第一个C++程序
#include<iostream>
using namespace std;
int main()
{cout << "hello world !" << endl;return 0;
}
上边的代码就是用来打印字符串 “hello world !” 的,可见,与C语言还是有很大的差别的,接下来我们就直接进入C++的世界!
命名空间namespace
在我们日常写代码的过程当中,可能会在同一个域中出现变量名,函数名等等的定义重名的情况,如果还是坚持不同变量用相同的名字的话,编译器就会报错,这个时候,我们就需要用到namespace关键字
定义命名空间
我们首先来看下边的一张图片。
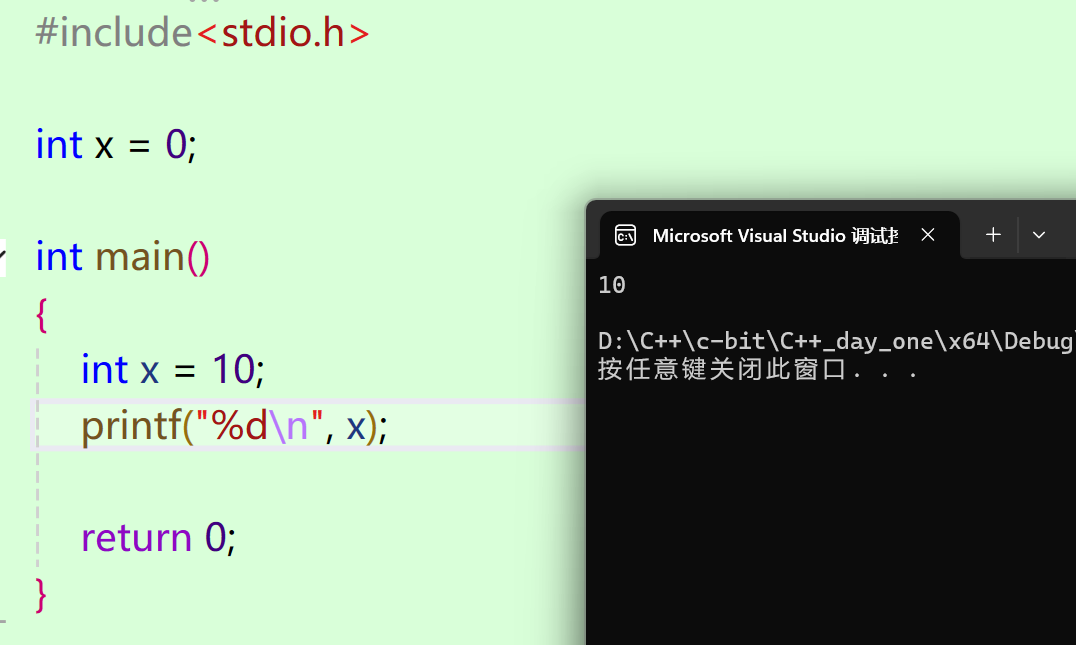
上边是用C语言写的代码,其中就定义了两个重名的x,但是为什么这里代码没有报错,并且打印的是10呢?
原因是这里的x一个是属于全局域,一个是属于局部域,而在默认的情况下(也就是没有指定域的情况下),编译器会默认先局部去找,然后再全局去找,因此这里就打印的是10。
那如果两个x都在全局的位置呢?
其实除了全局域,局部域,还有很多其它的域,我们主要探讨的是用namespace定义的域,用最简单的理解方式就是用namespace可以定义一个域,然后在这个自己定义的域里边写的东西就不会与全局的发生命名重复的冲突了,因此,namespace解决的是全局的命名重复问题。不能定义在局部。
来看一下下边的例子。
#include<stdio.h>//命名空间的定义就是
//namespace 命名空间名
namespace xc
{int x = 10;
}int x = 100;//全局变量int main()
{printf("%d\n", x);//100printf("%d\n", xc::x);//10return 0;
}::表示的是域作用限定符,如果它的前边什么都不加的话,就默认访问的是全局域的,上边代码里边的第一个x打印结果是100,是因为不加任何东西的情况下,编译器就先局部找,然后再全局找,如果想要访问命名空间里边的x,就要像上边的那种写法。
这里还要额外说明一下,命名空间域不会影响变量的生命周期,因此上边命名空间域xc里的x还是属于全局变量的。
namespace的嵌套定义:
首先,不同文件里边的同名的命名空间域会认为是同一个。
但在日常的工作当中,同一个项目可能会有不同的小组去完成,而不同的小组可能会使用不同名字的命名空间域,同一个namespace的内部可能又有重名的,这时候就可以用namespace的嵌套定义。看一个例子。
#include<stdio.h>namespace xxc
{namespace xc1{int rand = 1;int Add(int left, int right){return left + right;}}namespace xc2{int rand = 2;int Add(int left, int right){return (left + right) * 10;}}
}int main()
{printf("%d\n", xxc::xc1::rand);printf("%d\n", xxc::xc2::rand);printf("%d\n", xxc::xc1::Add(1, 2));printf("%d\n", xxc::xc2::Add(1, 2));return 0;
}命名空间使用
在上边已经说了在编译查找的时候如果不指定在命名空间域里边查找,是不会去找的,只会默认先局部然后全局的方式去找。
但是想要访问命名空间中的变量或者函数不止只有指定命名空间这样一种方式。还有两种方式。
其一是可以展开命名空间中的全部成员。
其二是可以将命名空间中的某个成员展开。
请看下边的代码示例。
#include<stdio.h>namespace xxc
{int a = 0;int b = 10;
}//指定命名空间访问
int main()
{printf("%d\n", xxc::a);return 0;
}//展开命名空间中的某一个成员
using xxc::a;
