目录
一. 线性表
二. 顺序表的概念与结构
2.1 核心概念
2.2 两种常见结构
静态顺序表
动态顺序表
2.3 核心区别对比
四. 顺序表的实现
4.1 顺序表的定义
4.2 顺序表初始化
4.3 动态顺序表容量检查与扩容
4.4 动态顺序表插入数据
4.4.1 头插
4.4.2 尾插
4.4.3 指定位置插入
4.5 动态顺序表的删除数据
4.5.1 头删
4.5.2 尾删
4.5.3 删除指定位置的数据
4.5.4 删除指定的数据
4.6 查找指定数据
4.6 动态顺序表销毁
五. 优缺点分析
六. 适用场景选择
七. 总结
在学习顺序表之前 我们需要有一定的基础知识 首先我们需要了解线性表
一. 线性表
线性表是具有 “一对一” 逻辑关系的有限数据元素序列,是数据结构中最基础、最常用的结构之一,广泛应用于数组、链表等底层实现,也是栈、队列等复杂结构的基础。
核心定义与逻辑特征
线性表由
n(n≥0)个相同数据类型的元素构成,记为L = (a₁, a₂, ..., aₙ),其中:
a₁是首元素(无前驱),aₙ是尾元素(无后继);除
a₁和aₙ外,每个元素aᵢ(2≤i≤n-1)有且仅有一个前驱(aᵢ₋₁)和一个后继(aᵢ₊₁);
n=0时称为空表(无任何元素)。
两种核心存储结构( 暂时只做了解 )
线性表的存储结构决定了其操作效率,核心分为 “顺序存储” 和 “链式存储” 两类,二者各有优劣:
| 对比维度 | 顺序存储结构(顺序表) | 链式存储结构(链表) |
|---|---|---|
| 存储方式 | 用连续的存储单元依次存储元素 | 用任意存储单元存储元素,通过指针 / 引用链接逻辑关系 |
| 逻辑与物理关系 | 逻辑顺序 ≡ 物理顺序 | 逻辑顺序 ≠ 物理顺序(靠指针维护) |
| 访问效率 | 支持随机访问(通过索引 O(1) 定位) | 仅支持顺序访问(需从表头遍历,O(n)) |
| 插入 / 删除效率 | 中间 / 头部操作需移动元素(O(n)),尾部插入 O(1) | 仅需修改指针(O(1),前提是找到目标位置) |
| 空间利用率 | 可能存在 “内存碎片”(预分配空间未用完) | 无碎片,但需额外存储指针(空间开销略大) |
| 典型实现 | 数组(如 C 语言数组、Java ArrayList) | 单链表、双向链表、循环链表(如 Java LinkedList) |
二. 顺序表的概念与结构
顺序表是线性表的顺序存储结构,核心是用一段地址连续的物理存储单元依次存储线性表中的元素,使得元素的 “逻辑顺序” 与 “物理存储顺序完全一致”(即第 1 个元素存在第 1 个物理位置,第 2 个元素存在第 2 个物理位置,以此类推)。
2.1 核心概念
顺序表本质是 “基于数组的线性表实现”,但相比普通数组,它会额外记录当前元素个数(避免越界)和数组容量(方便扩容),是对数组的 “结构化封装”,确保符合线性表的逻辑特征(一对一前驱 / 后继关系)。
例如:存储 [1,3,5,7] 的顺序表,物理存储上元素在内存中连续排列,逻辑上 1 的后继是 3、3 的后继是 5,与物理位置顺序完全匹配。
2.2 两种常见结构
根据数组空间的分配方式,顺序表分为 “静态顺序表” 和 “动态顺序表”,实际开发中动态顺序表更常用(避免空间浪费或不足)。
静态顺序表
- 特点:使用固定大小的数组存储元素,容量在定义时确定,无法动态调整。
- 结构定义:
