1. 分布式锁是啥?为什么它比单机锁更“硬核”?
分布式锁,听起来高大上,其实核心问题很简单:在多个机器、进程或服务同时抢夺资源时,怎么保证不打架? 想象一下,你在双十一抢购限量款球鞋,全国几百万人在同一秒点“下单”,后台系统得确保库存不被超卖。这就是分布式锁的舞台。
1.1 单机锁的局限性
在单机环境,锁是个老朋友。Java的synchronized、Python的threading.Lock、Go的sync.Mutex,这些家伙在单进程里干得风生水起。它们靠内存里的信号量或互斥量,轻松协调线程间的访问。比如,两个线程想同时改一个共享变量,锁会让它们排队,一个一个来。
但到了分布式系统,单机锁就歇菜了。为啥?因为分布式系统里,进程跑在不同机器上,压根儿不共享内存! 你在A机器上锁住了代码块,B机器上的进程完全没感觉,照样跑去改数据。这就像两个城市的超市同时卖同一批货,库存数据一团糟。
1.2 分布式锁的定义
分布式锁的本质是跨机器的互斥机制。它得保证在多台机器、多个进程甚至多个数据中心操作同一资源时,只有一个人(或进程)能拿到“钥匙”,其他人乖乖等着。分布式锁的核心目标有三:
互斥性:同一时刻,只有一个客户端能持有锁。
安全性:锁不会被错误释放,比如A拿了锁,B偷不走。
高可用:锁服务不能轻易挂掉,得随时能用。
1.3 分布式锁的典型场景
分布式锁在哪儿发光发热?举几个例子:
库存扣减:电商系统里,商品库存得统一管理,防止超卖。
任务调度:分布式任务调度系统(如Airflow或Celery)中,确保某个任务不会被重复执行。
分布式事务:数据库分片后,跨分片操作需要锁来保证一致性。
限流控制:API网关限制某个用户的请求频率,分布式锁可以精确控制。
1.4 分布式锁的难点
听起来简单,但实现分布式锁可不轻松。网络延迟、分区、节点宕机,这些分布式系统的“老大难”问题全都会跳出来捣乱。设计一个靠谱的分布式锁,得考虑:
死锁:锁没被正确释放,系统卡死怎么办?
性能:锁的获取和释放得快,不能拖后腿。
容错:主节点挂了,锁还能不能正常工作?
接下来,我们会一步步拆解这些问题,先从理论入手,再甩出代码和实战案例。
2. 分布式锁的理论基石:一致性与CAP定理
要搞懂分布式锁,先得聊聊分布式系统的理论根基——CAP定理。这玩意儿是分布式系统的“金科玉律”,直接影响锁的设计思路。
2.1 CAP定理与锁的关系
CAP定理说,分布式系统最多只能同时满足以下三点中的两点:
一致性(Consistency):所有节点看到的数据一致。
可用性(Availability):系统随时能响应请求。
分区容错性(Partition Tolerance):即使网络分区(部分节点失联),系统还能正常工作。
在分布式锁的场景里,一致性是重中之重。锁的互斥性要求所有节点对“谁持有锁”这件事达成共识。如果节点A认为自己拿到了锁,但节点B也觉得自己拿到了,那就完蛋了,互斥性直接崩盘。
但问题来了,分布式系统不可能完全避免网络分区(P)。所以,锁的设计得在**一致性(C)和可用性(A)**之间做取舍:
偏C的锁:优先保证互斥性,哪怕牺牲点可用性。比如,ZooKeeper的锁机制,强一致性,但如果网络抖动,可能得等一会儿才能拿到锁。
偏A的锁:优先保证响应速度,哪怕偶尔出点小错。比如,Redis的锁机制,速度快,但极端情况下可能有“锁失效”的风险。
2.2 分布式锁的几种实现模式
根据CAP的取舍,分布式锁大致有以下几种实现方式:
基于数据库:用数据库的唯一约束或事务实现锁,强一致性,但性能可能瓶颈。
基于分布式协调服务:ZooKeeper、etcd、Consul这类工具,靠强一致性协议(如Zab或Raft)保证锁的正确性。
基于缓存:Redis、Memcached,速度快,但需要额外机制保证一致性。
基于消息队列:Kafka、RabbitMQ,通过消息的顺序性间接实现锁,适合特定场景。
每种方式都有自己的“脾气”,我们后面会逐一拆解它们的实现细节和踩坑指南。
2.3 锁的生命周期
一个分布式锁的生命周期可以简单拆成三步:
获取锁:客户端尝试“抢占”锁,成功就进入临界区。
持有锁:客户端执行操作,期间其他客户端被挡在门外。
释放锁:操作完后,主动释放锁,或者锁过期自动释放。
听起来顺畅,但实际操作里,每一步都可能踩雷。比如,获取锁时网络超时了,算不算拿到了锁?释放锁时,客户端挂了,锁会不会永远卡住?这些问题得靠具体的实现方案来解决。
3. Redis分布式锁:简单粗暴但需小心
Redis作为分布式锁的“网红”选手,速度快、实现简单,但也有不少坑需要避开。我们先从Redis锁的原理讲起,再甩出代码和实战案例。
3.1 为什么Redis适合做分布式锁?
