前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2024年文章合集最新发布!在这里:再添近20万字-CS的陋室2024年文章合集更新
往期回顾
前沿重器[69] | 源码拆解:deepSearcher动态子查询+循环搜索优化RAG流程
前沿重器[70] | Query优化前沿综述:核心方法解读与个人实战启示
前沿重器[71] Context Engineering深度解读:范式跃迁,还是概念包装
前沿重器[72] 大模型“外脑”揭秘:Context Engineering综述
前沿重器[73] | 深入技术深水区:RAG与Agent如何实现精准个性化
大概半年前,我写了一篇大模型在淘宝电商推荐系统中的应用(前沿重器[59] | 淘宝LLM落地电商推荐实践启示),尽管文章已经比较早,但里面的应用思路还是比较值得参考的,最近淘宝直接写了一篇完整的技术报告,和之前我分享的这篇文章(前沿重器[59] | 淘宝LLM落地电商推荐实践启示)有很多相似之处,然而也针对具体实现做了很多有用的改进,实践性更强,文章详细地讲述了大模型和推荐系统之间的协作,并给出了很多训练和对齐策略,今天就来给大家介绍一下这篇文章。
论文:RecGPT Technical Report
链接:https://arxiv.org/pdf/2507.22879
目录:
聊一聊引言
具体实现
用户兴趣挖掘
商品标签预测
商品搜索
个性化推荐解释生成
人类-LLM协同评判器
实验
个人小结
聊一聊引言
引言中有透露作者在这方向上的研究,所以我还是想讲一讲。
理想的推荐系统应把用户的(通常是隐含的)意图与最相关的商品或内容匹配,让用户以最小的努力获得最大的体验价值,所以其核心的目标便是表征和匹配,之前的核心思路都是通过特征工程和模型架构的优化来实现,而这些优化的核心目标都是通过点击等行为作为媒介来实现的,这种媒介缺少更为深入的理解,只能强化已有行为相关的内容,这会放大信息茧房效应,马太效应,因此迫切需要能突破这种比较浅层的相关性的模式,实现更为深入的用户兴趣理解和挖掘。
没错,说到深层,说到理解,便要说今年以来的大模型了。大模型能基于他的推理能力,分析并推理出用户更为深层的偏好信息,这便是引入大模型的核心逻辑,无论是逐渐替代传统推荐系统中各模块的主要工作,还是直接端到端甚至是生成式的推荐系统,其生效的基点也很大程度在于此。
基于这个核心逻辑,文章构造了一套框架RecGPT,旨在让大模型能真正应用到推荐系统的生产环境中,并带来有效收益。
要想一个东西在某个场景有用,需要尽量理解到,这个东西能解决这个场景下的哪些问题,此时才能真正的有用,强行套用可能是创新,但有没有效,有多大效,就变得并不明确。
具体实现
RecGPT 的核心思想是:在推荐链路的各个阶段引入大语言模型,实现用户兴趣理解、商品预测,并为最终结果生成用户友好的推荐解释。根据这个思想,作者把RecGPT分为4个模块。
用户兴趣挖掘。对用户的终身多行为序列进行显式兴趣挖掘,以识别多样化的用户兴趣模式。
商品标签预测。基于用户兴趣挖掘结果,预测代表用户潜在偏好分布的商品标签。
商品检索。标签感知语义检索方法将预测标签映射到具体商品,同时引入用户行为协同信号,平衡语义与协同相关性。
推荐解释生成。综合用户兴趣与推荐商品,生成贴近个体用户偏好的个性化、友好解释,提升系统透明度与用户体验。
这个流程设计有两个优势。
可对各阶段中间过程及模型性能进行可解释监控。
可通过过程级监督引入专家知识,实现对各组件的有针对性优化。
用户兴趣挖掘
