介绍
实例分割(instance segmentation)的目的是从图像中分割出每个目标实例的掩模(mask)。与语义分割相比,实例分割不但要区分不同的类别,还要区分出同一种类别下的不同目标实例。如图13-1所示

语义分割的结果中,不同的羊对应的标签是一样的,即都被分配为“羊”的类别,而实例分割的结果中,不同的羊的类别标签一样,但是会有不同的实例号:与目标检测相比,实例分割需要在每个包围盒内再进一步将目标的掩模分割出来。因此,实例分割任务是语义分割任务与目标检测任务的结合。一句话,划分的更加仔细了。
在本章中,我们将介绍经典的基于深度学习的实例分割方法Mask R-CNN,并动手实现相应的实例分割框架。
数据集和度量
由于实例分割与目标检测之间有着紧密的联系,用于这两种任务的数据集和度量也很类似。 MS COCO是最常用的实例分割数据集,mAP是实例分割的评价指标。与目标检测不同的是,这里的mAP是通过Mask IoU进行度量。同目标检测中的Box IoU类似,而不是AP的平均,对于图像中的一个目标,令其真实的掩模内部的像素集合为A,一个预测的掩模内部的像素集合为B,Mask真实掩模预测掩模 IoU通过这两个掩模内像素集合的IoU来度量两个掩模的重合度:

图13-2中黄色部分的面积除以红色的面积。与目标检测中计算mAP的过程一样,对每种类别,通过调节Mask IoU的阈值,可以得到该类掩模交集掩模并集别实例分割结果的PR曲线,PR曲线下方的面积即为该类别实例分割结果的AP,所有类别实例分割结果的AP的平均即为mAP。
Mask R-CNN
既然实例分割结合了目标检测和语义分割,那么实现实例分割的一个很直接的思路就是先进行目标检测,然后在每个预测包围盒里做语义分割。著名的Mask R-CNN模型采用的就是这一思路,从模型的命名可以看出,这是R-CNN系列工作的延续。Mask R-CNN也是由何恺明、Georgia Gkioxari、Piotr Dollar和Ross Girshick提出的,获得了2017年国际计算机视觉大会(International Conference on Computer Vision,ICCV)最佳论文奖一马尔奖(Marr Prize). Mask R-CNN的结构如图I3-3所示。
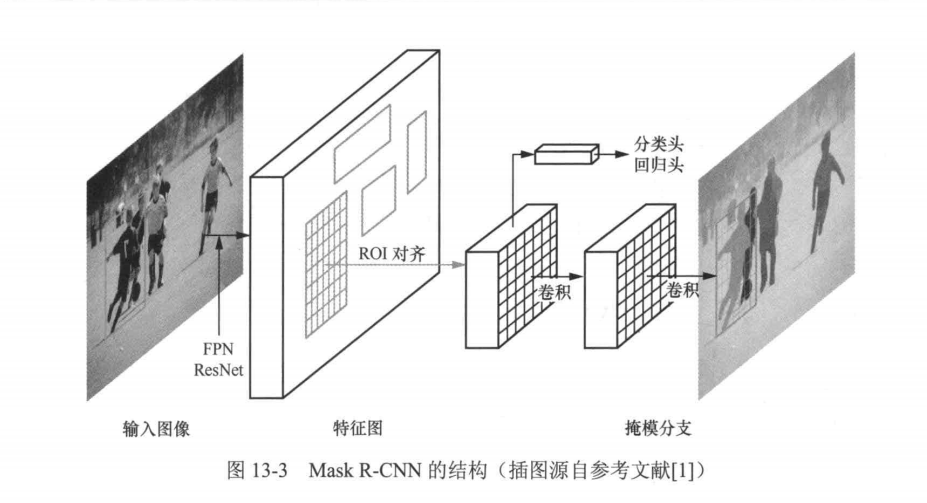
不难发现,Mask R-CNN是Faster R-CNN的拓展,它们之间的主要区别有3点:
(1)引入特征金字塔网络(feature pyramid network,FPN)与ResNet一起作为主干网络。 FPN作为一种融合多尺度特征信息的手段,在视觉领域有着非常广泛的应用;
(2)提出感兴趣区域对齐(ROI align)取代Faster R-CNN中的ROI池化作为目标区域的特征提取器,用于提取整个候选区域特征并将候选区域特征图尺寸归一化到统一大小,用于后续的预测;
(3)增加了一个用于预测掩模的分支,该分支与分类头和回归头并行。
特征金字塔网络(FPN)
由于图像中的目标大小各不相同,为了能够检测到不同大小的目标,目标检测模型通常需要多尺度检测架构。
图13-4展示了4种不同的用于目标检测的特征提取框架。
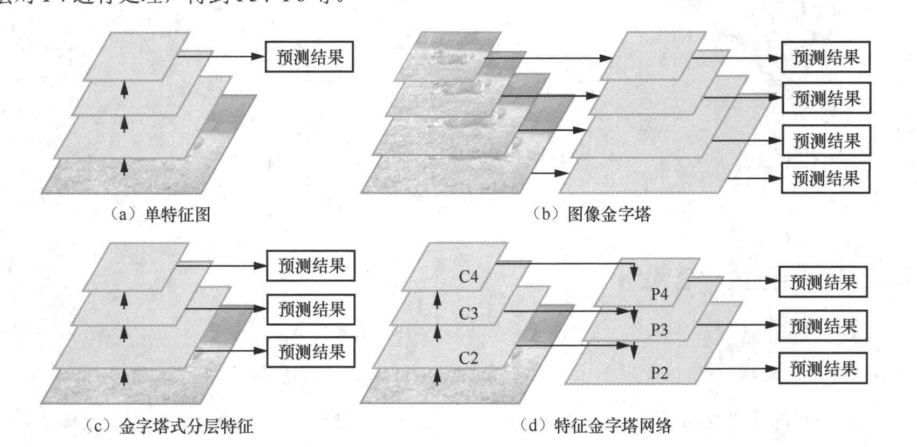
图13-4(a)这种架构只在主干网络的最后一层卷积层输出的特征图上做目标检测,故该架构最大的问题是对小目标的检测效果不理想。这是因为小尺度目标的特征会随着主干网络逐层下采样逐渐消失,在最后一层仅有少量的特征支持小目标的精准检测。
图13-4(b)是早期的目标检测算法常用的图像金字塔结构,它通过将输入图像缩放到不同尺度来构建图像金字塔,随后主干网络通过处理这些不同尺度的图像来得到不同尺度的特征图,最后分别在每个尺度的特征图上做目标检测。不难看出,使用图像金字塔最大的问题是主干网络的多次推理会带来计算开销的成倍增长。
图13-4(c)展示的网络架构从主干网络的多个层级都输出特征图,然后在不同空间分辨率的特征图上进行独立的目标检测。显然,这种结构并没有进行不同层之间的特征交互,既没有给深层特征赋予浅层特征擅长定位小目标的能力,也没有给浅层的特征赋予深层蕴含的语义信息,因此对目标检测效果的提升有限。
图13-4(d)展示了FPN的架构。FPN的主要思想是构建一个特征金字塔,将不同层级的特征图融合到一起,从而实现不同大小目标的检测。
