1. 接口测试过程中的痛点
接口的内容都是在yapi上,接口的内容都是以表格的形式呈现。在接口测试过程中,需要将表格形式的入参,手动敲成JSON格式,并且需要跟进字段类型,编辑字段值的形式。过程较为麻烦。
使用postman进行接口测试时,使用一个参数测试后,需要重新编辑参数进行下一个用例的执行,不能批量进行接口的调用。
自动化脚本每次都是需要人一行行写,有时有些脚本还不太熟练
2. 解决的方法
在大模型日渐流行的时代,就考虑是否可以使用大模型来简化上边的痛点,提高工作中的效率。于是,进行了以下的实践过程。
3. 开启探索之旅:
3.1 文本 API
与deepseek交互--提示词信息
URL:https://xxxx
请求方法:post
请求头:{
"Content-Type": "application/json"
”Authorization“:”xxxxx“
}
请求体:{
"storeCode": "",
"storeName": "",
"mdCode": "",
"mdName": "",
"queryKey": "",
"regionCode": [370212,370214],
"pageNum": 1,
"pageSize": 10
}
响应格式: JSON
响应状态码: 200
示例响应:
测试场景:
正常场景:入参有"regionCode": [370212,370214],pageNum": 1, "pageSize": 10。
异常场景:入参都为空。
断言要求:状态码为 200
生成的脚本
import requests
import pytest# 基础 URL
BASE_URL = "https://xxxxx"# 请求头
HEADERS = {"Content-Type": "application/json","Authorization": "xxxxx"# 正常场景测试
def test_query_for_design_success():# 请求体payload = {"storeCode": "","storeName": "","mdCode": "","mdName": "","queryKey": "","regionCode": [370212, 370214],"pageNum": 1,"pageSize": 10}# 发送 POST 请求response = requests.post(BASE_URL, json=payload, headers=HEADERS)# 断言assert response.status_code == 200, f"预期状态码为 200,实际为 {response.status_code}"assert isinstance(response.json(), dict), "响应体应为 JSON 格式"# 异常场景测试
def test_query_for_design_failure():# 请求体(所有参数为空)payload = {"storeCode": "","storeName": "","mdCode": "","mdName": "","queryKey": "","regionCode": [],"pageNum": 1,"pageSize": 10}# 发送 POST 请求response = requests.post(BASE_URL, json=payload, headers=HEADERS)# 断言assert response.status_code == 200, f"预期状态码为 200,实际为 {response.status_code}"assert isinstance(response.json(), dict), "响应体应为 JSON 格式"# 运行测试