传统的用户画像建模基本是使用固定、统计的隐式用户特征,难以形成显式、动态的兴趣,而生成式用户画像(Generative User Profiling)可以解决这个问题。
但是生成式用户画像会面临两个难题。
上下文窗口限制。推荐系统的用户行为多样且复杂,大模型并不能吃下超长序列。对此,文章开发了可靠行为序列压缩(Reliable Behavioral Sequence Compression),保留关键信息。
领域知识缺口。这个可以通过多阶段任务对齐框架来补充领域知识。
可靠行为序列压缩主要有几个流程。
可靠行为提取。关注高参与度的意图反馈行为,如“收藏”、“购买”、“加购”,以及主动性强的行为,如“搜索查询”,而不关注点击这种噪音比较多的行为。
分层行为压缩。对超长用户序列,将多源异构行为压缩为统一序列格式,商品主要保留商品名称、类别、品牌等核心属性,序列级根据不同时间段进行聚合。
为增强用户兴趣大模型在兴趣挖掘任务上的能力,此处使用了多阶段任务对齐,分阶段训练出和人类对齐的兴趣模型。
设计16个预备子任务,增强通用 LLM 在领域基础上的关键能力,如关键信息提取、复杂用户画像分析、因果推理等。受课程学习启发,按难度与依赖关系拓扑排序子任务,逐步引导模型掌握复杂任务。
推理增强预对齐。利用DeepSeek-R1的先进推理能力生成高质量兴趣挖掘训练数据,经人工精心筛选,将初始 9.0 万样本精炼为 1.9 万高质量数据集,用于知识蒸馏。
自训练演化。为进一步提升模型能力上限,我们提出自训练范式,模型自我生成训练数据并用于迭代优化,形成能力增强反馈环。为高效过滤自生成输出并低成本评估模型性能,采用人类-LLM协同范式,利用LLM-as-a-Judge能力进行数据质量管理与评估,显著提升整理效率并降低人工标注成本。
这里有个细节,如何避免大模型的幻觉问题,这里进行了多维度的拒绝采样。
意愿性:兴趣是否真实反映用户自发性偏好,而非外部义务。
合理性:兴趣是否有充分行为证据支持,分为强相关、弱相关、无相关、幻觉四类。
至于部署上,离线使用模型预测用户兴趣偏好,平均每用户预测 16.1 个兴趣。在线部署中,每两周迭代优化模型并刷新用户兴趣,确保兴趣时效性并精准捕捉用户个性化动态变化。
商品标签预测
标题是简单的,但实际的任务和标题存在偏差:利用大语言模型基于推断出的用户画像指导商品标签预测。注意,用户画像指导的商品预测标签,后续是需要进行搜索的,因此这里让两者的语义空间尽可能接近,这样后续的检索就会更简单。这里的思路是,首先对商品标签进行多阶段任务对齐,确保其有效理解商品相关上下文,然后接着引入增量学习方法,使模型持续适应用户兴趣与新品趋势。
首先是商品标签预测任务对齐,这里的对齐,是要增强大模型对商品的理解能力,强化大模型在应用于个性化商品预测任务时,在领域需求差异中的体现能力。这里比较突出的一点是提示词的设计。提示中会引入以下约束,通过这些多约束提示,大模型会输出(标签,关联兴趣,理由)三元组列表,用于后续商品检索。
兴趣一致性:标签与用户兴趣保持对齐。
多样性:至少生成 50 个标签,保证跨类目多样性。
语义精度:避免模糊或过于宽泛描述。
时效性:优先新品,避免近一月已交互商品。
季节性:结合时间戳生成季节相关标签。
当然,这一步也需要考虑幻觉和噪音的问题,这里引入多维度拒绝采样,评估标准包括相关性、一致性、具体性、有效性。仅当标签满足所有标准时才视为合格样本,否则标记为不合格。
然后是增量学习,这是为适应在线环境中用户兴趣与数据分布的动态变化(如季节变化),文章采用每两周一次的增量学习。每次更新周期内,选取过去 14 天用户在线交互记录(点击、购买等)作为增量训练数据源。
