计算机的世界只有0和1。
1.1 进制
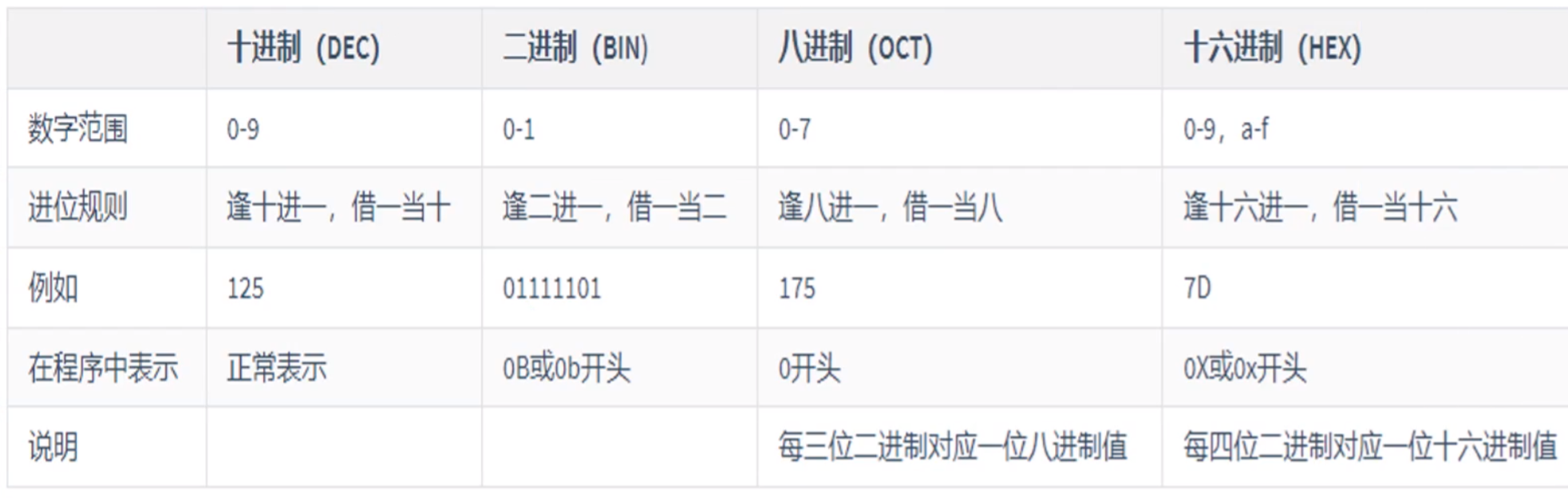
- 十进制整数->二进制整数:除2倒取余
- 二进制->十进制:权值相加法
-
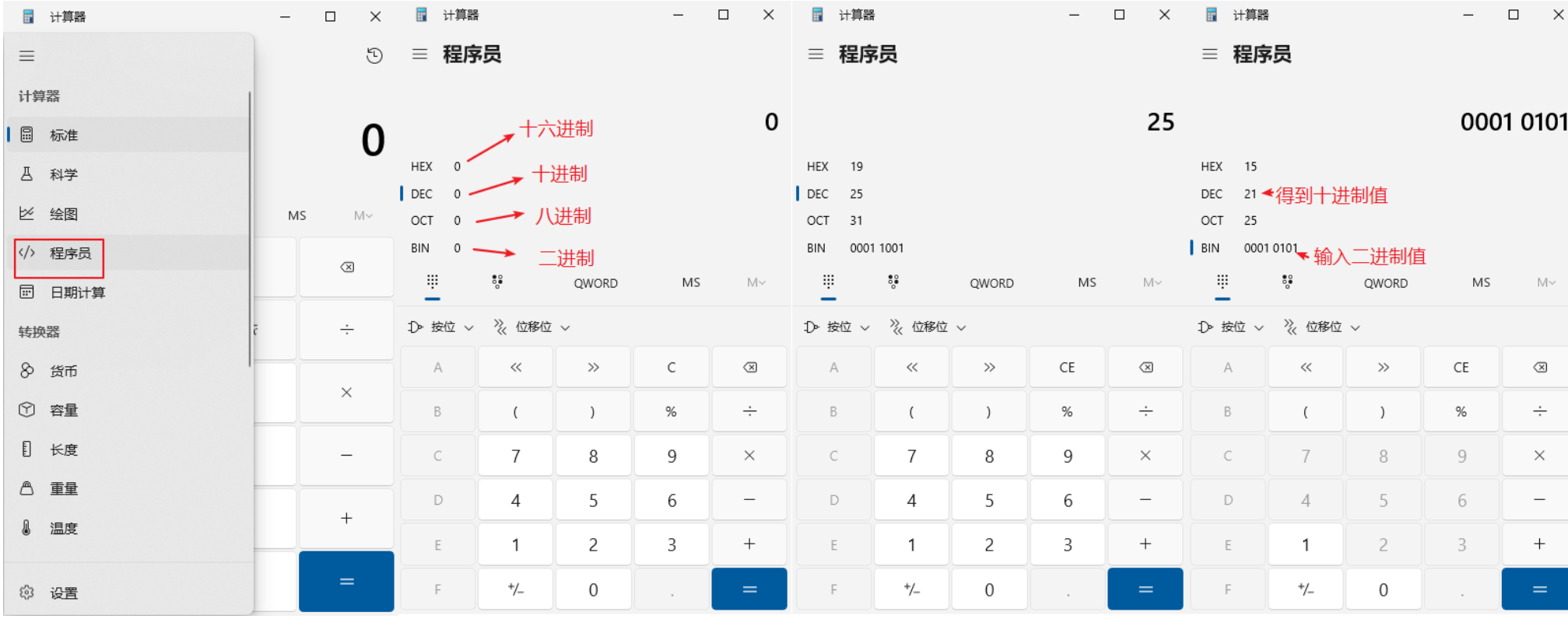
- 结论:1位8进制值 = 3位二进制值,1位十六进制值 = 4位二进制值
public class JinZhiDemo {public static void main(String[] args) {System.out.println(10);//十进制System.out.println(0B10);//二进制,输出的是十进制结果System.out.println(010);//八进制,输出的是十进制结果System.out.println(0x10);//十六进制,输出的是十进制结果System.out.println(25);//十进制//System.out.println(0B25);//二进制,错误,二进制只有0-1System.out.println(025);//八进制System.out.println(0x25);//十六进制}
}1.2 符号位、原码、反码、补码(理解)
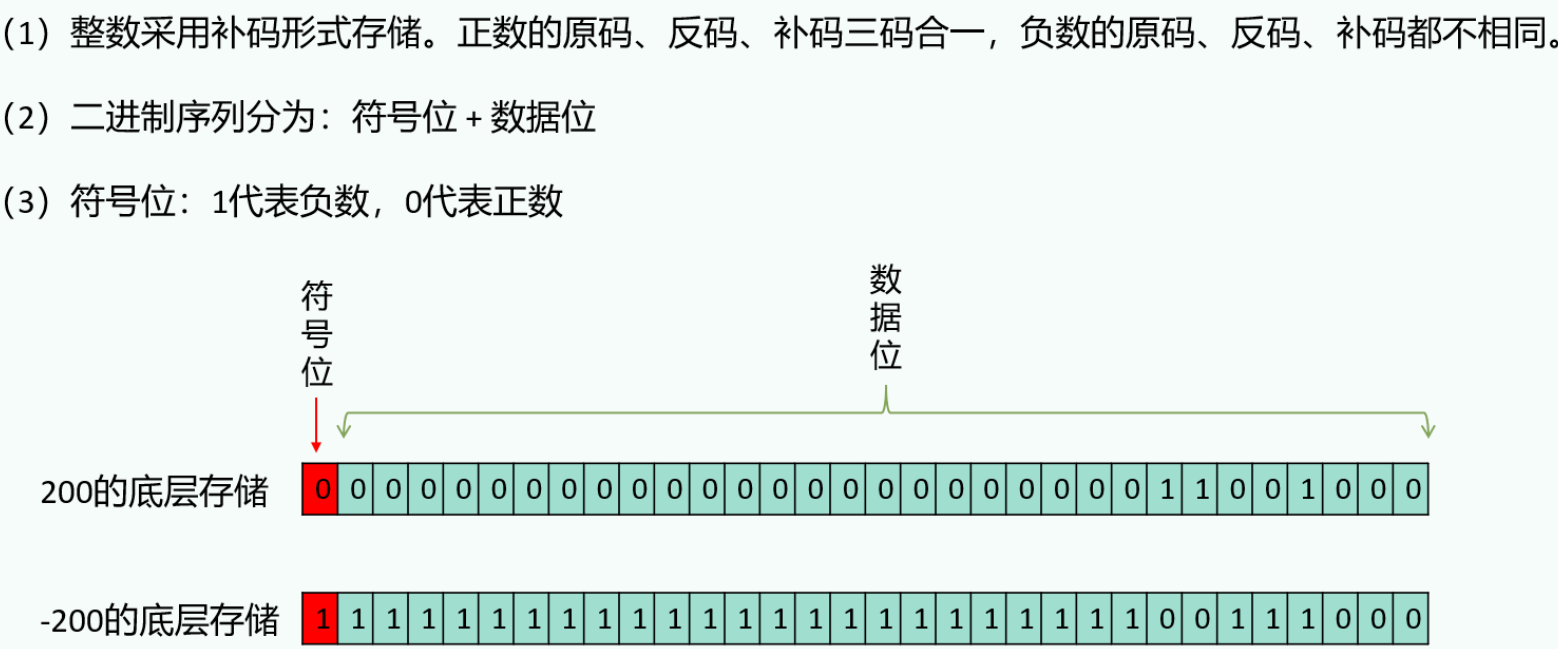
- 符号位:最高位,表示正负。0代表正数,1代表负数
- 原码:最直观的二进制表示法:符号位加上真值的绝对值。+25:
0001 1001,-25:1001 1001。 - 反码、补码
-
- 正数:反码、补码与原码一样。
- 负数的反码:原码的符号位不变,数值位按位取反(0变1,1变0)
-
- 负数的补码:反码加1
