Redis的慢查询
许多存储系统(例如 MySQL)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来,Redis也提供了类似的功能。
Redis客户端执行一条命令分为如下4个部分:
- 发送命令
- 命令排队
- 执行命令
- 返回结果
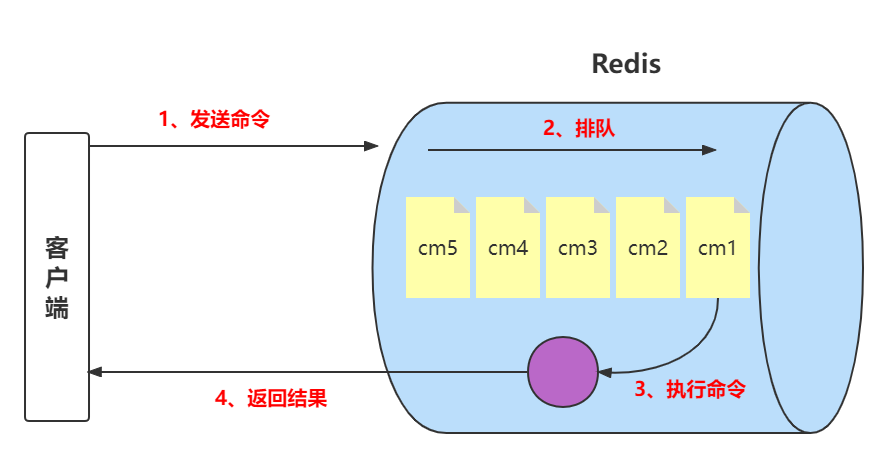
需要注意,慢查询只统计步骤3的时间,所以没有慢查询并不代表客户端没有超时问题。因为有可能是命令的网络问题或者是命令在Redis在排队,所以不是说命令执行很慢就说是慢查询,而有可能是网络的问题或者是Redis服务非常繁忙(队列等待长)。
慢查询配置
1、动态设置
慢查询的阈值默认值是10毫秒。
参数:slowlog-log-slower-than就是时间预设阀值,它的单位是微秒(1秒=1000毫秒=1 000 000微秒),默认值是10 000,假如执行了一条“很慢”的命令(例如keys *),如果它的执行时间超过了10 000微秒,也就是10毫秒,那么它将被记录在慢查询日志中。
查看slowlog-log-slower-than
config get slowlog-log-slower-than
更新slowlog-log-slower-than
config set slowlog-log-slower-than 20000
使用config set完后,若想将配置持久化保存到Redis.conf,要执行config rewrite
config rewrite
查看慢查询
#设置慢查询时间阈值为10微秒config set slowlog-log-slower-than 10#查看所有的keykeys *#查看慢查询个数slowlog len#展示慢查询信息(查询2个慢查询)slowlog get 2