int main()
{printf("%d\n", a);printf("%d\n",xxc::b);return 0;
}//using 将命名空间全部展开
using namespace xxc;
int main()
{printf("%d\n", a);printf("%d\n", b);
}C++中的输入和输出
<iostream>是 Input Output Stream的缩写,它是一个标准的输入输出流库,里边定义了标准的输入输出流对象。
这里涉及到更深的就不在本篇博客里边讲解了,大家初学的话就了解基本用法就行。
cout和cin一个是输出的意思,一个是输入的意思,其中cout配对的是流插入运算符 << 表示输出,cin配对的是流提取运算符 >>,表示输入。并且这两个输入和输出都会自动识别类型且可以输入输出任意类型。最后一个就是endl,现在初学者暂且理解它的作用为换行就行了。
#include<iostream>
using namespace std;
int main()
{int a;float b;cin >> a >> b;cout << a << " " << b << " " << endl;return 0;
}
缺省参数
缺省参数是在函数声明或者定义的时候的给函数形参的一个默认的值。缺省参数分为全缺省和半缺省。
全缺省就是给函数全部的参数给缺省值,半缺省就是从右到左依次给函数参数缺省值且不能跳跃着给缺省值。
当在调用有缺省参数的函数的时候,我们给实参是从左往后按照顺序依次给到形参的,不能间隔着给值,没有自己给值的话,函数就会用默认的缺省值。但如果那个函数是半缺省的话,那没有缺省值的参数一定要给它传值。
最后一个点就是如果有多文件的大项目的时候,缺省值是在函数声明的时候给的,函数定义的时候就不用给缺省值了(初学者先了解)
代码示例
#include<iostream>
using namespace std;//全缺省
void Func1(int a = 10, int b = 100, int c = 1000)
{cout << a << " " << b << " " << c << " " << endl;
}//半缺省
void Func2(int a, int b = 100, int c = 1000)
{cout << a << " " << b << " " << c << " " << endl;
}int main()
{//调用全缺省的函数Func1();Func1(1, 2, 3);Func1(1, 2);//调用半缺省的函数Func2(1);//没有缺省值的参数必须给值Func2(1, 2);Func2(1, 2, 3);return 0;
}
函数重载
在C++里边的同一个作用域下支持出现同名的函数,有个要求就是这些函数的形参列表是需要不同的。包括以下几点。
1.函数的形参的个数不同
2.函数的形参的类型不同
3.函数的形参的类型顺序不同
请看以下的示例
#include<iostream>
using namespace std;//声明,以下的函数重载只是举例子,就不写函数体了
//1.参数的类型不同
int Add(int a,int b)
{ }double Add(double a,double b)
{ }//2.参数的个数不同
void f()
{ }void f(int a)
{ }//3.参数的类型的顺序不同
void f(int a,char b)
{ }void f(char b, int a)
{ }int main()
{return 0;
}
当调用有重载的函数的时候,编译器会根据这些参数的不同来自动判断我们调用的是哪个函数。





)
![[Python] -进阶理解7- Python中的内存管理机制简析](http://pic.xiahunao.cn/[Python] -进阶理解7- Python中的内存管理机制简析)








)

)
` 和 `destroy()` 的区别)
![[RPA] 日期时间练习案例](http://pic.xiahunao.cn/[RPA] 日期时间练习案例)