在Java中的整数类型(byte, short, int, long)均采用补码表示
1.2.1 为什么使用补码?
直接说结论:
原码的主要缺陷有:
- 存在两种零:+0( 0000 0000) 和 -0( 1000 0000),浪费了一个二进制组合,并且在逻辑上是冗余的。
- 加减运算复杂:符号位不能直接参与运算,需要根据符号位进行额外判断(正数和负数相加需要取绝对值大者的符号),硬件实现效率低下。
原码的加法运算:
原码虽然是最直观的二进制表示,但是用原码进行运算时会存在致命的缺陷(eg (+25) + (-25)得不到0)。
→原码的加法不支持符号修正:不能自动让结果的符号与数值正确对应,并且不支持进位消除(多出的进位被丢弃,不影响结果)
一个字节为例的二进制值原码加法:
+25: 0001 1001
-25: 1001 1001
+-----------------1011 0010 -50(错误)-5: 1000 0101
-5: 1000 0101 (-5)
+ -----------------1 0000 1010 结果为 10(注意:最高位溢出了1位舍弃)符号位不仅仅要用来表示正、负数,还要考虑计算问题。补码的优势在于:
- 统一零的表示:0的补码只有一种形式,即 0000 0000。
- 简化硬件设计:减法运算可以转换为加法运算( A - B = A + (-B)),CPU只需一套加法电路即可处理加减法,硬件实现高效简单。
- 自然处理溢出:运算时产生的进位可以直接舍弃,不影响结果的正确性( eg(+25) + (-25)舍弃进位后得到0。
- 反码:试图改进运算,仍有双零和循环进位问题(历史概念)
- Java实践:
byte,short,int,long均用补码。Integer.toBinaryString()可查看补码形式.
