研究背景
在新能源汽车的热管理仿真研究中,神经网络训练技术常被应用于系统降阶建模。通过这一方法,可以构建出高效准确的代理模型,进而用于控制策略的优化、系统性能的预测与评估,以及实时仿真等任务,有效提升开发效率并降低计算成本。
虽然神经网络的强大能力离不开大数据的驱动,但在现实世界中,收集足够规模的真实数据却是一项常见且艰巨的挑战。数据匮乏极大地制约了模型的性能与发展。为此,我们常常需要借助仿真的力量来“创造”数据,填补这一空白。所采用的蒙特卡洛仿真方法,犹如一个强大的“数据发生器”,它通过建立数学模型并执行大量随机模拟,能够经济、高效地生成逼近现实的仿真数据集,从而为神经网络的训练提供坚实的数据支撑,破解了数据短缺的困局。
接下来将以AMESim中的自带空调系统的蒙特卡洛仿真案例展开介绍。
蒙特卡洛仿真
第一步:将需要蒙特卡洛仿真的部分提取出来
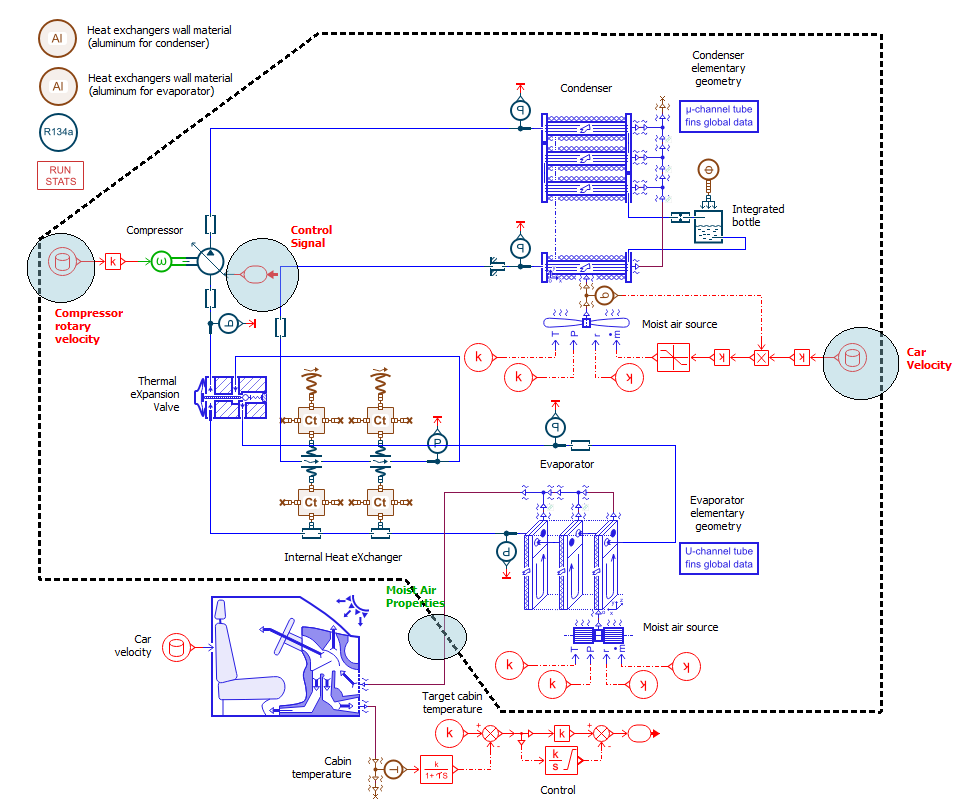
第二步:边界参数定义