#define MAX_SIZE 100 // 固定容量 typedef int SLDataType; // 元素类型(可替换为其他类型)// 静态顺序表结构 typedef struct SeqList {SLDataType arr[MAX_SIZE]; // 固定大小的数组,存储元素int size; // 当前元素个数(关键:记录有效元素数量) } SeqList; - 缺点:容量固定,若元素个数超过
MAX_SIZE会溢出;若元素少则浪费内存。
动态顺序表
- 特点:使用动态内存分配的数组(如
malloc/realloc分配),容量可根据元素个数动态扩容 / 缩容,灵活性更高。 - 结构定义:
typedef int SLDataType;// 动态顺序表结构 typedef struct SeqList {SLDataType* arr; // 指向动态分配数组的指针(存储元素)int size; // 当前元素个数(有效元素数)int capacity; // 当前数组的容量(最大可存储元素数) } SeqList; - 核心优势:容量按需调整,避免静态顺序表的空间浪费或溢出问题,是实际开发中的主流选择。
2.3 核心区别对比
| 对比维度 | 静态顺序表 | 动态顺序表 |
|---|---|---|
| 存储空间分配 | 编译时固定分配(栈上或全局区) | 运行时动态分配(堆内存) |
| 容量特性 | 容量固定,不可改变 | 容量可变,可动态扩容 / 缩容 |
| 空间利用率 | 可能浪费(容量大于实际需求) | 利用率高(按需分配) |
| 溢出风险 | 有(元素数超过最大容量时) | 无(可动态扩容避免溢出) |
| 内存管理复杂度 | 简单(自动分配和释放) | 复杂(需手动分配、扩容和释放) |
| 实现难度 | 简单 | 稍复杂(需实现扩容逻辑) |
四. 顺序表的实现
4.1 顺序表的定义
静态顺序表:
#define MAX_SIZE 100 // 固定容量
typedef int SLDataType; // 元素类型(可替换为其他类型)// 静态顺序表结构
typedef struct SeqList {SLDataType arr[MAX_SIZE]; // 固定大小的数组,存储元素int size; // 当前元素个数(关键:记录有效元素数量)
} SeqList;
动态顺序表:
typedef int SLDataType;// 动态顺序表结构
typedef struct SeqList {SLDataType* arr; // 指向动态分配数组的指针(存储元素)int size; // 当前元素个数(有效元素数)int capacity; // 当前数组的容量(最大可存储元素数)
} SeqList;
4.2 顺序表初始化
静态顺序表初始化:
void StaticSeqListInit(StaticSeqList* ssl) {ssl->size = 0; // 只需初始化元素个数为0,数组空间已固定分配
}
动态顺序表初始化:
void DynamicSeqListInit(DynamicSeqList* dsl) {dsl->data = NULL;dsl->size = 0;dsl->capacity = 0; // 初始容量为0,或可分配默认初始容量4.3 动态顺序表容量检查与扩容
// 检查容量,不足则扩容
