek-app-1.0
- ├── backend/ # Flask 后端
- ├── docs/ # 文档
- ├── frontend/ # React 前端
- ├── scripts/ # 系统脚本
- ├── logs/ # 日志目录
8、详细目录
- /opt/deepseek-app-1.0
- ├── backend/ # Flask 后端服务
- │ ├── app.py # 后端主应用(Flask)
- │ └── requirements.txt # Python 依赖列表
- │ └── database.py # 数据库操作
- ├── frontend/ # React 前端应用
- │ ├── public/ # 公共资源目录
- │ │ └── index.html # HTML 入口文件
- │ ├── src/ # 源代码目录
- │ │ ├── App.js # 主应用组件
- │ │ ├── App.css # 主样式文件
- │ │ └── index.js # React 入口文件
- │ │ └── components/
- │ │ └── HistoryPanel.js #历史记录面板文件
- │ └── package.json # Node.js 项目配置
- │ └── package-lock.json # Node.js 项目配置
- ├── scripts/ # 系统脚本
- │ ├── start.sh # 服务启动脚本
- │ ├── stop.sh # 服务关闭脚本
- │ └── init_db.sql # 数据库初始化脚本
- ├── logs/ # 日志目录(运行时自动生成)
- └── docs/ # 文档目录
- └── README.md # 项目说明文档
9、核心文件
后端主文件 | /opt/deepseek-app/backend/app.py | Flask应用入口,包含API路由 |
前端入口 | /opt/deepseek-app/frontend/src/App.js | React应用主组件 |
组件目录 | /opt/deepseek-app/frontend/src/components/ | 包含所有React组件 |
启动脚本 | /opt/deepseek-app/scripts/start.sh | 应用启动脚本 |
构建目录 | /opt/deepseek-app/frontend/build/ | 前端构建输出目录 |
10、项目架构
- 用户浏览器
- ↓
- HTTP 请求 (端口:5001)
- ↓
- Flask 后端 (app.py)
- ├─ 静态文件服务 → 前端构建 (frontend/build)
- ├─ API 路由:
- │ ├─ /api/subjects → 获取学科列表
- │ ├─ /api/generate → 生成题目
- │ └─ /api/judge → 判题
- ↓
- 后端服务
- ├─ 数据库操作 → MySQL (knowledge_db)
- └─ 模型调用 → Ollama (DeepSeek-R1:1.5B)
11、关键功能流程
- 学科加载:
- o 前端请求 /api/subjects
- o 后端从 MySQL 获取学科数据
- o 返回学科列表给前端
- 题目生成:
- o 用户选择学科并点击"生成新题目"
- o 前端发送 POST 到 /api/generate
- o 后端从知识库随机选题或调用模型生成
- o 返回题目内容
- 判题:
- o 用户输入答案并提交
- o 前端发送题目和答案到 /api/judge