1.3 计算机存储单元
最小单位:1位,一个比特位,bit,它只有0和1。
最基本的单位:字节,Byte,1B = 8bit。字节是数据存储和寻址的基本单元,例如一个英文字符通常占用1个字节,而一个中文字符通常占用2个字节。
// Java内部使用Unicode编码
char c = 'A'; // 英文字符,1个char单位(2字节)
char ch = '中'; // 中文字符,1个char单位(2字节)// 但转换为字节数组时,取决于编码方式
String str = "A中";
byte[] utf8Bytes = str.getBytes("UTF-8"); // A占1字节,中占3字节
byte[] gbkBytes = str.getBytes("GBK"); // A占1字节,中占2字节- 1 KB(Kilobyte,千字节) = 1024 Byte
- 1 MB(Megabyte,兆字节) = 1024 KB
- 1 GB(Gigabyte,吉字节) = 1024 MB
- 1 TB(Terabyte,太字节) = 1024 GB
- 1 PB(Petabyte,拍字节) = 1024 TB
- 1 EB(Exabyte,艾字节) = 1024 PB
- 1 ZB(Zettabyte,泽字节) = 1024 EB
PS:带宽
(1)带宽:100Mb = 100/8MB
(2)硬盘等硬件 1TB 实际会少于1TB:工业上硬盘制造商有时会使用 用1000代替1024进行进制换算(1GB = 1000MB),导致操作系统中识别的可用空间略小于标称值。
为了便于内存管理,不同虚拟机实现不一样,很多虚拟机会给一个boolean的变量分配1个字节。
面试题:
boolean的宽度是多少?