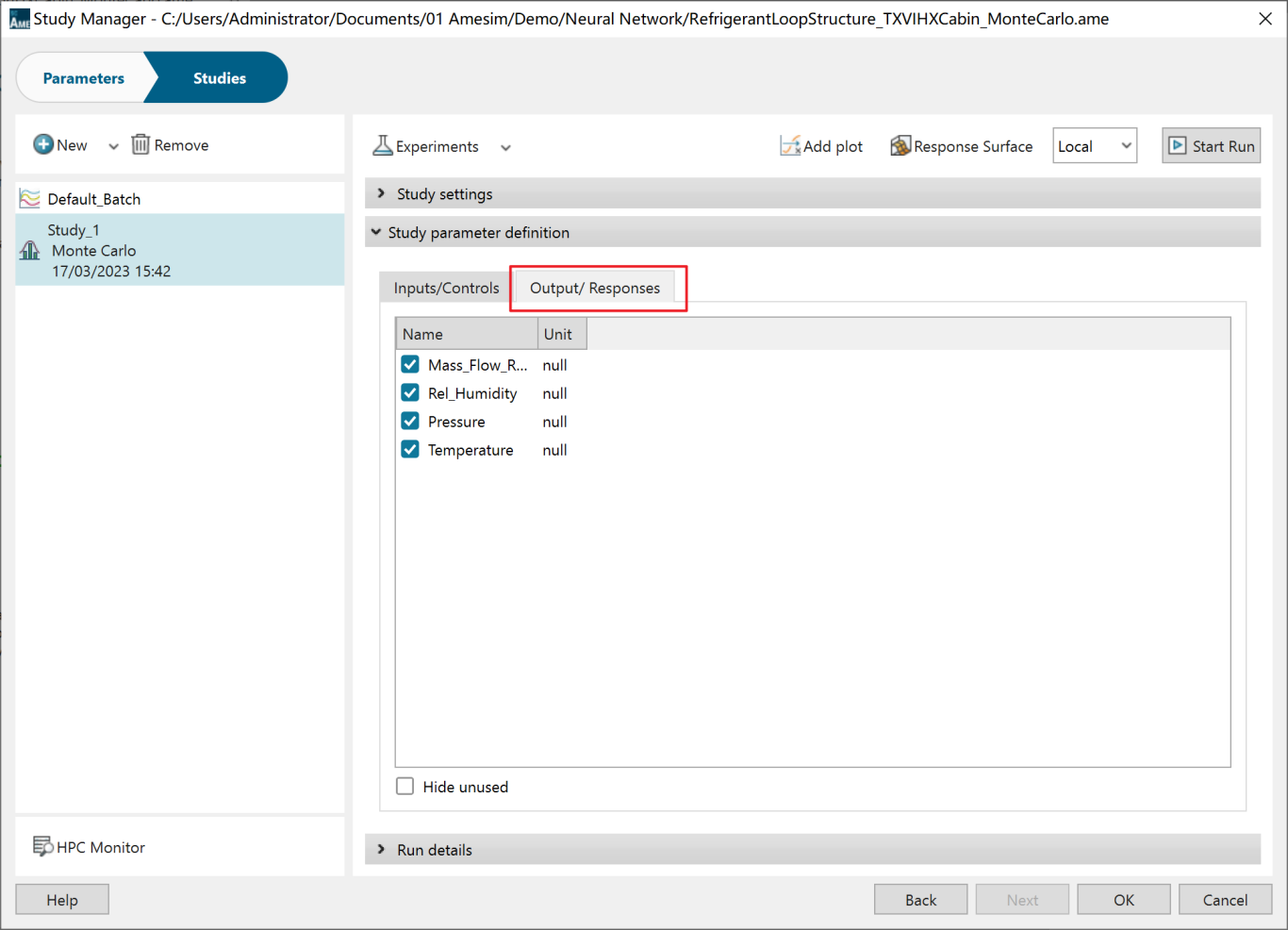
在SIMULATION窗口下,进入Study Manager界面,定义系统的出入输出变量。
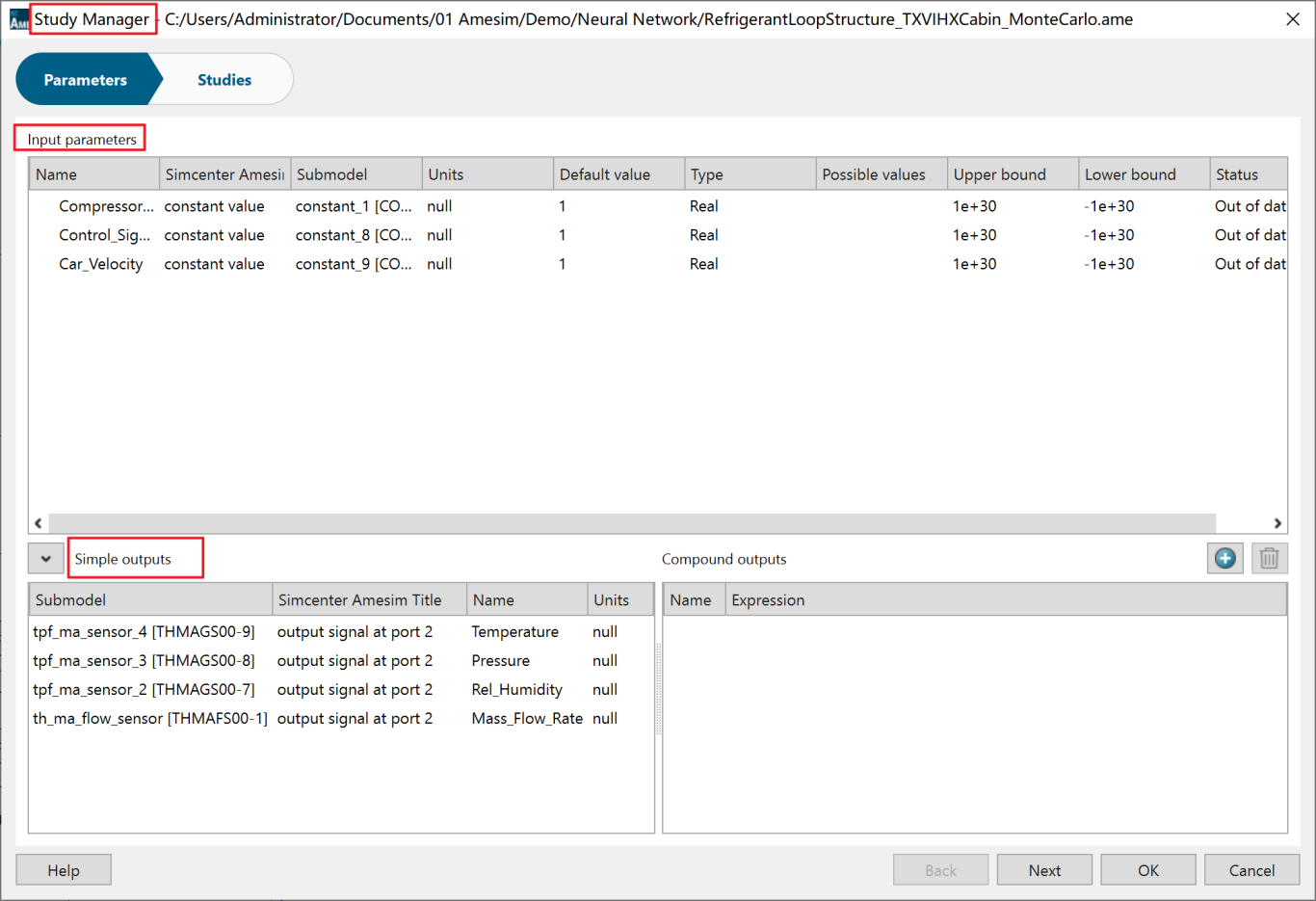
第三步:蒙特卡洛仿真定义
进入Study Manager-Studies界面,新建Monte Carlo,并定义相关参数。Study setting下Sample Method中选择Latin Hypercube;Parameter中Number