一、缓存机制的原理
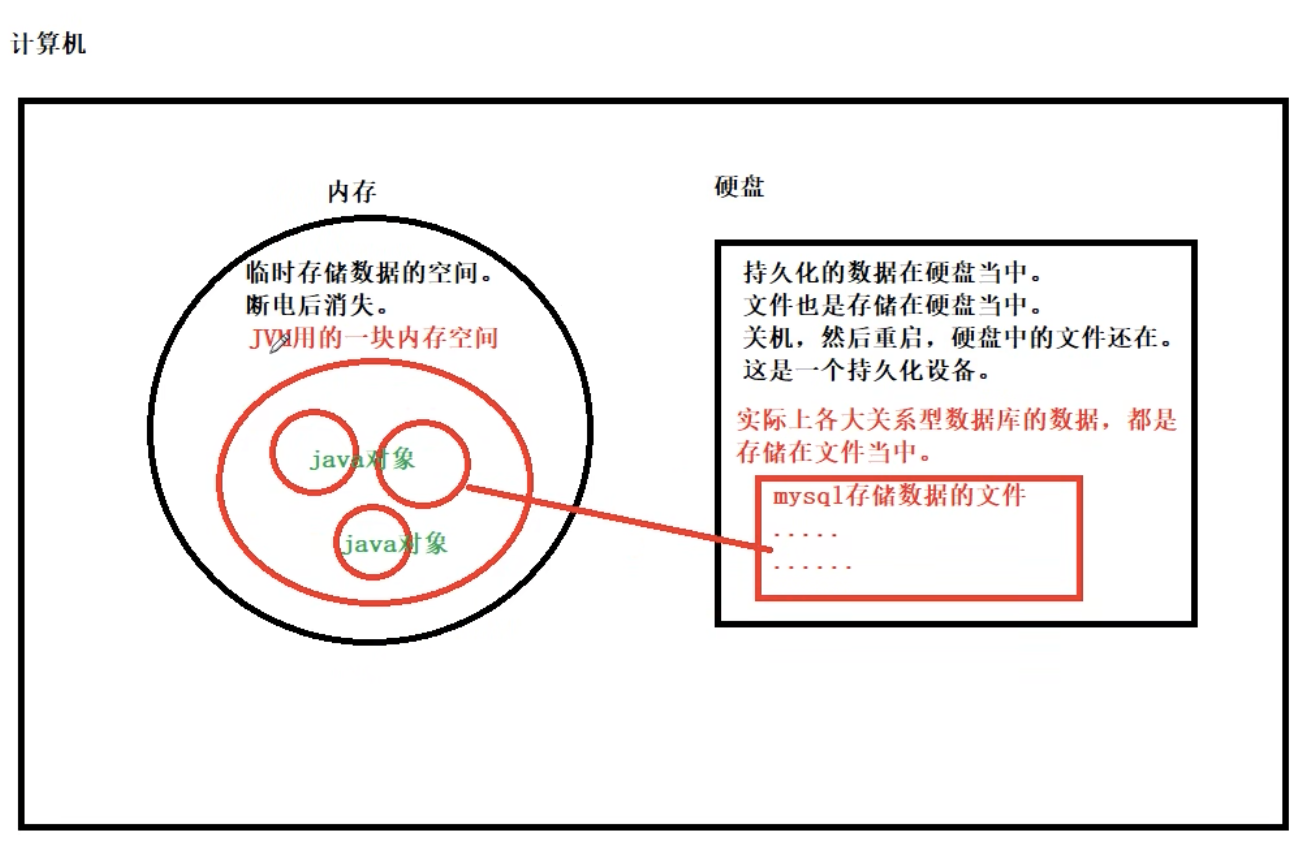
计算机每次从mysql中执行sql语句,都是内存与硬盘的通信,对计算机来说,影响效率。
因此使用缓存机制。
1-1、MyBatis 的缓存机制:
执行 DQL(select 语句)的时候,将查询结果放到缓存当中(内存当中),如果下一次还是执行完全相同的 DQL(select 语句)语句,直接从缓存中拿数据,不再查数据库了。不再去硬盘上找数据了。
示例:
第一次执行这个 SQL:
select * from t_car where id=1;
第二次还是执行这个 SQL,完全一样:
select * from t_car where id=1;
此时,从缓存中获取,不再查数据库了。
当两条sql语句之间,对数据库做了任何修改操作,缓存将从内存中清除。
目的:提高执行效率。
缓存机制:使用减少 IO 的方式来提高效率。
IO:读文件和写文件。
缓存通常是我们程序开发中优化程序的重要手段:
- 字符串常量池
- 整数型常量池
- 线程池
- 连接池
- ……
【小结】:
缓存(cache)就是内存,提前把数据放到内存中,下一次用的时候,直接从缓存中拿,效率高!