慢查询日志重置
slowlog reset
Pipeline
前面慢查询的时候提到过时间消耗,其中1(发送命令)和4(返回结果)花费的时间称为Round Trip Time (RTT,往返时间),也就是数据在网络上传输的时间。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。
但大部分命令是不支持批量操作的,例如要执行n次 hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
#设置一个hash对象json
hset json a 1 b 2#获取json的属性a
hget json a
#湖区json的属性b
hget json b#一次性获取json对象
hgetall json
举例:Redis的客户端和服务端可能部署在不同的机器上。例如客户端在本地(上海),Redis服务器在阿里云的北京,两地直线距离约为1200公里,那么1次RTT时间=1200 x2/ ( 300000×2/3 ) =12毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微妙=1毫秒)级别,所以才会有Redis 性能瓶颈是网络这样的说法。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端,没有使用Pipeline执行了n条命令,整个过程需要n次RTT。
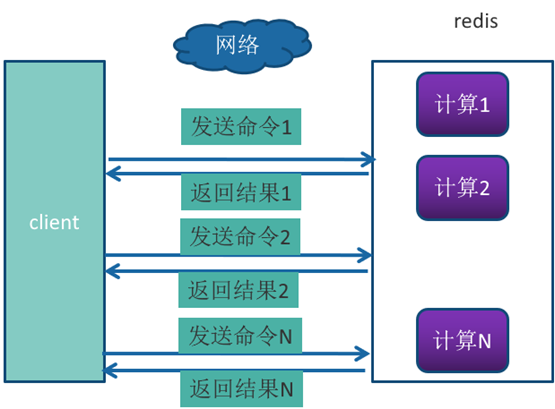
使用Pipeline 执行了n次命令,整个过程需要1次RTT。
public void plSet(List<String> keys,List<String> values) {Jedis jedis = null;try {jedis = jedisPool.getResource();Pipeline pipelined = jedis.pipelined();for(int i=0;i<keys.size();i++){pipelined.set(keys.get(i),values.get(i));}pipelined.sync();} catch (Exception e) {throw new RuntimeException("执行Pipeline设值失败!",e);} finally {jedis.close();}}/**逐个set和利用pipeline的处理时间对比*/public void testPipeline() {long setStart = System.currentTimeMillis();for (int i = 0; i < TEST_COUNT; i++) { //单个的操作redisString.set("testStringM:key_" + i, String.valueOf(i));}long setEnd = System.currentTimeMillis();System.out.println("非pipeline操作"+TEST_COUNT+"次字符串数据类型set写入,耗时:" + (setEnd - setStart) + "毫秒");List<String> keys = new ArrayList<>(TEST_COUNT);List<String> values= new ArrayList<>(TEST_COUNT);for (int i = 0; i < keys.size(); i++) {keys.add("testpipelineM:key_"+i);values.add(String.valueOf(i));}long pipelineStart = System.currentTimeMillis();redisPipeline.plSet(keys,values);long pipelineEnd = System.currentTimeMillis();System.out.println("pipeline操作"+TEST_COUNT+"次字符串数据类型set写入,耗时:" + (pipelineEnd - pipelineStart) + "毫秒");}
非pipeline操作10000次字符串数据类型set写入,耗时:4934毫秒
pipeline操作10000次字符串数据类型set写入,耗时:7毫秒
事务
Redis提供了简单的事务功能,将一组需要一起执行的命令放到multi和exec两个命令之间。multi 命令代表事务开始,exec命令代表事务结束。另外discard命令是回滚。
multi
sadd sa 1
sadd sb 2
exec
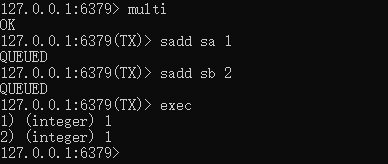
当没有执行exec的时候,开启另外一个redis-cli,利用SISMEMBER确认关键字是否存在
sismember sa 1
(integer) 0
当执行完exec的时候,开启另外一个redis-cli,利用SISMEMBER确认关键字是否存在
sismember sa 1
(integer) 1
Redis的事务原理
事务是Redis实现在服务器端的行为,用户执行MULTI命令时,服务器会将对应这个用户的客户端对象设置一个特殊的状态,在这个状态下后续用户执行的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行EXEC命令为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次执行。
Redis的watch命令
有些应用场景需要在事务之前,确保事务中的key没有被其他客户端修改过,才执行事务,否则不执行(类似乐观锁)。Redis 提供了watch命令来解决这类问题。
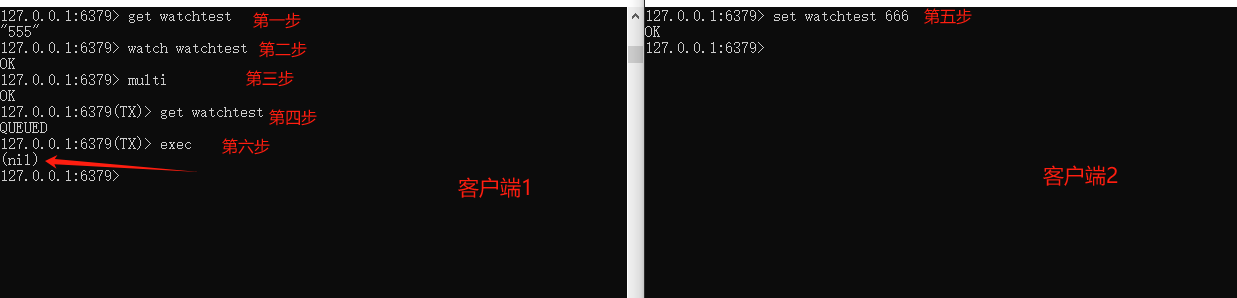
可以看到“客户端-1”在执行multi之前执行了watch命令,“客户端-2”在“客户端-1”执行exec之前修改了key值,造成客户端-1事务没有执行(exec结果为nil)。
Redis客户端中的事务使用代码:
public final static String RS_TRANS_NS = "rts:";@Autowiredprivate JedisPool jedisPool;public List<Object> transaction(String... watchKeys){Jedis jedis = null;try {jedis = jedisPool.getResource();if(watchKeys.length>0){/*使用watch功能*/String watchResult = jedis.watch(watchKeys);if(!"OK".equals(watchResult)) {throw new RuntimeException("执行watch失败:"+watchResult);}}Transaction multi = jedis.multi();multi.set(RS_TRANS_NS+"test1","a1");multi.set(RS_TRANS_NS+"test2","a2");multi.set(RS_TRANS_NS+"test3","a3");List<Object> execResult = multi.exec();if(execResult==null){throw new RuntimeException("事务无法执行,监视的key被修改:"+watchKeys);}System.out.println(execResult);return execResult;} catch (Exception e) {throw new RuntimeException("执行Redis事务失败!",e);} finally {if(watchKeys.length>0){jedis.unwatch();/*前面如果watch了,这里就要unwatch*/}jedis.close();}}
Pipeline和事务的区别
PipeLine看起来和事务很类似,感觉都是一批批处理,但两者还是有很大的区别。简单来说。
1、pipeline是客户端的行为,对于服务器来说是透明的,可以认为服务器无法区分客户端发送来的查询命令是以普通命令的形式还是以pipeline的形式发送到服务器的;
2、而事务则是实现在服务器端的行为,用户执行MULTI命令时,服务器会将对应这个用户的客户端对象设置为一个特殊的状态,在这个状态下后续用户执行的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行EXEC命令为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次执行。
3、应用pipeline可以提服务器的吞吐能力,并提高Redis处理查询请求的能力。
但是这里存在一个问题,当通过pipeline提交的查询命令数据较少,可以被内核缓冲区所容纳时,Redis可以保证这些命令执行的原子性。然而一旦数据量过大,超过了内核缓冲区的接收大小,那么命令的执行将会被打断,原子性也就无法得到保证。因此pipeline只是一种提升服务器吞吐能力的机制,如果想要命令以事务的方式原子性的被执行,还是需要事务机制,或者使用更高级的脚本功能以及模块功能。
4、可以将事务和pipeline结合起来使用,减少事务的命令在网络上的传输时间,将多次网络IO缩减为一次网络IO。
Redis提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算,当然也体现了Redis 的“keep it simple”的特性,下一节将介绍的Lua脚本同样可以实现事务的相关功能,但是功能要强大很多。





)










)


优化算法简介)