of runs定义的是该seeds下计算的数据组数量,此处设置为2000;Seeds的定义则是为了贵部不同seeds之间的数据重复。
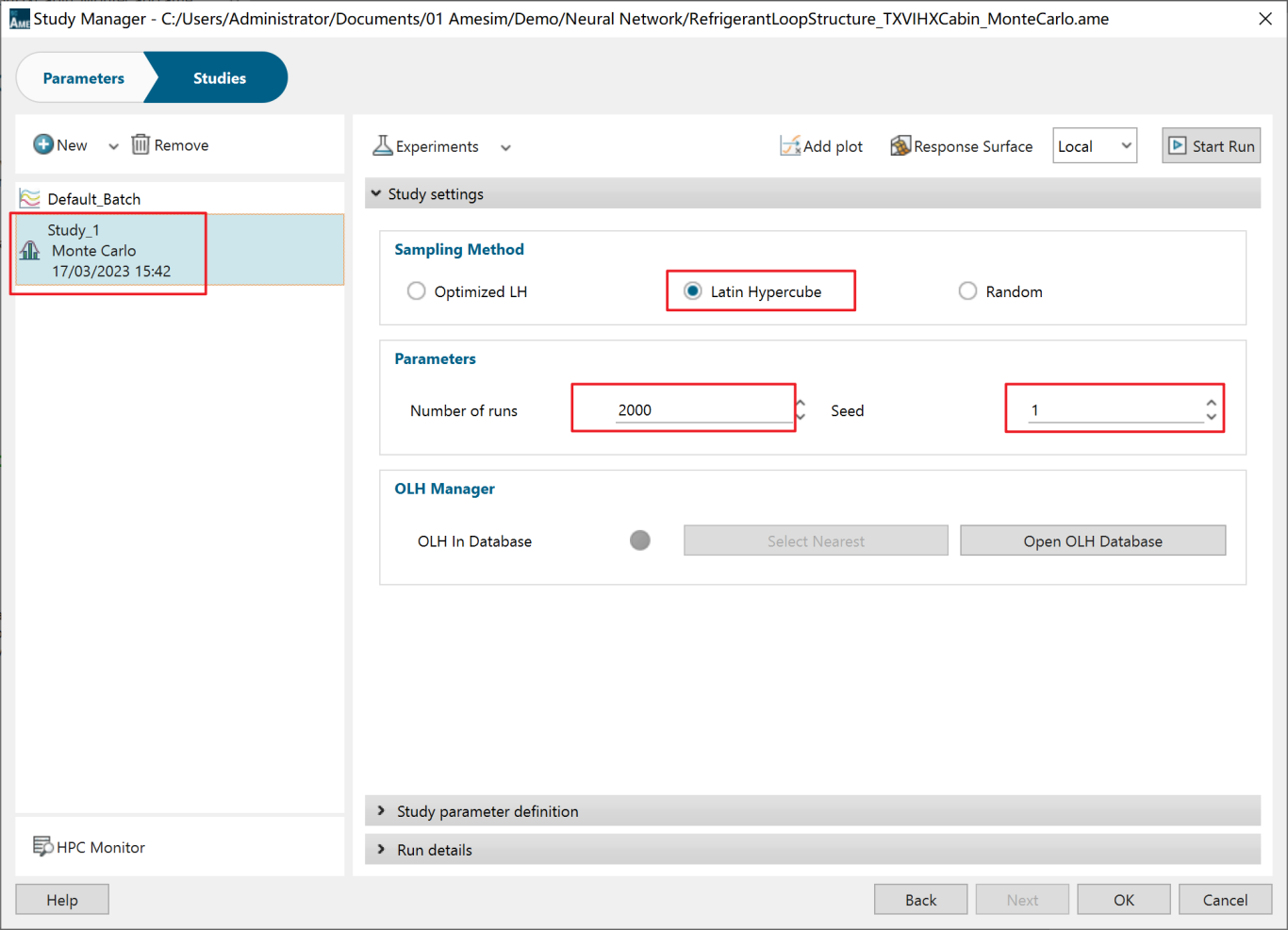
第四步:研究参数定义
Study parameter definition中定义输入参数。其中参数的分布类型可以选择uniform(均匀分布)与Gaussian(高斯分布)。对于流量信息、压缩机转速等信息,可使用均匀分布。