目录
前言
一、线程ID及进程地址空间布局
二、线程栈与线程局部存储
三、线程封装
总结:
前言
我们在上篇文章着重给大家说了一下线程的控制的有关知识。
但是如果我们要使用线程,就得那这pthread_create接口直接用吗?这样岂不是太过麻烦,要知道,C++,java等语言其实都对这个线程进行了封装,形成了独属于自己语言风格的线程。
今天,我们不仅要来给大家补充一些知识,还会给大家模拟实现一下一个简单的线程封装,希望能够帮助大家更好的学习线程。
一、线程ID及进程地址空间布局
我们之前使用pthread_create的时候曾经提到了线程ID。
我们知道,Linux中没有真正意义上的线程,只有轻量级进程。
每一个线程的数据结构其实都是PCB,所以针对每一个PCB,每一个线程(轻量级进程时调度的最小单位),都会有一个对应的ID来表示该线程,这个ID跟我们学习进程时的pid_t差不多。
但是实际上,pthread_create函数在使用时会产生一个线程ID,并将其存放在第一个参数指向的内存位置。pthread_create返回的线程ID实际上是NPTL线程库在用户空间分配的一个内存地址,这个地址指向线程控制块(TCB),作为线程库内部管理线程的标识符。线程库的后续操作,都是根据这个线程ID来操作的。
线程库提供了pthread_self函数,可以获得线程自身的ID:

#define _GNU_SOURCE
#include <stdio.h>
#include<iostream>
#include <pthread.h>
#include <unistd.h>void* thread_func(void* arg)
{// 获取当前线程的 pthread_tpthread_t self_id = pthread_self();// 打印 pthread_t 的值(以指针和整数形式)printf("Thread ID (pthread_self):\n");printf(" As pointer: %p\n", (void*)self_id);printf(" As unsigned long: %lu\n", (unsigned long)self_id);return NULL;
}int main()
{pthread_t tid;// 创建线程pthread_create(&tid, NULL, thread_func, NULL);// 打印主线程看到的 pthread_tstd::cout<<tid<<std::endl;printf("Main thread sees new thread ID:\n");printf(" As pointer: %p\n", (void*)tid);printf(" As unsigned long: %lu\n", (unsigned long)tid);pthread_join(tid, NULL);return 0;