void CheckCapacity(DynamicSeqList* dsl) {if (dsl->size == dsl->capacity) {// 计算新容量,初始容量为0则设为4,否则翻倍int newCapacity = dsl->capacity == 0 ? 4 : dsl->capacity * 2;// 重新分配内存SLDataType* newData = (SLDataType*)realloc(dsl->data, newCapacity * sizeof(SLDataType));if (newData == NULL) {perror("realloc failed");exit(EXIT_FAILURE);}dsl->data = newData;dsl->capacity = newCapacity;}
}4.4 动态顺序表插入数据
4.4.1 头插
//头插
void SLPushFront(SL* ps, SLdatatype x)
{assert(ps);//ps!=NULL//检查空间是否足够SLCheckCapacity(ps);//空间足够for (int i = ps->size; i > 0; i--){ps->arr[i] = ps->arr[i - 1];}ps->arr[0] = x;ps->size++;
}4.4.2 尾插
//尾插
void SLPushBack(SL* ps, SLTDataType x)
{//空间不够if (ps->size == ps->capacity){//增容int newCapacity = ps->capacity ==0 ? 4 : 2 * ps->capacity;SLTDataType* tmp = (SLTDataType*)realloc(ps->arr, newCapacity*sizeof(SLTDataType));if (tmp = NULL){perror("realloc");exit(1);}ps->arr = tmp;ps->capacity = newCapacity;}//空间足够ps->arr[ps->size++] = x;//插入完后,size往后走
}4.4.3 指定位置插入
// 在pos位置插入元素value
int DynamicSeqListInsert(DynamicSeqList* dsl, int pos, SLDataType value) {if (pos < 0 || pos > dsl->size) return -1;CheckCapacity(dsl); // 自动检查并扩容// 移动元素for (int i = dsl->size; i > pos; i--) {dsl->data[i] = dsl->data[i-1];}// 插入新元素dsl->data[pos] = value;dsl->size++;return 0;
}
4.5 动态顺序表的删除数据
4.5.1 头删
//尾删
void SLPopBack(SL* ps)
{assert(ps && ps->size);ps->size--;
}4.5.2 尾删
//尾删
void SLPopBack(SL* ps)
{assert(ps && ps->size);ps->size--;
}4.5.3 删除指定位置的数据