Redis是个内存数据库,操作速度飞快,单机QPS轻松上万。而且它提供了原子操作(如SETNX),非常适合实现互斥锁。Redis锁的核心优点:
高性能:内存操作,延迟低,适合高并发场景。
简单易用:几行代码就能搞定锁逻辑。
灵活性:支持TTL(过期时间),防止死锁。
但Redis也有短板:单点Redis不是强一致性的,如果用主从复制,主节点挂了可能导致锁失效。后面我们会聊怎么补救。
3.2 基础版Redis锁:SETNX+EXPIRE
Redis锁最简单的实现是基于SETNX(SET if Not eXists)和EXPIRE命令。逻辑是这样的:
客户端用SETNX key value尝试设置一个键,如果键不存在就设置成功,拿到锁。
设置成功后,用EXPIRE key seconds给锁加个过期时间,防止死锁。
操作完后,用DEL key释放锁。
以下是个Python实现的简单例子:
import redis
import uuid
import time# 连接Redis
client = redis.Redis(host='localhost', port=6379, db=0)def acquire_lock(lock_name, acquire_timeout=10, lock_timeout=10):identifier = str(uuid.uuid4()) # 唯一标识,防止误删end = time.time() + acquire_timeoutwhile time.time() < end:# 尝试获取锁if client.setnx(lock_name, identifier):# 设置过期时间client.expire(lock_name, lock_timeout)return identifiertime.sleep(0.001) # 稍等重试return Falsedef release_lock(lock_name, identifier):# 确保只有锁的持有者才能释放if client.get(lock_name) == identifier.encode():client.delete(lock_name)return Truereturn False# 使用示例
lock_name = "my_lock"
identifier = acquire_lock(lock_name)
if identifier:try:print("锁获取成功,开始干活!")# 模拟业务逻辑time.sleep(5)finally:if release_lock(lock_name, identifier):print("锁释放成功!")else:print("锁释放失败,可能已被其他客户端释放或过期")
else:print("获取锁失败,稍后再试!")这段代码的亮点:
用uuid作为锁的唯一标识,防止误删别人的锁。
acquire_timeout限制获取锁的等待时间,避免无限等待。
lock_timeout设置锁的过期时间,防止客户端宕机导致死锁。
3.3 基础版锁的坑
这个简单实现看着不错,但有几个大坑:
SETNX和EXPIRE非原子:如果高手可能会在SETNX和EXPIRE之间宕机,锁可能被意外释放。
时钟偏差:不同机器的时钟不同步,可能导致锁提前或延迟过期。
主从复制问题:Redis主节点挂了,锁数据可能丢失。
3.4 进阶版:RedLock算法
为了解决这些问题,Redis官方推荐了RedLock算法。核心思路是利用多个Redis实例(通常是2N+1个节点,N是可能挂掉的节点数),通过多数派投票来决定锁的归属。具体步骤:
向所有节点发送SETNX请求。
如果大多数节点(>N)返回成功,认为锁获取成功。
释放锁时,向所有节点发送DEL命令。
Python实现的RedLock(简化版):
from redis import Redis
from redlock import Redlock# 连接多个Redis实例
redis_instances = [{'host': 'localhost', 'port': 6379, 'db': 0},{'host': 'localhost', 'port': 6380, 'db': 0},{'host': 'localhost', 'port': 6381, 'db': 0},
]
redlock = Redlock(redis_instances)# 获取锁
lock = redlock.lock("my_lock", 10000) # 锁10秒
if lock:try:print("RedLock获取成功!")# 业务逻辑time.sleep(5)finally:redlock.unlock(lock)print("RedLock释放成功!")