- o 后端从知识库获取正确答案或调用模型判题
- o 返回批改结果
12、流程图
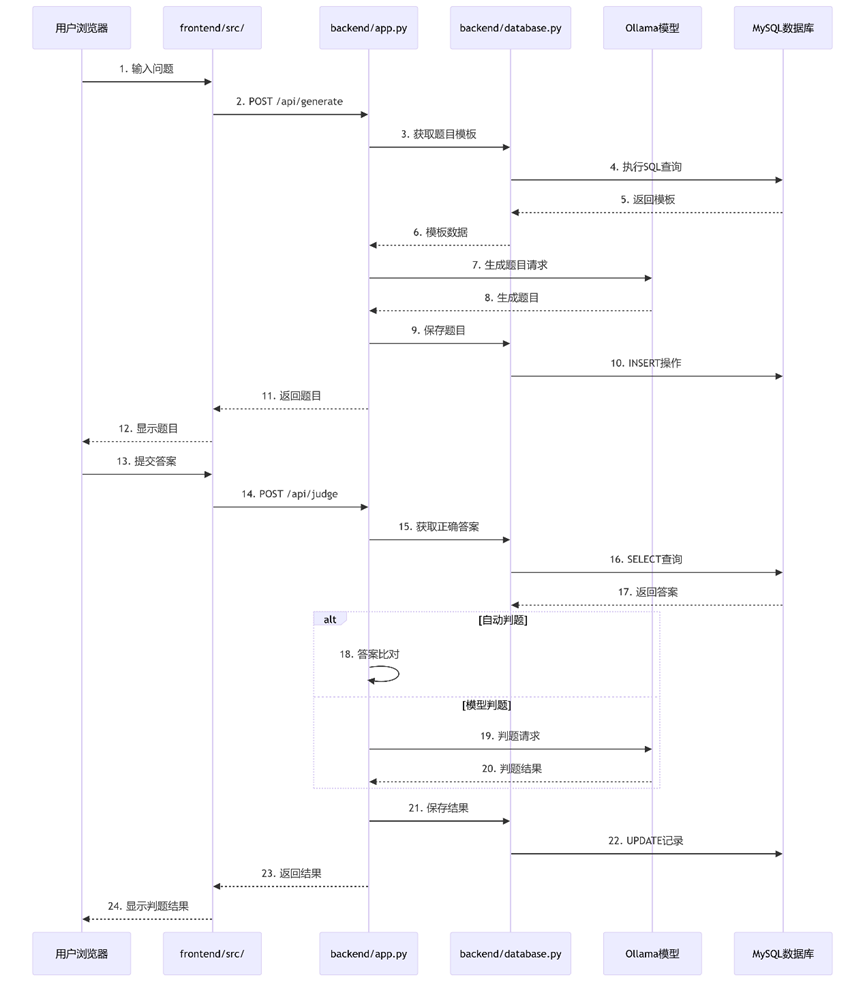
- Web 前端(React) ——> Flask 后端(Python) ——> Ollama 模型(DeepSeek)
- MySQL 知识库(题目/答案) <——> Flask 后端(Python)
13、完整数据流路径(用户请求 → 判题结果)
- (1)用户发起请求
- 用户操作:在浏览器界面输入问题/题目
- 触发文件:frontend/src/App.js(主应用组件)
- (2)API请求转发(后端入口)
- 接收文件:backend/app.py(Flask主应用)
- (3)数据库操作(z知识库交互)
- 执行文件:backend/database.py
- (4)模型服务调用(ollama集成)
- 调用ollama模型,出题
- (5)用户提交答案(判题开始)
- 前端文件:frontend/src/components/HistoryPanel.js
- (6)判题处理(后端逻辑)
- 执行文件:backend/app.py
- (7)结果返回与展示
- 前端文件:frontend/src/App.js
二、deepseek-app-2.0
1、系统要求
- CentOS 7.9
- Python 3.8+
- Node.js 16+
- MySQL 8.0
2、部署步骤
- 运行初始化脚本:
./scripts/setup.sh - 初始化数据库:
mysql -u root -p < scripts/init_db.sql - 启动服务:
./scripts/start.sh
3、访问地址
- 前端:http://服务器IP:3000
- 后端API:http://服务器IP:5001/api/subjects
4、项目网盘
- 主链接:https://www.123684.com/s/kPEvTd-0K7d3提取码:podL
- 备用链接:https://www.123912.com/s/kPEvTd-0K7d3提取码:podL
- 二维码:
5、项目地址
https://github.com/bei-chen-1/AI
bei-chen-1/AI: 存放AI相关的项目/Store AI-related projects
6、系统架构
- 前端:React
- 后端:Flask
- 数据库:MySQL
- 大模型:DeepSeek-R1:1.5B
7、项目目录
- /opt/deepseek-app-2.0
- ├── backend/ # Flask 后端服务
- ├── frontend/ # React 前端应用
- ├── scripts/ # 系统脚本
- ├── logs/ # 日志目录
- └── docs/ # 文档
8、详细目录
- /opt/deepseek-app-2.0
- ├── backend/
- │ ├── static # 后端静态文件
- │ │ ├──favicon.ico # 后端图标
- │ ├── app.py # 后端主应用(核心逻辑)
- │ ├── requirements.txt # Python 依赖
- │ └── .env # 环境变量配置
- ├── frontend/
- │ ├── public/
- │ │ └── index.html # HTML 入口
- │ │ └── favicon.ico #图标
- │ ├── src/
- │ │ ├── App.js # 主应用组件
- │ │ ├── App.css # 全局样式