void SQdelete(SL* ps, int pos) //删除第x个数据 这个x是数组的下标
{assert(ps->size > 0 && ps->size > pos);while (ps->size-pos>0){ps->arr[pos] = ps->arr[pos + 1];pos++;}ps->size--;
}4.5.4 删除指定的数据
void SQLdex(SL* ps, int x) //删除查找到的所有x
{int i = 0;while (i < ps->size){if (ps->arr[i] == x){// 元素前移覆盖要删除的元素for (int j = i; j < ps->size - 1; j++){ps->arr[j] = ps->arr[j + 1];}ps->size--; // 元素数量减1// 不执行i++,因为下一个元素移动到了当前位置}else{i++; // 只有当没有删除元素时,才移动到下一个位置}}
}
4.6 查找指定数据
void SLFind(SL* ps, SLdate x)
{for (int i = 0;i < ps->size;i++){if (ps->arr[i] == x){printf("找到了 顺序表第%d个",i+1);printf("\n");}}
}4.6 动态顺序表销毁
// 必须手动释放动态分配的内存,避免内存泄漏
void DynamicSeqListDestroy(DynamicSeqList* dsl) {free(dsl->data);dsl->data = NULL;dsl->size = 0;dsl->capacity = 0;
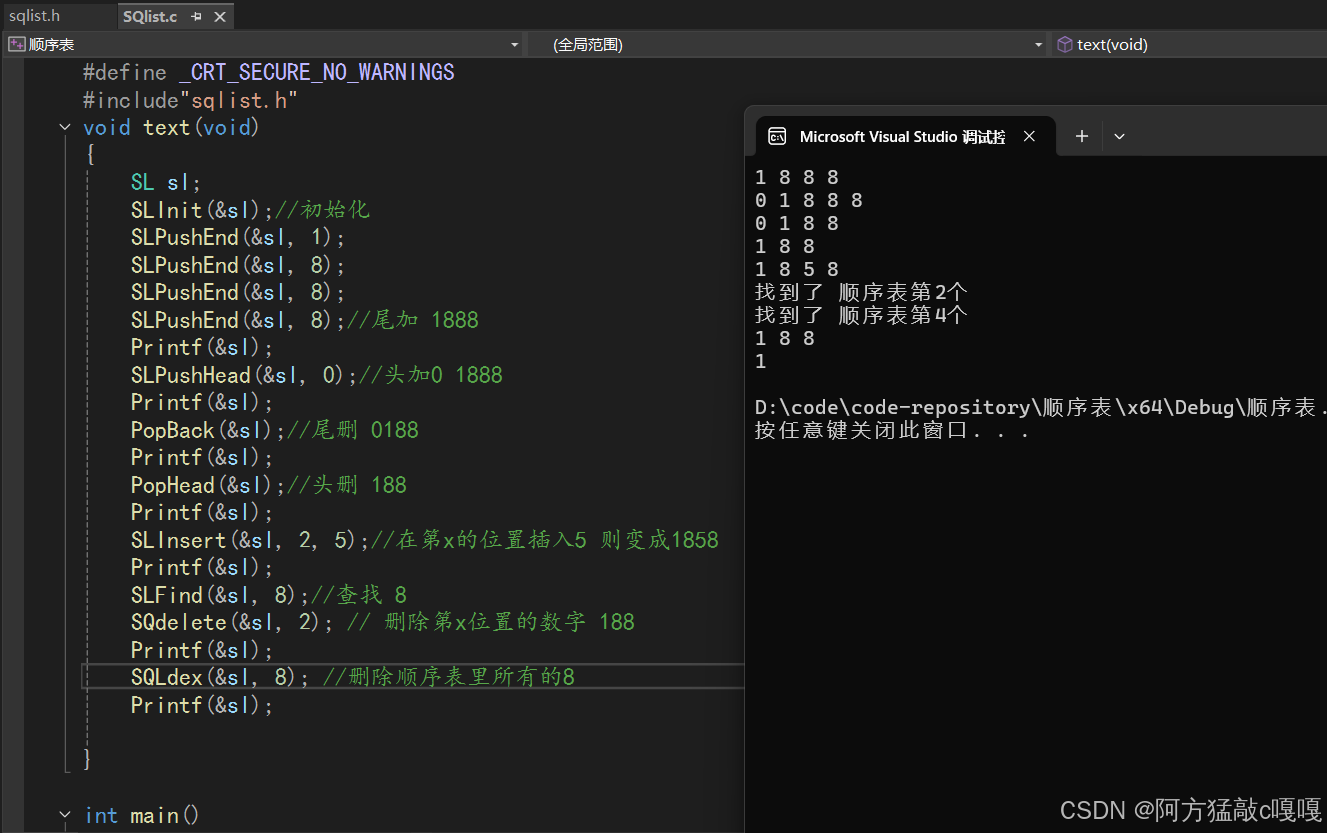
}示例运行结果如下:
五. 优缺点分析
静态顺序表
优点:
实现简单,无需处理复杂的内存分配逻辑
访问速度快,无需额外的指针操作
栈上分配内存,自动释放,不会造成内存泄漏
缺点:
容量固定,无法适应数据量动态变化的场景
可能造成内存空间浪费(当实际元素远少于最大容量时)
存在溢出风险(当元素数量超过最大容量时)
动态顺序表
优点:
容量可动态调整,能灵活适应数据量变化
内存利用率高,按需分配空间
不存在固定容量导致的溢出问题
缺点:
实现相对复杂,需要处理扩容、内存分配等问题
扩容时可能产生内存碎片
需手动管理内存,若操作不当易造成内存泄漏
扩容过程中需要拷贝数据,可能影响性能
六. 适用场景选择
静态顺序表适用场景:
数据量已知且固定不变的情况
对内存管理要求简单,不希望手动处理内存分配的场景
嵌入式系统、单片机等内存资源受限且数据量固定的环境
动态顺序表适用场景:
数据量不确定,需要动态增减的情况
对内存利用率要求较高的场景
大部分通用编程场景,如实现动态数组、列表等数据结构
七. 总结
静态顺序表和动态顺序表都是基于数组的线性表实现,核心区别在于存储空间是否可动态调整。静态顺序表简单直接但缺乏灵活性,动态顺序表灵活高效但实现稍复杂。
在实际开发中,动态顺序表应用更为广泛,因为它能更好地适应数据量动态变化的需求。了解两者的特点和差异,有助于根据具体场景选择合适的实现方式,从而优化程序性能和内存使用。
![[Maven 基础课程]Maven 是什么](http://pic.xiahunao.cn/[Maven 基础课程]Maven 是什么)





创建智能体的完整步骤)



)


)




)