对于温度信息(如蒸发器的进风温度),可使用高斯分布。如下图所示本案例将三个变量均设置为Uniform(均匀分布)。其中压缩机转速设置的参数为2000±1500转范围内波动。
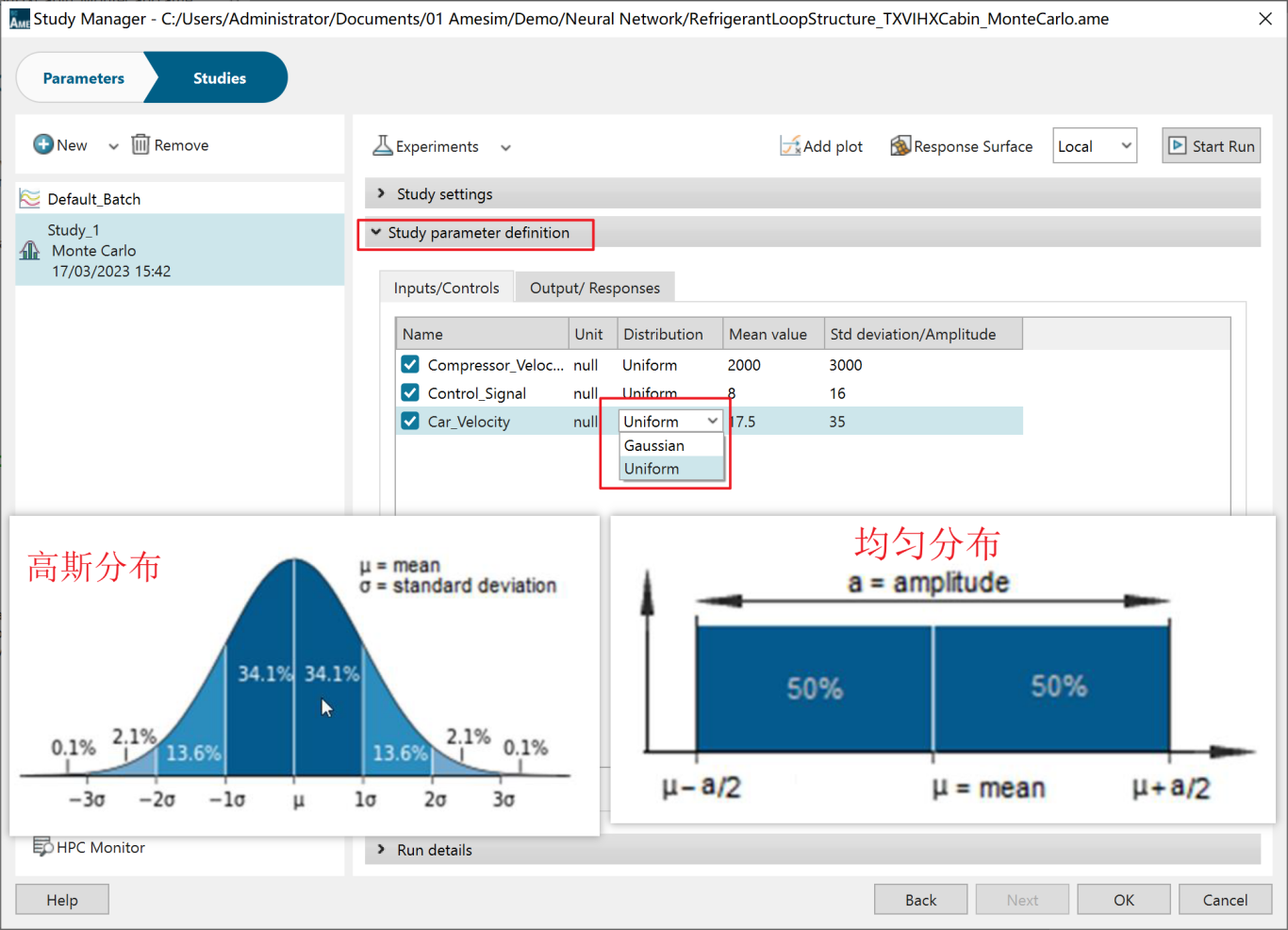
针对输出参数,可以通过勾选来决定是否对该参数进行研究。此案例中全部勾选,对所有参数进行研究。
第五步:开始仿真
点击右上角的Start Run开始蒙特卡洛计算。
