🐯猫头虎荐研|腾讯开源长篇叙事音频生成模型 AudioStory:统一模型,让 AI 会讲故事
大家好,我是猫头虎 🐯🦉,又来给大家推荐新鲜出炉的 AI 开源项目!
这次要聊的是腾讯 ARC Lab 最近开源的一个相当炸裂的模型 —— AudioStory。
一句话总结:它能把文本、视频,甚至已有音频,变成 长篇、完整、有情绪、有逻辑的音频故事。
👉 有声小说、动画配音、长音频叙事,全都不在话下。
文章目录
- 🐯猫头虎荐研|腾讯开源长篇叙事音频生成模型 **AudioStory**:统一模型,让 AI 会讲故事
- ✨ 为什么值得关注?
- 📖 它能做什么?
- 1️⃣ 视频配音(Video Dubbing)
- 2️⃣ 文本转长篇音频(Text-to-Long Audio)
- 3️⃣ 音频续写(Audio Continuation)
- 🧩 技术原理
- ⚙️ 安装与上手
- 📊 实验结果
- 🔋 致谢与生态
- 🐯猫头虎点评
✨ 为什么值得关注?
我们先来看看痛点。
传统的 Text-to-Audio (TTA) 技术,的确能生成短音频,但要做长篇叙事就会遇到三大难题:
- 场景割裂 —— 一会儿是森林,一会儿是都市,过渡生硬;
- 情绪漂移 —— 上一秒还在悲伤,下一秒突然变嗨,完全不连贯;
- 模块割裂 —— 大多数方案要把理解、生成、后处理拆成好几个流水线模块,工程复杂,效果还经常对不上。
而 AudioStory 的厉害之处在于:
它是一个 统一模型,把 指令理解 + 音频生成 + 跨场景一致性 全部揉在一起。
这意味着它不仅能生成自然过渡的叙事音频,还能稳住整体基调和情感,效果远超扩散模型或 LLM+扩散的组合。
研究团队也拿出了数据:在 FD (Fréchet Distance) 和 FAD (Fréchet Audio Distance) 两个关键指标上,AudioStory 的表现全面优于基线模型。
📖 它能做什么?
AudioStory 提供了三大核心能力:
1️⃣ 视频配音(Video Dubbing)