- │ │ ├── index.js # React 入口
- │ │ └── components/
- │ │ └── ExamPanel.js # 考试面板组件(核心UI)
- │ │ └── ExamPanel.css # 考试面板样式
- │ ├── package.json # 前端依赖
- │ └── .env # 前端环境变量
- │ └── .env.production # 前端生产环境变量
- ├── scripts/
- │ ├── start.sh # 启动脚本
- │ ├── stop.sh # 停止脚本
- │ └── init_db.sql # 数据库初始化脚本(核心数据)
- ├── logs/ # 日志目录
- └── docs/
- └── README.md # 项目文档
9、核心文件
- 后端核心:
- o backend/app.py: 处理所有API请求(试卷生成、判卷)
- o scripts/init_db.sql: 数据库结构和初始数据
- 前端核心:
- o frontend/src/components/ExamPanel.js: 考试界面组件
- o frontend/src/App.js: 应用主入口
- 系统脚本:
- o scripts/start.sh: 启动所有服务
- o scripts/stop.sh: 停止所有服务
10、项目架构
- React 前端(localhost:3000)——>Flask 后端 (localhost:5001)——> MySQL 数据库(knowledge_db)
- 用户浏览器(UI交互)——>React 前端(localhost:3000)
- OLLAMA 服务(DeepSeek模型)——>Flask 后端 (localhost:5001)
11、架构说明
- 前端层: React应用提供用户界面
- API层: Flask处理业务逻辑和路由
- 数据层: MySQL存储题目和答案
- AI层: OLLAMA服务提供DeepSeek模型
- 脚本层: Shell脚本管理服务生命周期
12、关键功能流程
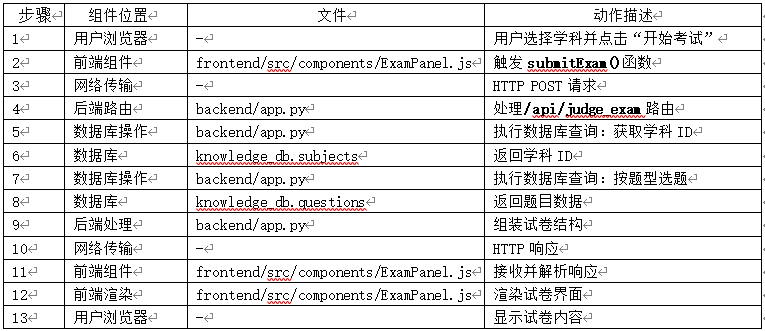
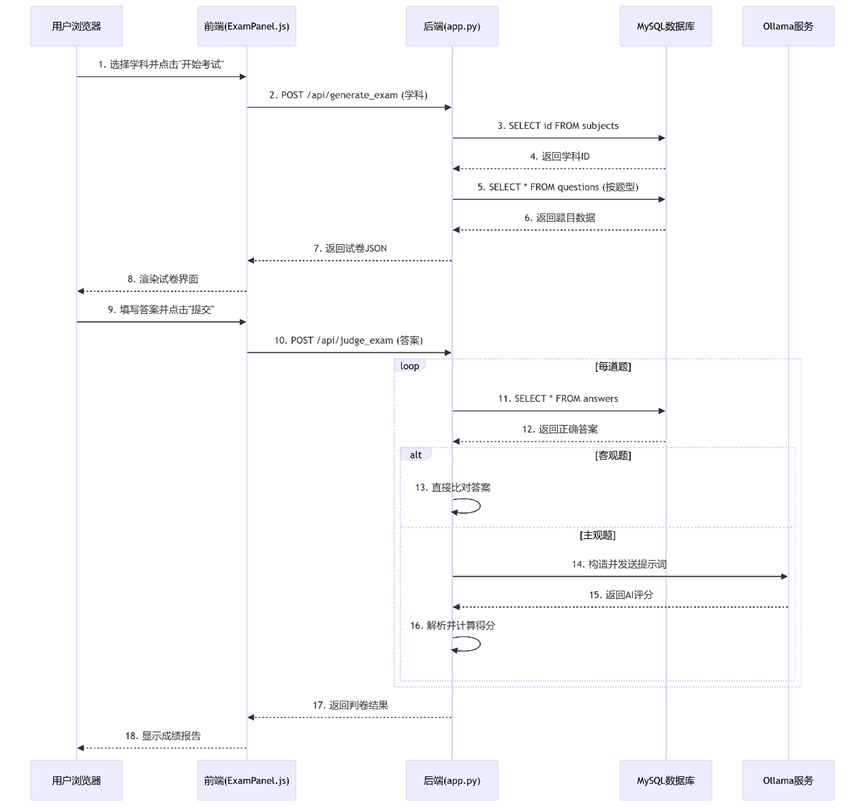
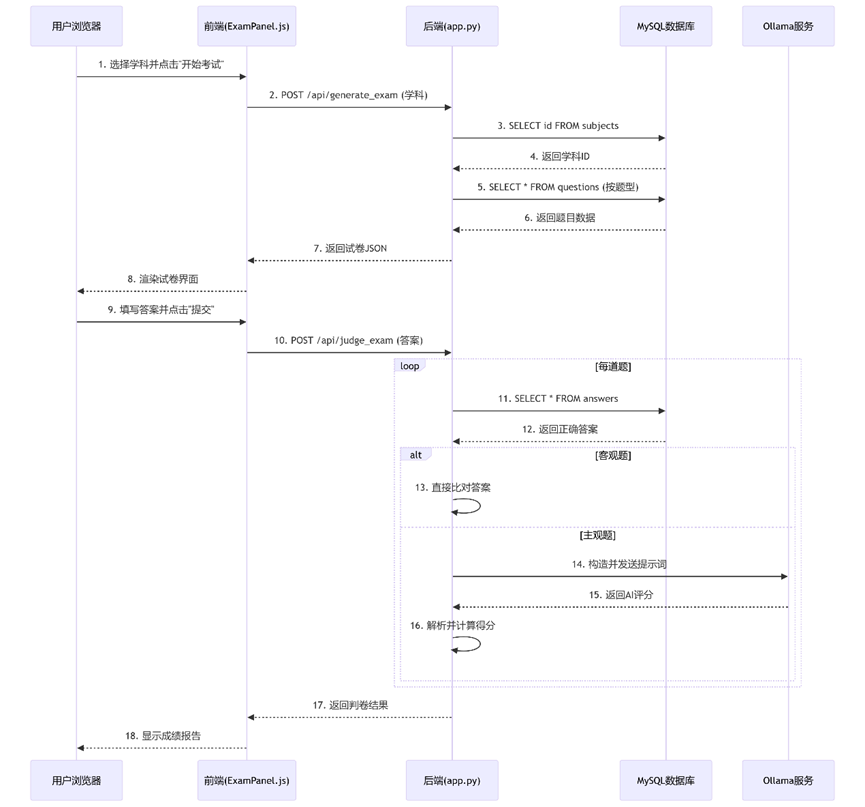
- 1、 试卷生成流程:
- (1) 用户选择学科
- (2) 前端调用/api/generate_exam
- (3) 后端按题型比例随机选题
- (4) 返回试卷结构
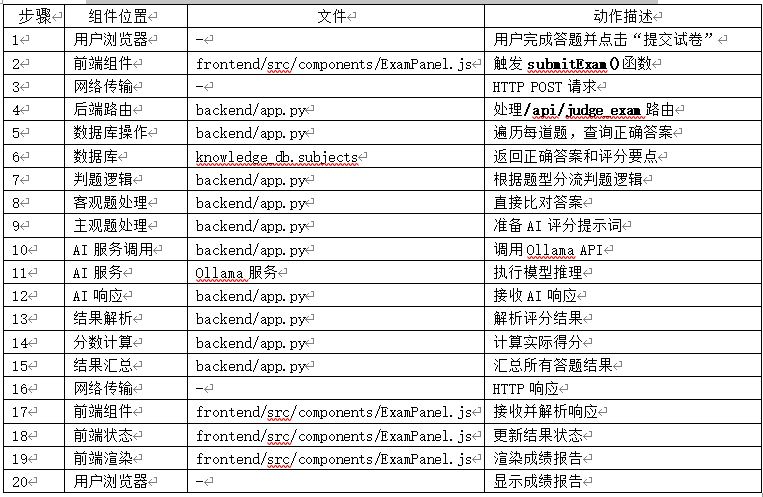
- 2、 智能判卷流程:
- (1) 用户提交答案
- (2) 前端调用/api/judge_exam
- (3)后端处理每道题:
- o 客观题: 直接比对答案
- o 主观题: 调用DeepSeek模型评分
- (4)计算总分并返回结果
- 3、 主观题评分流程:
- (1) 构造包含题目、答案、评分点的提示词
- (2) 调用DeepSeek模型获取评分
- (3) 解析模型返回的评分结果
- (4) 按比例计算实际得分
13、用户发起请求:选择学科 → 生成试卷
- 路径:用户浏览器 → 前端组件 → 后端API → 数据库 → 返回试卷
14、用户提交答案 → 判卷流程
- 路径:用户浏览器 → 前端组件 → 后端API → 数据库/AI模型 → 返回判卷结果
15、流程图
16、项目效果图
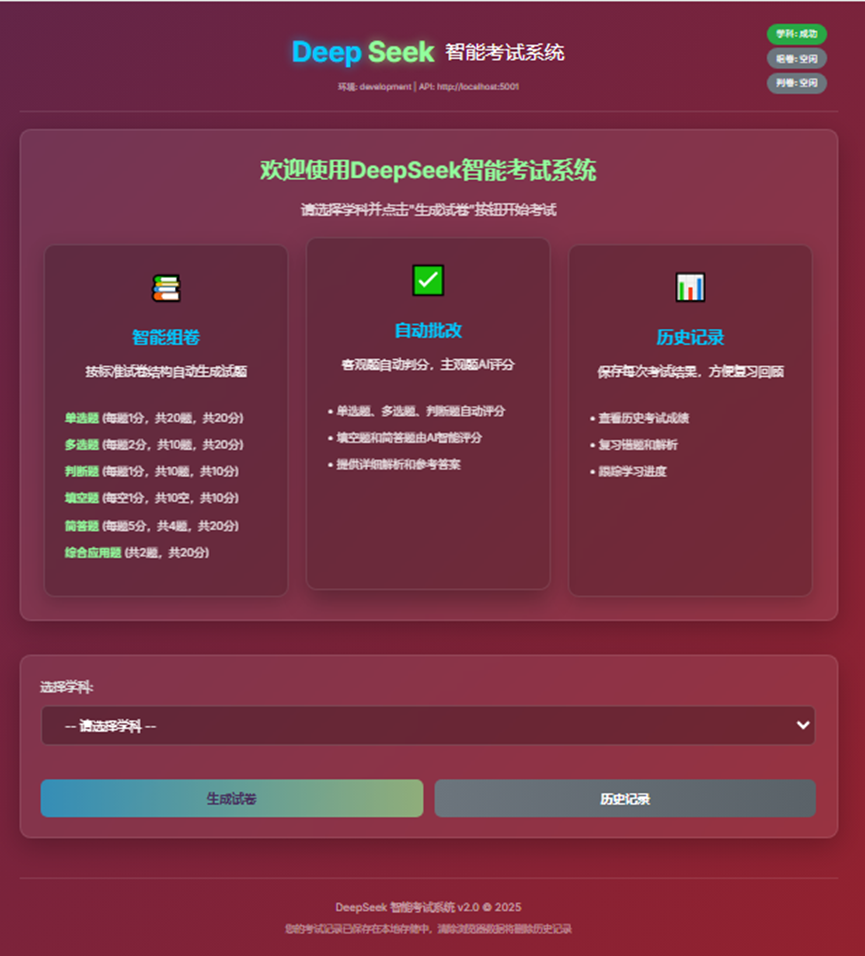
- 1、前端头部