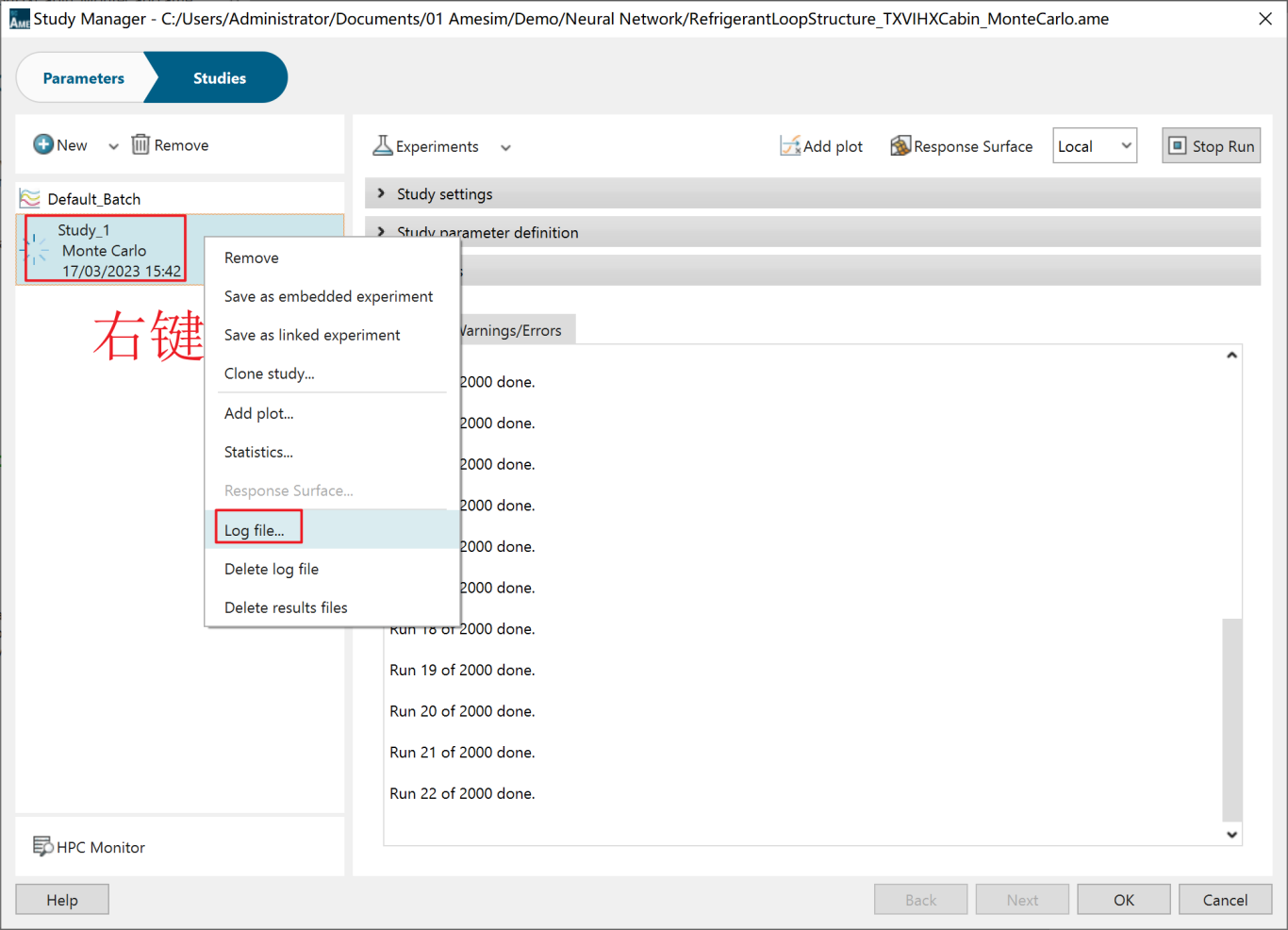
最后,对计算的结果查看并导出。选中Study_1 Monte Carlo右键,选择Log file对仿真数据查看。
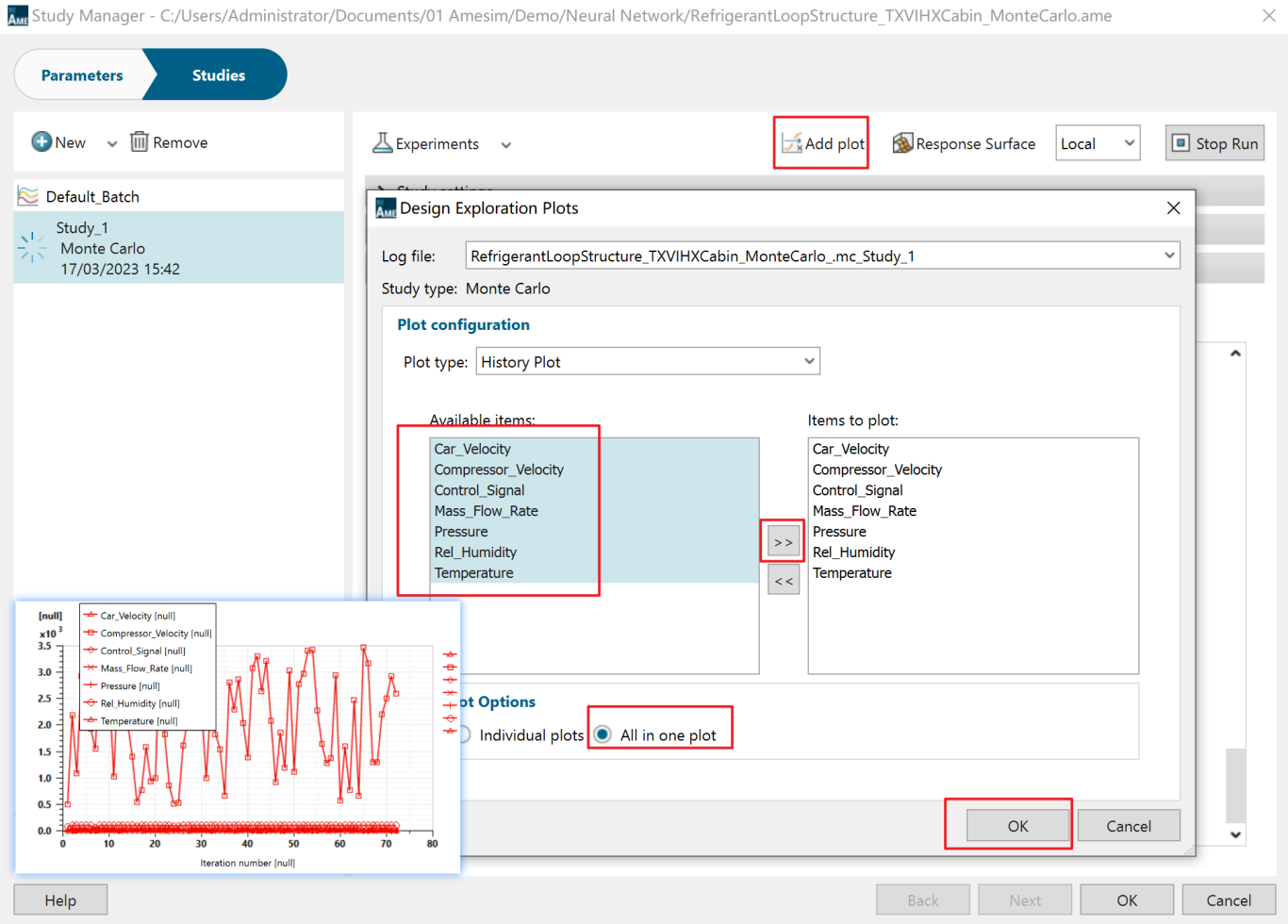
同时,也让可以点击Add Plot 选择需要查看的数据,如下图所示。其中下方的Individual Plots是将选择的数据,每个单独显示;All in one Plot是将所有的数据一个图中显示,如下图左下角所示。