- boolean类型的值true和false底层就是用1和0表示,1代表true,0代表false。
- 理论上1个比特位就够了,但是实际中,大多数JVM实现(如HotSpot)为每个
boolean变量分配1个字节(8位)。因为计算机中通常以字节为最小寻址单位,按字节处理效率更高。在数组(如boolean[])中,JVM可能会进行优化,尝试使用1位来表示每个元素。
1.4 不同数据类型的存储
宽度:不同数据类型的宽度(字节数)不同,与它们的取值范围直接相关。对于整数类型,其取值范围由位数和补码表示法决定。
| 数据类型 | 内存占用(字节) |
| byte | 1个字节 |
| short | 2个字节 |
| int | 4个字节 |
| long | 8个字节 |
| float | 4个字节 |
| double | 8个字节 |
| char | 2个字节 |
1.5 一个字节可以表示多大数字
1个字节可以表示的范围是 -128 ~ 127
同理:对于一个有符号整数类型,其位数(n bits)和取值范围的关系是:
最小值:−2^(n−1)
最大值:2^(n−1) −1
补码:
正数:0000 0001 十进制10111 1111 十进制127
负数:1000 0001 十进制-127 补码:1000 0001反码:1000 0000原码:1111 11111111 1111 十进制:-1补码:1111 1111反码:1111 1110原码:1000 0001
两个特殊值:0000 0000 十进制:01000 0000 十进制:-128 最高位是1,肯定是负数,还要满足计算规则-127: 补码 1000 0001
1 : 补码 0000 0001
相减 ------------------ 补码:1000 0000 (十进制-128)数学中 -127 -1 = -128public class IntegerStorageDemo {public static void main(String[] args) {// 1. 验证byte范围byte minByte = Byte.MIN_VALUE; // -128byte maxByte = Byte.MAX_VALUE; // 127System.out.println("Byte Range: " + minByte + " to " + maxByte);// 2. 查看-128的补码 (1000 0000)// 将byte转换为int并掩码最低8位,以查看其二进制表示System.out.println("-128 (byte) 的补码: " +String.format("%8s", Integer.toBinaryString(minByte & 0xFF)).replace(' ', '0'));// 3. 验证运算:(-127) + (-1) = -128byte b1 = -127;byte b2 = -1;byte sum = (byte) (b1 + b2); // 需要强制转换,因为byte运算会提升为intSystem.out.println("(-127) + (-1) = " + sum); // 输出: -128// 4. 验证int的默认性long longNum = 10000000000L; // 必须加L,否则100亿这个int字面量已超出int范围,编译报错。System.out.println("Big Long Number: " + longNum);}
}Byte Range: -128 to 127
-128 (byte) 的补码: 10000000
(-127) + (-1) = -128
Big Long Number: 100000000001.6 整数的存储范围(记byte、short)
整数存储:
| 数据类型 | 关键字 | 内存占用 | 取值范围 | 备注 |
| byte |
| 1字节 | -128 ~ 127 | 1. 范围计算:
|
| short |
| 2字节 | -32,768 ~ 32,767 | 1. 范围计算:
。 |
| int |
| 4字节 | -2,147,483,648 ~ 2,147,483,647 (约±21亿) | 1. 默认类型:Java中整数字变量默认是 |
| long |
| 8字节 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 1. 字面量:使用时需在数字后加 |
面试题:Q: byte b = 200;这句代码能否通过编译?为什么?
A: 不能。编译错误“不兼容的类型: 从int转换到byte可能会有损失”。因为整数字面量 200默认是 int类型,而其值 200超出了 byte的范围 (-128~127)。必须进行强制类型转换:byte b = (byte) 200;,但转换后值会溢出,不再是200。
面试题:Integer.MIN_VALUE的绝对值为什么还是负数?