if __name__ == "__main__":pytest.main()输出结果
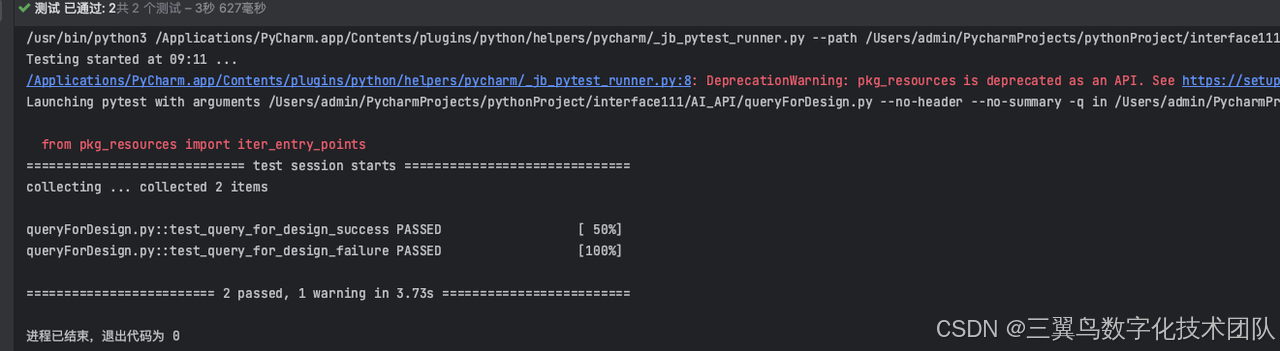
总结
1.使用大模型进行脚本生成时,尽可能的描述清晰接口的组成部分的内容。描述的越详细可以输出的更精准
2.测试场景,可以根据实际的测试需要,进行入参的赋值。生成固定参数的测试脚本
3.断言形式可以多种形式,选择自己需要的形式。比如返回值,返回code等
单接口、固定参数的接口自动化脚本的生成属于比较简单,并且最容易上手操作的一个场景。
不理想的方面:很多接口信息在YAPI上,每次整理上面格式都需要手动操作,比较耗时耗力。
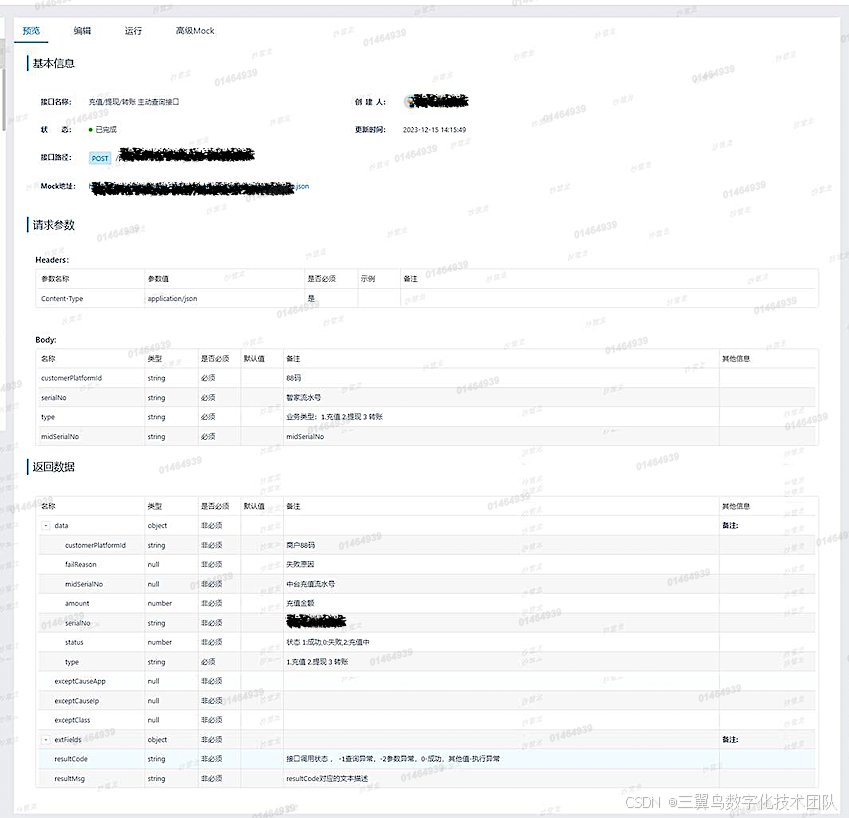
3.2 deepseek--快速生成入参格式
背景
在用postman或者其他工具进行接口测试,或者利用大模型进行接口自动化脚本生成时, 都需要手动去编写入参格式,在有大量入参的情况下,需要耗费较多的时间去编写入参,就思考能不能用大模型来做这个枯燥又麻烦的工作。
示例接口
yapi:https://xxxxxx
入参:
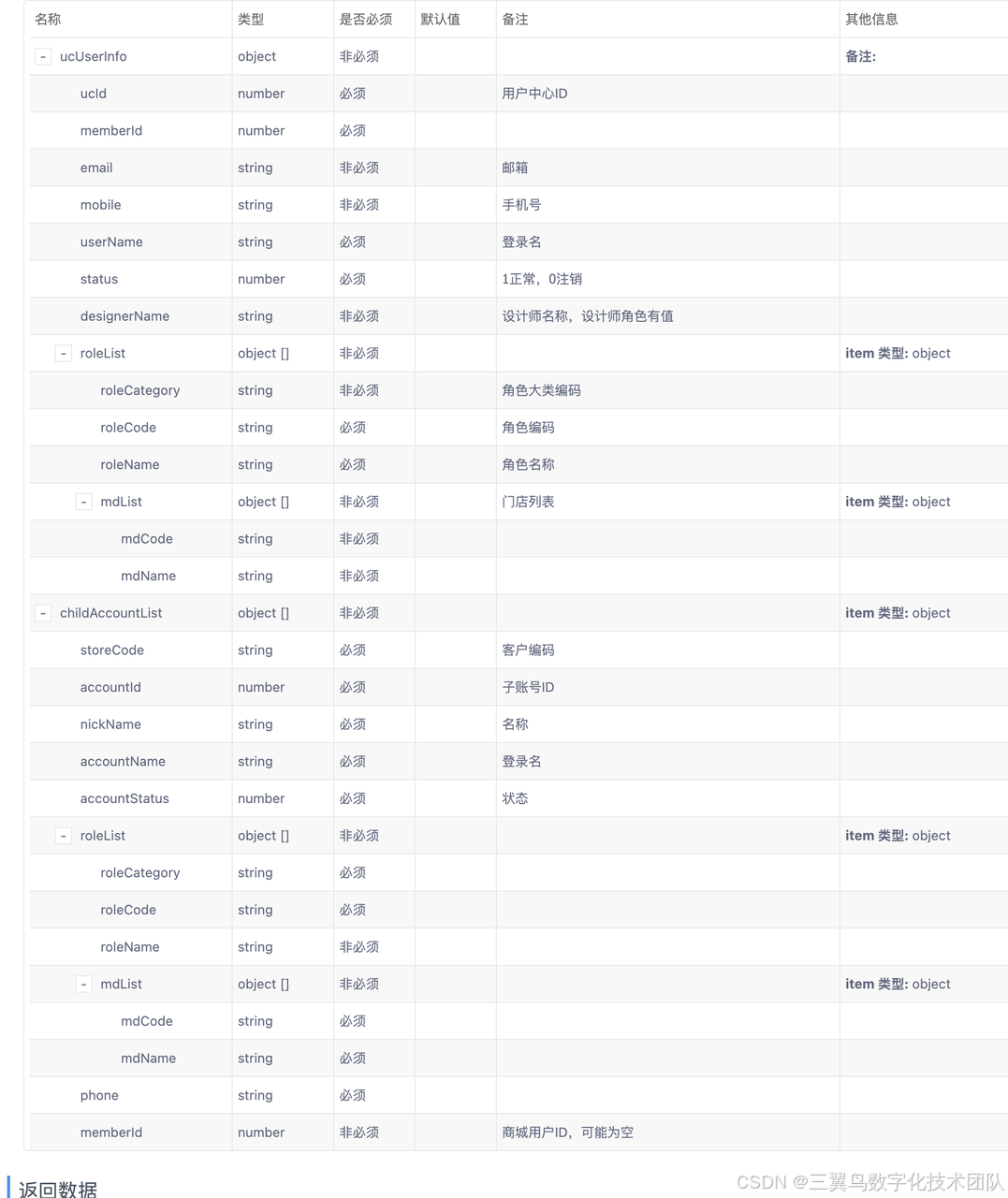
学习历程
1.从yapi上进行数据的摘抄,比较繁琐,所以我直接截图下来。将图片扔给了deepseek。
提示词:“根据名称,类型,生成入参格式”,输出了符合条件的入参格式。并且会根据字段的类型,给了每个字段一个实例。------此次为成功得到自己想要的结果的提示词
{"uclUserInfo": {"ucld": 12345,"memberId": 67890,"email": "user@example.com","mobile": "1234567890","userName": "DesignerName","status": 1},"roleList": [{"roleCategory": "Category1","roleCode": "RoleCode1","roleName": "RoleName1"}],"mdlList": [{"mdCode": "MD001","mdName": "MDName1"}],"childAccountList": [{"storeCode": "Store001","accountId": 111,"nickName": "Nick1","accountName": "Account1","accountStatus": 1}]
}总结
本次文章里提到的接口,属于比较典型的一种接口,拥有繁琐的入参,在进行手工编写入参的时候,经常性的出现类似于字段拼错,类型输错,格式不对等人为失误的情况。通过这种方式的尝试,能够快速和准确的生成,接口需要的入参格式。极大的缩减了自己手动编写的时间,以及准确性。是一种较为简便快捷的应用方案。
3.3 一步生成测试脚本
yapi接口
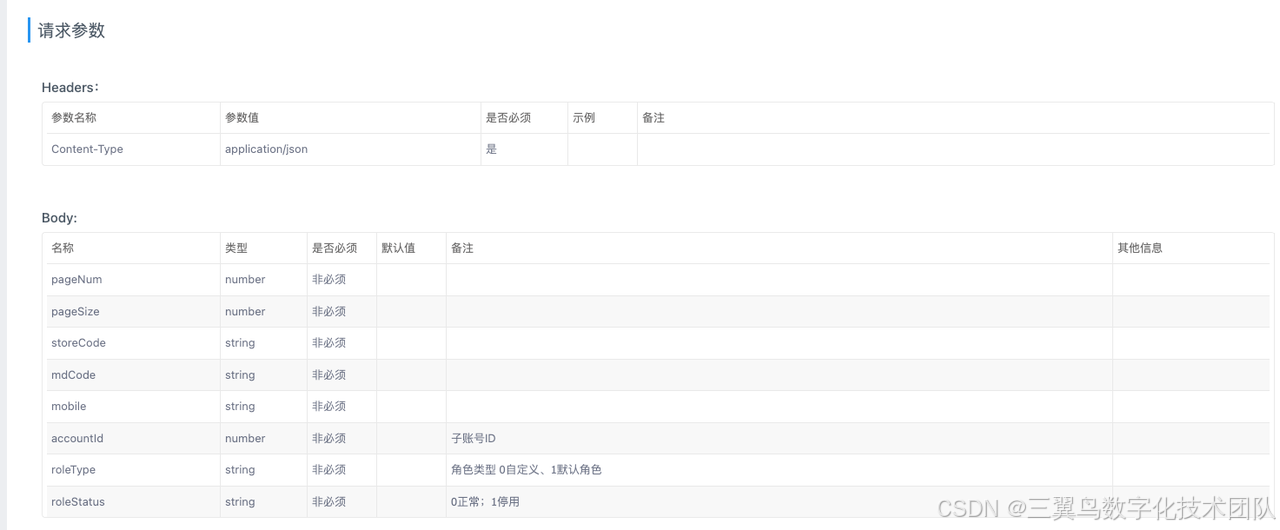
让deepseek进行输出:提示词:
根据入参的body,生成python自动化测试脚本
import requests
import json# 定义 API 的 URL
url = "https://xxxxxx"# 定义请求头
headers = {"Content-Type": "application/json"
