
导读

ChatGPT 用户量指数级暴涨,OpenAI 的 Kafka 集群在一年内增长 20 倍至 30+ 个集群[1],其 Kafka 架构面临日均千亿级消息(峰值 QPS 800万/秒) 的压力。这揭示了一个关键事实:OpenAI 的成功不只依赖模型,更依托能支撑高并发迭代的数据基础设施。
基于 OpenAI 在 Confluent 技术演讲中披露的内容,本文将从 Kafka 在 OpenAI 中的使用场景出发,揭示业务暴涨后的所面临的痛点,并重点介绍 “Proxy代理层”架构(Prism + uForwarder)如何实现业务与基础设施的深度解耦、跨集群容灾无缝迁移等能力。
在此基础上,我们将探讨 Apache Pulsar 的架构潜力(存储计算分离/消息流统一)和其在高可用、低延迟场景的优势(内置重试/死信/高效GEO复制),为 AI 业务的消息流选型提供前瞻洞察。
OpenAI中Kafka的使用场景

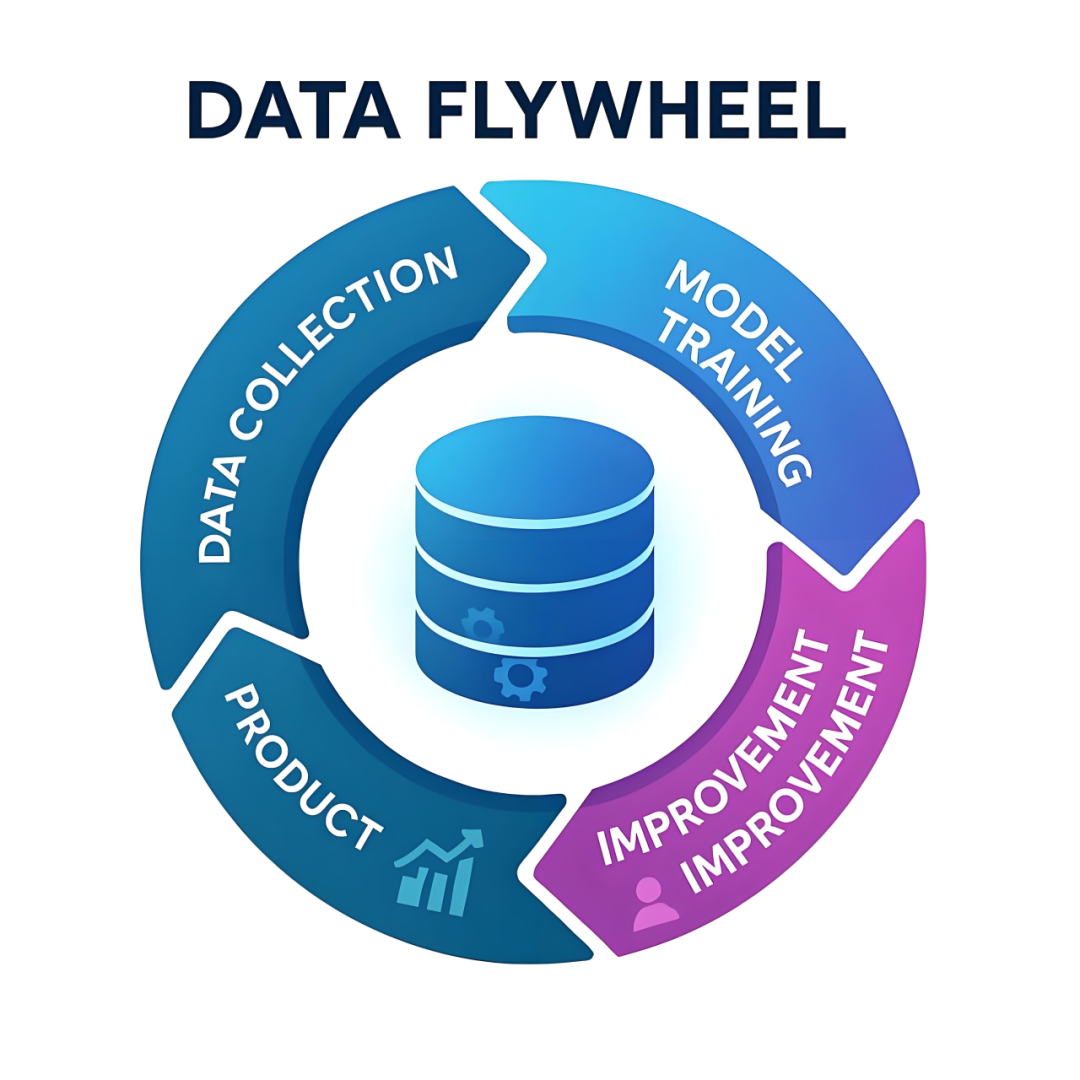
基于OpenAI在Confluent技术演讲中披露的架构实践,Kafka在OpenAI的场景中有深入的应用,例如典型的数据飞轮场景[2]如下:
OpenAI
数据收集(DATA COLLECTION):用户与ChatGPT等产品的交互行为数据(每次对话/点击)。
模型训练(MODEL TRAINING):根据实时收集的行为数据,对模型进行增量学习和训练。
模型优化(IMPROVEMENT):根据模型训练的结果,结合当前模型进行参数调优和能力增强。
模型上线(PRODUCT):新模型实时生效于用户终端,用户行为数据实时回流至采集端。
该流程与成熟的实时推荐系统高度一致:通过实时收集用户行为并反馈,持续修正推荐模型,形成正反馈循环。其中,消息中间件贯穿全流程,加速产品使用数据反馈至模型能产生实质影响。Kafka 在其中承担三重关键角色:数据管道(Data Pipeline)、流处理协同层、反馈加速器。
此外,在 AI 开发场景中,快速实验迭代是模型演进的核心驱动力[2],实现数据无缝管道化处理可建立关键基础
统一数据源:打破数据孤岛;将线上业务数据按需同步至实验沙盒环境。
快速实验:快速实现A/B Test,从数据的收集到最终的反馈一体化,加速模型优化 。通过端到端一体化流程实现A/B测试——从实时数据收集到模型效果反馈,加速模型优化。