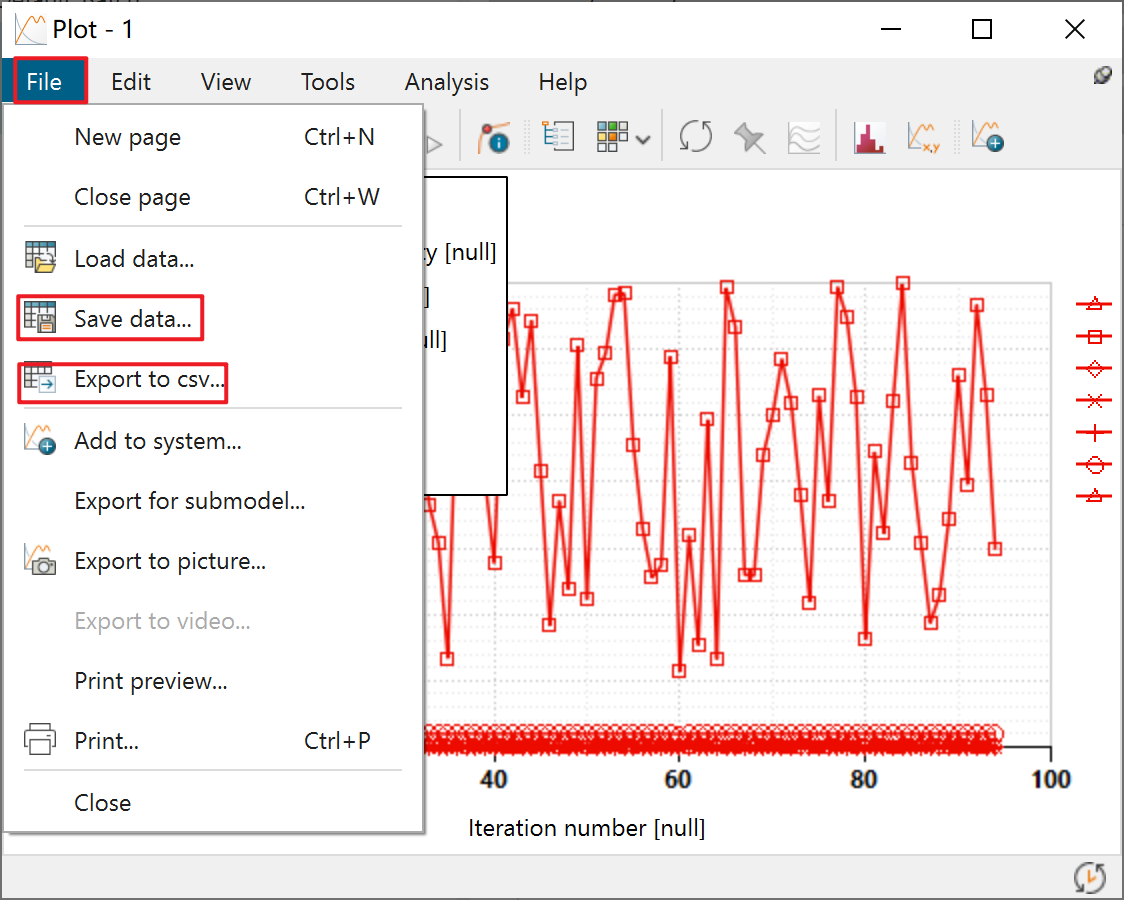
数据导出则是在Plot中选择Save datahuo Export to csv。
总结
以上是Monte Carlo 仿真在 AMESim 中的具体应用方法。在面向整车热管理的神经网络训练任务中,蒙特卡洛仿真能够有效弥补训练样本不足的瓶颈问题。通过大量随机抽样与概率模拟,它可生成覆盖多工况、多参数的合成数据集,从而为数据驱动的建模方法提供充分的学习素材。然而需注意的是,在开展蒙特卡洛仿真之前,必须确保所使用的整车热管理模型具备足够的精度与可靠性,以保证仿真输出结果符合物理实际。只有在模型置信度较高的前提下,基于仿真所生成的数据才能有效支撑神经网络训练,进而获得泛化能力强、可应用于实际控制与优化场景的可靠代理模型。下一篇文章中,我们将进一步介绍如何利用蒙特卡洛仿真所生成的数据集,进行神经网络的结构设计、训练与验证。
















)
)

