六、多表查询
1、多表关系
①、一对多(多对一)
举例:一个部门对多个员工
实现:多的那边建立外键,指向一的那边的主键
②、多对多
举例:一个学生可选多门课,一门课可被多个学生选
实现:建立中间表,包含两个外键,指向两边的主键
③、一对一
举例:一张表是用户姓名和id,另一张表是用户密码和信息
实现:任意一方加入外键,指向另一方的主键
2、多表查询分类
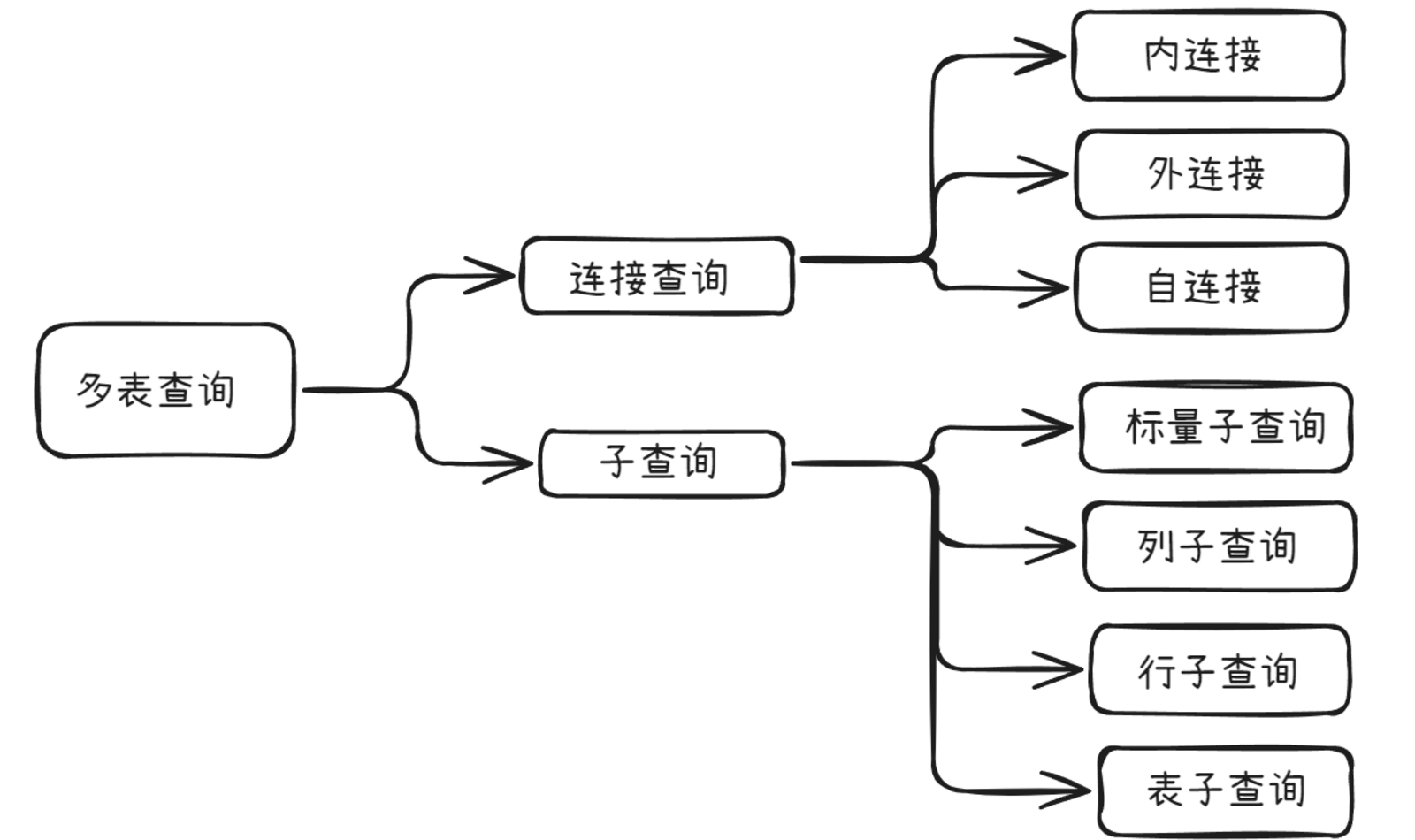
①、连接查询
Ⅰ、内连接
# 隐式内连接SELECT 字段列表 FROM 表1,表2 WHERE 条件 ...;# 显示内连接SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件 ...;# 内连接查询的是两张表交集的部分Ⅱ、外连接
# 左外连接SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件 ...;# 相当于查询表1(左表)的所有数据,包含表1和表2交集部分的数据# 右外连接SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件 ...;# 相当于查询表2(右表)的所有数据,包含表1和表2交集部分的数据Ⅲ、自连接
# 自连接查询,可以是内连接查询,也可以是外连接查询。# 自连接其实就是将一张表取两个名字,看成两张表来使用SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...;SELECT 字段列表 FROM 表A 别名A LEFT [OUTER] JOIN 表A 别名B ON 条件 ...;SELECT 字段列表 FROM 表A 别名A RIGHT [OUTER] JOIN 表A 别名B ON 条件 ...;# 补充:联合查询,把多次查询的结果合并起来,形成一个新的查询结果集# 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。# union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。SELECT 字段列表 FROM 表A ...UNION[ALL]SELECT 字段列表 FROM 表B ...;②、子查询
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