具体而言,类似图13-4(C),FPN先使用一个主干网络得到每个层级的特征图,从下到上分别命名为C2、C3、C4,其中的数字2、3 、4(直到 l),代表特征图空间分辨率为原图的1/2,由此得到的深层的特征图空间分辨率小,浅层的特征图空间分辨率大,这一过程称为自底向上。在此之后,FPN构建了一个自顶向下的路径来对不同空间分辨率的特征图进行融合。首先FPN直接输出空间分辨率最小的特征图[图13-4(d)右边第3层,顶层],记为P4,然后对P4进行2倍的上采样,使其空间分辨率大小和C3特征图的空间分辨率保持一致,再通过1×1卷积调整C3的通道数,使其与P4的通道数一致,并将两者进行相加,得到融合的特征图P3[图13-4(d)右边第2层],这一过程称为横向连接。这种融合方式迭代地在每层执行,上一层不断与下一层融合,从而实现自顶向下的效果。通过这种方式,FPN可以获取多个尺度的特征,并将这些特征融合在一起,形成了P2、P3、P4,从而提高对多尺度目标检测的准确性和效率。
FPN代码实现(基于PyTorch)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models.resnet import resnet50class FPN(nn.Module):def __init__(self, backbone=resnet50(pretrained=True)):super(FPPN, self).__init__()self.backbone = backbone# Lateral connectionsself.lateral5 = nn.Conv2d(2048, 256, 1)self.lateral4 = nn.Conv2d(1024, 256, 1)self.lateral3 = nn.Conv2d(512, 256, 1)self.lateral2 = nn.Conv2d(256, 256, 1)# Smooth layersself.smooth5 = nn.Conv2d(256, 256, 3, padding=1)self.smooth4 = nn.Conv2d(256, 256, 3, padding=1)self.smooth3 = nn.Conv2d(256, 256, 3, padding=1)self.smooth2 = nn.Conv2d(256, 256, 3, padding=1)# Extra layersself.conv6 = nn.Conv2d(2048, 256, 3, stride=2, padding=1)self.conv7 = nn.Conv2d(256, 256, 3, stride=2, padding=1)def forward(self, x):# Bottom-up pathway (backbone)c1 = self.backbone.conv1(x)c1 = self.backbone.bn1(c1)c1 = self.backbone.relu(c1)c1 = self.backbone.maxpool(c1)c2 = self.backbone.layer1(c1)c3 = self.backbone.layer2(c2)c4 = self.backbone.layer3(c3)c5 = self.backbone.layer4(c4)# Top-down pathwayp5 = self.lateral5(c5)p4 = self.lateral4(c4) + F.interpolate(p5, scale_factor=2, mode='nearest')p3 = self.lateral3(c3) + F.interpolate(p4, scale_factor=2, mode='nearest')p2 = self.lateral2(c2) + F.interpolate(p3, scale_factor=2, mode='nearest')# Smoothp5 = self.smooth5(p5)p4 = self.smooth4(p4)p3 = self.smooth3(p3)p2 = self.smooth2(p2)# Extra pyramid levelsp6 = self.conv6(c5)p7 = self.conv7(F.relu(p6))return p2, p3, p4, p5, p6, p7感兴趣区域对齐(ROI)
在ROI池化层中,为了得到固定空间分辨率的ROI特征图(如7像素×7像素)并将其送给后续的预测分支,需要将每个ROI的包围盒顶点坐标取整。在将该ROI切分为7×7共49个子窗口的过程中也需要将每个子窗口的坐标取整,如图13-5所示。