像 Tom & Jerry 这样的动画片,你只需要给出视觉字幕,AudioStory 就能自动生成拟声和对白。
它还能跨域泛化,比如 Snoopy、哪吒、Donald Duck、熊出没 风格全都能玩。
换句话说:你给它一个视频,模型能自动加上“活灵活现的声音轨”。
2️⃣ 文本转长篇音频(Text-to-Long Audio)
和普通的 TTS 不一样,它能把你的文本变成 完整的场景叙事。
示例指令:
生成一段完整音频:Jake Shimabukuro 在录音室弹奏复杂的尤克里里曲目,获得掌声,并在采访中讨论职业生涯。总时长 49.9 秒。
生成结果包含:演奏声 🎶 + 环境声 🌌 + 掌声 👏 + 采访 🎤 —— 全流程沉浸式叙事。
3️⃣ 音频续写(Audio Continuation)
给定一段已有音频,AudioStory 能理解上下文,并自然衔接后续。
例如:输入一段篮球教练训练的录音,模型能生成教练继续讲解战术的音频。
就像 GPT 写小说的续写,但对象换成了音频流。
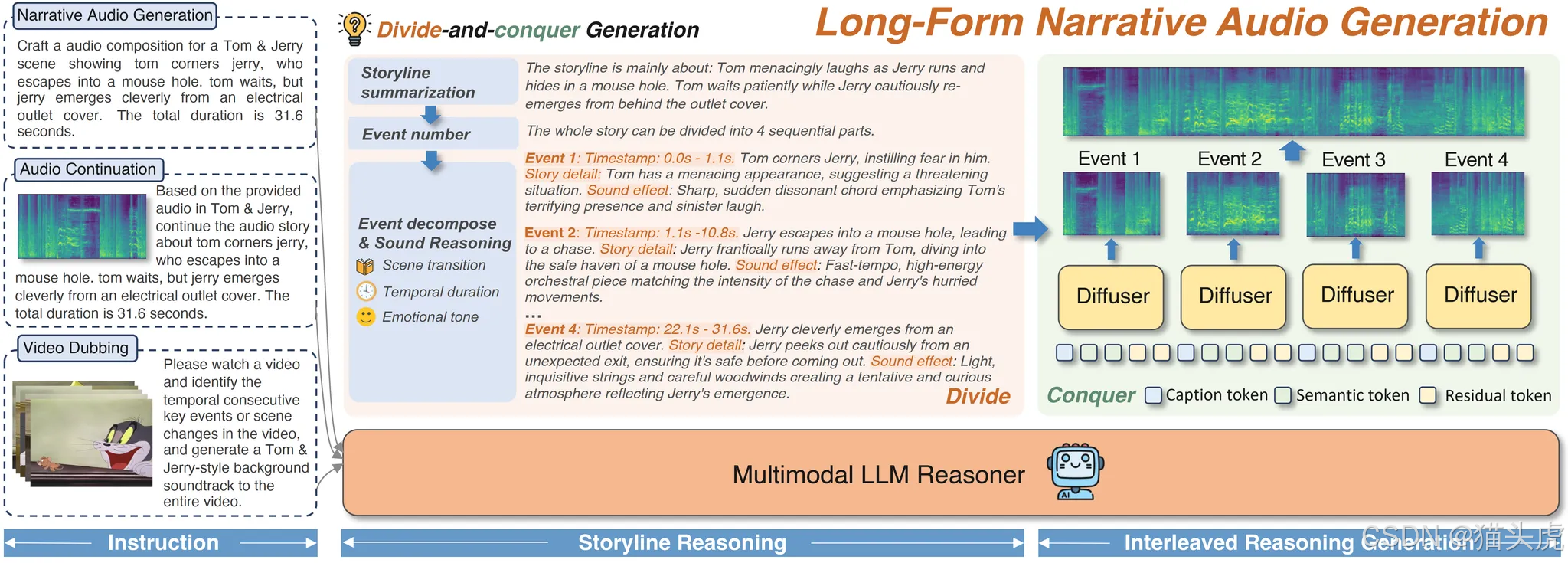
🧩 技术原理
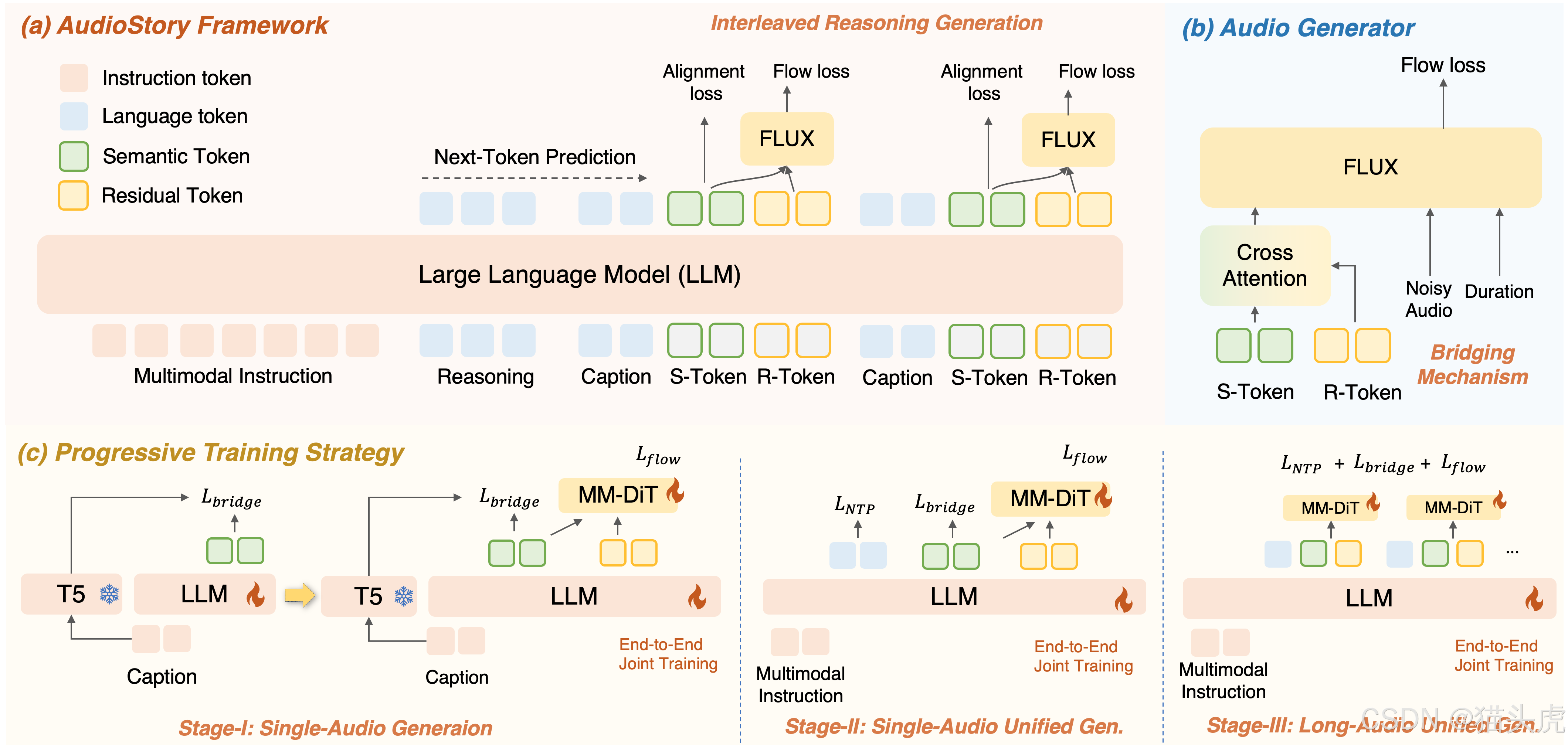
核心架构是一个 理解–生成统一框架:
-
输入理解
- LLM 先对输入(文本 / 音频 / 视频字幕)进行分析,拆解为有逻辑顺序的 子事件。
-
推理生成
- 每个子事件由 LLM 生成 描述字幕 (captions)、语义 token 和 残余 token;
- 这些 token 被送进 DiT(Diffusion Transformer),合成高保真音频片段。
-
一致性机制
- Bridging Query:保持单场景内部的语义稳定;
- Consistency Query:确保跨场景的情感和叙事基调统一。
最终效果:情绪和过渡都自然得像真人配音师。
⚙️ 安装与上手
项目已开源在 GitHub,环境配置很友好:
git clone https://github.com/TencentARC/AudioStory.git