做法都是将前一个表的查询语句插入到后一个表的限制条件内,只不过是前一个表的查询内容不同,有的是一个值(标量子查询)、一列(列子查询)、一行(行子查询)、一个表(表子查询)
Ⅰ、标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询成为标量子查询。常用的操作符:= <> > >= < <=
Ⅱ、列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。常用的操作符:IN 、NOT IN 、ANY 、SOME 、ALL
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
Ⅲ、行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。常用的操作符:= 、<>、IN 、NOT IN
Ⅳ、表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。常用的操作符:IN
3、实操
注意不是所有都演示,只演示部分
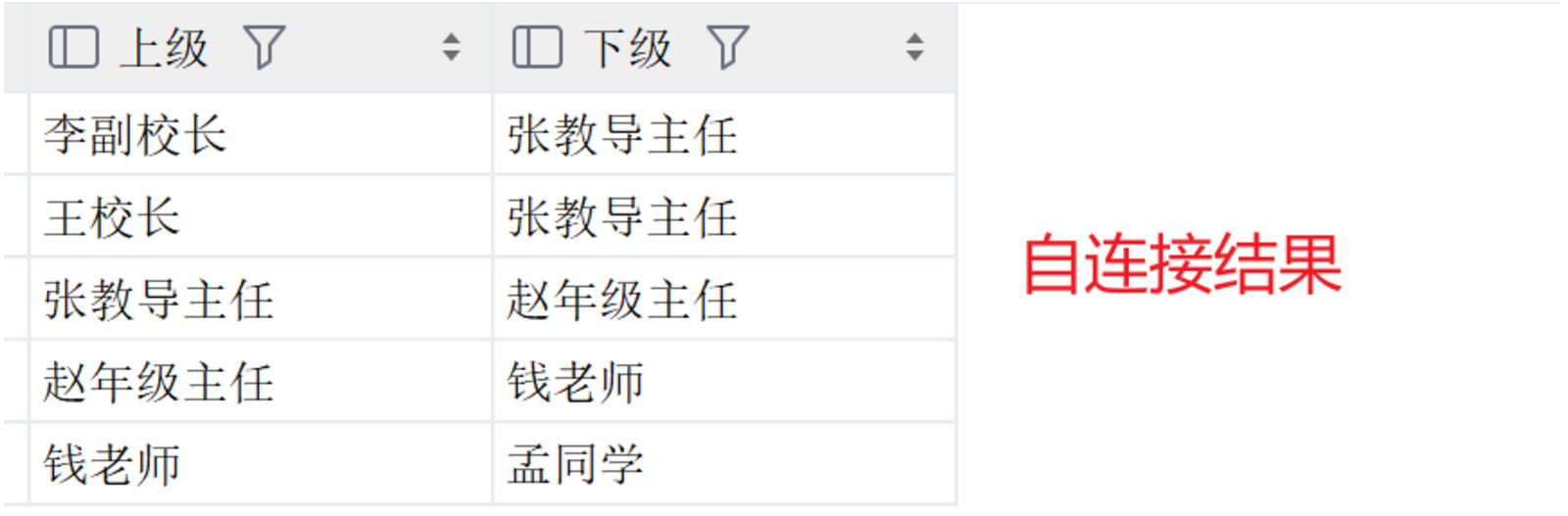
create table student(id varchar(20) primary key not null unique comment '学号',name varchar(20) not null comment '姓名',age smallint not null comment '年龄',gender varchar(1) not null comment '性别',major_class varchar(20) not null comment '专业')comment '学生表';create table course(course_id varchar(5) not null unique comment '课程编号',course_name varchar(20) not null comment '课程名称')comment '课程表';create table sc(id varchar(20) primary key not null unique comment '学号',course_id varchar(5) not null unique comment '课程编号',grade float not null