}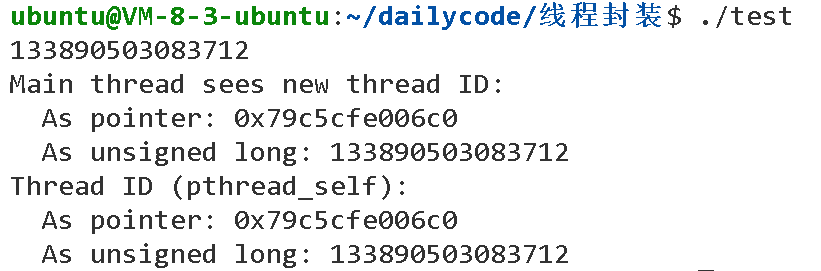
可以看出,实质上就是一个地址
我们之前学过一点库。可以知道,我们是先将pthread库加载到物理内存中,通过映射,让自己被看见(共享):
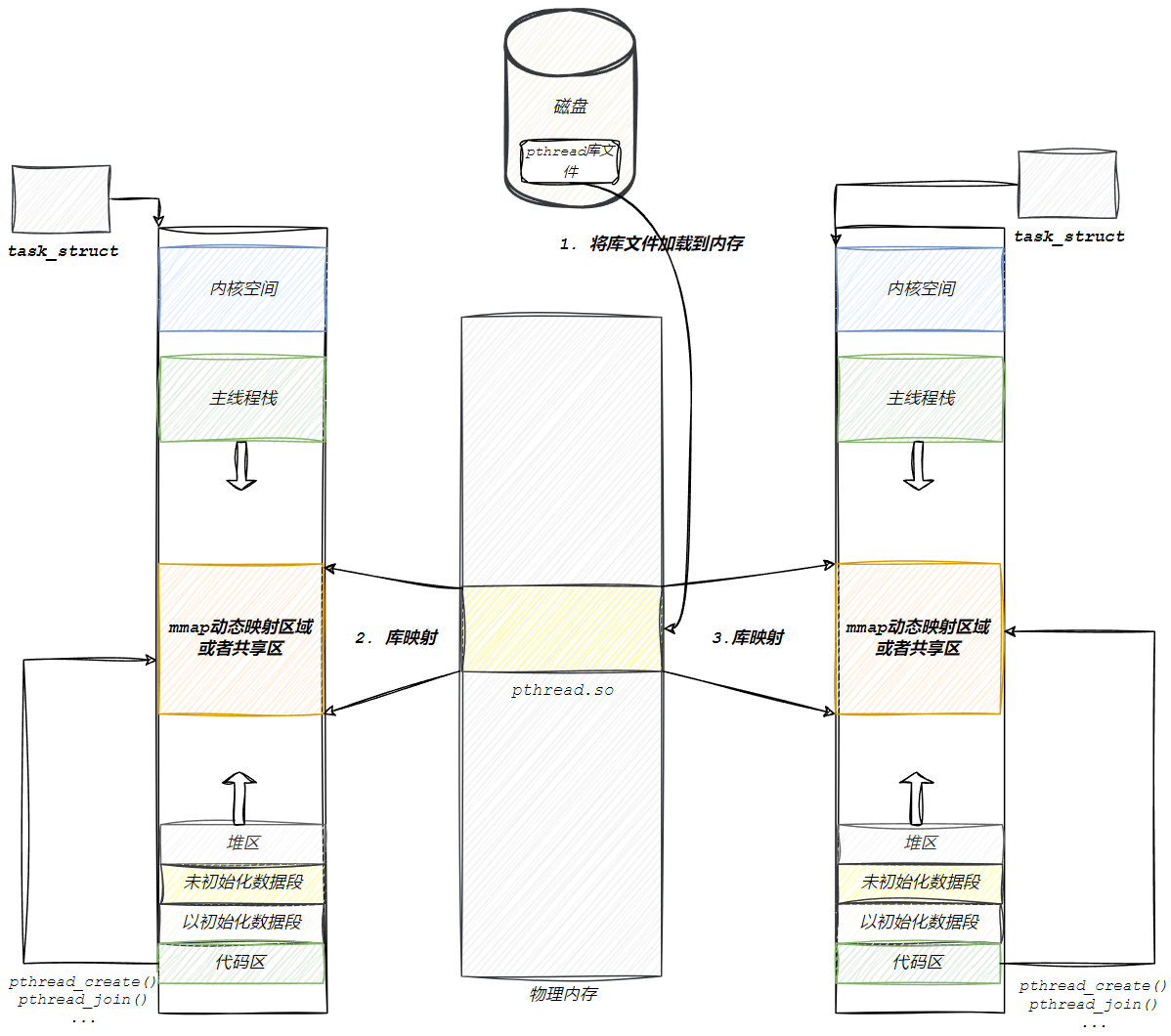
所以库也是共享的,那如果有一百个线程,库的内部岂不是要维护一百份线程的属性集合?库要不要对线程属性进行管理?
:要,怎么管理?:先描述,再组织。
所以有一个结构体,叫做TCB。 这就跟你去图书馆查阅资料一样,图书馆的书都是共享的,但是你需要读者借阅卡。
可以这样理解Linux线程的管理机制:主线程的进程控制块(PCB)通过mmap区域维护着与线程库(libpthread.so)的映射关系,而线程库内部使用一个称为TCB(线程控制块)的关键数据结构来管理线程资源。
每个TCB不仅保存着对应线程的pthread_t标识符(实际上就是TCB自身的地址指针),还记录了该线程独立分配的栈空间信息,包括栈的起始虚拟地址和结束虚拟地址。这些TCB通过链表等形式组织起来,使得线程库能够高效地管理所有线程的私有数据和执行上下文,而内核则只需关注轻量级进程(LWP)的调度,实现了用户态和内核态的协同分工。
每一个线程的TCB,在他创建时就已经在当前进程的堆空间上分配好空间了。
二、线程栈与线程局部存储
刚刚说每个TCB中都记录了当前线程独立分配的栈空间。
没错,每个线程也会独立分配栈空间信息,那么线程的栈与进程的栈有什么区别呢?
| 线程栈 | 进程栈(主线程栈) |
|---|---|
由线程库(NPTL)通过 mmap 动态分配 | 由内核在进程启动时静态分配 |
默认大小:8MB(可通过 pthread_attr_setstacksize 调整) | 默认大小:8MB(受 |
但是二者最大的区别,就是线程的栈,满了之后是不会自动拓展的。但是进程的栈,是可能会自动拓展的。
子线程的栈原则上是他私有的,但是同一个进程的所有线程生成时,会浅拷贝生成这的task_struct的很多字段,所以如果愿意。其他线程是可以访问到别人的栈区的。这一点我们在上一篇文章也提到过了。
我们之前说过,全局变量在多线程中是共享的,如果你改变了,我看见的也会改变。那有没有什么办法让这个各自私有一份呢?