在上述过程中,之所以需要取整,是因为将原始图像的候选区域映射到图像特征图中对应的ROI后,ROI顶点坐标可能是非整数,每一个子窗口的坐标也可能是非整数,而提取的特征图上每个位置坐标为整数。因此,通常需要将浮点数坐标取整到最近的整数坐标。但既然是近似,就会引入误差,从而影响检测算法的性能。为了解决这个问题,ROI对齐不再使用取整来处理非整数坐标,而是直接使用这些坐标,如图13-6所示。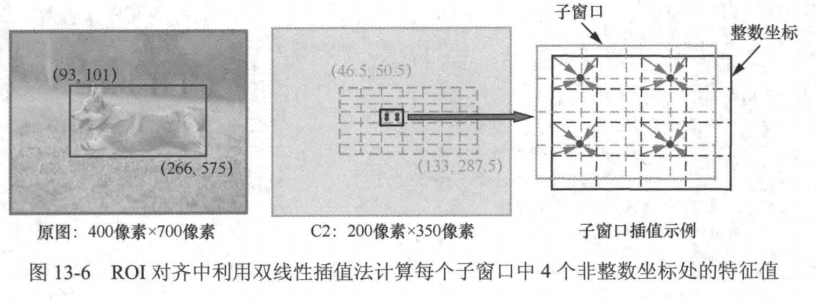
那么如何处理非整数坐标并得到特征图上对应位置的值呢?回忆一下之前学过的双线性插值,对于特征图中的任意一个位置,都可以利用双线性插值的方式得到其对应的数值。在这个过程中不会用到取整操作,因此不会引入因坐标取整导致的偏移误差,这有利于实例分割的精度提升。同ROI池化一样,在ROI对齐中,每个ROI将被均分成M×N个子窗口(图中为7×7个)。随后,将每个子窗口再均分成4个小的子窗口,取这4个小子窗口的中心点,根据每个点在特征图中最近的整数坐标对应的特征值,通过插值来计算各自的特征值,再对这4个值进行最大池化(max pooling)或平均池化(average pooling),得到该子窗口的特征值,最终便可以得到空间分辨率为M像素×N像素的ROI特征图。下面我们将介绍如何用代码实现ROI对齐。
ROI对齐的代码实现
import cv2
import numpy as npdef align_roi(image, roi_coords, output_size=(100, 100)):"""对齐ROI区域到指定尺寸"""x, y, w, h = roi_coordsroi = image[y:y+h, x:x+w]aligned = cv2.resize(roi, output_size, interpolation=cv2.INTER_AREA)return aligned在利用ROI对齐层得到了固定空间分辨率的ROI特征图之后,便可以利用这些特征图进后续的任务。同Faster R-CNN一样,Mask R-CNN在分类和回归分支利用全连接层对ROI进目标类别分类及包围盒回归。与Faster R-CNN不同的是,Mask R-CNN还增加了一条专门用预测掩模的分支
在这一分支中,ROI特征图的大小是14像素×14像素,首先会经过4层卷积层来适应分割任务,随后做2倍上采样得到空间分辨率为28像素×28像的特征图。这是因为空间分辨率大的特征图对于分割精度的提升有正向影响。最后,对该特征图使用1×1卷积层来预测最后的分割结果。
Mask R-CNN
Mask R-CNN的损失函数由三部分组成:分类损失
、包围盒回归损失
和掩模分割损失
。公式如下:
分类损失
采用交叉熵损失,用于衡量预测类别与真实类别的差异:
包围盒回归损失
采用平滑L1损失,用于优化边界框坐标
掩模分割损失
采用逐像素的二值交叉熵损失,用于优化目标的二值掩模
Mask R-CNN的测试阶段
在测试阶段,Mask R-CNN执行以下操作:
- 对候选区域生成包围盒预测和类别预测。
- 对每个包围盒内的目标预测其掩模。
- 对预测的包围盒进行非极大值抑制(NMS),去除冗余的包围盒。
NMS的公式如下:
对于每个类别,按置信度排序,保留最高置信度的包围盒,并移除与其交并比(IoU)超过阈值的其他包围盒:
其中和
为两个包围盒,
为预设阈值(通常为0.5)。
Mask R-CNN代码实现
由于Mask R-CNN代码架构规模比较大,我们将直接调用相关接口进行效果展示。先导入必要的包。
由于Mask R-CNN 和旧版 Keras/TensorFlow 在 Python 3.6 或 3.7 上运行更稳定,所以建议你安装对应的py版本来避免环境问题
下面代码都是在.ipynb文件中运行不同以往
先安装Mask_RCNN
# 导入必要的包
!git clone https://github.com/matterport/Mask_RCNN.git
!cd Mask_RCNN/
!python setup.py install导入和配置
import ospy
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt# Root directory of the project