comment '成绩',# 创建外键将本表 sc 的 id 和 student 表的 id 绑定constraint fk_s_sc foreign key (id) references student(id),# 创建外键将本表 sc 的 course_id 和 course 表的 course_id 绑定constraint fk_c_sc foreign key (course_id) references course(course_id))comment '学生课程表';create table staff(class int not null comment '所处层级',name varchar(20) not null comment '姓名',age smallint comment '年龄',gender varchar(1) comment '性别',job varchar(20) not null comment '工作',manage int comment '管理层级')comment '教职工表';INSERT INTO student (id, name, age, gender, major_class) VALUES(1, '张三', 12, '男', '计算机科学'),(2, '李四', 22, '女', '电子工程'),(3, '王五', 15, '男', '机械工程'),(4, '赵六', 18, '女', '化学工程'),(5, '孙七', 25, '男', '土木工程');INSERT INTO course (course_id, course_name) VALUES('C001', '高等数学'),('C002', '线性代数'),('C003', '大学物理'),('C004', '数据结构'),('C005', '操作系统');INSERT INTO sc (id, course_id, grade) VALUES(1, 'C001', 45.5),(2, 'C002', 77.0),(3, 'C003', 84.5),(4, 'C004', 98.0),(5, 'C005', 67.5);INSERT INTO staff VALUES(1, '王校长', 50, '男', '校长', 3),(2, '李副校长', 45, '女', '副校长', 3),(3, '张教导主任', 40, '男', '教导主任', 4),(4, '赵年级主任', 