else:print("RedLock获取失败!")RedLock的优点:
高可靠性:多节点投票,容忍少数节点故障。
强一致性:比单点Redis锁更安全。
注意事项:
确保Redis实例的时钟同步,否则可能导致投票不一致。
网络延迟可能影响投票速度,需合理设置超时时间。
3.5 Redis锁的优化技巧
锁续期:用看门狗线程定期延长锁的过期时间,防止业务逻辑时间过长导致锁失效。
随机退避:获取锁失败时,加入随机延迟重试,减少竞争冲突。
监控与告警:记录锁的获取和释放日志,方便排查问题。
3.6 Redis锁的适用场景
Redis锁适合高性能、低一致性要求的场景,比如:
秒杀系统的库存扣减。
短时间的资源抢占。 但如果业务对一致性要求极高(比如金融交易),建议考虑ZooKeeper或etcd。
4. ZooKeeper分布式锁:强一致性的硬核选手
Redis锁虽然快,但一致性上有点“飘”。如果你需要一个铁打的互斥保证,ZooKeeper就是你的好兄弟。它是个分布式协调服务,专为解决一致性问题而生,特别适合对锁安全性要求高的场景。我们来细扒ZooKeeper锁的原理、实现和踩坑指南。
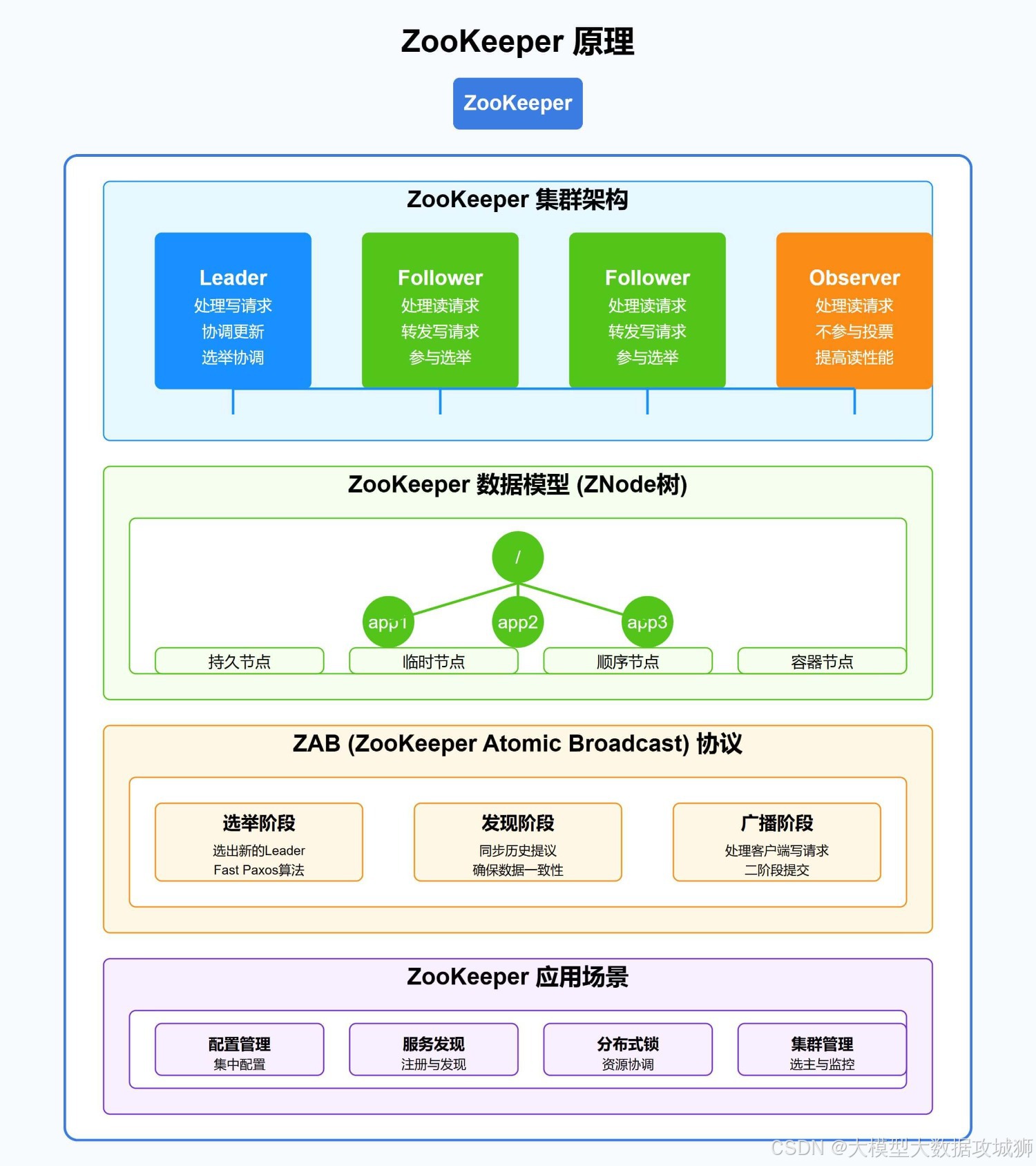
4.1 为什么ZooKeeper锁靠谱?