最后是消息中间的核心场景,例如服务间异步解耦通信、削峰填谷等。
OpenAI中Kafka面临的挑战

当ChatGPT的用户量如野火般蔓延,OpenAI中Kafka集群数量快速增长,随之问题也逐渐暴露出来。

业务接入痛点

认知成本过高
开发者需正确掌握 Kafka 机制和 api 使用(如 Offset 提交策略、消费者重平衡)。
业务逻辑与基础设施知识耦合,业务人员需要关心 Kafka 的部署架构,以及 Topic 归属哪个集群、该怎么连接。
分区限制所带来的性能问题
OpenAI 大量使用 Python 语言进行业务系统开发,对于高并发消费场景,一味地增加 Topic 的分区并不能从根本上解决问题;进一步地,因为 Kafka 集群支持的分区数由于本身 IO 模型而受限,过多的分区(Kafka 磁盘顺序写退化为随机写)会导致集群性能下降和延迟增加,增加分区的动作反而会带来 Kafka 集群不稳定的风险。

集群可用性痛点

单集群运维风险
分区/节点扩缩容操作,触发分区不可用(如 ISR 收缩、Leader 选举失败),导致分钟级业务中断。
连锁反应,局部故障可能演变为集群级雪崩(如Controller切换失败)单Kafka集群在运维时有非常多的弊端,例如扩分区扩容场景,会导致分区级别不用的情况,导致业务终端,带来集群不可用的风险。
多集群拆分困境
由于 Kafka 集群分区数规模的限制,不得不拆解更多的集群来满足业务的发展,同时集群运维成本也倍数增加
将一个 Topic 从 A 集群迁移到 B 集群,又对业务系统存在侵入性,无法做到平滑迁移。
公有云环境风险叠加
OpenAI的大部份服务部署于公有云,其底层基础设施异常(如区域级故障)会直接传导至 Kafka 集群;为规避单点风险,必须采用多区域多集群部署架构。

高阶特性缺失

Kafka 作为异步解耦通道,其原生 API 未提供业务级高阶特性[4],需系统自行实现。
重试消息:消费场景中,如果业务逻辑处理失败,需要进行退避式重试。这对于业务是必须的,但在 Kafka 的 API 里不支持。
死信消息:对于重试一直失败的消息(大多数情况是异常消息)需要放入到死信 Topic 中,不能占有资源部释放。
上述挑战并非 OpenAI 独有;所有经历指数级业务扩张的企业,其 Kafka 架构必然面临系统性瓶颈。下面让我们看看 OpenAI 是如何解决这些问题的。
OpenAI的解决方案

