温馨提示:
本篇文章已同步至"AI专题精讲" CPO:对比偏好优化—突破大型语言模型在机器翻译中的性能边界
摘要
中等规模的大型语言模型(LLMs),如参数量为 7B 或 13B 的模型,在机器翻译(MT)任务中展现出良好性能。然而,它们仍未能达到最先进的传统编码器-解码器翻译模型,或是如 GPT-4(OpenAI, 2023)等更大规模 LLM 的表现。在本研究中,我们致力于弥合这一性能差距。我们首先评估了在机器翻译任务中对 LLM 进行有监督微调的局限性,强调即便是人工生成的参考数据也存在质量问题。与模仿参考翻译的有监督微调方式不同,我们提出了一种新方法——对比偏好优化(Contrastive Preference Optimization, CPO),其目标是训练模型避免生成“尚可但不完美”的翻译结果。
我们将 CPO 应用于 ALMA(Xu et al., 2023)模型,仅使用 22K 个平行句对,并仅微调 0.1% 的参数,便获得了显著提升。最终模型名为 ALMA-R,其在 WMT’21、WMT’22 和 WMT’23 测试集上的表现与 WMT 比赛冠军和 GPT-4 相当,甚至更优。
1 引言
当前的机器翻译(MT)系统主要采用 transformer 编码器-解码器架构(Vaswani et al., 2017),这一点在主流模型中得到了体现,例如 NLLB-200(NLLB TEAM et al., 2022)、M2M100(Fan et al., 2021)、BiBERT(Xu et al., 2021)和 MT5(Xue et al., 2021)。然而,随着仅使用解码器的大型语言模型(如 GPT 系列(Brown et al., 2020;OpenAI, 2023)、Mistral(Jiang et al., 2023)、LLaMA 系列(Touvron et al., 2023a; b)、Falcon(Almazrouei et al., 2023)等)在各类 NLP 任务中表现出卓越性能,也引发了人们对使用这类模型进行机器翻译的兴趣。
近期研究(Zhu et al., 2023a;Jiao et al., 2023b;Hendy et al., 2023;Kocmi et al., 2023;Freitag et al., 2023)表明,大型 LLM(如 GPT-3.5(175B)和 GPT-4)具有很强的翻译能力。然而,较小规模的 LLM(7B 或 13B)在性能上仍落后于传统翻译模型(Zhu et al., 2023a)。
因此,已有一些研究致力于提升中等规模 LLM 的翻译能力(Yang et al., 2023;Zeng et al., 2023;Chen et al., 2023;Zhu et al., 2023b;Li et al., 2023;Jiao et al., 2023a;Zhang et al., 2023),但改进幅度相对有限,主要原因在于主流 LLM 的预训练数据大多以英语为中心,语言多样性受限(Xu et al., 2023)。为了解决这一问题,Xu 等人(2023)首先使用大规模非英文的单语数据对 LLaMA-2(Touvron et al., 2023b)进行初步微调,以增强其多语言能力,随后又使用高质量的平行数据进行有监督微调(SFT),指导模型生成翻译。他们所提出的模型 ALMA,在翻译任务中超越了此前所有中等规模的 LLM,甚至优于 GPT-3.5。但其性能仍略逊于 GPT-4 和 WMT 比赛的冠军系统。
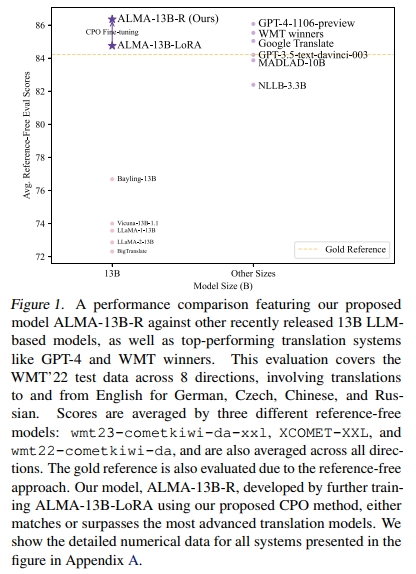
本研究通过我们提出的新训练方法 对比偏好优化(CPO),在极低成本的基础上(仅需 12M 个可学习参数,相当于原模型的 0.1%,以及一个包含 10 个翻译方向的 22K 数据集),进一步对 ALMA 模型进行微调,从而成功弥合了这一差距。该微调模型被称为 ALMA-R,其详细性能比较如图 1 所示。