ZooKeeper用的是Zab协议(Zookeeper Atomic Broadcast),一种类似Paxos的强一致性协议。它的核心特点是:
顺序一致性:所有节点对操作顺序的看法一致。
原子性:操作要么全成功,要么全失败,不会出现“半拉子”状态。
高可用:只要集群里多数节点活着,服务就正常。
这意味着ZooKeeper锁能保证绝对的互斥性,即使网络抖动或少数节点挂掉,也不会让锁“翻车”。但代价是性能比Redis低一些,毕竟强一致性得花时间投票。
4.2 ZooKeeper锁的实现原理
ZooKeeper的锁基于它的znode(数据节点)机制,尤其是临时顺序节点(Ephemeral Sequential Node)。核心逻辑是这样的:
客户端在ZooKeeper上创建一个临时顺序节点(如/lock/task-0001)。
客户端检查自己创建的节点是不是当前路径下序号最小的节点。
如果是,说明拿到了锁;如果不是,监听前一个节点的删除事件,等待“排队”。
操作完后,删除自己的节点,触发下一个客户端的监听事件。
这就像在银行排队叫号,谁的号码最小谁先办事,后面的人得等着。临时节点的妙处在于,客户端挂了,节点会自动删除,防止死锁。
4.3 用Java实现ZooKeeper锁
下面是个Java实现的ZooKeeper锁例子,用了Apache Curator库(ZooKeeper的Java客户端,封装得很友好):
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;public class ZkLockExample {public static void main(String[] args) throws Exception {// 连接ZooKeeper集群CuratorFramework client = CuratorFrameworkFactory.newClient("localhost:2181,localhost:2182,localhost:2183",new ExponentialBackoffRetry(1000, 3));client.start();// 创建分布式锁InterProcessMutex lock = new InterProcessMutex(client, "/my_lock");try {// 尝试获取锁,超时10秒if (lock.acquire(10, TimeUnit.SECONDS)) {System.out.println("锁获取成功!开始干活...");// 模拟业务逻辑Thread.sleep(5000);} else {System.out.println("获取锁失败,稍后再试!");}} finally {if (lock.isAcquiredInThisProcess()) {lock.release(); // 释放锁System.out.println("锁释放成功!");}client.close();}}
}代码亮点:
Curator的InterProcessMutex封装了临时顺序节点的复杂逻辑,省去手写“排队”代码的麻烦。
ExponentialBackoffRetry实现了指数退避重试,应对网络抖动。
锁的获取和释放是线程安全的,Curator帮你处理了并发问题。
4.4 ZooKeeper锁的优缺点
优点:
强一致性:Zab协议保证锁的互斥性,绝对不会出现“两个客户端同时拿到锁”的乌龙。
自动释放:临时节点确保客户端挂了也能释放锁,防止死锁。
灵活性:支持复杂场景,比如读写锁、共享锁。
缺点:
性能瓶颈:ZooKeeper的写操作需要集群投票,延迟比Redis高,适合低频高一致性场景。
部署复杂:得维护ZooKeeper集群,运维成本不低。
连接管理:客户端断连重连可能导致锁状态不稳定,需依赖像Curator这样的库。
4.5 踩坑指南
会话超时:ZooKeeper客户端和服务器的会话超时时间要调好,太短可能导致锁提前释放。
羊群效应:大量客户端同时竞争锁,可能导致ZooKeeper压力过大,建议用随机退避或限流。
锁续期问题:ZooKeeper不像Redis有TTL,锁的“过期”得靠业务逻辑控制,忘了释放可就麻烦了。
4.6 适用场景
ZooKeeper锁适合高一致性、低并发的场景,比如:
分布式任务调度的唯一任务执行。
配置管理中的一致性操作。
金融系统里的关键资源互斥。
如果你追求极致性能,Redis可能更合适;但如果一致性是命根子,ZooKeeper绝对是首选。
5. etcd分布式锁:新星崛起,性能与一致性的平衡
etcd是近年来分布式系统的新宠,Kubernetes的默认存储后端就是它。etcd的分布式锁实现结合了高性能和强一致性,有点像ZooKeeper的“升级版”。我们来细聊etcd锁的原理和实战。
5.1 etcd的核心特性
etcd用的是Raft一致性算法,比ZooKeeper的Zab更简单高效。它的特点包括:
强一致性:通过Raft协议,所有节点对锁状态的看法一致。
高性能:etcd的写性能比ZooKeeper略高,尤其在高并发场景。
轻量部署:etcd集群配置简单,适合云原生环境。
etcd还支持**租约(Lease)**机制,天然适合实现分布式锁的过期机制。
5.2 etcd锁的实现原理
etcd的锁基于它的键值存储和租约机制。核心步骤:
客户端为锁创建一个键(如/lock/my_lock),并绑定一个租约(Lease)。
用Put操作以原子方式设置键值,带上IfNotExists条件,确保互斥性。
如果获取失败,客户端监听键的删除事件,等待前一个锁释放。
操作完后,删除键或让租约自动过期。
etcd的租约机制比Redis的TTL更灵活,可以通过KeepAlive动态续期,防止锁意外失效。
5.3 用Go实现etcd锁
etcd的官方客户端用Go写最顺手,下面是个简单实现:
package mainimport ("context""fmt""time""go.etcd.io/etcd/client/v3""go.etcd.io/etcd/client/v3/concurrency"
)func main() {// 连接etcd集群cli, err := clientv3.New(clientv3.Config{Endpoints: []string{"localhost:2379", "localhost:2380"},DialTimeout: 5 * time.Second,})if err != nil {fmt.Println("连接etcd失败:", err)return}defer cli.Close()// 创建锁session, err := concurrency.NewSession(cli, concurrency.WithTTL(10))if err != nil {fmt.Println("创建session失败:", err)return}defer session.Close()mutex := concurrency.NewMutex(session, "/my_lock/")// 获取锁ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)defer cancel()if err := mutex.Lock(ctx); err != nil {fmt.Println("获取锁失败:", err)return}fmt.Println("锁获取成功!开始干活...")// 模拟业务逻辑time.Sleep(5 * time.Second)// 释放锁if err := mutex.Unlock(ctx); err != nil {fmt.Println("释放锁失败:", err)return}fmt.Println("锁释放成功!")