35, '女', '年级主任', 5),(5, '钱老师', 30, '女', '教师', 6);INSERT INTO staff (class, name, age, gender, job) VALUES(6, '孟同学', 14, '女', '学生');# 隐式内连接(查询每个同学所选的课程名称)SELECT name,course_name FROM student,sc,courseWHERE student.id = sc.id AND course.course_id = sc.course_id;# 显示内连接(查询 id 为 1 的同学其所选课程即成绩)SELECT name,course_name,grade FROM student,sc,courseWHERE student.id = sc.id AND course.course_id = sc.course_id AND student.id = 1;# 自连接(查询教职工名称及其直属管理人员)SELECT a.name '上级',b.name '下级' FROM staff a JOIN staff b on a.manage = b.class;# 子查询(无非就是一个套一个进行查询)# 查询张三和李四其所选课程即成绩SELECT id FROM student WHERE name = '张三' OR name = '李四';# 得id=1、2(一列数据),向下整合即可,其他子查询类似,只不过得到的变为一个标量、一行、一表SELECT name,course_name,grade FROM student,sc,courseWHERE student.id = sc.id AND course.course_id = sc.course_idAND student.id in (SELECT id FROM student WHERE name = '张三' OR name = '李四');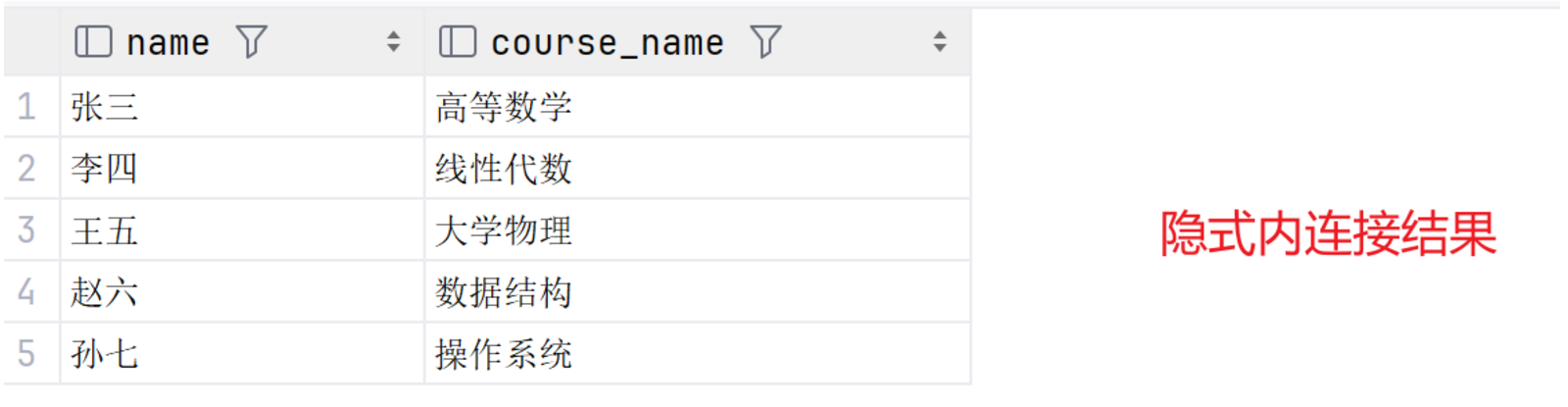


七、事务
1、事务简介
事务是一组操作的集合,这组操作要么全部成功,要么全部失败
2、事务操作
系统默认是自动提交,即每当我们执行了DML语句,MySQL会隐式提交事务。
但是如果是多个事务自动提交,那么当出现事务的报错后,可能上一个事务会执行而下一个事务不会执行,为避免一部分语句成功一部分失败的情况发生,所以需要手动提交事务。