CPO 旨在缓解有监督微调(SFT)中的两个根本性缺陷。首先,SFT 的训练目标是最小化预测输出与黄金参考之间的差距,这从根本上将模型性能限制在训练数据的质量水平之下。即便是传统上被视为高质量的人工数据,也不可避免地存在问题(详见第 2 节)。例如,如图 1 所示,一些强大的翻译模型有时会生成比黄金参考更优秀的译文。第二,SFT 缺乏一种机制来抑制模型生成“差一点就对”的翻译。当强模型在整体上能生成高质量译文时,有时也会出现遗漏、翻译不全等小错误。防止生成这种“几乎正确但最终有误”的译文至关重要。
为解决上述问题,我们引入 对比偏好优化(CPO) 方法,使用精心构建的偏好数据对 ALMA 模型进行训练。经过 CPO 微调后的模型 ALMA-R 实现了显著性能提升,其翻译质量达到了甚至超过 GPT-4 和 WMT 比赛冠军的水平。
参考译文是真正的“黄金”还是“镀金”?
我们对 ALMA 模型使用的训练数据(FLORES-200 数据集)进行了深入分析,仔细比较了参考译文与强大翻译模型生成的译文之间的质量差异。研究发现,在许多情况下,人工编写的平行语料的质量甚至劣于系统自动生成的译文。这一发现揭示了一个关键问题:仅训练模型去模仿参考译文可能并非最有效的策略,依赖参考译文进行评估也可能存在偏差。
突破有监督微调(SFT)的性能瓶颈
我们提出了一种新的训练方法——对比偏好优化(Contrastive Preference Optimization, CPO)。该方法在内存效率、训练速度和提升翻译质量方面都具有显著优势。CPO 能够打破 SFT 模型模仿式学习过程的性能瓶颈,进一步提升那些已经通过 SFT 达到性能饱和的模型。
偏好数据集
我们构建并公开发布了一个高质量的机器翻译偏好数据集,为后续研究提供了可靠的基础资源。
2. 是黄金还是镀金?审视黄金参考译文的质量
在机器翻译任务中,目标参考译文的重要性至关重要。当前模型训练范式在很大程度上依赖参考译文的质量,因为模型通常通过最小化预测输出与黄金参考之间差异的损失函数进行优化。
设有数据集 DDD,包含源语言句子 xxx 及其对应的目标语言句子(黄金参考)yyy,表示为:
D={(x(i),y(i))}i=1ND = \{(x^{(i)}, y^{(i)})\}_{i=1}^{N} D={(x(i),y(i))}i=1N
其中 NNN 是平行语句对的总数。针对这些平行语句,参数为 θ\thetaθ 的模型 πθ\pi_\thetaπθ 的负对数似然损失定义如下:
LNLL=−E(x,y)∼D[logπθ(y∣x)].(1)\begin{array} { r } { \mathcal { L } _ { \mathrm { N L L } } = - \mathbb { E } _ { ( x , y ) \sim \mathcal { D } } [ \log \pi _ { \theta } ( y \vert x ) ] . } \end{array}\quad(1) LNLL=−E(x,y)∼D[logπθ(y∣x)].(1)
因此,模型能否有效进行翻译,依赖于高质量翻译语句对的可用性(Xu 等,2023;Maillard 等,2023)。此外,当前常用的评估工具如 BLEU(Papineni 等,2002)和 COMET-22(Rei 等,2022)主要依赖基于参考的评估指标。然而,这些评估的准确性容易受到低质量参考译文的影响而下降(Kocmi 等,2023;Freitag 等,2023)。近期研究(Xu 等,2023;Kocmi 等,2023;Freitag 等,2023)已开始关注平行语料质量的评估,指出目标参考译文未必始终代表最高质量。在图 2 中,我们从 FLORES-200 数据集中选取了一个翻译示例,将黄金参考译文与最优的 ALMA 模型及 GPT-4 的翻译结果进行了对比。比较显示该黄金参考译文存在缺陷,遗漏了部分信息,而系统生成的译文则体现出更高的质量。这引发了一个疑问:参考译文(即便是人工撰写的)是否真的等同于“黄金标准”?为了全面评估黄金参考译文与当代高性能翻译模型输出的质量,我们建议采用无参考评估框架对这些译文进行评估。

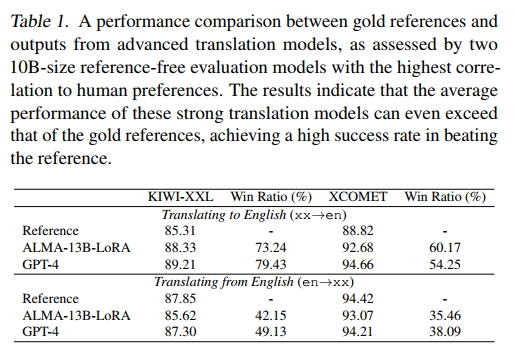