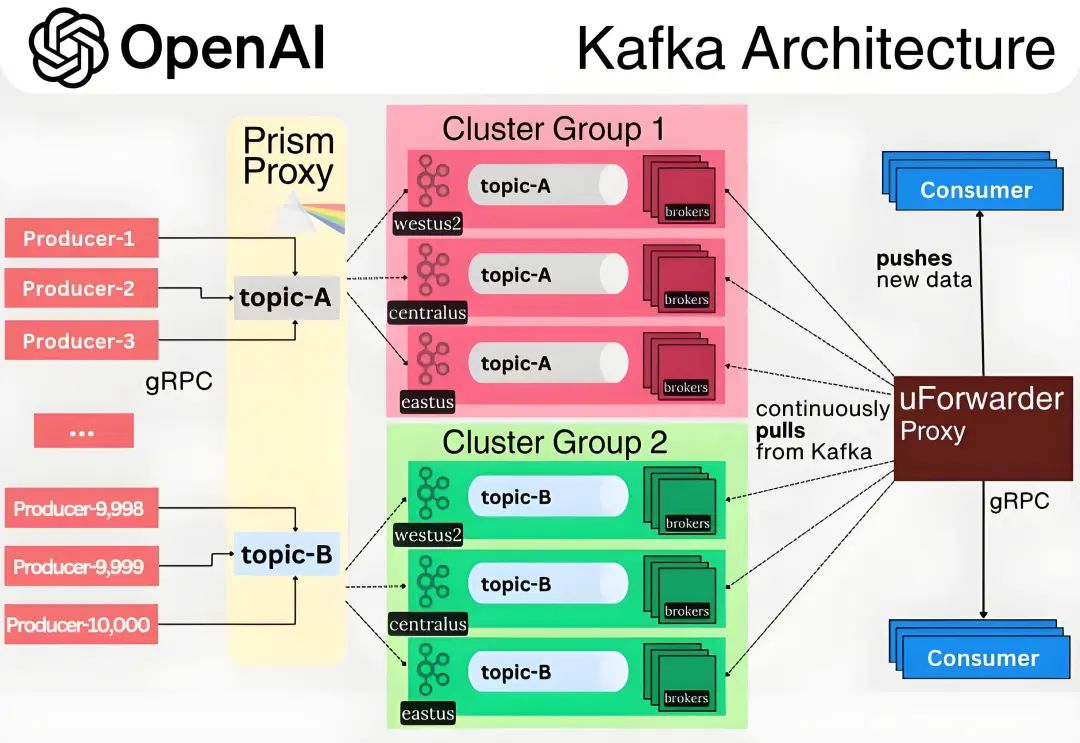
从 OpenAI 的技术方案可见,其架构设计始终以业务需求为驱动原点,核心聚焦业务系统与 Kafka 基础设施的解耦、全链路高可用保障,整体架构如下:

抽象分层

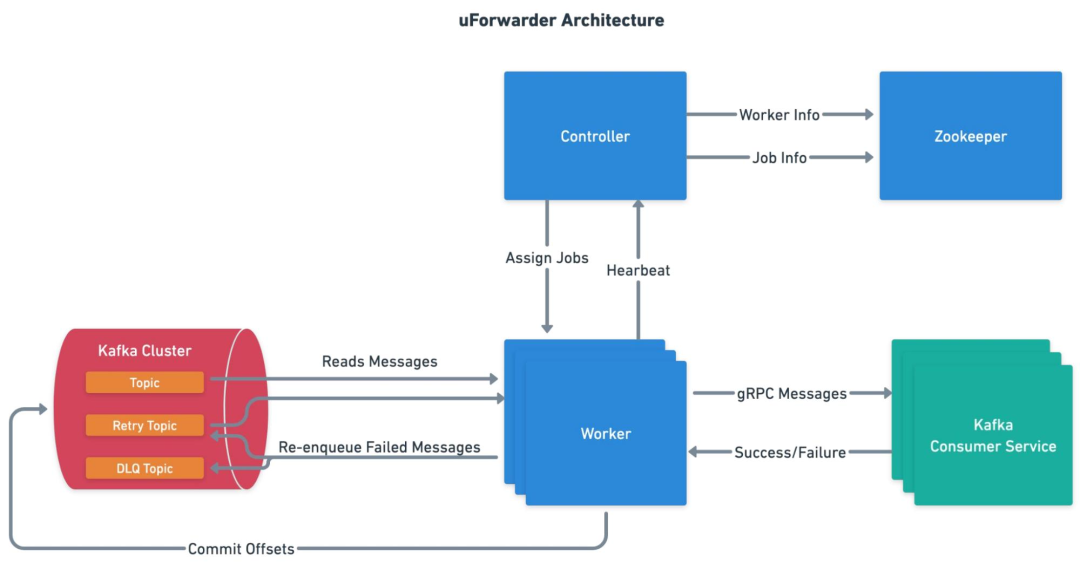
生产解耦[3]
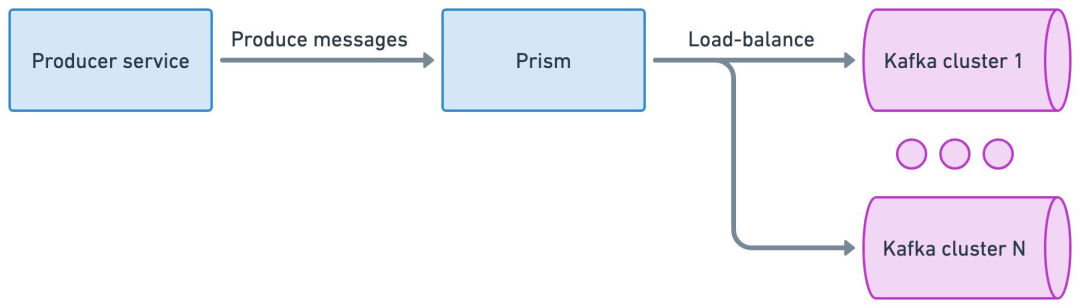
通过 Prism Proxy 代理层,将原生 Kafka 协议转换为标准化 gRPC 接口,屏蔽集群对接细节。
Prism Proxy 提供消息生产路由和负载均衡能力。
业务仅需指定逻辑主题(如 topic-A),无需感知物理集群部署(如 Cluster Group 1的位置与架构) 。
收敛生产者直连数量,规避海量连接导致的集群过载风险。
消费解耦[4]
uForwarder 模块实时从 Kafka 拉取新数据,并通过 gRPC 协议主动推送给业务消费服务。
uForwarder 模块通过 Zookeeper 管理消费相关的元数据配置,Controller 将任务下发给 Worker,实现高效的分布式内部协作。
uForwarder 内部基于Retry Topic 和 DLQ Topic 实现了重试消息和死信消息的能力。
消费服务仅需关注业务逻辑处理,通过返回成功或失败的应答,告知uForwarder是确认该消息还是重新推送。