# 1、通过控制事务的提交方式来操作事务# 查看/设置事务提交方式SELECT @@autocommit;SET @@autocommit = 0; # 如果是1,则是自动提交,如果是0,则是手动提交# 提交事务COMMIT;# 回滚事务ROLLBACK;# 当我们将事务的提交方式设置为手动提交,我们每次执行完语句,其内部数据不会改变,只有当执行commit; 语句后才会改变# 当出现错误时,我们可以使用rollback;语句回滚事务来保证数据的完整性和正确性# 2、通过控制事务的开启来操作事务# 开启事务START TRANSACTION 或 BEGIN;# 提交事务COMMIT;# 回滚事务ROLLBACK;# 开启事务到事务的提交(commit)或回滚(rollback)是一个完整的事务单元,即开启后一旦提交或回滚后就结束,然后需要再次开启# 当出现语句错误,由于我们开启事务,这时候原来的数据就不会改变,而是先报错提醒我们将会出现一部分成功一部分失败的情形而导致原来的数据发生改变3、事务四大特性(ACID)
原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
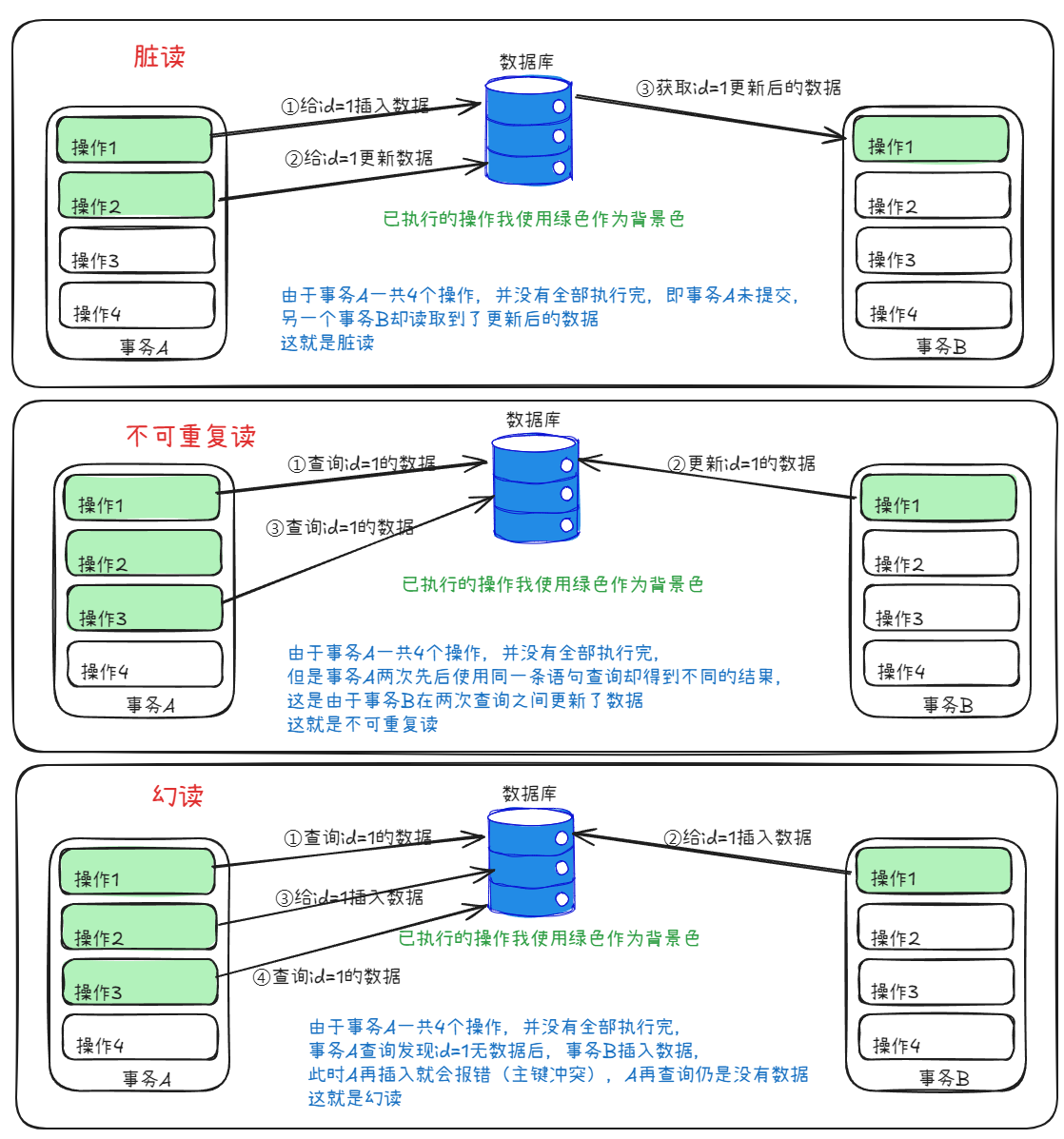
4、并发事务问题
并发事务问题即两个事务同时对同一数据的操作时会出现的问题
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另外一个事务还没有提交的数据。 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了“幻影”。 |
5、事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read(默认) | × | × | √ |
| Serializable | × | × | × |
# 查看事务隔离级别SELECT @@TRANSACTION_ISOLATION;# 设置事务隔离级别SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}性能排序(从高到低):
Read uncommitted
Read committed
Repeatable Read(默认)
Serializable
隔离级别排序(从高到低):
Serializable
Repeatable Read(默认)