}# 定义请求体
body = {"pageNum": 1,"pageSize": 10,"storeCode": "STORE123","mdCode": "MD123","mobile": "13800138000","accountId": 12345,"roleType": "0","roleStatus": "0"
}# 发送 POST 请求
response = requests.post(url, headers=headers, data=json.dumps(body))# 打印响应状态码和响应内容
print(f"响应状态码: {response.status_code}")
print(f"响应内容: {response.json()}")# 断言响应状态码是否为 200
assert response.status_code == 200, f"预期状态码为 200,实际为 {response.status_code}"print("测试通过!响应状态码为 200。")入参的值,需要进行手动的修改。改为自己需要的入参值。后续可以针对入参进行参数化处理
扩展
如果需要测试多个场景,可以将
body参数化,使用循环或数据驱动的方式测试不同的输入组合。可以将响应内容进一步解析,验证具体的字段值是否符合预期。
3.4 参数化
方法 1:使用列表或字典存储多组参数
将多组 body 参数存储在一个列表或字典中,然后通过循环遍历每组参数发送请求。
import requests
import json# 定义 API 的 URL
url = "https://xxxxx"# 定义请求头
headers = {"Content-Type": "application/json"
}# 定义多组 body 参数
test_cases = [req:{ "pageNum": 1,"pageSize": 10,"storeCode": "STORE123","mdCode": "MD123","mobile": "13800138000","accountId": 12345,"roleType": "0","roleStatus": "0"},rsp:{"asas":123123}{"pageNum": 1,"pageSize": 10,"storeCode": "STORE123","mdCode": "MD123","mobile": "13800138000","accountId": 12345,"roleType": "0","roleStatus": "0"},{"pageNum": 2,"pageSize": 20,"storeCode": "STORE456","mdCode": "MD456","mobile": "13900139000","accountId": 67890,"roleType": "1","roleStatus": "1"},{"pageNum": 3,"pageSize": 30,"storeCode": "STORE789","mdCode": "MD789","mobile": "13700137000","accountId": 54321,"roleType": "0","roleStatus": "0"}
]# 遍历每组参数并发送请求