但这里,真实数据会存在两大挑战:一个是噪声(如误点击、促销假象),另一个是固有不平衡,主导兴趣标签可能倾斜训练,降低多样性并加剧马太效应。这里,在数据处理上,采取了3个措施。
数据净化。依据相关性与时效性标准,使用 QwQ-32B 作为自动评判器进行数据清洗。相关性分析行为与兴趣一致性,滤除低质量记录;时效性判断商品是否适合当前或即将到来的季节。
兴趣补全。将有效交互映射为(标签,关联兴趣,理由)三元组。使用QwQ-32B基于用户画像、历史行为与需求提示进行深度推理,推断底层兴趣偏好及理由。商品标题直接作为标签,从而将行为数据转化为结构化训练样本。
数据平衡。设计两阶段重采样策略:首先每用户随机选取 80 个商品标签对应行为记录,保证多样性;其次使用预训练Tag-to-Cate模型将标签映射为类目,按类目二次采样(每类最多 2 样本),实现类别平衡。
商品搜索
大模型生成的标签,虽然能提供丰富的语义信息,但是这个抽象的语义无法映射到对应的目标商品,因此,需要引入标签感知方法,同时整合了协同过滤机制,提出统一的用户-商品-标签检索框架,协同增强语义推理与协同行为洞察,最终提升在线推荐系统的准确性与效率。
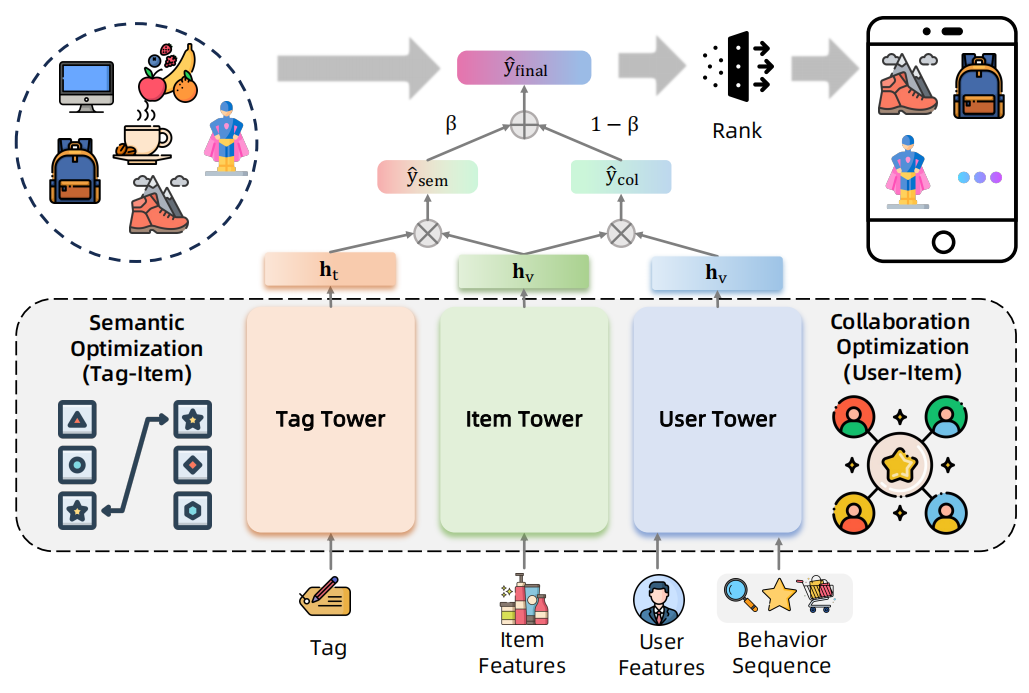
商品塔内是稀疏类别特征(ID、类目、品牌等)与连续数值特征(价格、销量等),用户塔内通过多行为序列建模捕捉用户偏好,输入包括用户 ID 与多行为交互序列(点击、购买等),标签塔将商品标签分词后取均值池化。
这个模型会形成连个分数,标签和商品的语义分数,用户和商品的协同分数,优化也会分这两个分别进行优化,协同优化师最大化正样本用户-商品交互似然,最小化负样本似然,语义优化则是最大化基于用户偏好生成的标签与商品间语义相关性。
然后推理的话,动态融合用户塔与标签塔输出,实现可控的协同-语义推荐,然后就可以去召回商品,这个训练出来的模型能兼顾相关性与语义一致性。
个性化推荐解释生成
最后一步是给用户解释为什么要给他推荐这个。这一步的重点是任务对齐与离线生产策略。
任务对齐需要经过两阶段训练,首先使用DeepSeek-R1生成的推理增强数据集进行预对齐(推理增强预对齐),随后在自生成数据上进行训练,数据经人类或 LLM 评判器严格过滤(自训练演化),最终实现与人类对齐的解释生成性能。
提示工程上,给定用户兴趣与推荐商品信息(标题、标签等),执行两步生成合理推荐解释:
上下文理解:分析输入信息,理解用户兴趣与商品特征。
解释生成:若商品与用户兴趣存在合理关联,则生成对话风格短语呈现关联;否则则基于商品本身特征生成解释。
风格层面,提示模板要求解释风格简洁、有趣、网络化,禁止夸大、虚假、套话、重复标题等。
这个解释生成可以说是非常真实了,在内容可解释时则直接解释两者的关联,但是出现一些偶然情况,如库内没有,或者是显式匹配度不足时,可以考虑直接解释商品本身的特征,例如比较普适的优点。
然而,每个内容都进行详细解释,在在线环境下肯定不现实,耗时撑不住,因此需要用离线的方式进行。从用户兴趣出发,利用已收集的标签-兴趣关联对,将商品标签映射至对应类目,建立用户兴趣与商品类目间的关联,此时就只对兴趣-商品生成解释,而不需要考虑用户和所有商品的排列组合,生成后建表记录,在线推荐时,通过当前推荐商品与用户兴趣匹配,直接查表获取预生成解释,实现毫秒级实时解释返回。
人类-LLM协同评判器
