目录
前言:
1、二叉搜索树的概念
2、二叉搜索树性能分析
3、二叉搜索树的实现
BinarySelectTree.h
test.cpp
4、key 和 key / value( map 和 set 的铺垫 )
前言:
又回到数据结构了,这次我们将要学习一些复杂的数据结构,例如 map,set,multimap,multiset 和红黑树,AVL树等,而这些复杂数据结构的基础都是二叉搜索树,避免大家没有听过这个玩意,今天咱们来单独讲一讲二叉搜索树。



1、二叉搜索树的概念
二叉搜索树又称二叉排序树(因为二叉搜索树中序遍历的结果是从小到大排序的),它或者是一棵空树,或者是具有以下性质的二叉树:
• 若它的左子树不为空,则左子树上所有结点的值都小于等于根结点的值
• 若它的右子树不为空,则右子树上所有结点的值都大于等于根结点的值
• 它的左右子树也分别为二叉搜索树
• 二叉搜索树中可以支持插入相等的值,也可以不支持插入相等的值,具体看使用场景定义,后续我们学习map/set/multimap/multiset系列容器底层就是二叉搜索树,其中map/set不支持插入相等 值(所以在需要去重的算法题中 set 和 map 是很好用的),multimap/multiset支持插入相等值。
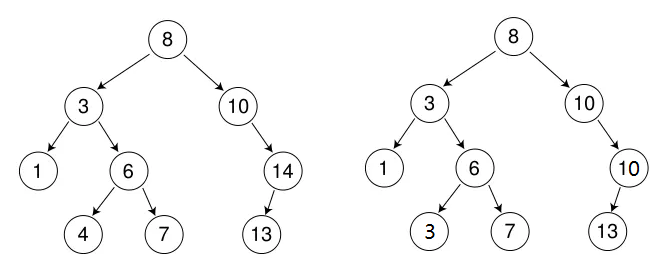
下面我实现的二叉搜索树就是以左边的树作为例子进行增删查操作的。
2、二叉搜索树性能分析
由于二叉搜索树每一层只会选择左节点和右节点中的一个比较大小,所以正常情况下性能为其高度。
最优情况下:二叉树是一棵完全二叉树,那么此时,每次搜索都能排除一半情况,此时高度为logN,所以搜索时间复杂度为O(logN)。
最坏情况下:二叉树的所有结点都放在一条分叉上,此时高度最高,为N,此时时间复杂度为O(N)。
所以综合而言,二叉搜索树增删查的时间复杂度为O(N),二叉搜索树一般不支持改,因为一改二叉搜素树就混乱了。
由于当出现一个分叉的情况时,时间复杂度有点高,所以就出现了平衡二叉树这一做法,这个比较复杂,后面AVL树和红黑树会讲。
其实二分查找时间复杂度也是O(logN),但是缺陷也很大:
1、首先下标要满足随机访问,而且必须有序。
2、其次插入和删除效率太低了,删除或插入一个数据需要挪动一堆数据。
到这里二叉搜索树的基础知识就结束了,下面我们来实现一下这个简单的数据结构吧。
3、二叉搜索树的实现
我们分两个文件来写,代码中给出了注释:
BinarySelectTree.h
#define _CRT_SECURE_NO_WARNINGS 1#include <iostream>
#include <algorithm>
using namespace std;template <class K>
class BSTreeNode
{
public:K _key;BSTreeNode<K>* _left;BSTreeNode<K>* _right;BSTreeNode(const K& key):_key(key), _left(nullptr), _right(nullptr){ }
};template <class K>
class BSTree
{
public:typedef BSTreeNode<K> Node;BSTree() = default;//由于我们已经有了拷贝构造,所以不写构造函数就会报错(因为缺少默认构造),//而这个类没必要写构造,这个句子就是告诉编译器构造函数交给你默认生成了~BSTree()//析构函数,利用后序遍历析构,从叶子节点开始析构,运用递归{Destroy(_root);_root = nullptr;}void Destroy(Node* root)//这里我们把Destroy单独封装,因为要写递归{if (root == nullptr){return;}Destroy(root->_left);Destroy(root->_right);delete root;}BSTree(const BSTree<K>& bst)//拷贝构造{_root = Copy(bst._root);}Node* Copy(Node* root)//这里要从根节点开始复制,运用的是先序遍历{if (root == nullptr){return nullptr;}Node* newRoot = new Node(root->_key);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot;}bool Insert(K key){if (_root == nullptr)//如果树为空,则直接插入{_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur)//直到cur为空为止{if (cur->_key > key)//结点值大于插入值,则往左孩子方向走{parent = cur;cur = cur->_left;}else if (cur-> _key < key)//结点值小于插入值,则往右孩子方向走{parent = cur;cur = cur->_right;}else//结点值等于插入值,我们这里不支持插入相等值{return false;}}if (key < parent->_key)//cur到空后你并不知道插入值比父节点大还是小,判断后再插入{parent->_left = new Node(key);}if (key > parent->_key){parent->_right = new Node(key);}return true;}void InOrder(){_InOrder(_root);cout << endl;}void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->_left);cout << root->_key << ' ';_InOrder(root->_right);}bool Find(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if (cur->_key < key){parent = cur;cur = cur->_right;}else{return true;}}return false;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if (cur->_key < key){parent = cur;cur = cur->_right;}else{//开始删除if (cur->_right == nullptr)//只有左子树{if (cur == _root)//如果要删除的为根节点,如果不写,下面的parent就会使空,//空的引用会报错{_root = cur->_left;}else{if (parent->_left == cur)//如果父节点的左孩子为要删除的节点{parent->_left = cur->_left;//cur只有左子树,把左子树放在父节点的左子树上}if (parent->_right == cur)//如果父节点的右孩子为要删除的节点{parent->_right = cur->_left;//把cur左子树放到父节点的右子树上}}delete cur;}else if (cur->_left == nullptr)//只有右子树{if (_root == cur){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}if (parent->_right == cur){parent->_right = cur->_right;}}delete cur;}else//左右子树都有,将要删除的节点与中序遍历的前驱节点(中序遍历前一个结点)//或后继节点(中序遍历的后一个节点)交换//中序遍历的前驱节点即待删除节点的左子树的最大节点,也就是左子树最右节点//中序遍历的后继节点即待删除节点的右子树的最小节点,也就是右子树最左节点{Node* replace = cur->_right;Node* replaceParent = cur;while (replace->_left)//寻找右子树的最左节点{replaceParent = replace;replace = replace->_left;}swap(replace->_key, cur->_key);if (replaceParent->_left == replace)//有两种情况(通过replaceParent和replace有没有移动来判断):有可能找到了最左节点replaceParent->_left = replace->_left;else//还有可能replace就没有左节点,此时它为右子树最小节点replaceParent->_right = replace->_right;delete replace;}return true;}}return false;}
private :Node* _root = nullptr;
};void test()
{int arr[] = { 8, 3, 1, 10, 1, 6, 4, 7, 14, 13 };BSTree<int> t;for (auto e : arr){t.Insert(e);}t.InOrder();//cout << t.Find(3) << endl;//cout << t.Find(5) << endl;////左右都不为空//t.Erase(8);//t.InOrder();//t.Erase(3);//t.InOrder();////右为空//t.Erase(14);//t.InOrder();////左为空//t.Erase(6);//t.InOrder();//for (auto e : arr)//{// t.Erase(e);// t.InOrder();//}BSTree<int> t1(t);t1.InOrder();
}test.cpp
#define _CRT_SECURE_NO_WARNINGS 1#include "BinarySelectTree.h"int main()
{test();return 0;
}4、key 和 key / value( map 和 set 的铺垫 )
在二叉搜索树中,我们都是以 key 作为树排序的依据的,比如整型的插入,结点里存储的整型就是它的键值,也就是我们这里所说的 key ,key 是二叉搜索树排序的依据。
key的应用场景,比如我们小区的门卫系统,如果车主住在小区,那么业主的汽车的信息就会存入门卫系统,每次只需要按照 key 来查找就可以了(当然小区系统存储肯定用的是数据库,但也可以是二叉搜索树的应用,只不过存储空间小,这样存储的数据都存到内存里了,容易弄丢)。
接着就是键值对 key / value,这个就是 map 的关键,上面说过,multimap 是支持等值存储的,在 multimap 中,key 和 value 是绑定存储的,比如我们在 multimap 中存储了 3 这个整型,那么键值 key 就是 3 ,如果他只出现了一次,那么 value 就是 1 ,每多存储一个 key ,value 就++,当然,这只是 multimap 的一个应用,value同样可以存储字符串等,这里只是告诉大家两者是绑定的。
但是有一点大家要知道,不管是 map 和 set ,都只看key,而不去看value。
OK,到这里我们的二叉搜索树就结束了,接下来我们将要面对的是高阶数据结构,让我们一起加油吧。












 推荐使用 constexpr和模板 (Templates) 作为宏 (#define) 的替代品?)





)