二、几种常见的缓存/池化技术
这些“池”技术,其实都是 Java 中的 缓存/复用机制,目的是:提升性能、减少资源消耗、避免频繁创建和销毁对象。下面来系统讲解几种常见的缓存/池化技术:
2-1、字符串常量池(String Constant Pool)
1、原理:
Java 中字符串是不可变的(final),所以 JVM 会把相同的字符串常量只保留一份副本,存放在一个称为 字符串常量池 的内存区域。
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2); // true
"hello"是一个字符串字面量,保存在常量池中s1 和 s2 都指向同一个地址
2、注意:
String s3 = new String("hello");
System.out.println(s1 == s3); // false(堆 vs 常量池)
如果你想把 new 出来的字符串放入常量池:
String interned = s3.intern();
System.out.println(s1 == interned); // true
2-2、整数型常量池(Integer Cache)
1、原理:
Java 对于包装类型 Integer,有一个缓存区([-128, 127]),当你使用 valueOf() 方法创建时,会从缓存中取对象而不是创建新对象。
Integer a = 127;
Integer b = 127;
System.out.println(a == b); // true(缓存)Integer c = 128;
Integer d = 128;
System.out.println(c == d); // false(未缓存)
2、范围:
JVM 默认缓存范围为 [-128, 127],可以通过启动参数修改:
-XX:AutoBoxCacheMax=300
2-3、线程池(Thread Pool)
1、原理:
线程的创建与销毁成本高(涉及操作系统资源),频繁创建新线程会拖慢系统。
所以,线程池把线程复用起来,让多个任务共享固定线程,提高并发效率。
2、常用方式:
// 创建固定大小为 3 的线程池ExecutorService pool = Executors.newFixedThreadPool(3);// 模拟提交 5 个任务for (int i = 1; i <= 15; i++) {int taskId = i;pool.submit(new Runnable() {public void run() {String threadName = Thread.currentThread().getName();System.out.println("任务 " + taskId + " 开始,线程:" + threadName);try {Thread.sleep(20000); // 模拟任务耗时} catch (InterruptedException e) {e.printStackTrace();}System.out.println("任务 " + taskId + " 结束,线程:" + threadName);}});}// 关闭线程池(注意不是立刻关闭)pool.shutdown();
打印结果:
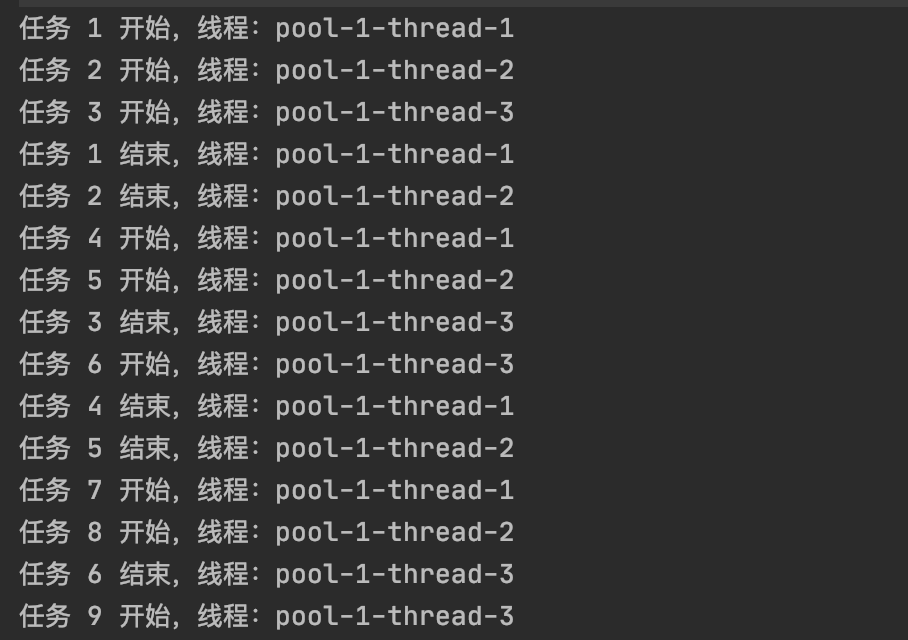
可以看到线程是复用的。
Executors 提供常见线程池工厂方法:
newFixedThreadPool(n)newCachedThreadPool()newSingleThreadExecutor()newScheduledThreadPool(n)
2-4、连接池(Connection Pool)
1、 原理:
数据库连接创建代价高(要连接服务器、授权、建会话),所以使用连接池 复用已建立的连接。
2、常见实现:
HikariCP(Spring Boot 默认)
DBCP
C3P0
Druid
3、示例(Spring Boot):
spring.datasource.hikari.maximum-pool-size: 10
应用启动后,会提前建立 10 个连接,放入连接池,供业务查询复用。
2-5、对象池(Object Pool)