可用性保障

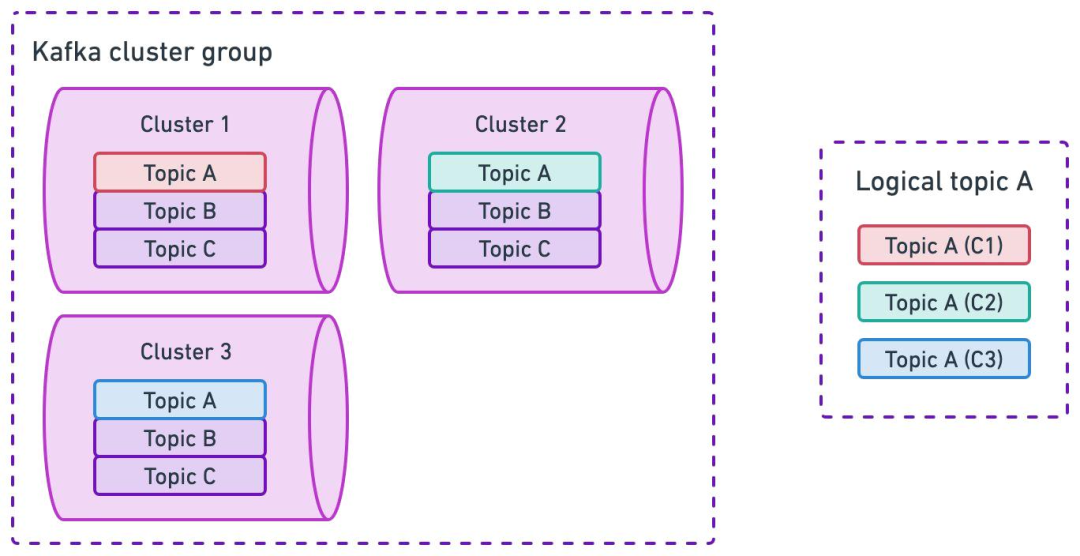
物理隔离
业务按集群组划分,每个业务组映射到特定集群组,降低业务间影响。
集群组内,Topic 会在所有集群中创建,避免单集群故障问题。
应对云环境的区域故障,集群组内采用跨区域部署。
生产高可用
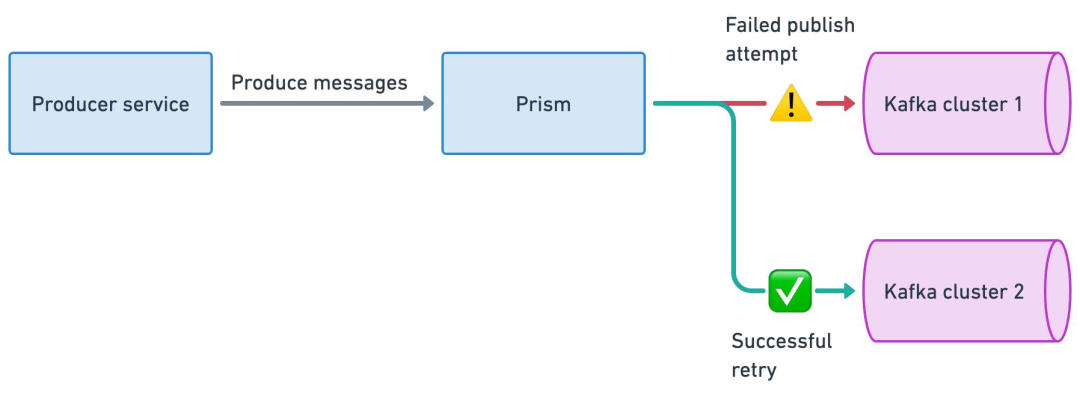
正常情况下,Prism Proxy 会基于负载均衡策略,将写入请求均匀分散到整个集群组。
当 Prism 向集群组中的 Kafka1 发送一批消息失败时,会自动选择另一个正常运行的集群(如 Kafka2)进行写入。
逻辑 TopicA 的消息会被均匀分散存储在集群组的所有 Kakfa 集群 TopicA 中,基于这种方式,实现了生产端的高可用性。
消费高可用
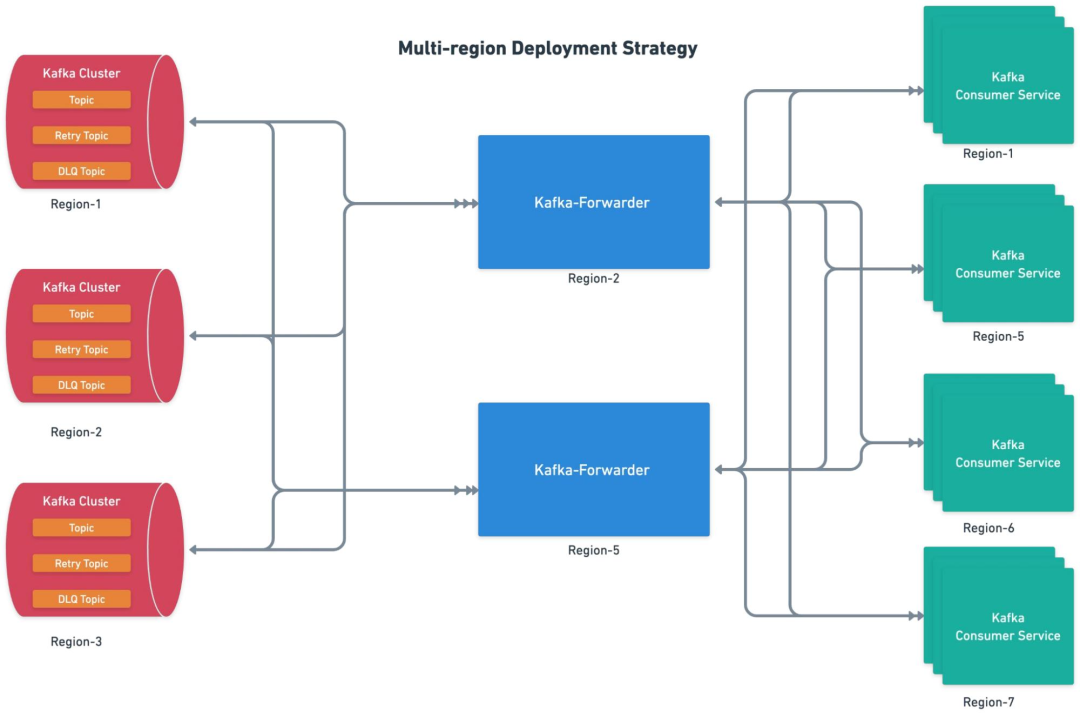
uForwarder 会与同集群组中的所有 Kafka 集群建立订阅关系。
uForwarder 模块负责定义逻辑 Topic 与后端 Consumer Server 端点的映射关系。
uForwarder 支持跨区域部署。
集群无缝迁移
历史集群迁移方案较为简单:
首先,Prism Proxy 通过调整路由配置,将生产请求从 legacy 集群摘除
待 uForwarder 消费完 legacy 集群中的残留消息后,即可安全下线该集群,完成迁移过程。
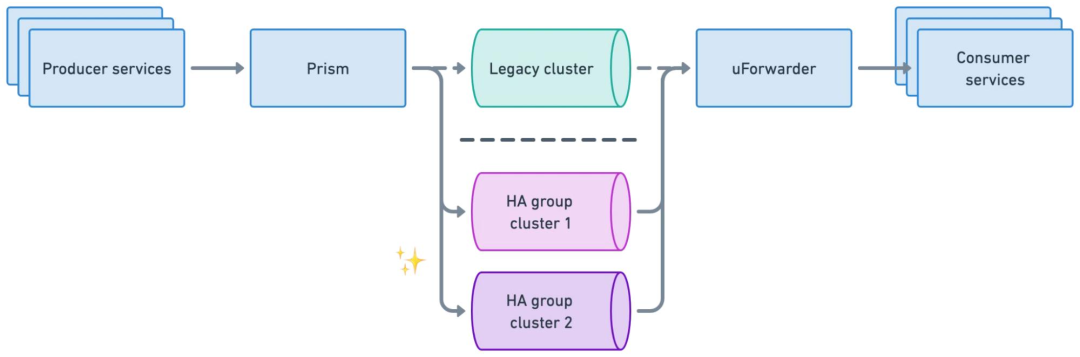
OpenAI 中 Kafka 这套架构方案比较常规,通过生产和消费的代理层来实现业务逻辑和消息中间件的解耦,同时在代理层实现流量的精细化调度。很多企业例如滴滴出行的 DDMQ[5] 也比较类似。
每个方案都有取舍,OpenAI 这个也不例外,主要体现在[3]:
消息的顺序性无法得到保证。在 Kafka 常规模式下,可以通过 key-based 路由将相同 key 的消息发送到同一 Topic 分区,从而提供分区级别的局部顺序性。然而,多集群写入方案在提升高可用性的同时,牺牲了消息的顺序性保障。OpenAI 将顺序问题由业务层自行处理,例如通过 Flink 批量消费数据后,在内部进行排序来规避这个问题。
消息幂等或事务性写入无法得到保证,原因同上。
OpenAI 更关注消息服务的可用性保障和业务系统的高效接入能力,当前这套技术方案能够较好地满足这些需求。
Kakfa 替换成 Pulsar 会更好