- 2、前端欢迎

- 3、前端尾部
- 4、前端全貌
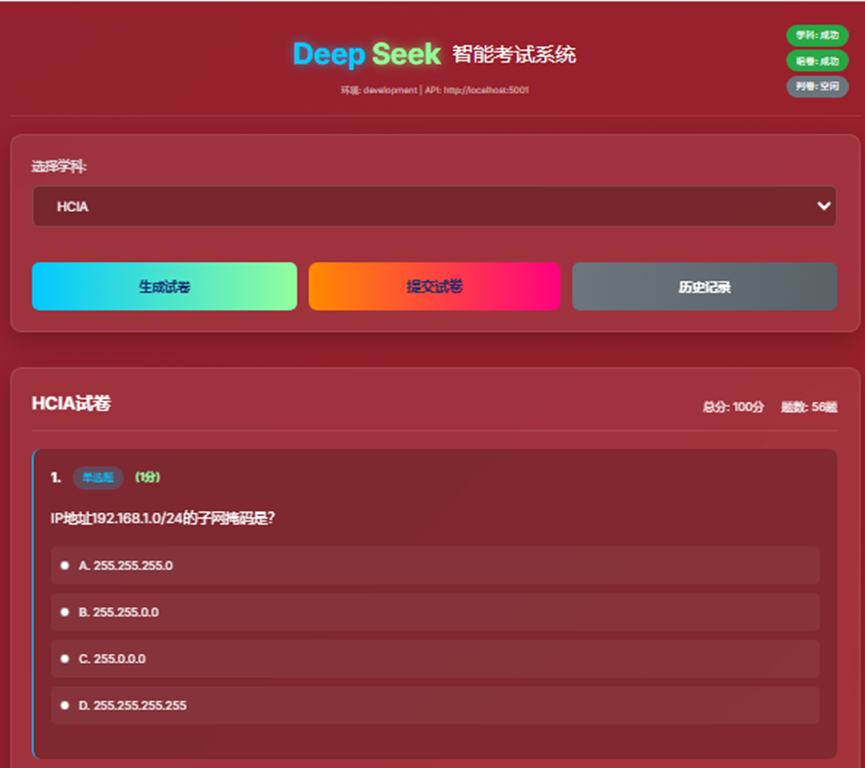
- 5、试卷界面
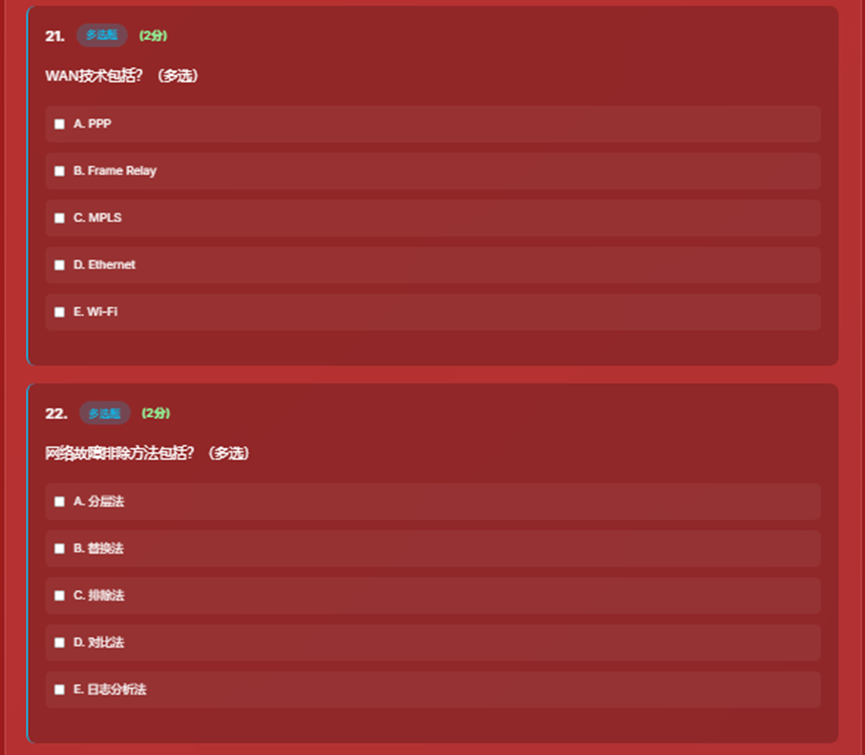
- 6、多选题界面
- 7、判断题界面
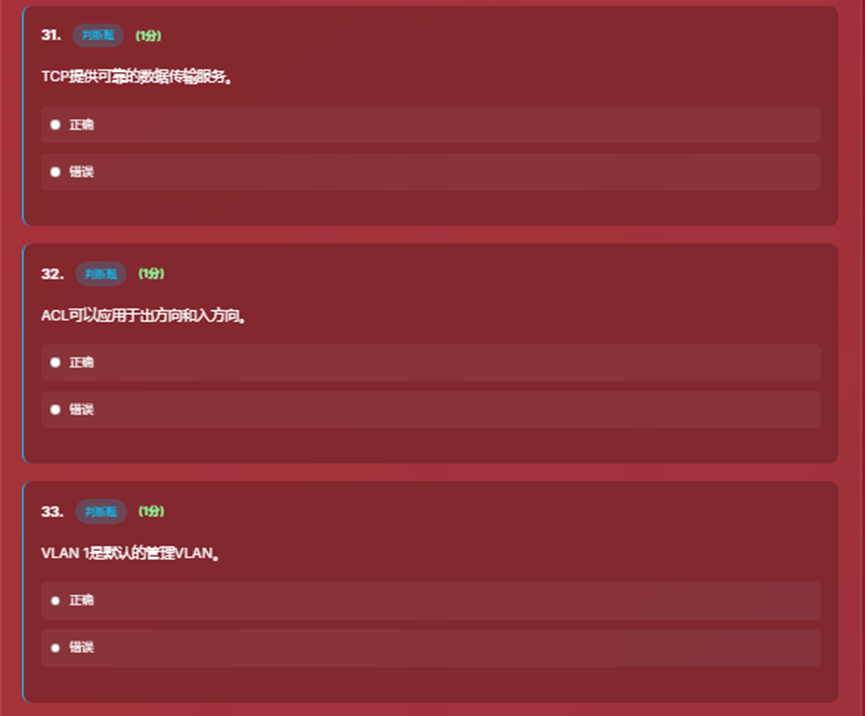
- 8、填空题和简答题界面

- 9、综合应用题界面
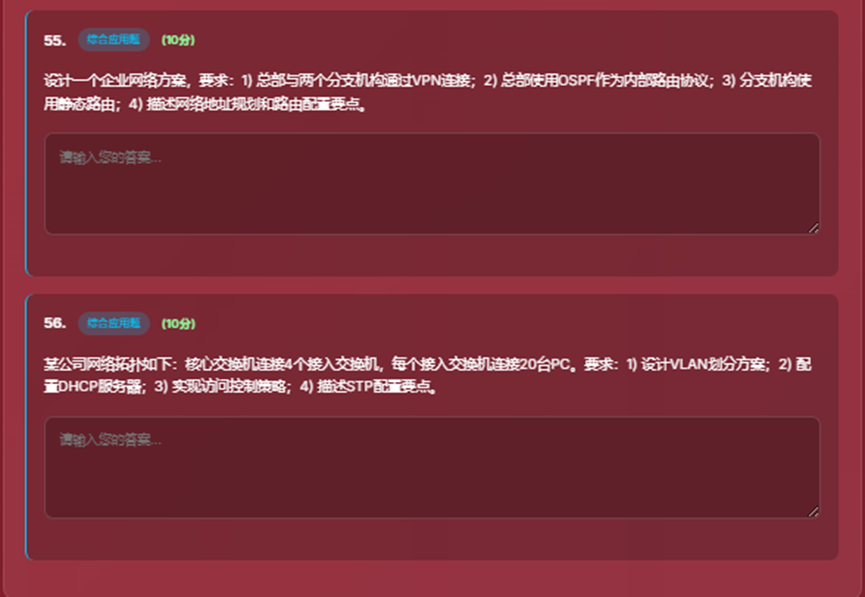
- 10、得分界面
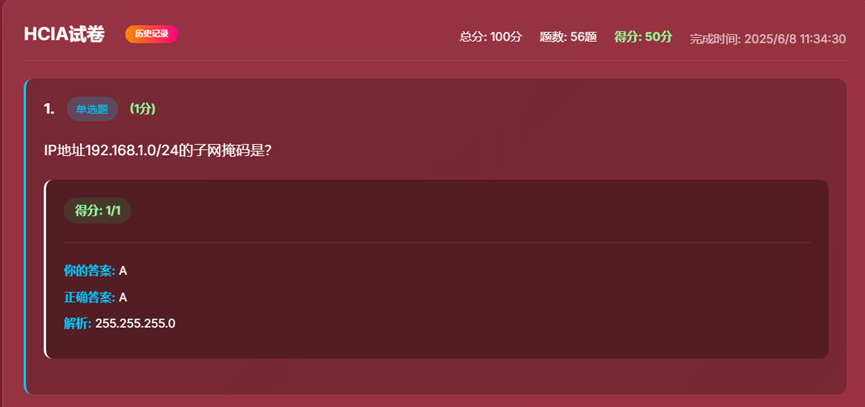
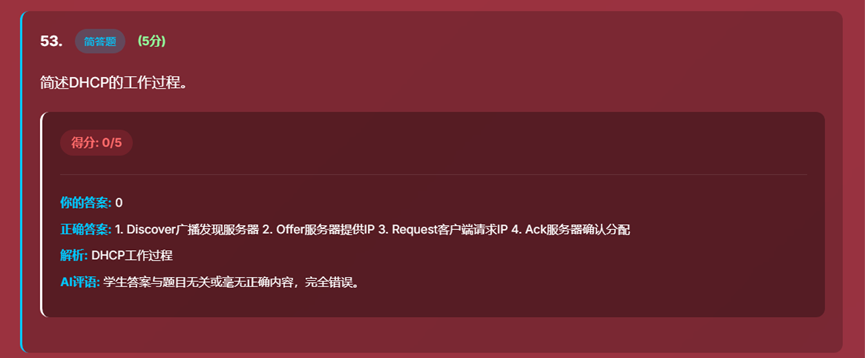
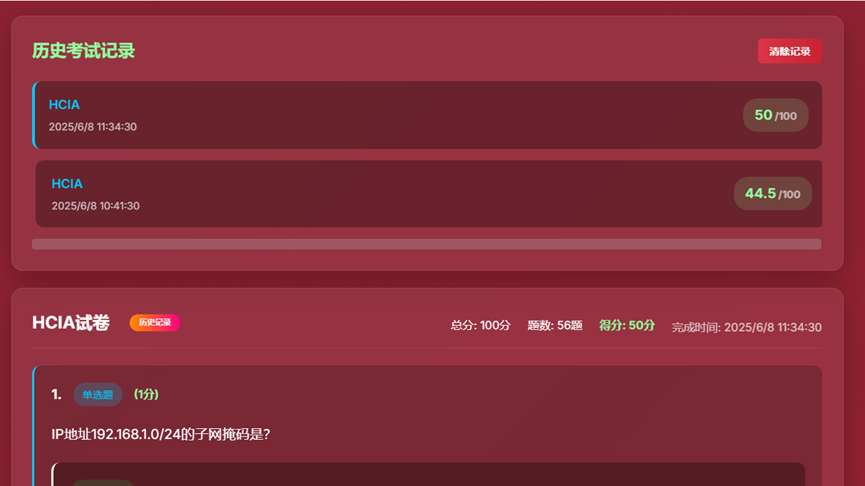
- 11、历史考试记录界面
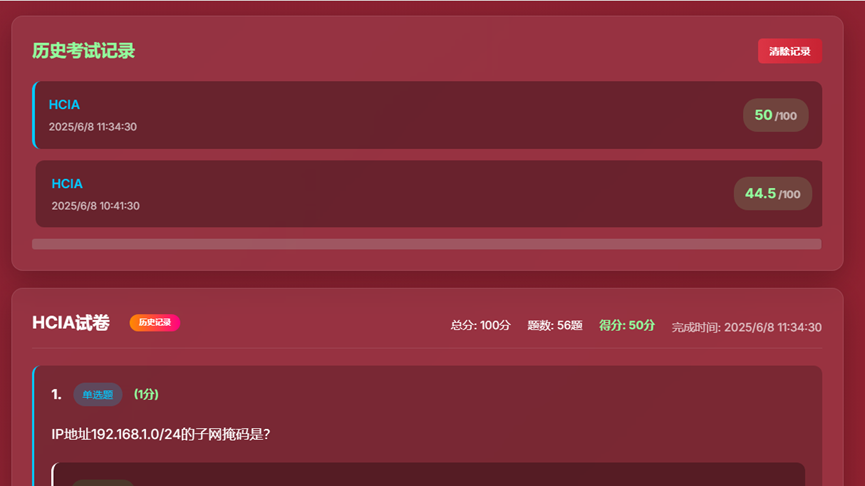
三、deepseek-app-2.1
1、系统要求
- CentOS 7.9
- Python 3.8+
- Node.js 16+
- MySQL 8.0
2、部署步骤
- 搭建系统所需环境
- 初始化数据库:
mysql -u root -p < scripts/init_db.sql - 启动服务:
./scripts/start.sh - 关闭服务:
./scripts/stop.sh
3、访问地址
- 前端:http://服务器IP:3000
- 后端API:http://服务器IP:5001/api/subjects
4、项目网盘
- 主链接:https://www.123684.com/s/kPEvTd-0K7d3提取码:podL
- 备用链接:https://www.123912.com/s/kPEvTd-0K7d3提取码:podL
- 二维码:
5、项目地址
https://github.com/bei-chen-1/AI
bei-chen-1/AI: 存放AI相关的项目/Store AI-related projects
6、系统架构
- 前端:React
- 后端:Flask
- 数据库:MySQL
- 大模型:DeepSeek-R1:1.5B
7、前端依赖
- 目录:frontend
- 命令:
npm install sonner - 命令:
npm install lucide-react - 命令:
npm install tailwind-merge
8、后端依赖
- 目录:backend
- 命令1:
pip install -r requirements.txt - 命令2:
npm install react-svg - 命令3:
npm install gojs
9、网络拓扑图绘制API
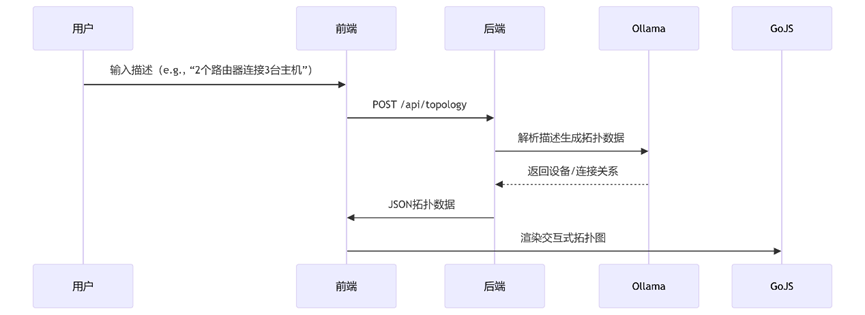
- API接口地址:
POST /api/ai/generate-topology
- 你可以通过调用后端API接口实现网络拓扑图的AI自动生成。
- 请求参数:
- 字段:
description - 类型:
string
- 示例请求体(JSON):
json { "description": "最上方是防火墙,防火墙下方连接路由器,路由器下方连接交换机,交换机连接两个主机和一个无线AP" } - 返回结果格式:
json { "devices": [ { "id": "router_1", "label": "路由器_1", "type": "router", "position": { "x": 150, "y": 80 } }, { "id": "switch_1", "label": "交换机_1", "type": "switch", "position": { "x": 150, "y": 200 } }, { "id": "host_1", "label": "主机_1", "type": "host", "position": { "x": 100, "y": 350 } }, { "id": "ap_1", "label": "无线AP_1", "type": "ap", "position": { "x": 220, "y": 350 } } ], "connections": [ { "id": "conn_1", "source": "router_1", "target": "switch_1", "type": "ethernet" }, { "id": "conn_2", "source": "switch_1", "target": "host_1", "type": "ethernet" }, { "id": "conn_3", "source": "switch_1", "target": "ap_1", "type": "ethernet" } ] } - 示例前端代码调用(fetch)
async function fetchTopology(description) { const response = await fetch('http://localhost:5001/api/ai/generate-topology', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ description }) }); const data = await response.json(); return data; }js - 用 Postman/cURL 测试 ` curl -X POST http://localhost:5001/api/ai/generate-topology
-H "Content-Type: application/json"
-d '{"description": "一个防火墙连接一个路由器,路由器连接三个主机"}'
10、项目目录
- /opt/deepseek-app-2.1
- ├── backend/ # Flask后端服务
- ├── frontend/ # React前端应用
- ├── scripts/ # 系统脚本
- ├── logs/ # 日志目录
- └── docs/ # 文档
11、详细目录
- /opt/deepseek-app-2.1
- ├── backend/
- │ ├── static/ # 静态文件
- │ │ └── favicon.ico # 网站图标
- │ ├── app.py # 主应用(试卷生成/判卷/路由)
- │ ├── requirements.txt # Python依赖
- │ ├── .env # 环境变量配置
- │ ├── ai_router.py # AI对话和拓扑图API
- │ └── topology_generator.py # 拓扑图生成逻辑
- ├── frontend/
- │ ├── public/ # 公共资源
- │ │ ├── index.html # HTML入口
- │ │ └── favicon.ico # 图标
- │ ├── src/
- │ │ ├── App.js # 主应用组件
- │ │ ├── App.css # 全局样式
- │ │ ├── index.js # React入口