对于那些频繁使用又比较重量级的对象(如:ByteBuffer, Socket, 数据库连接),也可以池化处理。
Java 标准库没有通用的 ObjectPool,但 Apache Commons Pool 提供支持。
GenericObjectPool<MyReusableObject> pool = new GenericObjectPool<>(new MyObjectFactory());MyReusableObject obj = pool.borrowObject(); // 借
obj.doSomething(); // 用
pool.returnObject(obj); // 还你需要在项目中引入 Apache Commons Pool 的依赖(如果用 Maven):
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.11.1</version> <!-- 可根据需要换版本 -->
</dependency>
2-6、内存缓存(如 LRU 缓存)
Java 中可以自己实现缓存算法(如 LRU),也可以使用:
Guava Cache
Caffeine(高性能)
Ehcache
Redis(分布式)
示例(Caffeine):
Cache<String, Object> cache = Caffeine.newBuilder().maximumSize(1000).expireAfterWrite(10, TimeUnit.MINUTES).build();
2-7、类加载缓存(ClassLoader)
JVM 对每个类只加载一次,会将 .class 文件缓存到内存中,后续实例化只需创建对象而不重复加载。
2-8、反射缓存(Method/Field 缓存)
使用反射获取字段/方法(如 Class.getDeclaredMethods())是慢操作。JVM 会自动缓存这些反射结构,Spring、MyBatis 等框架也会自己做缓存。
2-9、JVM 运行时常见缓存(底层)
| 缓存类型 | 说明 |
|---|---|
| 字符串常量池 | 复用 String 常量 |
| Integer 缓存 | 避免频繁装箱创建 Integer |
| Class 常量池 | 常量值如 final 字段、枚举等 |
| 方法句柄缓存 | JVM 优化调用性能 |
| Lambda 表达式缓存 | 编译后只创建一次匿名类对象 |
2-10、总结对比表
| 技术名称 | 类型 | 缓存对象 | 控制方式 | 是否可配置 |
|---|---|---|---|---|
| 字符串常量池 | 编译期/运行期 | String | 自动/intern() | ❌ |
| Integer 缓存 | 运行期 | Integer | 自动/valueOf() | ✅ |
| 线程池 | 并发 | Thread | Executors | ✅ |
| 连接池 | IO资源 | DB连接 | DataSource | ✅ |
| ObjectPool | 自定义 | 业务对象 | Apache Commons | ✅ |
| Guava/Caffeine | 本地缓存 | 任意对象 | API构建 | ✅ |
| Redis | 分布式缓存 | 任意对象 | 客户端控制 | ✅ |
三、Mybatis的缓存
mybatis 缓存包括:
- 一级缓存:将查询到的数据存储到 SqlSession 中。
- 二级缓存:将查询到的数据存储到 SqlSessionFactory 中。
- 集成其它第三方的缓存:比如 EhCache【Java 语言开发的】、Memcache【C 语言开发的】等。
SqlSessionFactory是一个数据库一个,SqlSession作用域是当前的sql会话。
缓存只针对DQL语句,也就是说:缓存只针对select语句!
3-1、MyBatis 一级缓存
3-1-1、什么是一级缓存?
一级缓存是 MyBatis 的默认缓存机制,作用范围是 一次 SqlSession 内部。简单说:
同一个 SqlSession 中,相同的查询语句和参数,MyBatis 会从缓存中取数据,不会再次访问数据库。
一级缓存mybatis默认开启,不需要任何配置!