前文有大量提到需要进行样本筛选、模型训练等工作,这里需要对DeepSeek-R1或自训练模型生成的样本进行人工筛选,以对齐人类标准,受“LLM-as-a-Judge”在各类自然语言理解与生成任务中优异表现的启发,我们采用该范式,让LLM担任智能评判器,实现自动化评估,从而降低成本、提高效率。(有关这块的研究,我曾经写过一篇综述的解读:前沿重器[65] | 大模型评判能力综述)
但此处,存在两个比较大的挑战。
认知偏差:说白了,人对用户偏好的理解和大模型的理解并不对齐。
时间错位:推荐生态的动态性导致静态LLM评判器与不断演化的真实条件失配。主要是对用户行为模式的演化、商品特征的动态变化、评价标准的更新不够灵敏。
这些动态因素累积削弱静态LLM评判器的评估能力,引入系统偏差,因此文章提出了人类-LLM协同评判系统(Human-LLM Cooperative Judge System),其核心思想是人类专家与LLM评判器的协同合作,在重大版本更新时引入人类在环监督,实时对齐演化数据分布与任务需求,这里有两个关键任务,LLM-as-a-Judge与Human-in-the-Loop。
LLM-as-a-Judge中,需要构造人类标注的评估数据集用于LLM指令微调,这里主要是两块数据,一块是二分类评估(相关性好坏)、另一块是多级评估(真实性好中差)。数据的来源是DeepSeek-R1在预对齐阶段生成的推理增强数据和任务专用LLM在自训练迭代中自生成的样本,这些是需要人工标注的。另外,由于都是分类问题,因此需要留意样本均衡的问题,对少数类需要需要做额外的人工标注增加,也需要通过时间衰减策略优先保留最新评估样本。
但是,LLM-as-a-Judge的可靠性会因为因动态数据分布漂移而面临挑战,在面对新商品、新特征的时候会失效,因此本文在每个重要版本更新的过程中,收集专家对近期生成样本的标注,同时系统对比LLM评判结果与人工评估,当性能显著下降时,使用新标注数据对LLM评判器进行持续微调,这便是Human-in-the-Loop的过程。
这里,借助LLM-as-a-Judge和Human-in-the-Loop两者协同,能持续和演化的系统保持对齐,维持持续运营,但这里毫无疑问,无论是标注人力还是训练资源,这个成本都不小。
实验
推荐系统核心关注的还是业务指标,就是在线用户的停留、成交等信息,因此都是做的AB实验。
评价指标上,用户体验选择的是停留时长、曝光多样性和停留多样性,平台收益则是上面页面浏览量、点击率、点击日活、和加购数。结果显示多个方面的指标均有不同程度的提升,这个全面提升还挺少见的。
另外作者还做了深入的案例分析以及用户调研,这个我就不赘述了。
有个遗憾,论文本身是一个完整的框架,内部很多部分都可以拆解应用到原有的推荐系统中的,消融实验在这里做的并不完善。
个人小结
这篇文章相比最近比较火的生成式推荐,还是比较保守的,每一步都做了专门的设计,也很符合推荐系统上的模块拆解。简单聊聊我自己觉得这套方案的优势吧。
因为是模块化设计,支持每个模块独立优化,效果监控比较方便,后续的上限也可以分批分点上,再一点是,推荐系统中用户和物料之间是存在更新的gap,两者隔离,各自的更新解耦,最终整个系统的可维护性也会比较强。
可实操性和可解释性更强,真正意义的结合了用户和商品的显式理解,充分发挥大模型自身优势的同时,保留推荐系统原有信息和特征信息。
考虑到了冷启动问题。对新产品、新用户也有兼容。
考虑到了性能问题。现在大模型的核心压力主要在文本生成,尤其是长文本层面的压力,本文在推荐解释那个部分,提供了一种提前计算缓存的模式,有效把在线的问题降级为了离线完成的问题。


的崛起——为什么“会写Prompt”成了新技能?)

)


)