A: 这是一个经典的溢出陷阱。Math.abs(Integer.MIN_VALUE)的结果仍是 Integer.MIN_VALUE。因为32位补码能表示的最大正数是 2^31 - 1(即 Integer.MAX_VALUE),而 Integer.MIN_VALUE是 -2^31。它的绝对值 2^31超出了 int的正数表示范围,导致运算溢出,结果又回到了负数区间。
Q: 基本类型 int和包装类 Integer的区别?自动装箱/拆箱的原理?
int是基本数据类型,存储的是值本身,存放在栈(局部变量)或堆(成员变量)中。
Integer是对象,是 int的包装类,实例存储在堆中。
自动装箱(Autoboxing): Integer i = 10;-> 编译器自动转换为 Integer i = Integer.valueOf(10);
自动拆箱(Unboxing): int n = i;-> 编译器自动转换为 int n = i.intValue();
缓存机制: Integer.valueOf()方法会缓存 -128 到 127 之间的对象。
Integer a = 127;
Integer b = 127;
System.out.println(a == b); // true, 因为取自缓存,是同一个对象Integer c = 128;
Integer d = 128;
System.out.println(c == d);// false, 超出缓存范围,new了新对象
System.out.println(c.equals(d)); // true, 比较的是值比较包装类对象时,总是使用 .equals()而不是 ==。