模型 我们对 ALMA-13B-LoRA2 的翻译结果以及最新的 GPT-4(gpt-4-1106-preview)的 zero-shot 翻译进行了深入分析。为评估这些译文的质量,我们采用了两种最新且规模最大的无参考评估模型,它们的参数规模均为 10B,并在与人工评价的一致性方面表现出极高的相关性(Freitag 等,2023)。这两个模型分别是 Unbabel/wmt23-cometkiwi-da-xxl(以下简称 KIWI-XXL)(Rei 等,2023)和 Unbabel/XCOMET-XXL(以下简称 XCOMET)(Guerreiro 等,2023)。
数据 我们使用的是高质量且人工编写的 FLORES-200 数据集(NLLB TEAM 等,2022),包括开发集和测试集,每个语言方向共计 2009 个样本,用于对比黄金参考译文与模型生成的译文。我们使用 ALMA-13B-LoRA 和 GPT-4 对五个以英语为中心的语言对进行翻译,涵盖从英语和翻译到英语的方向。这些语言对包括德语(de)、捷克语(cs)、冰岛语(is)、中文(zh)和俄语(ru),其中冰岛语(is)被归为低资源语言,其余则为高资源语言。
提示词 ALMA 模型生成翻译时所用的提示词与 Xu 等(2023)中所用的一致。GPT-4 的翻译生成则遵循 Hendy 等(2023)提出的建议。这些提示词的具体细节见附录 B。
模型输出可以成为更好的参考译文
在表 1 中,我们展示了 KIWI-XXL 和 XCOMET 对黄金参考译文、ALMA-13B-LoRA 输出以及 GPT-4 输出的评估得分。此外,我们还报告了胜率(Win Ratio),即模型输出优于黄金参考译文的比例。这些指标是五种语言的平均值。值得注意的是,即使是与高质量的 FLORES-200 数据集相比,在 xx→en 翻译方向上,翻译模型的平均表现也明显优于参考译文,在 KIWI-XXL 中提升约 3–4 分,在 XCOMET 中提升约 4–6 分。尤其值得一提的是,KIWI-XXL 评估中,有大量模型输出被评分为优于参考译文(例如 ALMA 为 73.24%),即便是使用 XCOMET 评估,仍有相当比例(如 ALMA 为 60.17%)胜出。在 en→xx 方向上,尽管整体表现与参考译文相当,仍有约 40% 的模型输出被视为优于参考译文。
动机:帮助模型学会拒绝
上述发现表明,先进模型生成的翻译有时可以超越黄金参考译文的质量。这引发了一个问题:如何有效利用这类数据。一种直接的方法是使用源句和更优的译文作为参考对模型进行微调。尽管这种做法可能提升模型的翻译能力,但它并不能教会模型识别和避免生成质量较差的译文,例如图 2 所示那类“不错但不完美”的译文。因此,这种情况促使我们开发一种新的训练目标,旨在指导模型优先生成更高质量的译文,并拒绝较差的译文,采用带有困难负样本的对比学习方式(Oord 等,2018;Chen 等,2020;He 等,2020;Robinson 等,2021;Tan 等,2023)。该目标超越了传统仅最小化参考译文交叉熵损失的范式。
3. 对比偏好优化
为了学习一个既能促进优质翻译又能拒绝劣质翻译的目标函数,获取标注好的偏好数据是关键,但在机器翻译领域中,此类数据非常稀缺。本节首先介绍我们如何构建偏好数据,然后提出一种偏好学习技术——对比偏好优化(CPO)。
3.1 三元组偏好数据
本节详细说明我们构建偏好数据集 DDD 的方法。该数据集基于 FLORES-200 数据(包括开发集和测试集)构建,涵盖第 2 节中提到的相同语言对。对于每一个语言对,数据集包含 2009 个平行句对。
给定一个源句 xxx(无论是从英语翻译还是翻译成英语),我们分别使用 GPT-4 和 ALMA-13B-LoRA 生成对应的译文,分别记为 ygpt-4y_{\text{gpt-4}}ygpt-4 和 yalmay_{\text{alma}}yalma。再加上原始的参考译文 yrefy_{\text{ref}}yref,形成三元组 y=(yref,ygpt-4,yalma)y = (y_{\text{ref}}, y_{\text{gpt-4}}, y_{\text{alma}})y=(yref,ygpt-4,yalma),表示输入 xxx 的三个不同翻译结果。
接着,我们使用无参考评价模型 KIWI-XXL 和 XCOMET 对这些翻译进行打分,取平均分表示为 s=(sref,sgpt-4,salma)s = (s_{\text{ref}}, s_{\text{gpt-4}}, s_{\text{alma}})s=(sref,sgpt-4,salma)。分数最高的译文被标为偏好译文 ywy_wyw,分数最低的译文标为不偏好译文 yly_lyl,即:
- yw=yargmaxi(s)y_w = y_{\arg\max_i(s)}yw=yargmaxi(s)
- yl=yargmini(s)y_l = y_{\arg\min_i(s)}yl=yargmini(s)
其中 iii 是三元组中译文的索引。得分处于中间的译文将不被使用。图 3 展示了该选择过程的一个示意例子。
值得注意的是,即便是被标记为“不偏好”的译文也可能具有较高质量。这个标签仅说明该译文相较于其他候选仍有提升空间,比如缺少细节。这种使用“高质量但不完美”的译文作为负样本的方法,有助于模型学习如何优化细节,从而生成更完美的译文。
3.2 CPO 目标函数的推导
我们从 Direct Preference Optimization(DPO)的分析出发推导 CPO 的目标函数。DPO 是一种直接优化目标,广泛用于人类反馈强化学习(RLHF)任务中(Ziegler et al., 2019;Ouyang et al., 2022;Rafailov et al., 2023)。

给定一组源句 xxx,以及相应的偏好译文 ywy_wyw 和不偏好译文 yly_lyl,我们可以构建一个静态比较数据集:
D={(x(i),yw(i),yl(i))}i=1ND = \{(x^{(i)}, y_w^{(i)}, y_l^{(i)})\}_{i=1}^{N} D={(x(i),yw(i),yl(i))}i=1N
DPO 的损失函数以最大似然的形式定义于参数化策略 πθ\pi_\thetaπθ 上:
L(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))],(2)\begin{array} { r l r } & { } & { \mathcal { L } ( \pi _ { \boldsymbol { \theta } } ; \pi _ { \mathrm { r e f } } ) = - \, \mathbb { E } _ { ( x , y _ { w } , y _ { l } ) \sim \mathcal { D } } \Big [ \log \sigma \Big ( \beta \log \frac { \pi _ { \boldsymbol { \theta } } ( y _ { w } | x ) } { \pi _ { \mathrm { r e f } } ( y _ { w } | x ) } \Big . } \\ & { } & { \Big . \quad \quad \quad - \, \beta \log \frac { \pi _ { \boldsymbol { \theta } } ( y _ { l } | x ) } { \pi _ { \mathrm { r e f } } ( y _ { l } | x ) } \Big ) \Big ] , \quad \quad \quad \quad \quad \quad } \end{array}\quad(2) L(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))],(2)
其中,πref\pi_{\text{ref}}πref 是一个预训练的语言(翻译)模型,σ\sigmaσ 是 Sigmoid 函数,β\betaβ 是一个超参数。DPO 损失函数是通过在 Proximal Policy Optimization(PPO)框架(Schulman et al., 2017)中,对真实奖励和相应最优策略进行重参数化推导而来。因此,DPO 训练可以采用监督微调的方式进行,因为它完全依赖于带偏好标签的数据,不需要智能体与环境之间的交互。
然而,与常规 SFT 相比,DPO 存在显著缺点。首先,DPO 占用内存效率低:它需要同时存储参数化策略和参考策略,这意味着两倍的内存消耗。其次,它运行速度低效:需要对两个策略分别执行模型推理,导致推理时间加倍。为了解决这些效率问题,我们提出了对比偏好优化(Contrastive Preference Optimization, CPO)。