Read committed
Read uncommitted
这里就不演示每个隔离级别了,如有兴趣可自行双开终端试一试。
八、存储引擎
1、MySQL体系结构
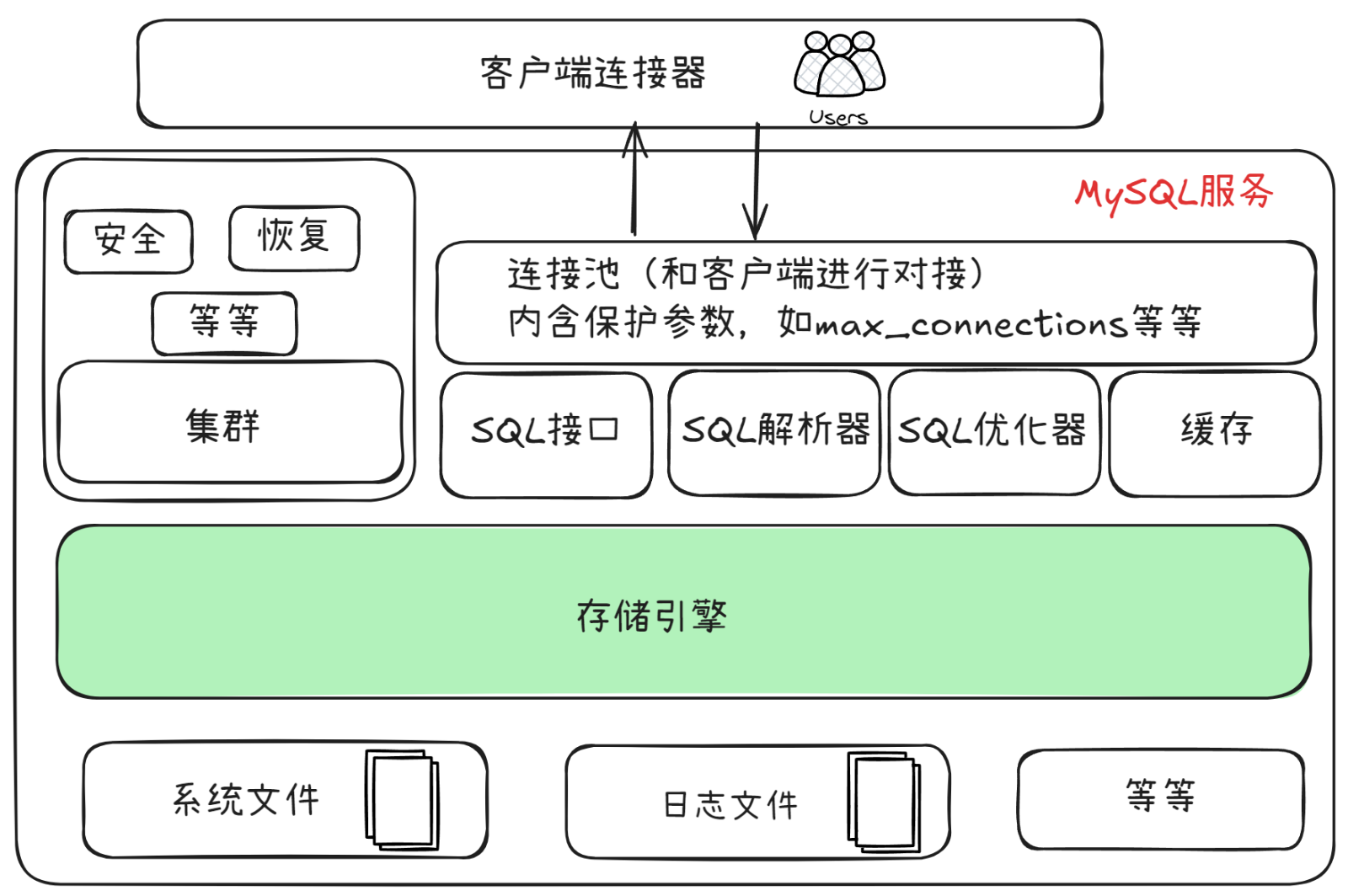
2、存储引擎
①、简介
存储引擎是数据库管理系统中用于存储、管理和检索数据的软件组件。它决定了数据的存储方式、索引方式以及如何在数据库中存取数据。
# 在创建表时,指定存储引擎CREATE TABLE 表名(字段1 字段1类型 [COMMENT 字段1注释 ],......字段n 字段n类型 [COMMENT 字段n注释 ])ENGINE = INNODB [ COMMENT 表注释 ];# 查看当前数据库支持的存储引擎SHOW ENGINES;②、特点
Ⅰ、InnoDB(默认)
DML操作遵循ACID模型,支持事务;
行级锁,提高并发访问性能;
支持外键FOREIGN KEY约束,保证数据的完整性和正确性;
Ⅱ、MyISAM
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
Ⅲ、Memory
内存存放
hash索引(默认)
| 特点 | InnoDB(默认) | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
③、选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
九、索引
MySQL 中,索引是一种用于优化查询效率的数据结构。索引可以加快数据检索速度,提高数据库性能。
1、索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持 B+ 树索引 |
| Hash索引 | 底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES |
我们主要研究 InnoDB 的 B+Tree 索引
①、预备知识
Ⅰ、B树(B-Tree)
定义:
B树是一种平衡多路查找树(多叉树),可以有多于两个儿子,通常用于数据库和文件系统中。
特点:
平衡:所有叶子节点都位于同一层。
多路:每个节点可以有多个子节点(通常为2到最大度数)。
路径从根节点到叶子节点长度相同。
支持范围查询,可以找到给定范围内的所有数据。
任一元素左子树小于它本身,右子树大于它本身