3-1-2、一级缓存工作流程图
SqlSession├── 查询语句 1(未命中缓存) → 查数据库,缓存结果├── 查询语句 1(再次执行) → 命中缓存,直接返回└── SqlSession.close() → 缓存销毁
3-1-3、一级缓存使用示例
@Test
public void testFirstLevelCache() {SqlSession session = sqlSessionFactory.openSession();UserMapper mapper = session.getMapper(UserMapper.class);// 第一次查询,去数据库User u1 = mapper.selectById(1L);System.out.println("第一次查询:" + u1);// 第二次查询相同 ID,命中缓存User u2 = mapper.selectById(1L);System.out.println("第二次查询:" + u2);System.out.println(u1 == u2); // true(同一个对象)session.close();
}
【注意】:
此时,控制台只执行一条sql select语句!
3-1-4、哪些情况会导致缓存失效?
SqlSession 不是同一个
每次
openSession()创建新的 Session,缓存就不同。示例:
@Testpublic void testFirstCache2() throws IOException {SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml"));SqlSession sqlSession1 = sqlSessionFactory.openSession();CarMapper mapper1 = sqlSession1.getMapper(CarMapper.class);Car car1 = mapper1.selectOneById(1L);System.out.println(car1);SqlSession sqlSession2 = sqlSessionFactory.openSession();CarMapper mapper2 = sqlSession2.getMapper(CarMapper.class);Car car2 = mapper2.selectOneById(1L);System.out.println(car2);sqlSession1.close();sqlSession2.close();}此时,控制台会打印两条sql select语句。
执行了
update/insert/delete操作写操作会清空缓存(保证数据一致性),修改任意一张表,都会清空缓存!
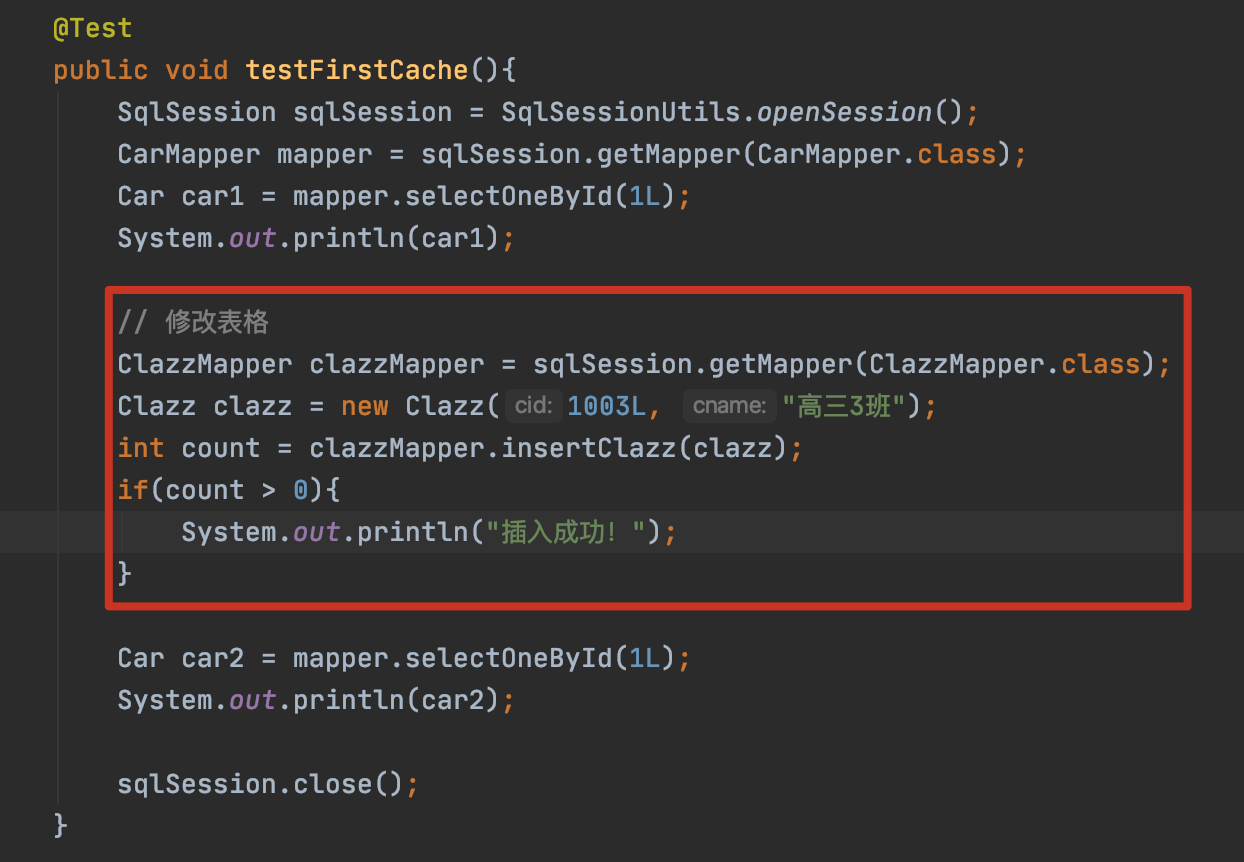
手动清空缓存
session.clearCache();查询的 SQL 或参数不同
3-1-5、一级缓存原理简述
MyBatis 内部维护了一个
PerpetualCache(HashMap 实现)每次查询前会根据 SQL+参数,生成 key,先查缓存
如果命中,直接返回
如果没命中,查数据库并存入缓存
3-2、MyBatis 二级缓存
MyBatis 的二级缓存,这对优化多次查询、减少数据库压力非常重要,尤其是跨 SqlSession 的查询场景。
3-2-1、什么是二级缓存?