当将 πref\pi_{\text{ref}}πref 设置为均匀先验 UUU 时,可以解决内存和速度上的低效问题,因为此时 πref(yw∣x)\pi_{\text{ref}}(y_w|x)πref(yw∣x) 和 πref(yl∣x)\pi_{\text{ref}}(y_l|x)πref(yl∣x) 两项相互抵消。这样就无需在策略模型之外进行额外的计算和存储。因此,我们首先展示,DPO 损失函数可以使用均匀参考模型进行有效近似:
L(πθ;U)=−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)−βlogπθ(yl∣x))].(3)\begin{array} { r l } & { \mathcal { L } ( \pi _ { \theta } ; U ) = - \operatorname { \mathbb { E } } _ { ( x , y _ { w } , y _ { l } ) \sim \mathcal { D } } \Big [ \log \sigma \Big ( \beta \log \pi _ { \theta } ( y _ { w } | x ) } \\ & { \quad \quad \quad \quad \quad - \beta \log \pi _ { \theta } ( y _ { l } | x ) \Big ) \Big ] . } \end{array}\quad(3) L(πθ;U)=−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)−βlogπθ(yl∣x))].(3)
具体来说,我们在附录 C 中证明了以下定理:
定理 1. 当 πref\pi_{\text{ref}}πref 定义为 πw\pi_wπw,即精确符合真实优选数据分布的理想策略时,DPO 损失 L(πθ;πw)+CL(\pi_\theta; \pi_w) + CL(πθ;πw)+C (其中 CCC 为常数)被 L(πθ;U)L(\pi_\theta; U)L(πθ;U) 上界约束。
式(3)中的近似有效,因为它最小化了 DPO 损失的上界。证明依赖于 πref=πw\pi_{\text{ref}} = \pi_wπref=πw 的重要假设。与通常将 π_ref\pi\_{\text{ref}}π_ref 设为初始 SFT 检查点的做法不同,我们的方法将其视为希望达到的理想策略。虽然理想策略 πw\pi_wπw 在模型训练过程中是未知且不可达的,但经过近似后,πw\pi_wπw 不再参与损失计算。
此外,我们还引入了行为克隆(Behavior Cloning, BC)正则项(Hejna et al., 2023),以确保 πθ\pi_\thetaπθ 不偏离优选数据的分布:
minθL(πθ,U)s.t.E(x,yw)∼D[KL(πw(yw∣x)∣∣πθ(yw∣x))]<ϵ,(4)\begin{array} { r l } & { \underset { \theta } { \operatorname* { m i n } } \, \mathcal { L } ( \pi _ { \theta } , U ) } \\ & { \mathrm { s . t . } \; \mathbb { E } _ { ( x , y _ { w } ) \sim \mathcal { D } } \Big [ \mathbb { K } \mathbb { L } ( \pi _ { w } ( y _ { w } | x ) | | \pi _ { \theta } ( y _ { w } | x ) ) \Big ] < \epsilon , } \end{array}\quad(4) θminL(πθ,U)s.t.E(x,yw)∼D[KL(πw(yw∣x)∣∣πθ(yw∣x))]<ϵ,(4)
温馨提示:
阅读全文请访问"AI深语解构" CPO:对比偏好优化—突破大型语言模型在机器翻译中的性能边界

















+Gitee实现自动化部署)