n路B树即n阶B树,每个节点最多存储(n-1)个值,n个指针,当每个节点插入值后多于(n-1)个值即会分裂。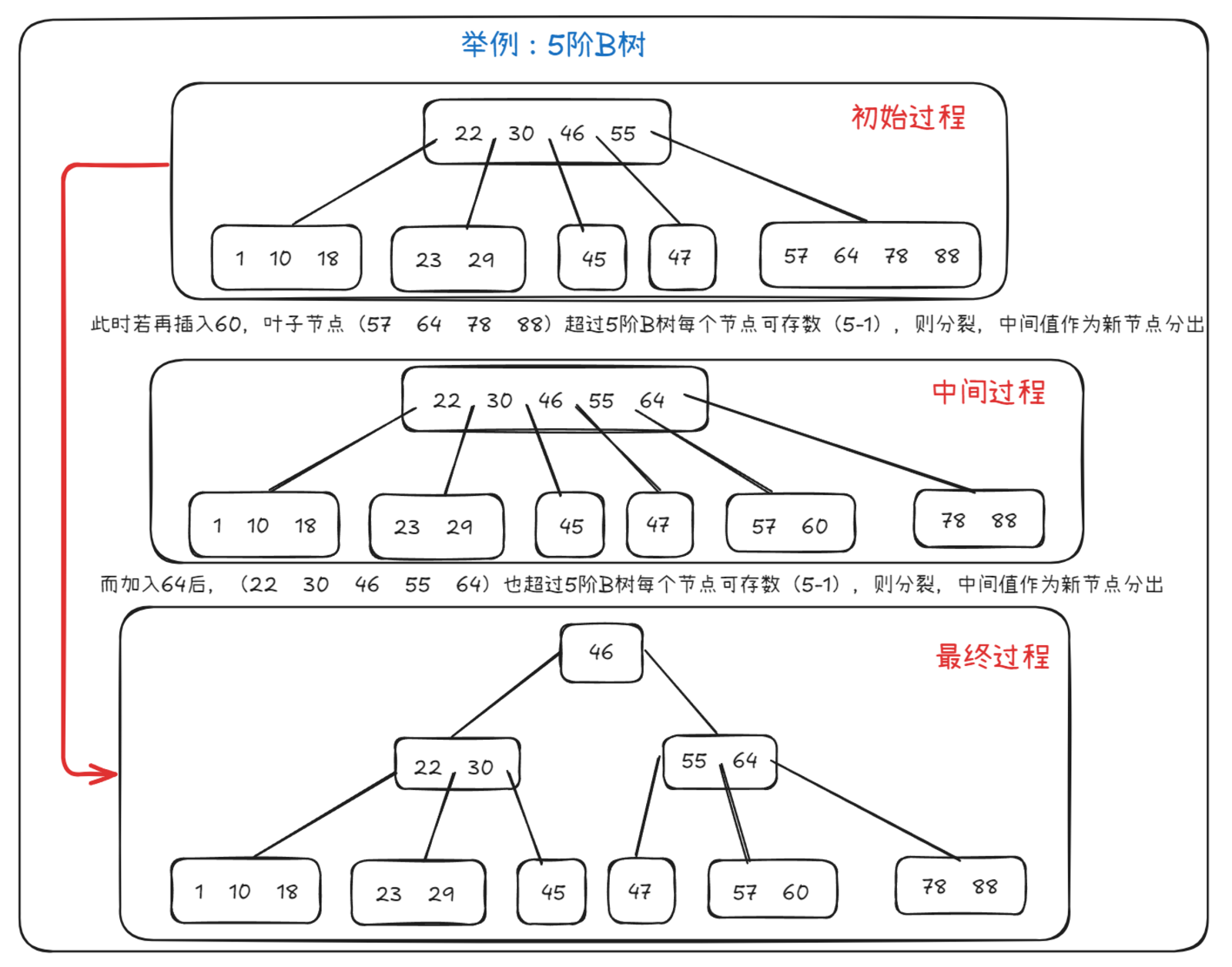
Ⅱ、B+树(B+Tree)
定义:
B+树是B树的变种,具有所有叶子节点都链接在一起,并且叶子节点增加一个指向下一个叶子节点的指针。即叶子节点会形成单向列表。
特点:
保持B树的平衡性,但增加了顺序访问的能力。
叶子节点包含数据,非叶子节点不包含数据,只包含键和指针。
支持高效的范围查询,因为叶子节点按顺序链接。
支持高效的顺序访问(如扫描)。
B+树的数据只存在于列表,故每个节点可存储更多地址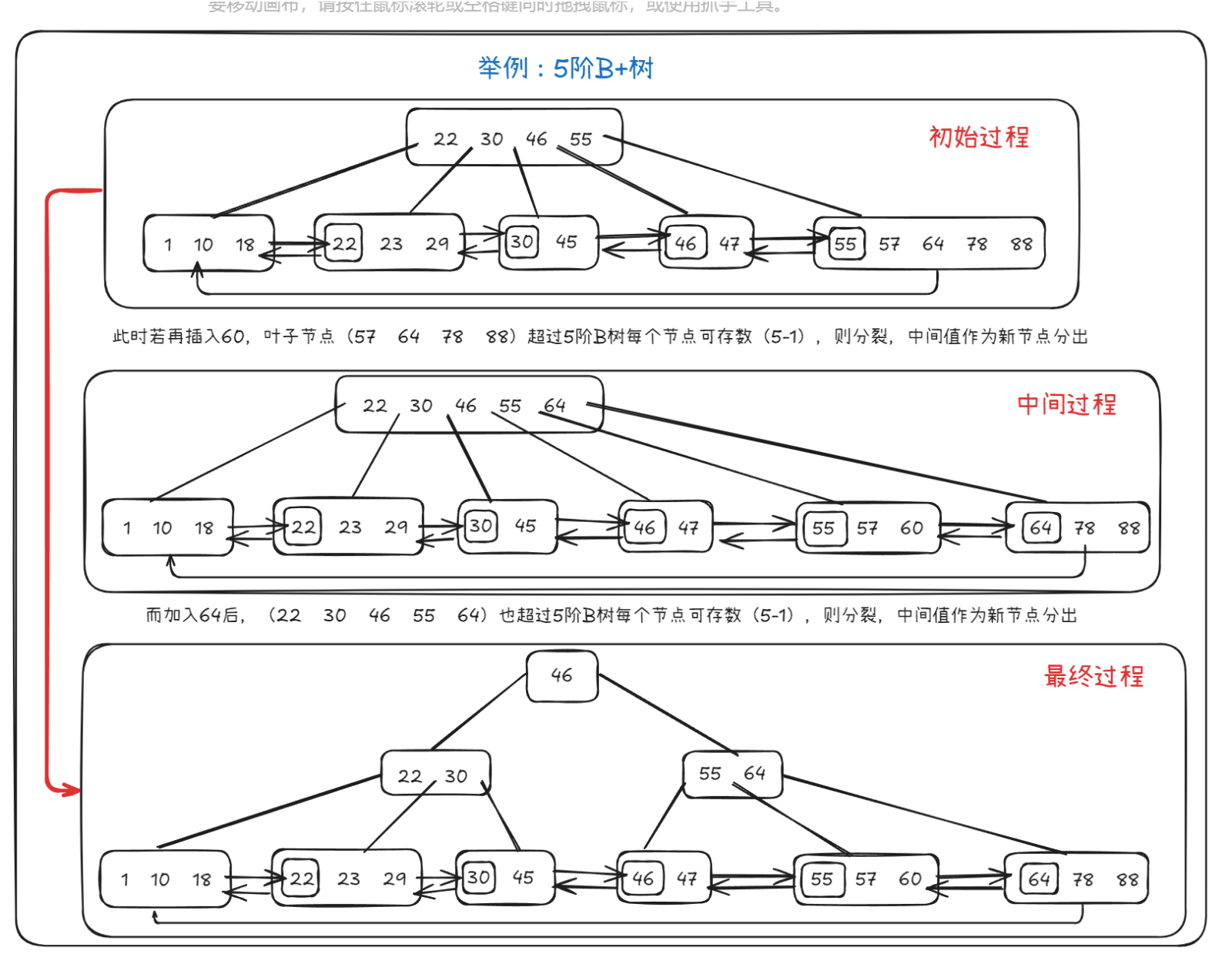
Ⅲ、哈希表
哈希索引(Hash Index)是一种数据库索引技术,它使用哈希表(Hash Table)来实现索引。哈希表是一种数据结构,它通过哈希函数将数据值映射到一个固定大小的数组索引表中,从而实现快速的数据查找。
快速查找:哈希索引非常适合于等值查询操作,因为它可以直接通过哈希函数计算出数据应该存储的位置,从而实现快速查找。
不支持范围查询:由于哈希索引的特性,它不支持范围查询(如
BETWEEN、LIKE等)。如果需要进行范围查询,可能需要使用其他类型的索引,如B+树索引。哈冲突解决:当两个不同的数据值经过哈希函数计算后得到相同的索引位置时,称为哈希冲突(Hash Collision)。解决哈希冲突的方法通常是链地址法(Chaining),即在哈希表的每个槽位上维护一个链表,用于存储所有映射到该槽位的数据。
适用场景:哈希索引适用于那些需要快速查找且数据分布均匀的场景。如果数据分布不均匀,可能会导致哈希冲突增多,从而影响性能。
②、补充知识
Ⅰ、B树和B+树区别
| 特性 | B树 | B+树 |
|---|---|---|
| 数据存储位置 | 所有节点都存储数据 | 只有叶子节点存储数据,内部节点只存键值 |
| 叶子节点连接 | 叶子节点不相互连接 | 叶子节点通过指针相互连接形成链表 |
| 查询性能 | 可能在非叶子节点找到数据,查询不稳定 | 必须到叶子节点才能找到数据,查询稳定 |
| 范围查询 | 效率较低 | 效率高,通过叶子节点链表快速遍历 |
| 空间利用率 | 内部节点存储数据,占用更多空间 | 内部节点只存键值,空间利用率更高 |
| 相同键值 | 不会重复存储 | 键值可能在内部节点和叶子节点重复存储 |
Ⅱ、MySQL选择B+树的原因