ROOT_DIR = os.path.abspath("../")# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco%matplotlib inline # Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):utils.download_trained_weights(COCO_MODEL_PATH)# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")Configurations 配置项
我们将使用基于 MS-COCO 数据集训练的模型。该模型的配置参数存放在 coco.py 文件的 CocoConfig 类中。
为了进行推理任务,需要稍微调整配置以适应需求。具体做法是继承 CocoConfig 类并重写需要修改的属性。
class InferenceConfig(coco.CocoConfig):# Set batch size to 1 since we'll be running inference on# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPUGPU_COUNT = 1IMAGES_PER_GPU = 1config = InferenceConfig()
config.display()output:
Configurations:
BACKBONE_SHAPES [[256 256][128 128][ 64 64][ 32 32][ 16 16]]
BACKBONE_STRIDES [4, 8, 16, 32, 64]
BATCH_SIZE 1
BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
DETECTION_MAX_INSTANCES 100
DETECTION_MIN_CONFIDENCE 0.5
DETECTION_NMS_THRESHOLD 0.3
GPU_COUNT 1
IMAGES_PER_GPU 1
IMAGE_MAX_DIM 1024
IMAGE_MIN_DIM 800
IMAGE_PADDING True
IMAGE_SHAPE [1024 1024 3]
LEARNING_MOMENTUM 0.9
LEARNING_RATE 0.002
MASK_POOL_SIZE 14
MASK_SHAPE [28, 28]
MAX_GT_INSTANCES 100
MEAN_PIXEL [ 123.7 116.8 103.9]
MINI_MASK_SHAPE (56, 56)
NAME coco
NUM_CLASSES 81
POOL_SIZE 7
POST_NMS_ROIS_INFERENCE 1000
POST_NMS_ROIS_TRAINING 2000
ROI_POSITIVE_RATIO 0.33
RPN_ANCHOR_RATIOS [0.5, 1, 2]
RPN_ANCHOR_SCALES (32, 64, 128, 256, 512)
RPN_ANCHOR_STRIDE 2
RPN_BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
RPN_TRAIN_ANCHORS_PER_IMAGE 256
STEPS_PER_EPOCH 1000
TRAIN_ROIS_PER_IMAGE 128
USE_MINI_MASK True
USE_RPN_ROIS True
VALIDATION_STEPS 50
WEIGHT_DECAY 0.0001
创建模型并加载已训练权重
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)Class Names 类名称
模型会对物体进行分类并返回类别 ID,这些整数值用于标识每个类别。某些数据集会为类别分配整数值,有些则不会。例如在 MS-COCO 数据集中,'person'类别对应 1,'teddy bear'对应 88。这些 ID 通常是连续的,但并非始终如此——比如 COCO 数据集中就有对应 70 和 72 的类别,但 71 却不存在。
为了提高一致性,并支持同时从多个数据源进行训练,我们的 Dataset 类会为每个类分配自有的顺序整数 ID。例如,若使用我们的 Dataset 类加载 COCO 数据集,'person'类别将获得 class ID=1(与 COCO 相同),而'teddy bear'类别则为 78(与 COCO 不同)。在将类别 ID 映射到类别名称时需注意这一点。
要获取类名列表,您可以加载数据集后使用 class_names 属性,如下所示。
# Load COCO dataset
dataset = coco.CocoDataset()