cd AudioStory
conda create -n audiostory python=3.10 -y
conda activate audiostory
bash install_audiostory.sh
推理示例:
python evaluate/inference.py \--model_path ckpt/audiostory-3B \--guidance 4.0 \--save_folder_name audiostory \--total_duration 50
依赖环境:
- Python >= 3.10
- PyTorch >= 2.1.0
- NVIDIA GPU + CUDA
📊 实验结果
团队在多任务测试中给出了硬指标:
- FD/FAD:明显优于扩散模型和 LLM+扩散基线。
- 叙事一致性:在动画配音和自然场景音频中,人类听感评测也显著提升。
可以说,AudioStory 把长篇叙事音频生成拉到了一个新高度。
🔋 致谢与生态
在持续噪声去除器(continuous denoisers)构建上,AudioStory 参考了 SEED-X 和 TangoFlux 项目。
学术圈的相互借鉴与迭代,正推动整个 TTA 领域的飞速发展。
🐯猫头虎点评
为什么我推荐大家关注 AudioStory?
- 场景落地感强 —— 有声小说、播客、动画后期、虚拟主播,马上能用。
- 统一模型思路 —— 省去了多模块拼接的麻烦,更简洁也更稳健。
- 开源可玩性 —— 代码+模型+Demo 全放出,研究者和开发者都能快速上手。
未来如果结合 多模态大模型(如视觉+音频),再叠加 实时生成,那真的就是“AI 声音导演”了。
👉 地址奉上:https://github.com/TencentARC/AudioStory
🐯 总结一句:
AudioStory = 让 AI 不仅能说话,更能讲故事。
从短音频走向长篇叙事,这是 TTA 的关键突破,也可能是下一波“有声内容产业”的催化剂。








】项目管理上:盈亏平衡分析与进度管理)