- │ │ ├── pages/ # 页面组件
- │ │ │ ├── AIChatPage.js # AI聊天页
- │ │ │ └── TopologyEditorPage.js # 拓扑图编辑页
- │ │ ├── styles/ # 页面样式
- │ │ │ ├── AIChatPage.css # AI聊天样式
- │ │ │ └── TopologyEditorPage.css # 拓扑图样式
- │ │ ├── components/ # 可复用组件
- │ │ │ ├── ExamPanel.js # 考试面板
- │ │ │ ├── ExamPanel.css # 考试面板样式
- │ │ │ ├── TopologyEditor.js # 拓扑编辑器
- │ │ │ ├── TopologyEditor.css # 拓扑编辑器样式
- │ │ │ └── GoJSTopology.js # GoJS拓扑组件
- │ │ │ └── GoJSTopology.css # GoJS拓扑组件样式
- │ │ └── utils/
- │ │ └── topologyElements.js # 拓扑元素配置
- │ ├── package.json # 前端依赖
- │ ├── .env # 开发环境变量
- │ └── .env.production # 生产环境变量
- ├── scripts/
- │ ├── start.sh # 启动脚本
- │ ├── stop.sh # 停止脚本
- │ └── init_db.sql # 数据库初始化脚本
- ├── logs/ # 日志文件
- └── docs/
- └── README.md # 项目文档
12、核心文件
- 后端核心:
- o backend/app.py: 处理所有API请求(试卷生成、判卷)
- o scripts/init_db.sql: 数据库结构和初始数据
- o app.py:主逻辑(试卷生成/判卷/路由)
- o ai_router.py:AI对话和拓扑图API
- o topology_generator.py:拓扑图生成逻辑
- o init_db.sql:数据库初始化
- 前端核心:
- o frontend/src/components/ExamPanel.js: 考试界面组件
- o frontend/src/App.js: 应用主入口
- o AIChatPage.js:AI聊天界面
- o TopologyEditorPage.js:拓扑图编辑器
- o GoJSTopology.js:GoJS拓扑渲染组件
- 系统脚本:
- o scripts/start.sh: 启动所有服务
- o scripts/stop.sh: 停止所有服务
13、项目架构
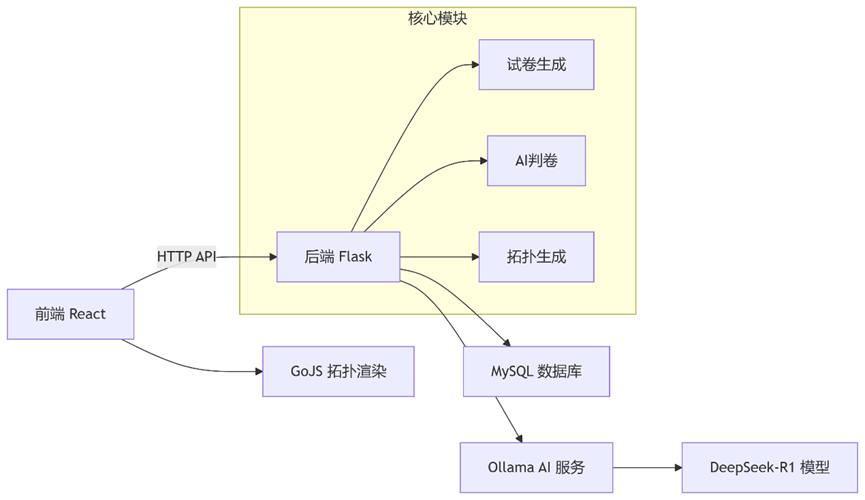
14、架构说明
- 前端层: React + GoJS + TailwindCSS
- API层: Flask处理业务逻辑和路由
- 数据层: MySQL存储题目和答案
- AI层: OLLAMA服务提供DeepSeek模型
- 脚本层: Shell脚本管理服务生命周期
15、关键功能流程
- 试卷生成流程:
- (1) 用户选择学科
- (2) 前端调用/api/generate_exam
- (3) 后端按题型比例随机选题
- (4) 返回试卷结构
- 2、 智能判卷流程:
- (1) 用户提交答案
- (2) 前端调用/api/judge_exam
- (3)后端处理每道题:
- o 客观题: 直接比对答案
- o 主观题: 调用DeepSeek模型评分