dataset.load_coco(COCO_DIR, "train")
dataset.prepare()# Print class names
print(dataset.class_names)我们不想让你为了运行这个演示就必须下载 COCO 数据集,所以下面提供了类别名称列表。列表中每个类别名称的索引代表其 ID(第一个类别是 0,第二个是 1,第三个是 2,...以此类推)。
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane','bus', 'train', 'truck', 'boat', 'traffic light','fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird','cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear','zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie','suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball','kite', 'baseball bat', 'baseball glove', 'skateboard','surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup','fork', 'knife', 'spoon', 'bowl', 'banana', 'apple','sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza','donut', 'cake', 'chair', 'couch', 'potted plant', 'bed','dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote','keyboard', 'cell phone', 'microwave', 'oven', 'toaster','sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors','teddy bear', 'hair drier', 'toothbrush']运行目标检测
# Load a random image from the images folder
file_names = next(os.walk(IMAGE_DIR))[2]
image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))# Run detection
results = model.detect([image], verbose=1)# Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'], class_names, r['scores'])Processing 1 images image shape: (476, 640, 3) min: 0.00000 max: 255.00000 molded_images shape: (1, 1024, 1024, 3) min: -123.70000 max: 120.30000 image_metas shape: (1, 89) min: 0.00000 max: 1024.00000

Mask-RCNN还要很对应用,具体可见matterport/Mask_RCNN: Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow
本文介绍了实例分割的基本概念及其经典方法Mask R-CNN。实例分割结合了目标检测和语义分割,不仅能区分不同类别,还能识别同一类别下的不同实例。Mask R-CNN在Faster R-CNN基础上引入特征金字塔网络(FPN)和ROI对齐(ROIAlign)技术,并增加掩模预测分支,显著提升了分割精度。文章详细阐述了FPN的多尺度特征融合机制和ROIAlign避免坐标取整误差的优势,并提供了基于PyTorch的FPN实现代码。最后演示了使用预训练Mask R-CNN模型进行实例分割的完整流程,包括环境配置。









:I2C协议实现)





 微服务)

显示器位置调节)

:SPI协议测试(使用W25Q64))