更高的查询效率:
B+树的非叶子节点不存储数据,因此可以存储更多的键值,使树的高度更低
通常3-4层的B+树就能存储千万级的数据,减少磁盘I/O次数
更稳定的查询性能:
所有查询都必须到达叶子节点,查询路径长度相同
避免了B树中可能在非叶子节点找到数据导致的不稳定情况
优秀的范围查询能力:
叶子节点形成的链表使范围查询非常高效
只需找到起始节点,然后沿着链表遍历即可
更高的磁盘I/O效率:
B+树的内部节点只存储键值,不存储数据,可以一次读入更多的键值
更适合以页为单位(如4KB)的磁盘读取
更适合数据库场景:
数据库经常需要全表扫描,B+树只需遍历叶子节点链表
而B树需要遍历整棵树,效率低很多
更好的缓存利用率:
非叶子节点可以常驻内存,只对叶子节点进行磁盘I/O
因为非叶子节点不包含数据,占用空间小,缓存效率高
MySQL的InnoDB存储引擎使用B+树作为索引结构,这种设计在数据库的读多写少、大量范围查询的场景下表现尤为出色。
2、索引分类
①、主键索引(PRIMARY KEY):
每个表只能有一个主键索引。
主键索引列不能包含 NULL 值。
通常用于唯一标识表中的每一行。
②、唯一索引(UNIQUE):
保证列中的所有值都是唯一的。
可以包含 NULL 值。
③、常规普通索引(INDEX):
最常用的索引类型,没有唯一性或主键的限制。
④、全文索引(FULLTEXT):
用于全文搜索,支持对较大的文本字段进行搜索。
⑤、空间索引(SPATIAL):
用于地理数据类型,如 GEOMETRY。
按存储分类可将索引分为两类:聚集索引和二级索引
聚集索引:
聚集索引通常用于主键(PRIMARY KEY)。
由于数据行的物理顺序与索引顺序一致,因此聚集索引可以非常高效地支持范围查询。
聚集索引可以包含其他列,但只有第一列是聚集的。
若有主键则主键索引就是聚集索引,没有主键有唯一索引则唯一索引就是聚集索引,否则生成一个隐藏聚集索引
二级索引:
二级索引不保证数据行的物理顺序与索引顺序一致。
可以有选择表中的任何列作为索引列,不仅限于主键。
适用于非聚集索引列,可以提高查询性能,尤其是在非范围查询中。
聚集索引的叶子节点下挂的是主键对应的行数据,二级索引的叶子节点下挂的是该字段值对应的主键值。
回表查询即先通过二级索引查找相应主键值,再通过主键值的聚集索引进行查找
3、索引语法
4、性能分析
5、索引使用
6、索引设计原则
明天继续补充完成



))





通信)
处理)




)
)