- (4)计算总分并返回结果
- 3、 主观题评分流程:
- (1) 构造包含题目、答案、评分点的提示词
- (2) 调用DeepSeek模型获取评分
- (3) 解析模型返回的评分结果
- (4) 按比例计算实际得分
16、用户发起请求:选择学科 → 生成试卷
- 路径:用户浏览器 → 前端组件 → 后端API → 数据库 → 返回试卷
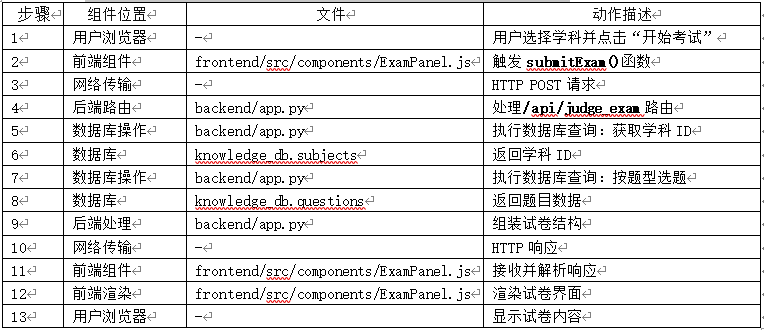
17、用户提交答案 → 判卷流程
- 路径:用户浏览器 → 前端组件 → 后端API → 数据库/AI模型 → 返回判卷结果

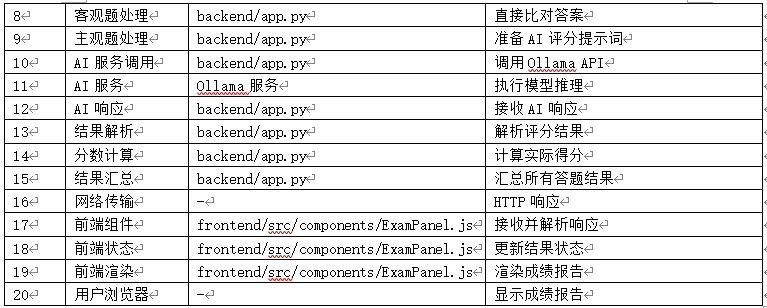
18、流程图
- 1、自动组卷判卷
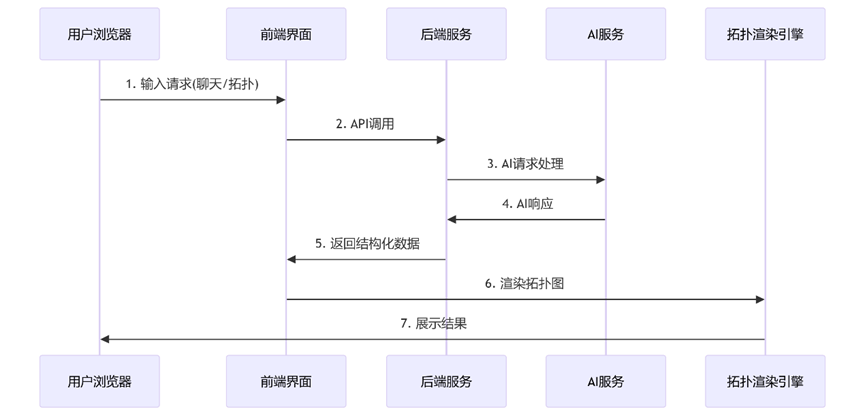
- 2、AI对话生成拓扑图
19、详细数据流(精确到文件级)
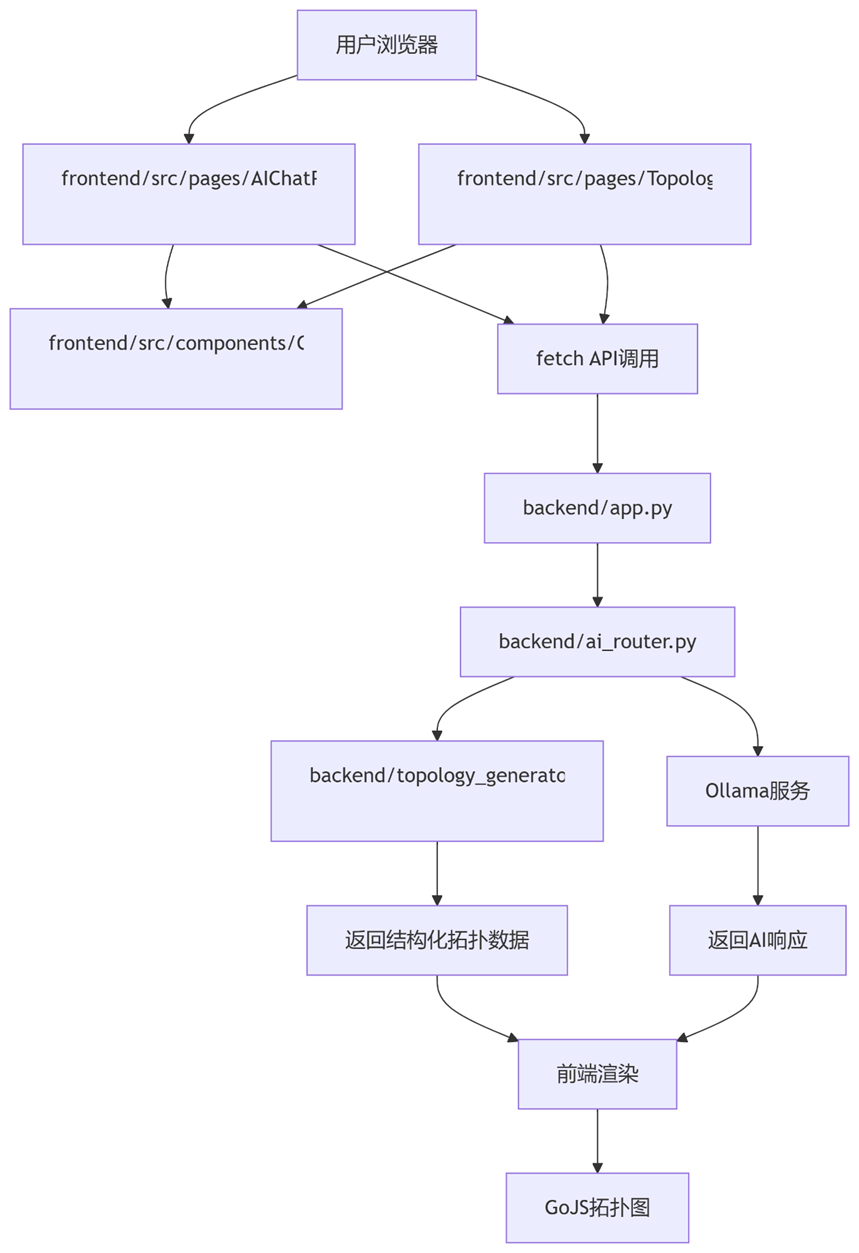
- 阶段1:用户发起请求 (浏览器 → 前端)
- 用户操作:
- o 在聊天界面(frontend/src/pages/AIChatPage.js)输入消息
- o 或在拓扑界面(frontend/src/pages/TopologyEditorPage.js)输入描述
- 前端处理:
- o AIChatPage.js 中 handleSendMessage() 处理聊天请求
- o TopologyEditorPage.js 中 handleGenerate() 处理拓扑请求
- o 构建请求体,包含用户输入和历史上下文
- 阶段2:前端调用API (前端 → 后端)
- API调用:
- // AIChatPage.js
- fetch(
${API_BASE}/api/ai/chat, { - method: 'POST',
- body: JSON.stringify({ message: input, history })
- });
- // TopologyEditorPage.js
- fetch(
${API_BASE}/api/ai/generate-topology, { - method: 'POST',
- body: JSON.stringify({ description })
- });
- 阶段3:后端处理请求 (后端 → AI服务)
- 路由分发:
- o 请求到达 backend/app.py 主应用
- o 路由到 backend/ai_router.py (蓝图注册的路由)
- AI处理:
- o 聊天请求(/api/ai/chat):
-
ai_router.py
- response = ollama.generate(model='deepseek-r1:1.5b', prompt=full_prompt)
- o 拓扑请求(/api/ai/generate-topology):
-
ai_router.py
- topology_data = generate_topology(description) # 调用topology_generator.py
-
- 拓扑生成 (backend/topology_generator.py):
- o 构造AI提示词:要求返回JSON格式的拓扑数据
- o 解析AI响应,提取设备和连接关系
- o 返回结构化拓扑数据:
- {
- "devices": [
- {"id": "r1", "type": "router", "label": "核心路由器", "position": {"x": 100, "y": 100}},
