目录
一、从传统查找的痛点到哈希表的优势
二、哈希表的核心结构:文件柜的构成
2.1、 dictht 结构体:文件柜本体
2.2、dictEntry 结构体:带链条的文件夹
2.2.1、 哈希冲突的解决:抽屉里的链条
2.3、字典的高层封装:文件柜管理系统
2.4、dictType:文件处理工具包
三、哈希计算:如何确定文件位置
四、动态扩容与收缩:文件柜的大小调整
4.1、何时需要调整大小?
4.2、调整大小的规则
4.3、渐进式 rehash:边营业边搬家
4.4、写时复制优化:拍照时不整理房间
五、字典与 SDS 的完美配合
六、字典设计的核心智慧
如果说 SDS 是 Redis 的 "智能笔记本",链表是 "活页文件夹",那么字典就是把这些笔记和文件夹有序管理起来的 "智能文件柜系统"。当你在 Redis 中使用哈希类型存储用户信息(如HSET user:1 name "张三" age 30)时,背后正是字典结构在高效运作。
一、从传统查找的痛点到哈希表的优势
想象你在图书馆找书的三种方式:
- 按书架顺序查找:像数组遍历一样,逐个查看每个书架,效率极低
- 按分类目录查找:像链表遍历一样,虽然有分类但仍需逐个翻阅
- 按编号定位查找:像哈希表一样,通过书号直接计算出所在书架和位置,一步到位
Redis 的字典采用哈希表作为底层实现,正是为了实现这种 "一步到位" 的高效查找能力。哈希表就像配备了智能索引系统的文件柜,能在 O (1) 时间复杂度内完成数据的查找、添加和删除操作。
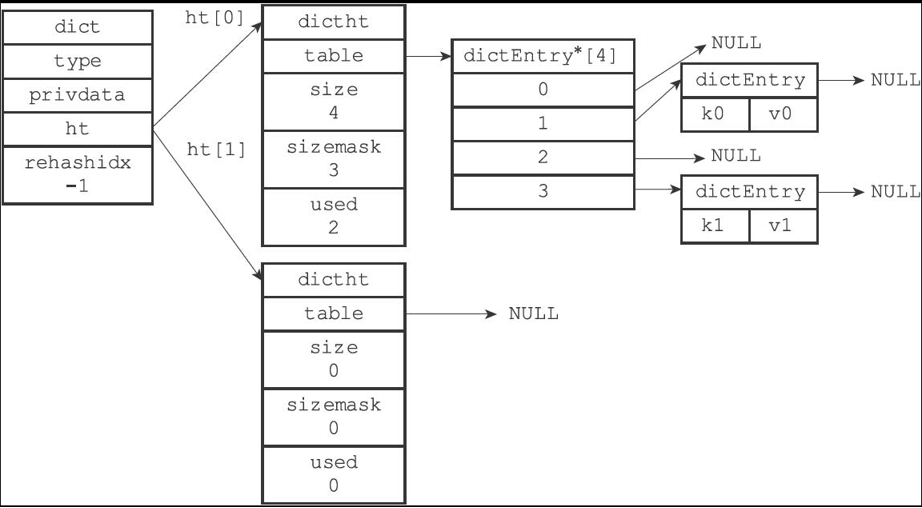
二、哈希表的核心结构:文件柜的构成
Redis 的哈希表结构由三个关键部分组成,就像文件柜的不同组件:
2.1、 dictht 结构体:文件柜本体
struct dictht {dictEntry **table; // 抽屉数组(哈希表节点数组)unsigned long size; // 抽屉总数(哈希表大小)unsigned long sizemask; // 定位掩码(总是等于size-1)unsigned long used; // 已使用抽屉数(节点数量)};这个结构体就像一个文件柜:
- table是一排抽屉,每个抽屉可以放多个文件夹(通过链表连接)
- size记录总共有多少个抽屉
- sizemask是定位工具,用来计算文件应该放入哪个抽屉
- used记录已经放了多少文件
2.2、dictEntry 结构体:带链条的文件夹
struct dictEntry {void *key; // 文件标签(键)union { // 文件内容(值)void *val;uint64_t u64;int64_t s64;} v;struct dictEntry *next; // 下一个文件夹(解决冲突的链表)};每个节点就像一个带链条的文件夹:
- key是文件的标签,在 Redis 中通常用 SDS 存储(比如 "name"、"age")
- v是文件内容,可以是字符串指针(void *val)、无符号整数(u64)或有符号整数(s64)
- next是连接链条,当多个文件需要放入同一个抽屉时,用链条将它们串起来(哈希冲突解决)
2.2.1、 哈希冲突的解决:抽屉里的链条
当两个不同的键计算出相同的抽屉编号时(哈希冲突),就像两个文件要放进同一个抽屉,这时next指针就发挥作用了 —— 它把这些文件串成一个链表,这种方法称为 "链地址法"。
比如 "张三" 和 "张三丰" 计算出相同的抽屉编号,它们会通过next指针连接在一起,查找时只需遍历这个小链表即可。
2.3、字典的高层封装:文件柜管理系统
Redis 的字典结构在哈希表之上增加了管理层,就像文件柜的智能管理系统:
struct dict {dictType *type; // 操作工具集void *privdata; // 工具参数dictht ht[2]; // 两个哈希表(主表和备用表)int rehashidx; // 搬家进度(-1表示未进行)};这个管理系统的核心功能:
- 维护两个哈希表ht[0](日常使用)和ht[1](搬家时使用)
- 通过rehashidx记录数据迁移进度
- 提供type中定义的工具函数处理不同类型的数据
2.4、dictType:文件处理工具包
struct dictType {unsigned int (*hashFunction)(const void *key); // 计算抽屉编号的工具void *(*keyDup)(void *privdata, const void *key); // 复制标签的工具void *(*valDup)(void *privdata, const void *obj); // 复制内容的工具int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 比较标签的工具void (*keyDestructor)(void *privdata, void *key); // 销毁标签的工具};这些函数就像文件柜的配套工具:
- hashFunction:根据文件名计算抽屉编号(哈希函数)
- keyDup:复制文件标签(比如复制 SDS 字符串)
- keyCompare:比较两个文件标签是否相同
- 其他工具负责数据的复制和销毁
三、哈希计算:如何确定文件位置
把文件放入文件柜需要两步:计算哈希值(文件名编码)和计算索引(抽屉编号):
- 计算哈希值:用hashFunction对键(key)进行计算,比如对 SDS 字符串 "name" 计算得到一个大整数
- 计算索引:用哈希值与sizemask(size-1)做与运算,得到抽屉编号:
索引 = 哈希值 & sizemask
例如:当size=8(sizemask=7),哈希值 = 10(二进制 1010)时:
1010 & 0111 = 0010(二进制)→ 索引=2
这种计算方式要求size必须是 2 的幂次方,这样sizemask的二进制表示全是 1,能保证索引均匀分布在0到size-1之间。
四、动态扩容与收缩:文件柜的大小调整
随着文件增减,文件柜需要动态调整大小以保持效率,这个过程称为 "rehash"(重新散列):
4.1、何时需要调整大小?
- 扩展条件:当文件太多导致拥挤时
- 无备份任务时,负载因子≥1(used/size ≥1)
- 有备份任务时,负载因子≥5(避免频繁复制内存)
- 收缩条件:当文件太少导致空间浪费时
- 负载因子≤0.1(used/size ≤0.1)
负载因子就像 "拥挤度":比如 8 个抽屉放了 10 个文件,拥挤度 = 10/8=1.25。
4.2、调整大小的规则
- 扩展:ht[1]的大小是第一个大于等于ht[0].used*2的 2 的幂次方
- 例:used=10 → 10*2=20 → 下一个 2 的幂次方是 32
- 收缩:ht[1]的大小是第一个大于等于ht[0].used的 2 的幂次方
- 例:used=10 → 下一个 2 的幂次方是 16
4.3、渐进式 rehash:边营业边搬家
如果文件柜需要从 8 个抽屉扩到 32 个抽屉,不可能一次性搬完所有文件 —— 这会导致图书馆暂时停业。Redis 采用 "渐进式 rehash" 策略,就像边营业边搬家:
- 准备阶段:为ht[1]分配新空间,rehashidx=0(开始搬家)
- 渐进迁移:每次有读写操作时,顺带迁移ht[0]中rehashidx索引处的所有文件到ht[1],然后rehashidx加 1
- 双表并行:迁移期间,查找操作会同时检查ht[0]和ht[1];新增操作直接放入ht[1],保证ht[0]只减不增
- 完成迁移:当ht[0]所有文件都迁移到ht[1]后,ht[1]成为新的ht[0],rehashidx=-1(搬家完成)
这种策略把巨大的迁移工作分散到每次操作中,避免了服务中断。
4.4、写时复制优化:拍照时不整理房间
当 Redis 执行 BGSAVE(备份)或 BGREWRITEAOF(日志重写)时,会创建子进程。为了减少内存复制开销,Redis 采用 "写时复制" 技术:
- 子进程创建时共享父进程内存,只有当数据修改时才复制相关内存页
- 因此在备份期间,Redis 提高扩展阈值(负载因子≥5 才扩展),减少内存写入操作
- 这就像拍照时不整理房间,等照片拍完再整理,避免重复劳动
五、字典与 SDS 的完美配合
SDS 在字典中扮演重要角色:
- 键(key)的存储:字典的键几乎都是用 SDS 存储的,比如HSET user:1 name "张三"中的 "name"
key → SDS结构:len=4, free=4, buf=['n','a','m','e','\0']
- 字符串值的存储:当值是字符串时,也用 SDS 存储,比如 "张三"
v.val → SDS结构:len=6, free=6, buf=['张','三','\0']
- 数值的优化存储:当值是整数时,直接用u64或s64存储,避免 SDS 的内存开销
这种组合让字典既能高效存储字符串,又能优化数值类型的存储。
六、字典设计的核心智慧
| 特性 | 生活比喻 | 技术价值 |
| 哈希表结构 | 智能文件柜 | O (1) 时间复杂度的基本操作 |
| 链地址法 | 抽屉里的链条 | 优雅解决哈希冲突 |
| 双哈希表 | 新旧文件柜 | 支持动态扩容 / 收缩 |
| 渐进式 rehash | 边营业边搬家 | 避免操作阻塞 |
| 类型特定函数 | 专用工具包 | 支持多类型数据处理 |
| 写时复制适配 | 拍照时不整理 | 优化备份时的性能 |
Redis 字典通过这些设计,完美平衡了性能、灵活性和内存效率。它不仅是哈希类型的底层实现,还被用于 Redis 数据库的核心(键空间)、集群节点通信等关键场景,是 Redis 高效运作的基石之一。
理解了字典结构,你就掌握了 Redis 数据管理的核心机制 —— 从简单的键值对到复杂的哈希对象,都依赖这个精妙的 "智能文件柜系统" 来实现高效管理。

)






)





:H264中的SEI)