有的,就是线程局部存储。
我们要用到__thread关键字。
#include <stdio.h>
#include<iostream>
#include <pthread.h>
#include <unistd.h>__thread int counter = 0; // 每个线程有独立副本void* thread_func(void* arg)
{for (int i = 0; i < 3; i++) {counter++; // 修改线程私有变量printf("Thread %ld: counter = %d (地址: %p)\n",(long)arg, counter, &counter);}return NULL;
}int main()
{pthread_t t1, t2;pthread_create(&t1, NULL, thread_func, (void*)1);pthread_create(&t2, NULL, thread_func, (void*)2);pthread_join(t1, NULL);pthread_join(t2, NULL);printf("主线程: counter = %d\n", counter); // 输出0(主线程的独立副本)return 0;
}在全局变量前使用该关键字,可在各线程中私有一份,这个线程独立存储是在TCB中记录的。

三、线程封装
补充完了线程的知识,接下来我们就进行封装一下我们的线程,方便后续课程的使用。
首先,我们要明确要实现的功能,
封装几个最常用的功能:
-
start():开新线程让它跑起来
-
join():等这个线程干完活
-
detach():让线程自己玩去,不用管它死活
-
stop():强行让线程下岗(这个要小心用)
为了实现这些功能,我们就得想要哪些成员变量帮助我们实现方法,或者记录一下信息:
-
线程ID(_tid):不然找不到这个线程
-
线程名(_name):调试时候好认人
-
能不能join(_joinable):防止重复join搞出事情
-
进程ID(_pid):这个可能有用先留着
所以我们可以先这样写:
#ifndef _MYTHREAD_HPP_
#define _MYTHREAD_HPP_#include<iostream>
#include<string>namespace ThreadModule
{class Mythread{public:Mythread(){}void start()//负责线程的创建{}void join()//负责线程的等待{}void stop()//负责线程的取消{}~Mythread(){}void detach()//负责线程的分离{}private:std::string _name;pthread_t _tid;pid_t _pid;bool _joinable;//判断状态,我们之前讲了进程分离};
}#endif
为了后文我们方便调用测试方法,所以我们可以用function,来包含我们的方法(打印之类的),我们规定这个方法就是void(void)的函数,所以我们可以在类成员变量中新加一个方法,为了方便,可以使用重命名:using func_t = std::function<void()>;
另外,我们可以定义一个enum,来定义宏状态来代表线程的运行状态(不是分离):新建,运行,暂停
using func_t = std::function<void()>;enum class TSTATUS{NEW,RUNNING,STOP};想完这些,就是来实现我们的函数接口了。
首先是初始化,我们规定我们的线程要传入相应的执行方法,所以构造函数需要外部传入func_t类型。同时,为了方便从名称看出来线程的数量等信息,我们可以在作用域中定义一个static int的number变量来记录,在_name初始化时可以用上。
Mythread(func_t func):_func(func), _status(TSTATUS::NEW), _joinable(true){_name = "Thread-" + std::to_string(number++);_pid = getpid();}然后,就是创建进程,这里我们要注意,先检查状态是否为Running,如果是,就没必要新建一个线程,
这里我们要注意的是,我们需要写一个回调函数Routine,方便我们执行传进来的函数func,以及改变运行状态等操作,为了安全,这个回调函数应该写在private中:
值得注意的是,我们Routine的前缀类型如果没有加static,在我们start中pthread_create时会报错。
因为我们的Routine是类成员函数,真正的函数参数中是有一个this指针的,所以我们这里必须加static限制。
private:static void *Routine(void*args){Mythread *t = static_cast<Mythread *>(args);t->_status = TSTATUS::RUNNING;t->_func();return nullptr;} bool start()//负责线程的创建{if (_status != TSTATUS::RUNNING){int n = ::pthread_create(&_tid, nullptr, Routine, this); // TODOif (n != 0)return false;return true;}return false;}顺便,修改一下start函数返回类型为bool,为了方便我们获取是否成功的信息。(这里是一切从简了,否则我们还可以定义一个返回值错误的enum)
之后,就是对join,stop的封装,实际上底层就是调用我们之前说过的pthread_cancel与pthread_join,所以这里不再过多赘述。
bool join()//负责线程的等待{if (_joinable){int n = ::pthread_join(_tid, nullptr);if (n != 0)return false;_status = TSTATUS::STOP;return true;}return false;}bool stop()//负责线程的取消{if (_status == TSTATUS::RUNNING){int n = ::pthread_cancel(_tid);if (n != 0)return false;_status = TSTATUS::STOP;return true;}return false;}最后,就是线程的分离,我们要判断我们的成员变量_joinable的状态,是否可以进行分离,随后调用分离函数,最后再更新状态:
bool detach()//负责线程的分离{if (_joinable){int n = ::pthread_detach(_tid);if (n != 0)return false;_joinable = false;}}为了方便我们后续的打印测试,所以我们可以新加一个name接口返回该线程的名字。
所以我们初代版本的简单线程封装,就已经完成了:
#ifndef _MYTHREAD_HPP_
#define _MYTHREAD_HPP_#include<iostream>
#include<string>
#include<functional>
#include<unistd.h>
#include<sys/types.h>namespace ThreadModule
{using func_t = std::function<void()>;static int number =1;enum class TSTATUS{NEW,RUNNING,STOP};class Mythread{private:static void *Routine(void*args){Mythread *t = static_cast<Mythread *>(args);t->_status = TSTATUS::RUNNING;t->_func();return nullptr;}public:Mythread(func_t func):_func(func), _status(TSTATUS::NEW), _joinable(true){_name = "Thread-" + std::to_string(number++);_pid = getpid();}bool start()//负责线程的创建{if (_status != TSTATUS::RUNNING){int n = ::pthread_create(&_tid, nullptr, Routine, this); // TODOif (n != 0)return false;return true;}return false;}bool join()//负责线程的等待{if (_joinable){int n = ::pthread_join(_tid, nullptr);if (n != 0)return false;_status = TSTATUS::STOP;return true;}return false;}bool stop()//负责线程的取消{if (_status == TSTATUS::RUNNING){int n = ::pthread_cancel(_tid);if (n != 0)return false;_status = TSTATUS::STOP;return true;}return false;}~Mythread(){}bool detach()//负责线程的分离{if (_joinable){int n = ::pthread_detach(_tid);if (n != 0)return false;_joinable = false;}}std::string Name(){return _name;}private:std::string _name;pthread_t _tid;pid_t _pid;bool _joinable;//判断状态,我们之前讲了进程分离func_t _func;TSTATUS _status;};
}#endif
我们可以写一些代码来测试一下:
#include <stdio.h>
#include<iostream>
#include <pthread.h>
#include <unistd.h>#include "Mythread.hpp"int main()
{ThreadModule::Mythread t([](){while(true){std::cout << "hello world" << std::endl;sleep(1);}});t.start();std::cout << t.Name() << "is running" << std::endl;sleep(5);t.stop();std::cout << "Stop thread : " << t.Name()<< std::endl;sleep(1);t.join();std::cout << "Join thread : " << t.Name()<< std::endl;return 0;
}
那么如果我要用多线程呢?
我们这里不使用C++的方法可变参数,我们可以使用我们的老朋友容器来进行管理:
using thread_ptr_t = std::shared_ptr<ThreadModule::Mythread>;int main()
{std::unordered_map<std::string, thread_ptr_t> threads;// 如果我要创建多线程呢???for (int i = 0; i < 10; i++){thread_ptr_t t = std::make_shared<ThreadModule::Mythread>([](){while(true){//std::cout << "hello world" << std::endl;sleep(1);}});threads[t->Name()] = t;}for(auto &thread:threads){thread.second->start();std::cout<<thread.second->Name()<<"is started"<<std::endl;}sleep(5);for(auto &thread:threads){thread.second->stop();std::cout<<thread.second->Name()<<"is stopped"<<std::endl;}for(auto &thread:threads){thread.second->join();std::cout<<thread.second->Name()<<"is joined"<<std::endl;}return 0;
}至此,一旦有了线程对象后,我们就能使用容器的方式对线程进行管理了,所以这就是:先描述再组织。
总结:
我们线程部分的第一阶段的内容就到此结束了,接下来带大家进入二阶段:同步异步等概念知识的学习,届时,我们就会接触到锁等概念了。


)




 的用法与实战案例)










)