- {"id": "s1", "type": "switch", "label": "接入交换机", "position": {"x": 300, "y": 200}}
- ],
- "connections": [
- {"source": "r1", "target": "s1", "type": "ethernet"}
- ]
- }
- 阶段4:响应返回 (后端 → 前端)
- 数据返回:
- o 聊天响应:
- {
- "response": "网络拓扑建议...",
- "topology_data": {...} // 当检测到拓扑关键词时
- }
- o 拓扑响应:直接返回拓扑数据结构
- 阶段5:前端渲染 (前端 → GoJS)
- 数据处理:
- o TopologyEditorPage.js 接收拓扑数据,更新状态:
- setTopologyData(result);
- GoJS渲染 (frontend/src/components/GoJSTopology.js):
- o 在 useEffect 钩子中处理拓扑数据变化:
- useEffect(() => {
- if (topologyData) {
- // 转换数据为GoJS模型
- model.nodeDataArray = topologyData.devices.map(...);
- model.linkDataArray = topologyData.connections.map(...);
- diagram.model = model;
- }
- }, [topologyData]);
- o 使用GoJS API渲染交互式拓扑图
- 阶段6:用户交互 (GoJS → 浏览器)
- 最终展示:
- GoJS中渲染SVG图形
- o 支持用户拖拽设备、查看连接关系
- o 可通过导出按钮保存为PNG/JSON
20、关键文件交互图
21、项目效果图
- 1、前端头部

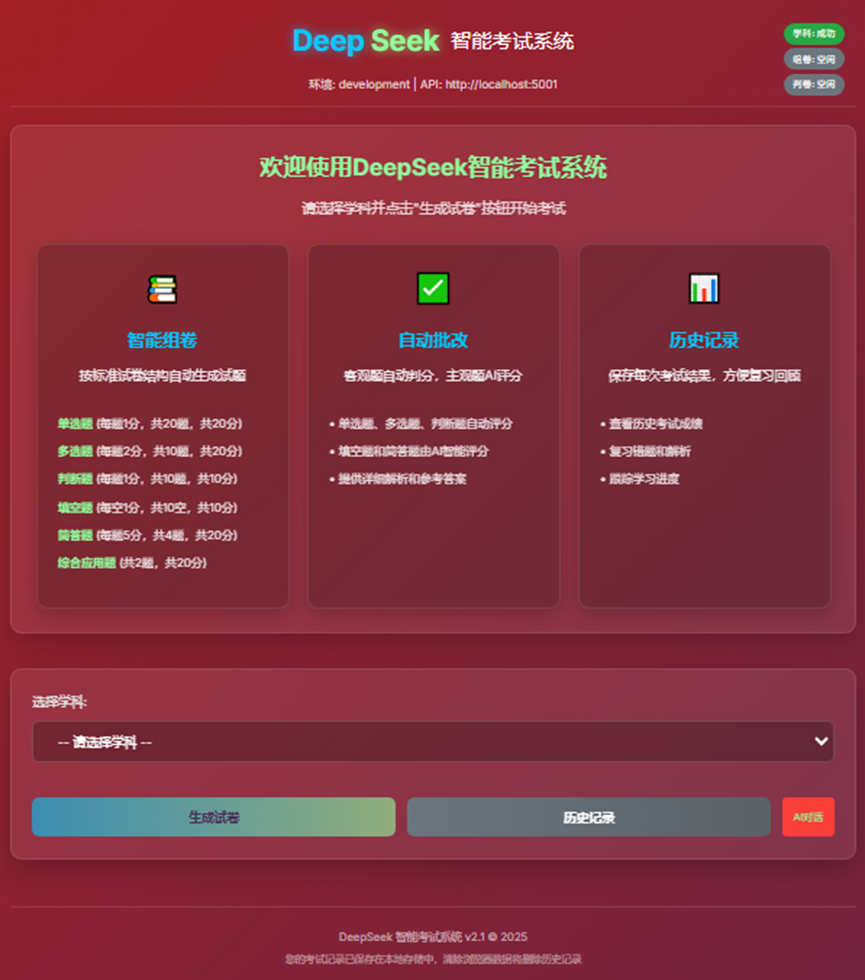
- 2、前端欢迎

- 3、前端尾部
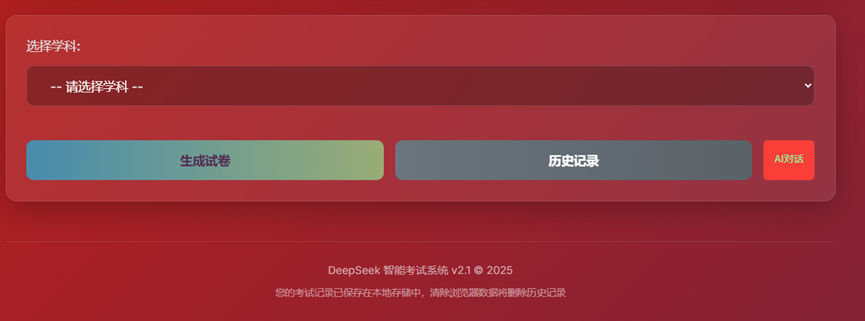
- 4、前端全貌
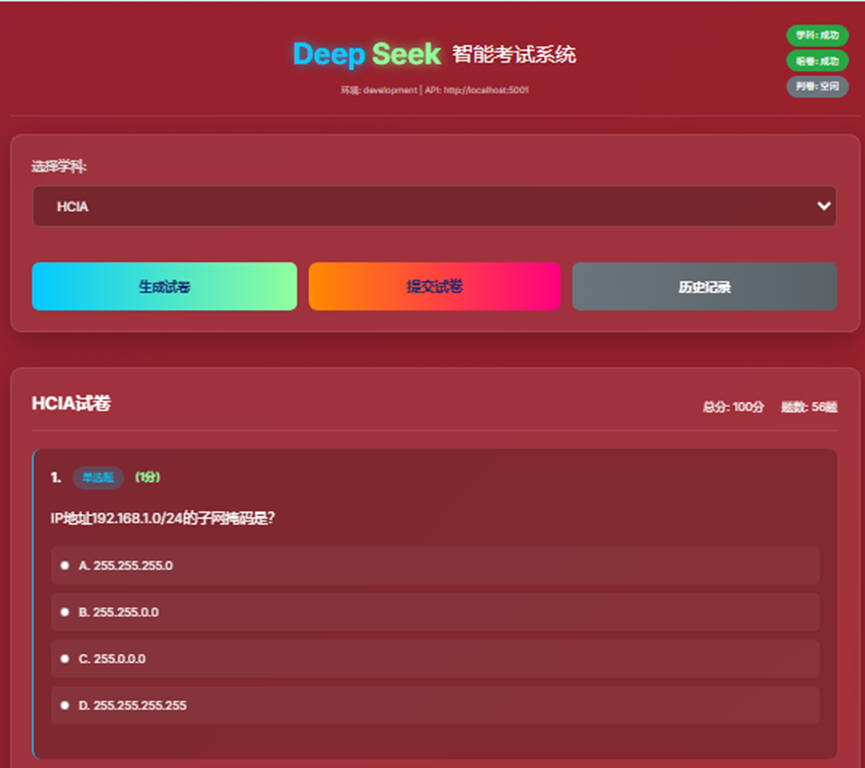
- 5、试卷界面
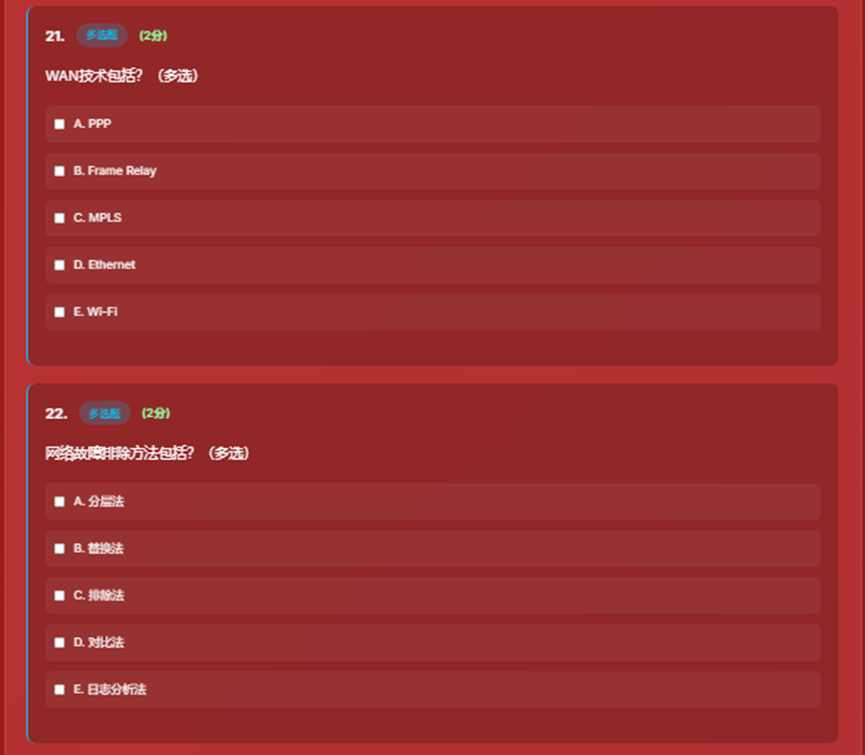
- 6、多选题界面
- 7、判断题界面
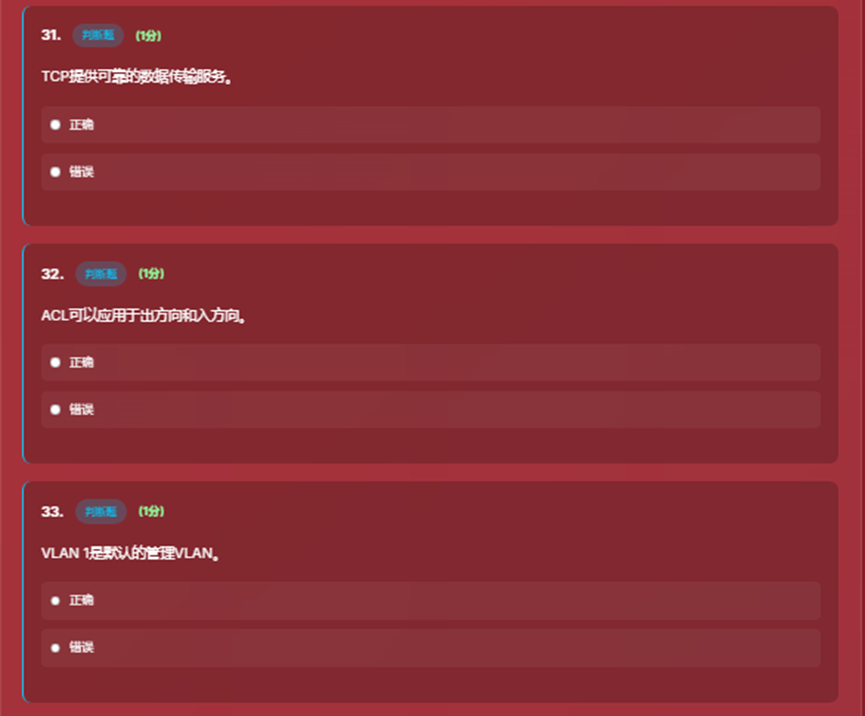
- 8、填空题和简答题界面、

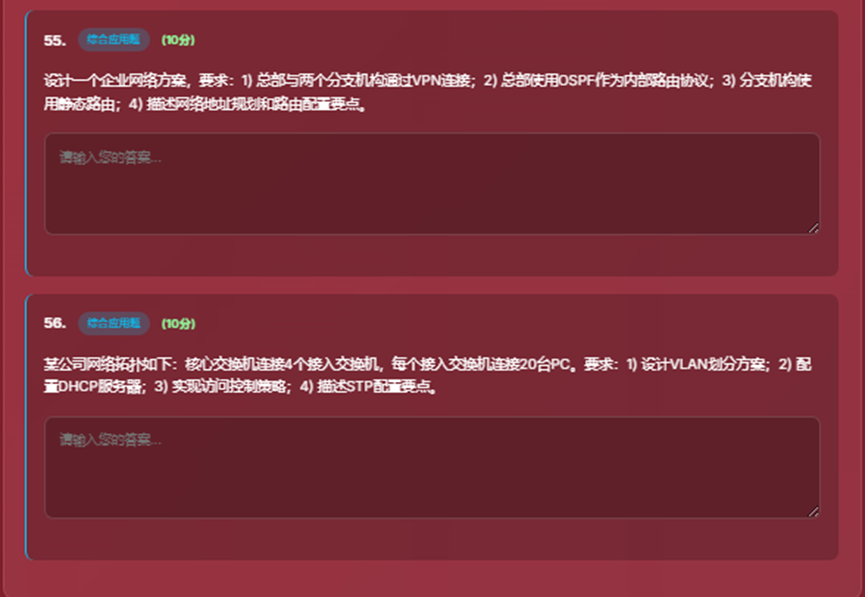
- 9、综合应用题界面
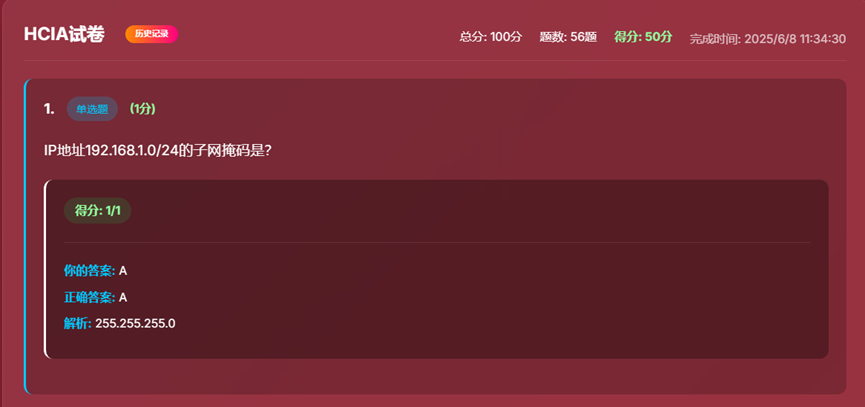
- 10、得分界面
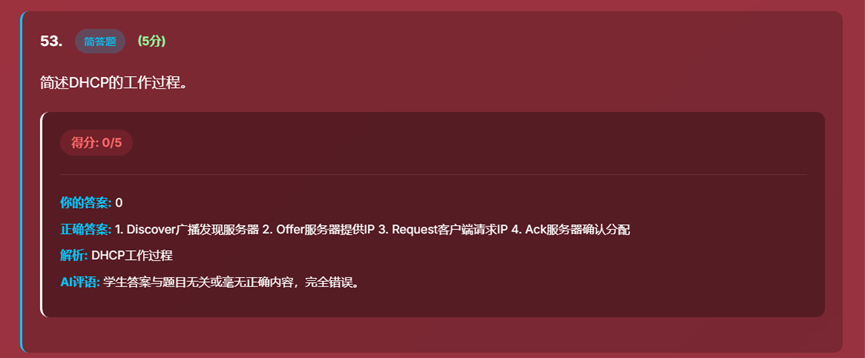
- 11、历史考试记录界面
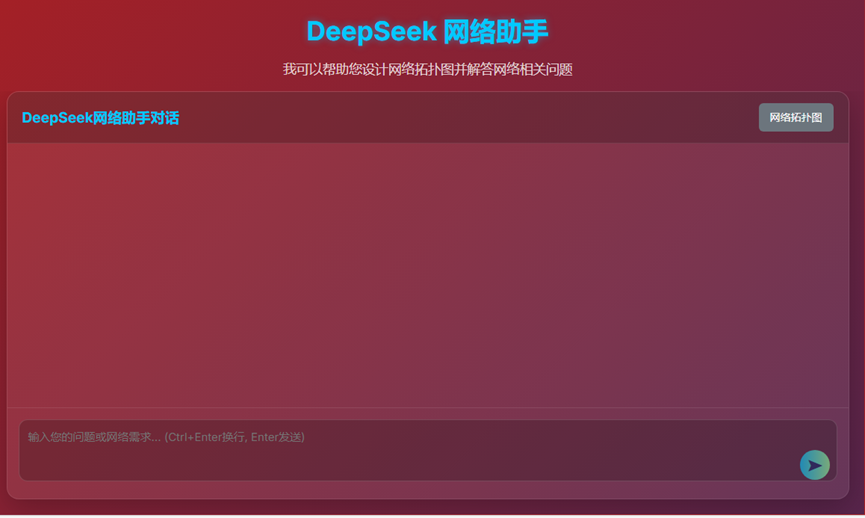
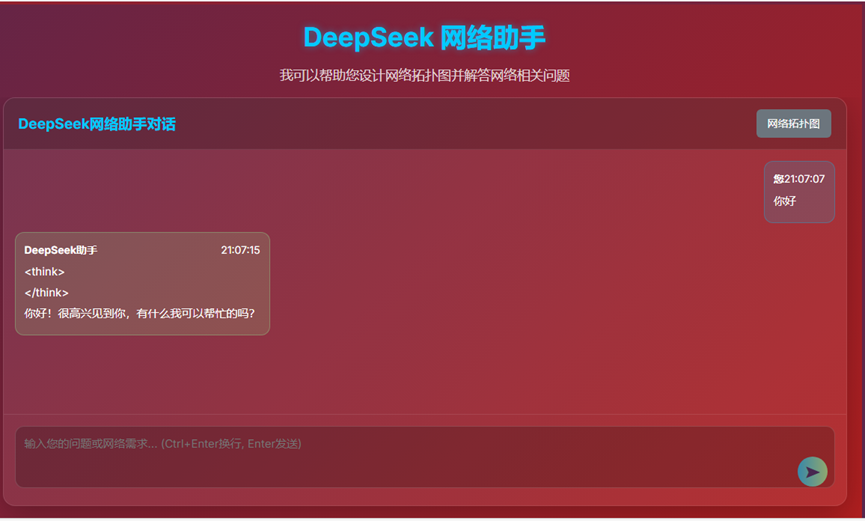
- 12、AI对话页面
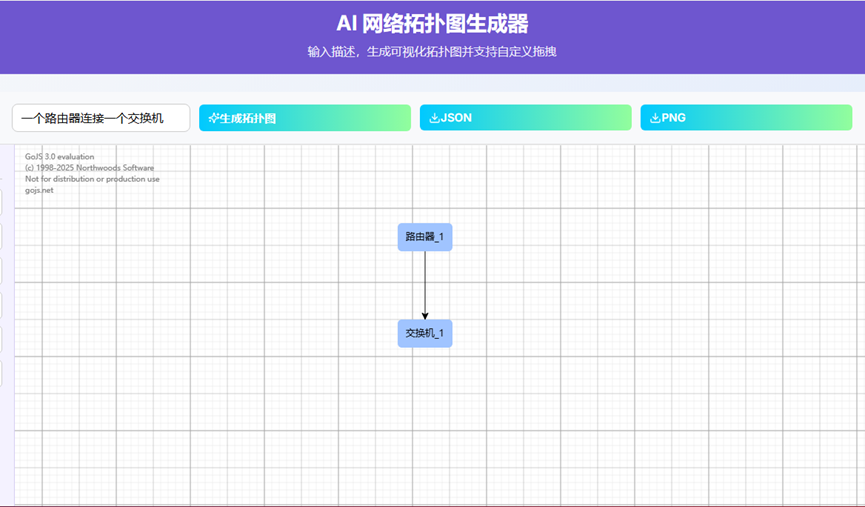
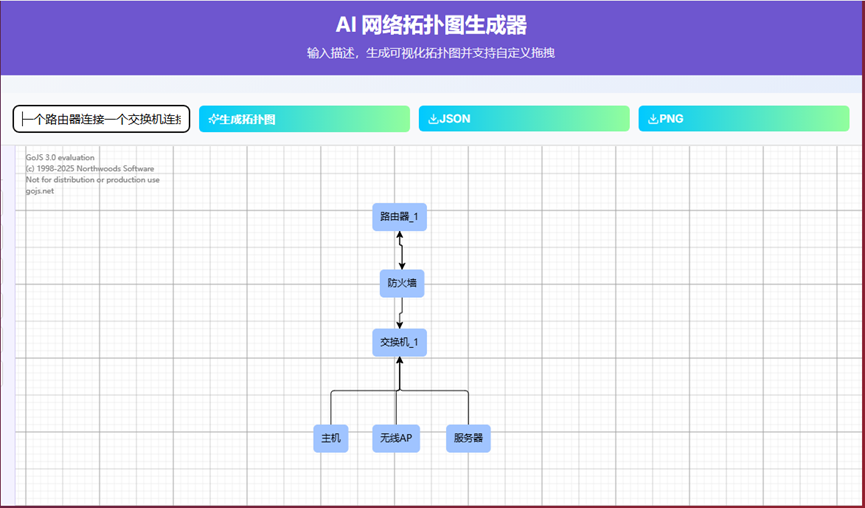
- 13、AI绘制拓扑图界面


- 左侧边栏:
- (1)当鼠标变成小手形状,可以拖动边栏网络设备到右侧网格中
- (2)点击网络设备或连接线,按dalete键删除
)

)












)