Apache Pulsar 作为下一代云原生分布式消息流平台,从架构上要领先于 Kakfa,更适合 OpenAI 所关注的集群可用性、可靠性以及端到端的低延迟场景。
架构对比
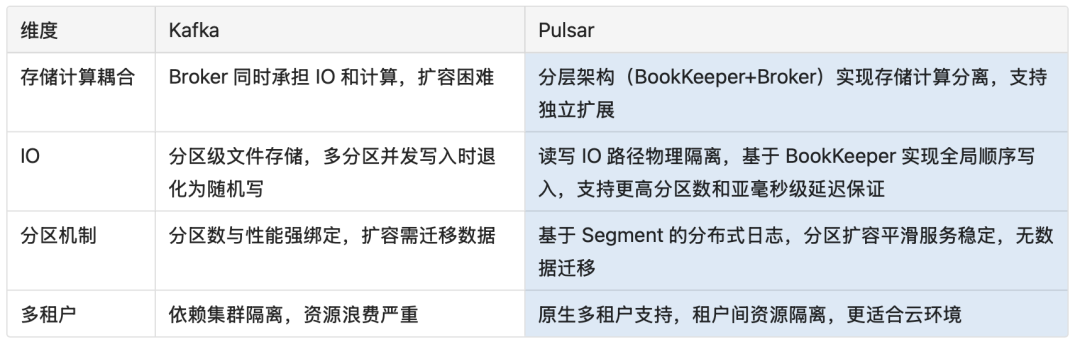
业务特性对比
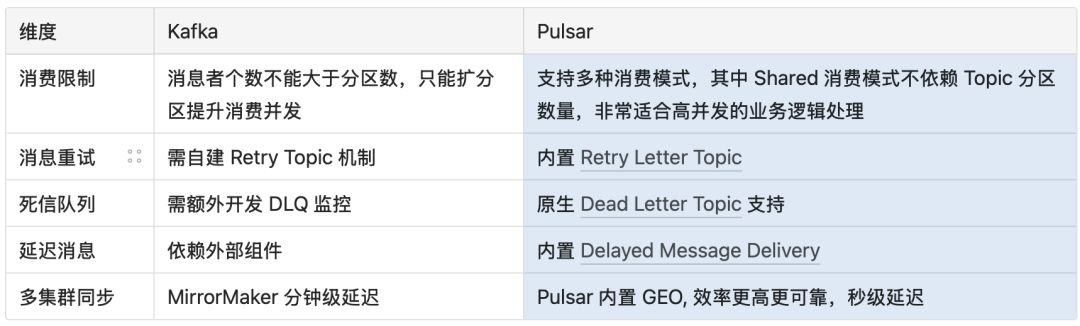
多集群同步机制至关重要。OpenAI 将业务数据分散存储在一个集群组中,并跨多个云可用区部署。这种情况下,Flink 无法从一个统一的数据源完整获取数据,同时还存在因重复读取同一份数据而产生的额外网络费用开销。