for index, body.res in enumerate(test_cases, start=1):print(f"正在测试第 {index} 组参数: {body}")# 发送 POST 请求response = requests.post(url, headers=headers, data=json.dumps(body))# 打印响应状态码和响应内容print(f"响应状态码: {response.status_code}")print(f"响应内容: {response.json()}")# 断言响应状态码是否为 200assert response.status_code == 200, f"第 {index} 组参数测试失败,预期状态码为 200,实际为 {response.status_code}"print(f"第 {index} 组参数测试通过!\n")print("所有测试用例执行完毕!")方法 2:从外部文件读取参数
将测试参数存储在外部文件(如 JSON 文件、CSV 文件或 Excel 文件)中,然后在脚本中读取文件内容并参数化。
示例:从 JSON 文件读取参数
1. 创建一个 JSON 文件 test_data.json,内容如下:
[{"pageNum": 1,"pageSize": 10,"storeCode": "STORE123","mdCode": "MD123","mobile": "13800138000","accountId": 12345,"roleType": "0","roleStatus": "0"},{"pageNum": 2,"pageSize": 20,"storeCode": "STORE456","mdCode": "MD456","mobile": "13900139000","accountId": 67890,"roleType": "1","roleStatus": "1"}
]2.修改脚本,从 JSON 文件中读取参数:
import requests
import json# 定义 API 的 URL
url = "https://xxxxx"# 定义请求头
headers = {"Content-Type": "application/json"
}# 从 JSON 文件中读取测试数据
with open("test_data.json", "r", encoding="utf-8") as file:test_cases = json.load(file)# 遍历每组参数并发送请求
for index, body in enumerate(test_cases, start=1):print(f"正在测试第 {index} 组参数: {body}")# 发送 POST 请求response = requests.post(url, headers=headers, data=json.dumps(body))# 打印响应状态码和响应内容print(f"响应状态码: {response.status_code}")print(f"响应内容: {response.json()}")# 断言响应状态码是否为 200assert response.status_code == 200, f"第 {index} 组参数测试失败,预期状态码为 200,实际为 {response.status_code}"print(f"第 {index} 组参数测试通过!\n")print("所有测试用例执行完毕!")方法 3:动态生成参数
如果需要动态生成参数,可以使用 Python 的 faker 库或随机生成数据。
示例代码
import requests
import json
from faker import Faker# 初始化 Faker