二级缓存是 MyBatis 提供的跨 SqlSession 的缓存机制。
它的作用范围是:Mapper 映射级别(namespace),不同 SqlSession 之间共享缓存数据。
3-2-2、一级 vs 二级缓存对比
| 对比项 | 一级缓存(默认) | 二级缓存(需开启) |
|---|---|---|
| 缓存范围 | 单个 SqlSession 内 | 多个 SqlSession 共享 |
| 默认状态 | 开启 | 默认关闭 |
| 生命周期 | SqlSession 生命周期 | 应用级、映射器级别 |
| 存储结构 | 基于 HashMap(PerpetualCache) | 可自定义实现 |
| 典型用途 | 同一次操作内避免重复查询 | 缓解高频读操作数据库压力 |
3-2-3、使用二级缓存的三步配置
Step 1:开启全局二级缓存
<settings><setting name="cacheEnabled" value="true"/>
</settings>
【注意】:
是的,
<setting name="cacheEnabled" value="true"/>在 MyBatis 中默认就是开启的。
Step 2:在 Mapper 映射文件中开启 <cache/>
例如:UserMapper.xml
<mapper namespace="com.example.mapper.UserMapper"><cache /><select id="selectById" resultType="User">SELECT * FROM users WHERE id = #{id}</select>