运维成本对比
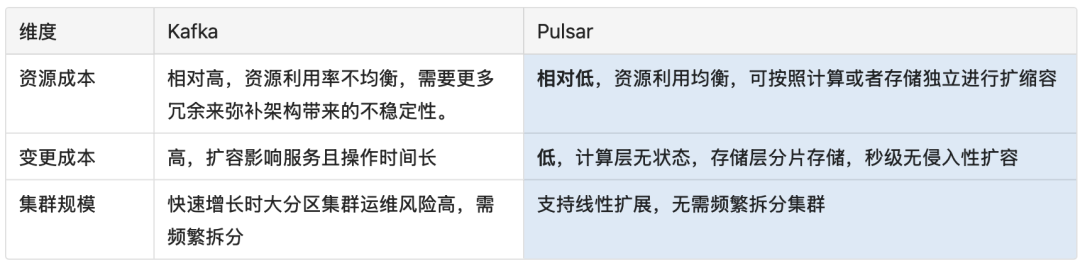
Apache Pulsar 能为 OpenAI 提供更简洁的流式架构、更经济的公有云消息中间件部署方案,同时具备更适合在线业务的功能特性,并能提供更可靠、更低延迟的消费服务。
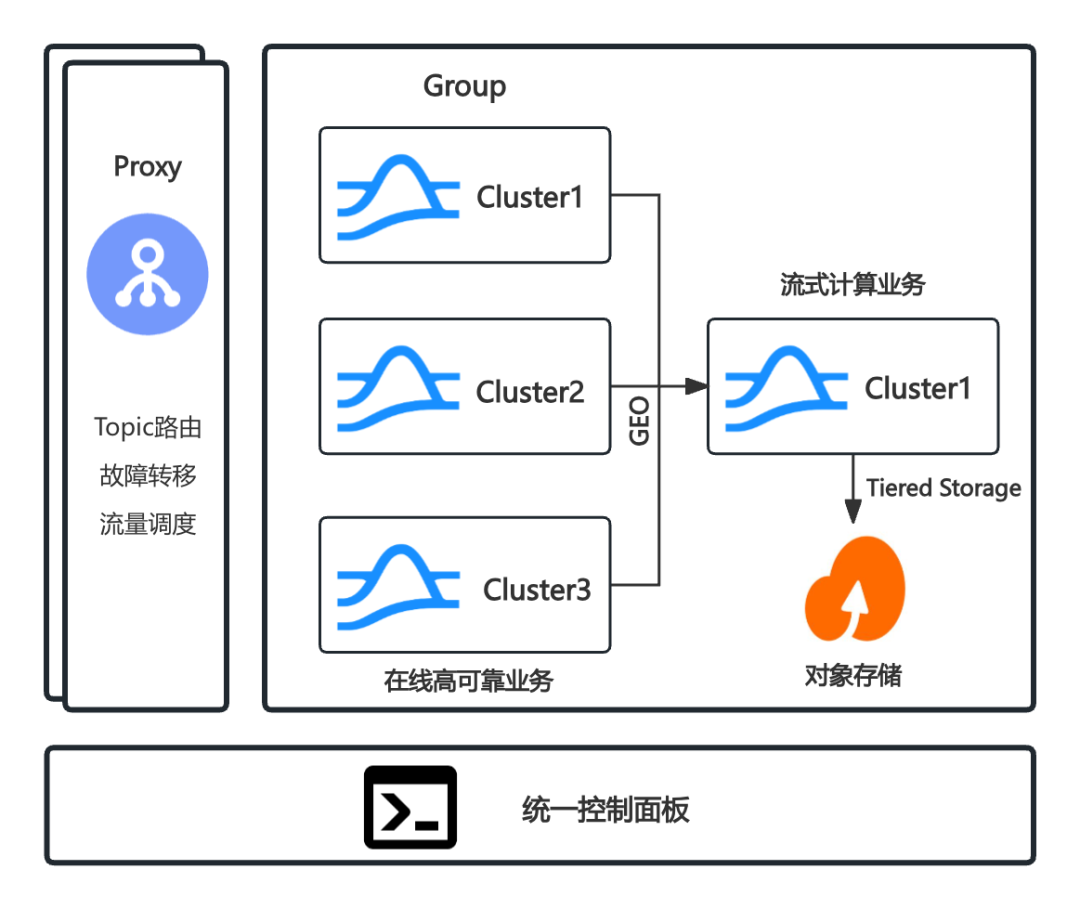
对于 Prism Proxy 和 uForwarder 模块是构建在消息中间件之上的配套能力,通过 Proxy 代理实现全局 Topic 的路由、故障转移以及流量调度能力;通过 GEO-Replication 能力高效可靠地汇聚数据,为流式计算业务提供统一的数据消费视图;基于 Tiered Storage 实现冷热数据分层存储,支持低成本长期数据保留(满足 PB 级存储需求);通过统一控制面板,以业务视角对集群组进行全生命周期管理。
结语