fake = Faker()# 定义 API 的 URL
url = "https://xxxxxx"# 定义请求头
headers = {"Content-Type": "application/json"
}# 动态生成测试数据
def generate_test_data(num_cases):test_cases = []for _ in range(num_cases):body = {"pageNum": fake.random_int(min=1, max=10),"pageSize": fake.random_int(min=10, max=50),"storeCode": fake.bothify(text="STORE###"),"mdCode": fake.bothify(text="MD###"),"mobile": fake.phone_number(),"accountId": fake.random_int(min=10000, max=99999),"roleType": fake.random_element(elements=("0", "1")),"roleStatus": fake.random_element(elements=("0", "1"))}test_cases.append(body)return test_cases# 生成 5 组测试数据
test_cases = generate_test_data(5)# 遍历每组参数并发送请求
for index, body in enumerate(test_cases, start=1):print(f"正在测试第 {index} 组参数: {body}")# 发送 POST 请求response = requests.post(url, headers=headers, data=json.dumps(body))# 打印响应状态码和响应内容print(f"响应状态码: {response.status_code}")print(f"响应内容: {response.json()}")# 断言响应状态码是否为 200assert response.status_code == 200, f"第 {index} 组参数测试失败,预期状态码为 200,实际为 {response.status_code}"print(f"第 {index} 组参数测试通过!\n")print("所有测试用例执行完毕!")4. 总结成功使用的方案
找到目标接口的yapi地址
截取含有header和body内容的截图
在deepseek上传截图,以及输入提示词
url: https://xxxxxxx
请求方法:post
响应格式:JSON
响应状态码:200
测试场景:根据名称,类型生成入参格式
断言:状态码为200
得到需要的目标脚本
5. 后续研究的方向
1.接口入参的自动生成(自动化场景生成)
2.根据不同的CASE,生成不同的断言
3.API-Agent搭建
6. 团队介绍
「三翼鸟数字化技术平台-质量保障与测试团队」负责为各业务团队的产品交付提供质量保障。制定软件测试流程规范及准入准出标准保障业务正确性;开发自动化测试工具支撑性能测试、兼容性测试、异常测试等测试活动保障产品稳定性;通过代码扫描,权限合规检查等专项测试保障产品符合安全标准;搭建Tone测试一体化平台实现Mock服务,流量录制及回放等提效关键能力,并与Z·ONE平台协同实现软件交付全流程提效。











)



运行自动化测试)

 G Wafu! 题解)

)