系列文章目录
初识CNN01——认识CNN
初识CNN02——认识CNN2
初识CNN03——预训练与迁移学习
初识CNN04——经典网络认识
文章目录
- 系列文章目录
- 一、GoogleNet——Inception
- 1.1 1x1卷积
- 1.2 维度升降
- 1.3 网络结构
- 1.4 Inception Module
- 1.5 辅助分类器
- 二、ResNet——越深越好
- 总结
一、GoogleNet——Inception
GoogLeNet(Inception v1)是谷歌团队在2014年ImageNet大规模视觉识别挑战赛(ILSVRC 2014)中夺得分类任务冠军的深度学习模型。它的主要创新在于保持深度的同时大幅减少了参数量(约600万参数,仅为AlexNet的1/10到1/12),并引入了Inception模块、辅助分类器等结构来提升性能并缓解梯度消失问题。
1.1 1x1卷积

当卷积核大小为1时,我们可以将其用于通道融合。以一个三通道RGB图像为例:
import torch
import cv2
import torch.nn as nn
from matplotlib import pyplot as plt@torch.no_grad()
def gray():# input:RGB图片img = cv2.imread("./images/a.jpg")img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)print(img.shape)# 1 x 1卷积con1_1 = nn.Conv2d(in_channels=3,out_channels=1,kernel_size=1,stride=1,padding=0,bias=False,)print(con1_1.weight.data.shape)# 常规转换公式:0.2989R + 0.5870G + 0.1140B# 修改权重参数con1_1.weight.data = torch.Tensor([[[[0.2989]], [[0.5870]], [[0.1140]]]])print(con1_1.weight.data.shape)# 使用卷积核处理图像out = con1_1(torch.Tensor(img).permute(2, 0, 1).unsqueeze(0))print(out.shape)# 显示图片plt.imshow(out.squeeze(0).permute(1, 2, 0).numpy(), cmap="gray")plt.show()if __name__ == "__main__":gray()

1.2 维度升降
- 瓶颈结构
借助1x1卷积我们可以设计这种两头宽,中间窄的网络结构。如果一个输入特征大小为N1×H×W, 使用N1×N2个1×1卷积,就可以将其 映射为N2×H×W大小的特征。当N1>N2,就实现了通道降维。
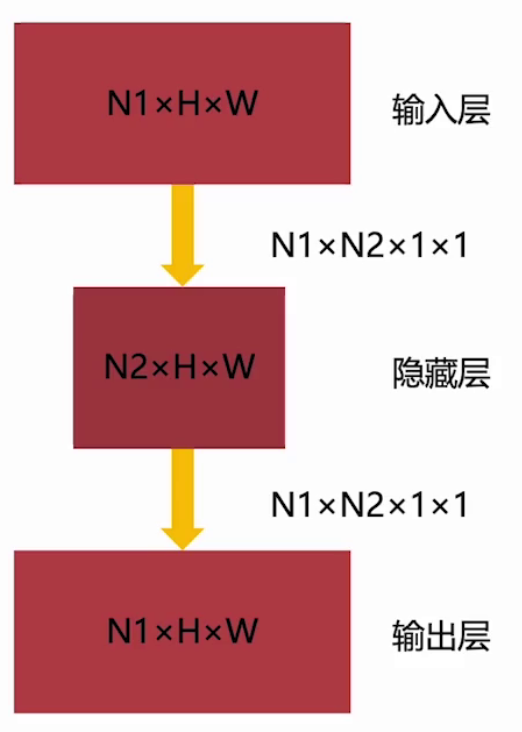
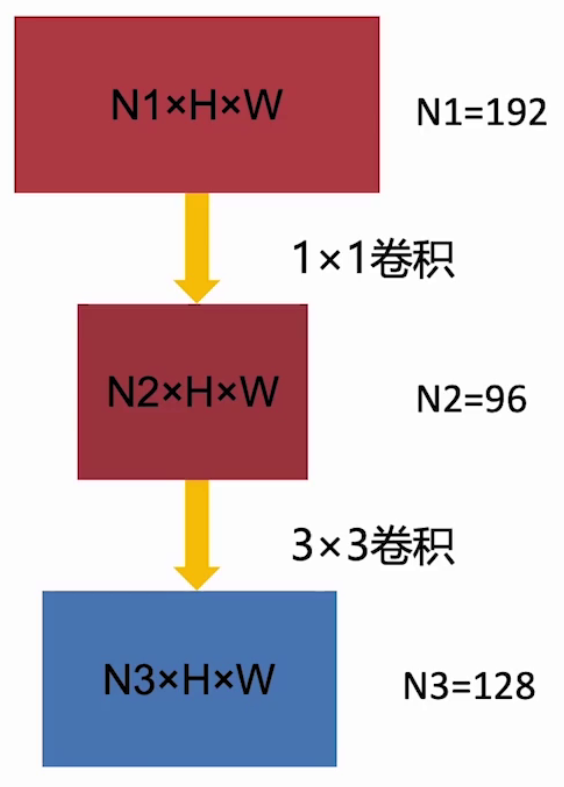
可以通过以上结构完成参数压缩:
假设输入通道数为192,输出通道数为128,则普通3×3卷积,参数量为128×192×3×3=221184,而先使用1×1卷积进行降维到96个通道,然后再用3×3升维到128
,则参数量为:96×192×1×1+128×96×3×3=129024。
- 纺锤结构
与瓶颈结构类似,不过是两头窄,中间宽的网络结构。
1.3 网络结构
网络结构如下图所示,可以看到为多尺度,更宽,分组的网络设计:

1.4 Inception Module
从以上的结构图中可以看到一个反复出现的单词Inception,该结构由谷歌的研究人员在2014年提出,它的名字来源于电影《盗梦空间》,因为它设计时使用了多个并行的卷积神经网络模块,这些模块之间形成了一个嵌套的结构,就像人在梦中穿梭于不同场景中一样。
Inception结构是对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图,且不同大小卷积核的卷积运算可以得到图像中的不同信息,处理获取到的图像中的不同信息可以得到更好的图像特征,一个Inception结构如下图所示。
其中1x1卷积的位置如果放置在前,通道降维;如果放置在后,更好地维持性能

Inception结构的思想和之前的卷积思想不同,LeNet-5模型是将不同的卷积层通过串联连接起来的,但是Inception结构是通过串联+并联的方式将卷积层连接起来的。
Inception结构通常用于图像分类和识别任务,因为它能够有效地捕捉图像中的细节信息。它的主要优势在于能够以高效的方式处理大量的数据,并且模型的参数量相对较少,这使得它能够在不同的设备上运行。
1.5 辅助分类器
在以上网络结构中,有些分支在中间层就进行了softmax操作得到结果,这个结构叫做辅助分类器。在GoogLeNet中有两个辅助分类器,分别在Inception4a和Inception4d,它们的结构如下图所示:

辅助分类器通常与主要的分类器结合使用,以帮助模型更好地理解图像中的细节和复杂模式。这种技术可以提高模型的泛化能力,使其更准确地预测未知的图像。训练时,额外的两个分类器的损失权重为0.3,推理时去除。
二、ResNet——越深越好
ResNet(Residual Network,残差网络)是由何恺明等人于2015年提出的深度卷积神经网络架构。它通过引入残差学习和跳跃连接(Skip Connection),有效解决了极深神经网络中的梯度消失和网络退化问题,使得训练数百甚至上千层的网络成为可能,并在ImageNet等竞赛中取得了突破性成果。
2.1 梯度消失
深层网络有个梯度消失问题:模型变深时,其错误率反而会提升,该问题非过拟合引起,主要是因为梯度消失而导致参数难以学习和更新。

想要理解这个问题我们需要回忆反向传播与链式法则,即神经网络通过梯度下降来更新权重。梯度通过反向传播计算,从输出层一路通过链式法则 乘到输入层。对于一个 L 层的网络,第 l 层的梯度是它之后所有层梯度的乘积。
现在想象一下,在反向传播时,梯度需要连续乘以这些很小的导数(比如0.1, 0.25)。经过多层之后,这个连乘的结果会指数级地趋近于零。这意味着,对于靠近输入层的网络层(浅层),计算出的梯度值几乎为零。
2.2 Residual结构
Residual结构即残差结构,有两种不同的残差结构,在ResNet-18和ResNet-34中,用的如下图中左侧图的结构,在ResNet-50、ResNet-101和ResNet-152中,用的是下图中右侧图的结构。

上图左图可看到输入特征的channels是64,经过一个3x3的卷积核卷积之后,进行Relu激活,再经过一个3x3的卷积核进行卷积,但并没有直接激活。并且可以看到,在主分支上有一个圆弧的线从输入特征矩阵直接到加号,这个圆弧线是shortcut(捷径分支),它直接将输入特征矩阵加到经过第二次3x3的卷积核卷积之后的输出特征矩阵,再经过Relu激活函数进行激活。
在传统网络中我们是直接学习的期望映射y=H(x)y=H(x)y=H(x),这种映射能处理大多数关系,但对于恒等关系,即输入与输出相等的映射,拟合效果很差。但如果使用映射关系y=F(x)+xy=F(x)+xy=F(x)+x,那么若某层的最优映射接近恒等映射,那么学习残差 F(x)F(x)F(x) 逼近 0 比学习一个完整的恒等映射要容易得多。

通过使用残差连接,使得更深的网络具有更低的错误率。

总结
本文主要介绍了经典网络中的GoogleNet以及ResNet,主要是对于1x1卷积核的使用以及残差结构的理解,而非具体网络细节。


: DAPO,VAPO,GMPO,GSPO, CISPO,GFPO)

)


)






)

)