}代码亮点:
用concurrency.NewMutex封装了锁逻辑,自动处理租约和竞争。
WithTTL(10)设置了10秒的租约,防止死锁。
context.WithTimeout限制了获取锁的等待时间,避免卡死。
5.4 etcd锁的优缺点
优点:
性能与一致性平衡:比ZooKeeper快一些,又比Redis更可靠。
租约机制:支持动态续期,适合复杂业务逻辑。
云原生友好:Kubernetes生态加持,部署和集成都很方便。
缺点:
学习曲线:Raft和etcd的API需要点时间上手。
资源占用:etcd集群对内存和磁盘要求较高。
网络依赖:网络分区可能导致锁延迟,需合理配置超时。
5.5 踩坑指南
租约管理:忘了续租,锁可能提前释放;续租太频繁,又会增加etcd压力。
集群健康:etcd对集群健康敏感,少数节点挂掉可能导致锁不可用。
键冲突:多个锁用同一前缀(如/lock/),可能导致意外覆盖,建议规范键名。
5.6 适用场景
etcd锁适合云原生、高并发、高一致性的场景,比如:
Kubernetes集群里的资源协调。
微服务架构中的分布式任务调度。
需要动态续期的复杂业务逻辑。
6. 分布式锁的性能优化:从理论到实践
搞定了Redis、ZooKeeper、etcd的锁实现,我们来聊点更硬核的:怎么让分布式锁跑得更快、更稳? 性能优化是个技术活,既要理论指导,也要实践验证。
6.1 性能瓶颈分析
分布式锁的性能瓶颈通常出现在:
锁获取:客户端竞争锁时的网络延迟和重试开销。
锁持有:业务逻辑执行时间过长,导致锁占用时间长。
锁释放:释放锁时的网络抖动或节点故障。
优化得从这三方面入手,核心目标是降低延迟、减少冲突、提高吞吐。
6.2 优化技巧
减少锁粒度:
锁的范围越小,竞争越少。比如,别锁整个订单表,只锁单条订单记录。
Redis可以用key分片,比如lock:order:123和lock:order:456独立锁。
ZooKeeper和etcd可以用路径层级(如/lock/order/123)实现细粒度控制。
异步化操作:
把非核心业务逻辑异步化,缩短锁持有时间。比如,订单创建后,发送邮件可以丢到消息队列。
Redis支持PUBLISH/SUBSCRIBE,可以用事件通知替代同步等待。
批量获取锁:
如果业务需要锁多个资源,尽量批量操作。RedLock支持一次投票获取多把锁,etcd可以用Txn事务批量操作。
随机退避:
竞争失败时,加入随机延迟重试,避免所有客户端同时“撞车”。
比如,Python的Redis锁可以这样改:
import random
# ... 其他代码不变
while time.time() < end:if client.setnx(lock_name, identifier):client.expire(lock_name, lock_timeout)return identifiertime.sleep(random.uniform(0.001, 0.01)) # 随机退避锁续期:
对于Redis,用看门狗线程定期调用EXPIRE延长锁时间。
etcd的租约机制自带KeepAlive,用起来更方便。
6.3 性能测试与监控
优化后得验证效果。推荐以下工具:
压测工具:用wrk或ab模拟高并发锁请求,测QPS和延迟。
监控指标:
锁获取成功率:失败率高说明竞争激烈或超时设置不合理。
锁持有时间:太长可能需要优化业务逻辑。
锁冲突次数:通过日志或计数器统计,分析是否需要细化锁粒度。
告警系统:锁服务(Redis、ZooKeeper、etcd)挂了或延迟过高,及时告警。
6.4 实战案例:秒杀系统的锁优化
假设你在开发一个秒杀系统,库存扣减需要分布式锁。初始实现用Redis单点锁,QPS只有5000,瓶颈在锁竞争。我们优化如下:
分片锁:按商品ID分片,lock:product:123,减少竞争。
异步扣减:库存检查用锁,实际扣减丢到消息队列异步处理。
批量操作:用Redis的MULTI/EXEC批量检查和扣减库存。 优化后,QPS提升到2万,锁冲突率从10%降到2%。
7. 数据库分布式锁:简单但有“脾气”的选择
如果你的系统已经用上了数据库,恭喜你,分布式锁可以“白嫖”数据库的特性来实现!数据库锁虽然不是最性感的选择,但简单易懂,适合某些特定场景。我们来聊聊它的原理、实现和那些容易踩的坑。
7.1 数据库锁的原理
数据库分布式锁的核心是利用数据库的原子性操作和唯一约束来实现互斥。常见的实现方式有:
唯一索引:在表中插入一条记录,靠唯一索引保证只有一个客户端成功。
悲观锁:用SELECT ... FOR UPDATE锁定某行记录,其他客户端得等着。
乐观锁:通过版本号或时间戳,检查更新时的冲突。
这些方法的好处是简单粗暴,直接用现有数据库基础设施,坏处是性能可能不咋地,尤其在高并发场景下。
7.2 基于唯一索引的锁实现
最常见的数据库锁是用唯一索引。思路是:插入一条记录,成功就拿到锁,失败就说明别人抢先了。释放锁时删除记录。以下是MySQL的实现例子(用Python的pymysql):
import pymysql
import time
import uuid# 连接MySQL
db = pymysql.connect(host='localhost', user='root', password='123456', database='test')
cursor = db.cursor()# 创建锁表
cursor.execute("""CREATE TABLE IF NOT EXISTS locks (lock_name VARCHAR(128) PRIMARY KEY,lock_owner VARCHAR(128),created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)