</mapper>
你也可以配置更多参数(见下方扩展)
Step 3:实体类实现 Serializable 接口(因为缓存需要序列化)
public class User implements Serializable {private Long id;private String name;// ...其他字段
}
3-2-4、二级缓存使用示例
示例1:没有使用二级缓存

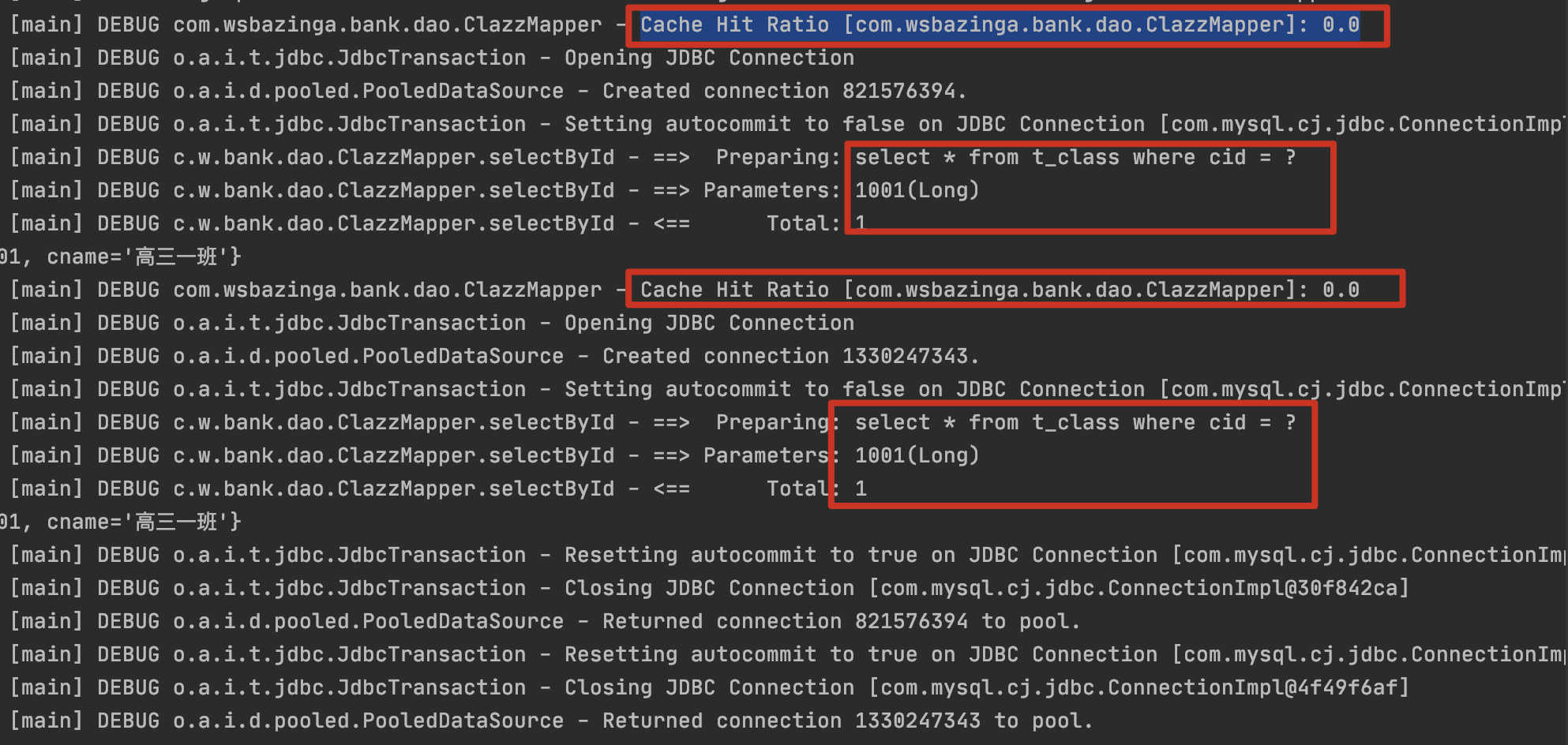
示例2:数据从二级缓存中获取
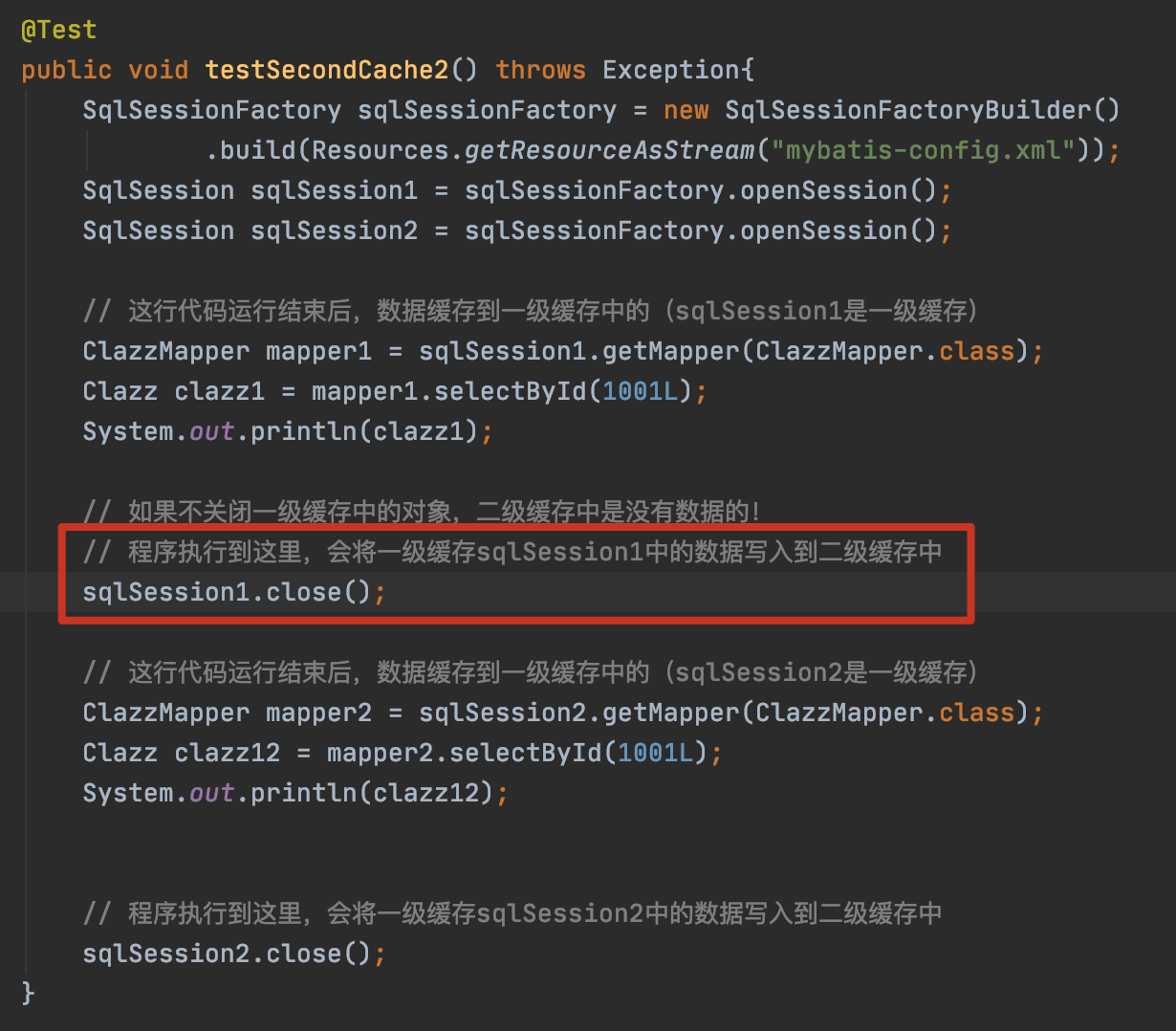
sqlSession1关闭,数据保存到二级缓存中,再执行sqlSession2中的select语句,会从二级缓存中获取。

【注意】:
一级缓存的优先级高,先从一级缓存中取数据,若是一级缓存关闭,则从二级中取数据!
示例3:跨namespace测试二级缓存
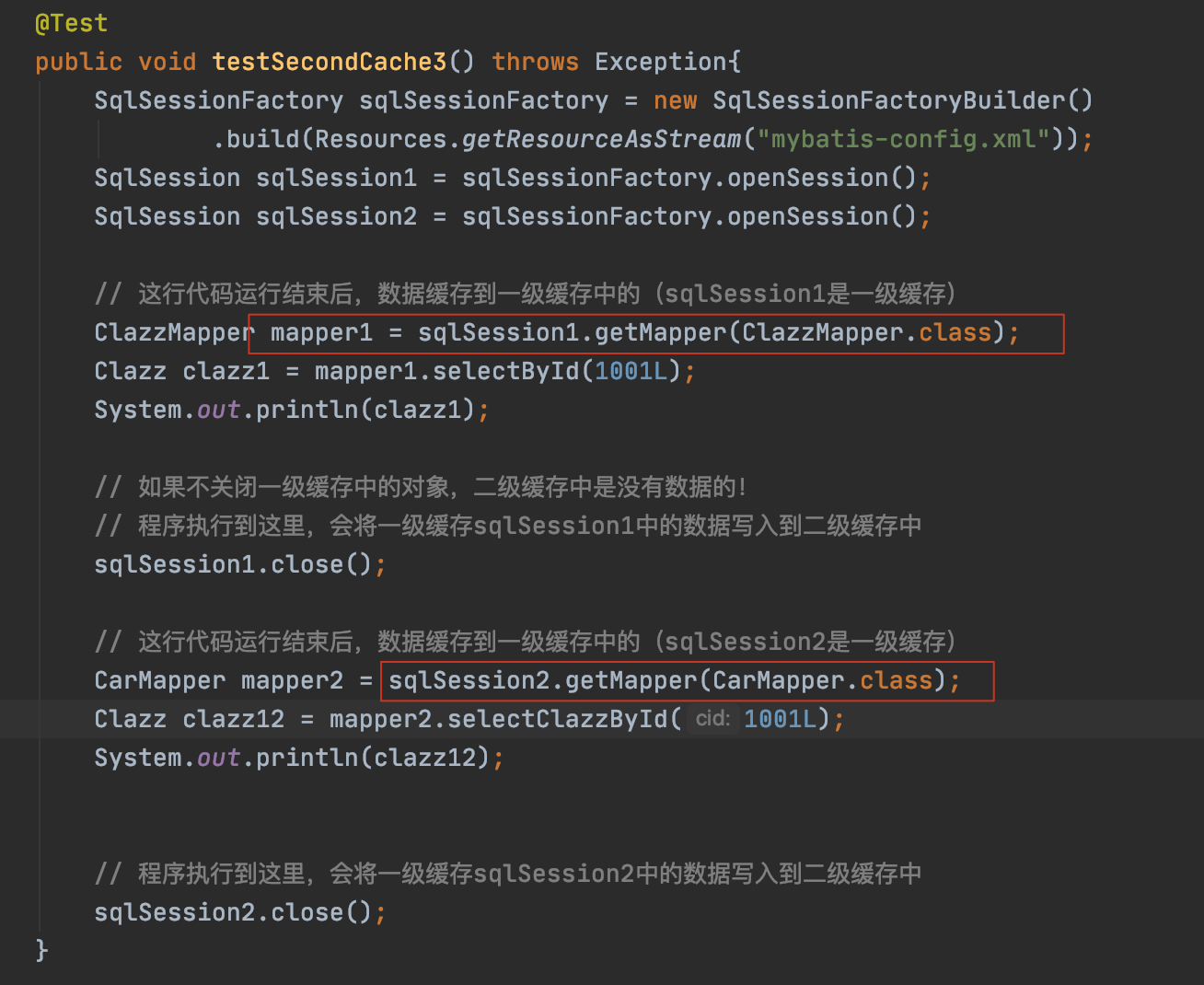
【注意】:
两个mapper不一样,但是执行的select语句和参数都是一样的,但是控制台依旧会执行两条select查询语句,说明二级缓存不能跨namespace!
3-2-5、哪些操作会清空二级缓存?
对该
namespace进行了update/insert/delete(增、删、改)显式调用了
clearCache()配置
<cache flushInterval="..."/>自动过期跨 namespace 无法共享(除非手动自定义)