自动拆箱、装箱的原理与作用
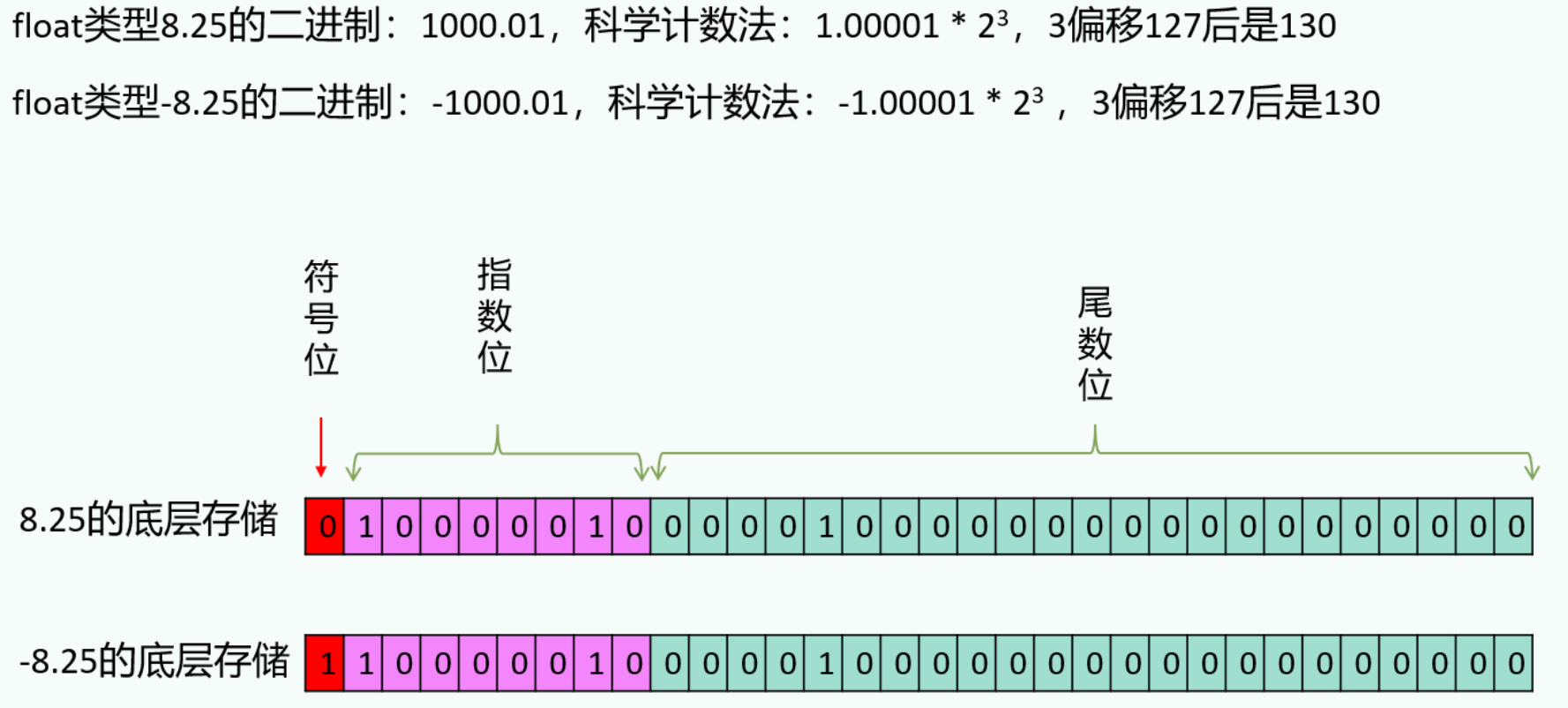
1.7 小数存储范围(记结论)
结论:
1、4个字节float比8个字节long类型的存储范围大。
2、float和double都是浮点型,不精确。
3、double的精度大约是十进制科学计数法小数点后15-16位,float是7-8位。
浮点数:

1.8 char类型
char类型的字符底层也是用二进制表示。每一个char都对应一个整数值,然后底层存的是这个整数值的二进制。规定char对应整数值的表称为字符集。
最早的字符集:ASCII码字符集,最早规定127个字符。
'0' : 48 '1':49
‘A': 65 'B':66
'a': 97 'b':98当计算机传到欧洲的时候,超出了ASCII表的范围,它们动起了心思,把ASCII码表127之后的编码值利用起来,但是它们无法通用,每个国家不同一样。当计算机传到亚洲的时候,ASCII完全不够用,大陆地区最新用GB2312,现在改为GBK字符集。当一个程序或一个文档中同时出现多个国家的文字,就麻烦了,必须出一个万国码,能同时表示全世界所有国家的常用文字。它就是unicode字符集。
Java目前在JVM中采用的就是unicode字符集。字符编码的范围是 0- 65535。编码值没有负数。
char本质是整数,它可以和 int进行各种运算。
制表位Tab:'\t'
删除键Backspace:'\b'
回车键:'\r'
换行键:'\n'
单引号:'\''
双引号:'\"'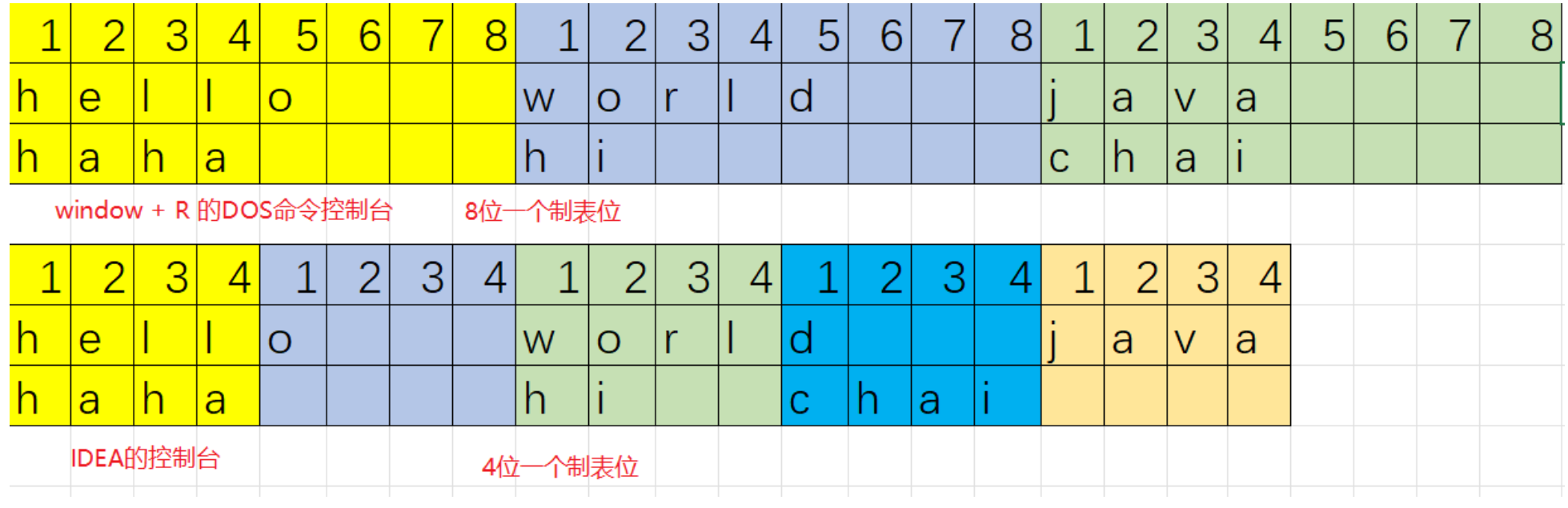



)










)




)