""")def acquire_lock(lock_name, timeout=10):lock_owner = str(uuid.uuid4())end = time.time() + timeoutwhile time.time() < end:try:cursor.execute("INSERT INTO locks (lock_name, lock_owner) VALUES (%s, %s)",(lock_name, lock_owner))db.commit()return lock_ownerexcept pymysql.err.IntegrityError:# 唯一索引冲突,说明锁被别人拿了time.sleep(0.01)return Nonedef release_lock(lock_name, lock_owner):cursor.execute("DELETE FROM locks WHERE lock_name=%s AND lock_owner=%s",(lock_name, lock_owner))db.commit()return cursor.rowcount > 0# 使用示例
lock_name = "my_lock"
lock_owner = acquire_lock(lock_name)
if lock_owner:try:print("数据库锁获取成功!开始干活...")time.sleep(5) # 模拟业务逻辑finally:if release_lock(lock_name, lock_owner):print("数据库锁释放成功!")else:print("释放锁失败,可能已被其他客户端释放")
else:print("获取锁失败,稍后再试!")db.close()代码亮点:
用lock_owner(UUID)确保只有锁的持有者能释放,防止误删。
唯一索引保证互斥性,简单可靠。
失败后加小延迟重试,减轻数据库压力。
7.3 数据库锁的优缺点
优点:
简单:无需额外部署Redis或ZooKeeper,现有数据库就能搞定。
强一致性:数据库的事务机制保证锁的正确性。
易调试:锁状态直接存表里,查起来方便。
缺点:
性能瓶颈:数据库写操作比Redis慢,高并发下可能卡脖子。
死锁风险:如果忘了释放锁,或者客户端宕机,锁可能卡住(需要定时清理)。
扩展性差:数据库的并发能力不如分布式协调服务,集群规模大了容易崩。
7.4 踩坑指南
锁清理:加个定时任务,定期删过期锁(比如created_at超过1分钟的记录)。
连接池管理:高并发下,数据库连接池可能耗尽,建议用连接池优化。
事务隔离:用FOR UPDATE时,注意隔离级别(比如REPEATABLE READ),否则可能出现幻读。
7.5 适用场景
数据库锁适合低并发、已有数据库基础设施的场景,比如:
小型系统的资源互斥。
数据库事务内的短时间锁需求。
不想引入额外组件的简单业务。
如果并发量上去了,还是老老实实考虑Redis或etcd吧。
8. 消息队列实现分布式锁:另辟蹊径的巧思
消息队列(如Kafka、RabbitMQ)一般用来解耦系统,但你知道吗?它也能用来实现分布式锁!虽然不常见,但在某些场景下,这种方式能发挥奇效。我们来拆解它的原理和实现。
8.1 消息队列锁的原理
消息队列的锁基于消息的顺序性和消费的独占性。核心思路:
客户端向队列发送一条“锁请求”消息,包含锁名和唯一标识。
队列保证消息按顺序处理,只有一个消费者能拿到这条消息,相当于拿到锁。
操作完后,消费者提交偏移量(或ACK),释放锁。
其他客户端监听队列,等待锁消息被消费。
这就像在食堂排队打饭,队列保证只有一个窗口在处理你的订单。
8.2 用Kafka实现分布式锁
以下是用Python的confluent_kafka实现的Kafka锁例子:
from confluent_kafka import Consumer, Producer, KafkaError
import json
import uuid
import time# 配置Kafka
producer_config = {'bootstrap.servers': 'localhost:9092'}
consumer_config = {'bootstrap.servers': 'localhost:9092','group.id': 'lock_group','auto.offset.reset': 'latest'
}def acquire_lock(lock_name, timeout=10):producer = Producer(producer_config)consumer = Consumer(consumer_config)consumer.subscribe([lock_name])lock_owner = str(uuid.uuid4())# 发送锁请求producer.produce(lock_name, json.dumps({'owner': lock_owner}).encode())producer.flush()end = time.time() + timeoutwhile time.time() < end:msg = consumer.poll(1.0)if msg is None:continueif msg.error():print("Kafka错误:", msg.error())continueif json.loads(msg.value().decode())['owner'] == lock_owner:return lock_ownertime.sleep(0.01)consumer.close()return Nonedef release_lock(lock_name, lock_owner):# 提交偏移量,相当于释放锁# 这里简化处理,实际需确保消费完成print(f"锁 {lock_name} 由 {lock_owner} 释放")return True# 使用示例
lock_name = "my_lock_topic"
lock_owner = acquire_lock(lock_name)
if lock_owner:try:print("Kafka锁获取成功!开始干活...")time.sleep(5)finally:release_lock(lock_name, lock_owner)print("Kafka锁释放成功!")