OpenAI 的 Kafka 代理层架构,是在业务爆发增长与基础设施瓶颈间的一次成功权衡——它通过创新的解耦设计将可用性推向极致,同时验证了“以业务需求反哺架构迭代”的实践哲学。
而 Pulsar 的云原生基因与高阶特性,则揭示了下一代消息流平台在 AI 时代的为更好的选择,本质上是对「规模、效率、成本」核心命题的持续求解。
参考文献
[1] OpenAI’s Kafka throughput grew 20x in the last year across 30+ clusters, https://www.linkedin.com/posts/stanislavkozlovski_openai-kafka-activity-7331683326195331073-cxN6/
[2] Building Stream Processing Platform at OpenAI, https://current.confluent.io/post-conference-videos-2025/building-stream-processing-platform-at-openai-lnd25
[3] Changing engines mid-flight: Kafka migrations at OpenAI, https://current.confluent.io/post-conference-videos-2025/changing-engines-mid-flight-kafka-migrations-at-openai-lnd25
[4] How OpenAI Simplifies Kafka Consumption, https://current.confluent.io/post-conference-videos-2025/changing-engines-mid-flight-kafka-migrations-at-openai-lnd25
[5]支持异构消息引擎!滴滴开源消息中间件DDMQ

Apache Pulsar 作为一个高性能、分布式的发布-订阅消息系统,正在全球范围内获得越来越多的关注和应用。如果你对分布式系统、消息队列或流处理感兴趣,欢迎加入我们!
Github:
https://github.com/apache/pulsar

扫码添加pulsarbot,加入Pulsar社区交流群
最佳实践
互联网
腾讯BiFang | 腾讯云 | 微信 | 腾讯 | BIGO | 360 | 滴滴 | 腾讯互娱 | 腾讯游戏 | vivo | 科大讯飞 | 新浪微博 | 金山云 | STICORP | 雅虎日本 | Nutanix Beam | 智联招聘
金融/计费
腾讯计费 | 平安证券 | 拉卡拉 | Qraft | 甜橙金融
电商
Flipkart | 谊品生鲜 | Narvar | Iterable
机器学习
腾讯Angel PowerFL
物联网
云兴科技智慧城市 | 科拓停车 | 华为云 | 清华大学能源互联网创新研究院 | 涂鸦智能
通信
江苏移动 | 移动云
教育
网易有道 | 传智教育
推荐阅读
资料合集 | 实现原理 | BookKeeper储存架构解析 | Pulsar运维 | MQ设计精要 | Pulsar vs Kafka | 从RabbitMQ 到 Pulsar | 内存使用原理 | 从Kafka到Pulsar | 跨地域复制 | Spring + Pulsar | Doris + Pulsar | SpringBoot + Pulsar











技术构建的数据可视化大屏展示页面)





)
)