3-2-6、常见 <cache> 配置项
<cache eviction="LRU" <!-- 缓存淘汰策略:LRU, FIFO, SOFT, WEAK -->flushInterval="60000" <!-- 自动刷新间隔:毫秒;刷新后二级缓存失效 -->size="512" <!-- 最大缓存对象数量 -->readOnly="false" <!-- 是否只读(只读更快但不可修改), car1 == car2 -->blocking="true" <!-- 防止缓存击穿 -->
/>
3-2-7、一级缓存 vs 二级缓存(图解理解)
+------------------------+
| SqlSession A |
| └── 一级缓存(仅自己用) |
| |
| SqlSession B |
| └── 一级缓存(仅自己用) |
+------------------------+↓(关闭 SqlSession 后)
+------------------------+
| 二级缓存(共享) |
| key: SQL + 参数 |
| value: 查询结果对象 |
+------------------------+
3-3、自定义缓存实现(可选)
MyBatis 允许你自定义二级缓存逻辑(如整合 Redis),也就是集成第三方的缓存组件。
【注意】:
MyBatis的一级缓存是不可替代的!集成第三方的缓存组件,替代的是二级缓存!
MyBatis 如何集成第三方缓存组件,比如 Redis、EhCache、Caffeine 等。这种方式可以将 MyBatis 的二级缓存升级为分布式或高性能缓存,实现更强的可扩展性与性能提升。
1、示例:集成EhCache
step1:pom.xml中添加依赖
<!-- MyBatis 对 EhCache 的支持 -->
<dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>1.2.1</version>
</dependency>step2: 添加 ehcache.xml 配置文件
<ehcache><cache name="com.example.mapper.UserMapper"maxEntriesLocalHeap="1000"timeToLiveSeconds="600"/>
</ehcache>step3: 在对应的xxxMapper.xml 中配置:

step4: 编写测试类
测试类和测试二级缓存一样,没有变动!


![[黑马头条]-文章列表加载](http://pic.xiahunao.cn/[黑马头条]-文章列表加载)

的重复使用和db.rollback())



安装 Docker 容器完整教程)



完全指南)
)


![[simdjson] document_stream | iterate_many() | batch_size | 线程加速 | 轻量handle](http://pic.xiahunao.cn/[simdjson] document_stream | iterate_many() | batch_size | 线程加速 | 轻量handle)

- 数据渲染与显示之首页)