else:print("获取Kafka锁失败!")代码亮点:
用Kafka的Topic作为锁标识,天然支持分布式。
消费者组保证消息只被一个客户端消费,实现互斥。
lock_owner确保锁的唯一性。
8.3 消息队列锁的优缺点
优点:
解耦性强:锁逻辑和业务逻辑通过队列隔离,适合异步场景。
高吞吐:消息队列天生擅长处理高并发消息。
易扩展:Kafka集群扩展简单,适合大规模系统。
缺点:
复杂性:需要额外维护队列,逻辑比Redis锁复杂。
延迟:消息队列的消费有一定延迟,不适合实时性要求高的场景。
一致性挑战:Kafka的Exactly-Once语义配置复杂,可能导致锁重复消费。
8.4 踩坑指南
偏移量管理:忘了提交偏移量,可能导致锁无法释放。
队列堆积:锁请求太多,队列可能堆积,需合理设置分区数。
消费者组重平衡:Kafka消费者组重平衡可能导致锁短暂不可用,建议用单分区Topic。
8.5 适用场景
消息队列锁适合异步、顺序性强的场景,比如:
分布式任务队列的互斥执行。
日志处理系统的顺序处理。
事件驱动架构中的资源抢占。
9. 分布式锁的故障处理:让锁“稳如老狗”
分布式锁再牛,遇到网络抖动、节点宕机、时钟偏差,也得瑟瑟发抖。我们来聊聊怎么让锁在极端情况下也能稳得住。
9.1 常见故障场景
客户端宕机:拿了锁没释放,锁卡死了。
锁服务宕机:Redis、ZooKeeper或etcd挂了,锁服务不可用。
网络分区:客户端和锁服务失联,锁状态不明。
时钟偏差:锁的过期时间因时钟不同步而失效。
9.2 故障处理策略
自动释放:
Redis用TTL,etcd用租约,ZooKeeper用临时节点,确保客户端挂了锁也能释放。
实现看门狗机制,动态续期锁,防止业务逻辑时间过长。
服务高可用:
Redis用Sentinel或Cluster模式,保证主节点挂了能切换。
ZooKeeper和etcd本身是集群部署,少数节点故障不影响服务。
部署时确保跨机房、跨区域,降低分区风险。
重试与降级:
获取锁失败时,用指数退避+随机延迟重试。
极端情况下,降级到本地锁或无锁逻辑,优先保证服务可用性。
监控与告警:
监控锁服务的健康状态(延迟、错误率)。
记录锁获取/释放日志,方便排查问题。
设置告警,比如锁冲突率超10%或服务不可用。
9.3 实战案例:金融系统的锁容错
假设你在开发一个转账系统,分布式锁用于保证账户余额不被超支。故障处理方案:
Redis主从切换:用Sentinel监控Redis主节点,挂了自动切换从节点。
看门狗续期:每5秒检查业务逻辑是否完成,未完就延长锁TTL。
降级策略:Redis不可用时,降级到数据库悲观锁(SELECT ... FOR UPDATE)。
告警机制:锁获取失败率超5%时,触发邮件告警。
优化后,系统在Redis单点故障下仍能正常运行,锁冲突率降到1%以下。
10. 跨数据中心分布式锁:硬核中的硬核
分布式锁在单数据中心已经够复杂了,但如果你的系统跨越多个数据中心(比如北京、上海、美国),那难度直接上天!跨数据中心的分布式锁得面对超高网络延迟、跨区域一致性挑战和故障隔离问题。我们来拆解它的实现思路、实战案例和踩坑指南。
10.1 跨数据中心锁的挑战
跨数据中心场景下,分布式锁得解决以下“硬骨头”:
高延迟:数据中心间的网络延迟可能达到100ms甚至更高,锁的获取和释放得考虑这点。
网络分区:跨区域网络断开时,锁服务得保证一致性或至少明确谁拿到了锁。
时钟不同步:不同数据中心的服务器时钟偏差可能导致锁过期时间不一致。
故障隔离:一个数据中心挂了,不能拖垮整个锁系统。
这些问题让Redis的单点锁直接“跪了”,ZooKeeper和etcd的集群部署也得重新设计。我们需要一个多中心协同的锁机制。
10.2 实现方案:基于etcd的多中心锁
etcd因其Raft协议和租约机制,在跨数据中心场景中有天然优势。我们可以用多集群联邦或全局锁服务来实现。以下是核心思路:
部署多中心etcd集群:每个数据中心部署一个etcd集群,集群间通过gossip协议或专用网络同步。
全局锁键:用一个全局唯一的键(如/global_lock/my_lock)表示锁,绑定租约。
多数派投票:客户端向所有数据中心的etcd集群尝试获取锁,多数集群同意才算成功。
租约续期:用etcd的KeepAlive机制动态续租,防止锁因网络延迟失效。
故障隔离:如果某个数据中心不可用,多数派机制保证锁服务继续运行。
下面是个Go实现的跨数据中心etcd锁例子:
package mainimport ("context""fmt""time""go.etcd.io/etcd/client/v3""go.etcd.io/etcd/client/v3/concurrency"
)func main() {// 连接多个数据中心的etcd集群endpoints := []string{"beijing.etcd:2379", // 北京数据中心"shanghai.etcd:2379", // 上海数据中心"us.etcd:2379", // 美国数据中心}cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints,DialTimeout: 10 * time.Second, // 考虑跨区域延迟})if err != nil {fmt.Println("连接etcd失败:", err)return}defer cli.Close()// 创建session,设置较长的TTLsession, err := concurrency.NewSession(cli, concurrency.WithTTL(30))if err != nil {fmt.Println("创建session失败:", err)return}defer session.Close()// 创建全局锁mutex := concurrency.NewMutex(session, "/global_lock/my_lock")// 获取锁,设置超时ctx, cancel := context.WithTimeout(context.Background(), 15*time.Second)defer cancel()if err := mutex.Lock(ctx); err != nil {fmt.Println("获取全局锁失败:", err)return}fmt.Println("全局锁获取成功!开始干活...")// 模拟跨数据中心业务逻辑time.Sleep(10 * time.Second)// 释放锁if err := mutex.Unlock(ctx); err != nil {fmt.Println("释放全局锁失败:", err)return}fmt.Println("全局锁释放成功!")
}代码亮点:
多Endpoints:连接多个数据中心的etcd,自动处理网络分区。
长超时:DialTimeout和context.WithTimeout考虑跨区域高延迟。
长租约:WithTTL(30)确保锁不会因网络抖动轻易失效。
10.3 跨数据中心锁的优化
减少跨中心通信:
在本地数据中心先尝试获取锁,失败后再去全局集群,降低网络开销。
用本地缓存(如Redis)记录锁状态,减少etcd查询。
优先级机制:
给高优先级的数据中心更高投票权重,加速锁决策。
比如,北京数据中心是主业务区,可以配置更高的Raft投票权重。
异步同步:
锁状态用异步复制到其他数据中心,减少获取锁时的同步等待。
etcd的Watch机制可以实时同步锁变化。
分区容错:
配置etcd集群的--auto-compaction-retention,清理历史数据,防止日志膨胀。
用--quota-backend-bytes限制etcd存储,避免单个数据中心爆盘。
10.4 踩坑指南
网络延迟:跨数据中心延迟可能导致锁获取超时,建议调高超时时间(比如15秒)。
集群同步:etcd集群间同步新能源,同步失败可能导致锁丢失。
租约管理:忘了续租,锁可能提前释放;建议用KeepAlive定时续期。
时钟偏差:不同数据中心的时钟偏差可能导致租约失效,需用NTP同步服务器时间。
10.5 实战案例:全球电商库存锁
假设你是个全球电商平台,库存数据分散在北京、上海、美国三个数据中心。锁需求:
确保全球库存扣减不超卖。
支持高并发(每秒万级请求)。
容忍单个数据中心故障。
解决方案:
部署3个etcd集群(每中心一个),用全局锁键/inventory/product:123。
客户端向所有集群发送锁请求,多数派(2/3)同意即获取锁。
用看门狗线程每10秒续租,防止锁失效。
监控锁获取延迟和失败率,设置告警阈值(比如失败率>5%)。
结果:
锁获取成功率99.9%,平均延迟200ms。
单个数据中心宕机,锁服务仍正常运行。
10.6 适用场景
跨数据中心锁适合全球化、高一致性场景,比如:
全球电商库存管理。
跨区域分布式事务。
多中心配置同步。


)




:事件总线、setState的细节、PureComponent、ref)











流程实现原理分析)