文章目录
- 说明
- 一 GraphRAG查询(Query)流程
- 二 Local Search 实现原理
- 三 Global Search 实现原理
- 四 GraphRAG Python API使用
说明
- 本文学自赋范社区公开课,仅供学习和交流使用!
- 本文重在介绍GraphRAG查询流程,有关索引构建的详细内容参看GraphRAG快速入门和原理理解
一 GraphRAG查询(Query)流程
- 完成
Microsoft GraphRAG的索引构建后,Microsoft GraphRAG提供一种更为直观、易用的查询方式,只需要输入自然语言查询,即可获得结构化的查询结果。 - 索引阶段利用大语言模型结合提示工程,从非结构化文本(
.txt、.csv、Json)中提取出实体(Entities)与关系(Relationships),构建出了基础的Knowledge Graph,并且通过建立层次化的community结构,community以及community_report的丰富语义。 - 相较于传统基于
Cypher的查询方式可以提供更多灵活性的Query操作,Microsoft GraphRAG提供local和global两种查询方式,分别对应local search和global search,而后在不断的迭代更新过程中,除了优化了local search和global search的效果,还新增了DRIFT Search和Multi Index Search作为扩展优化的可选项,以进一步丰富Query操作的多样性。
| 模式 | 核心思路 | 场景举例 |
|---|---|---|
| local | 只查询与“当前节点”邻居相关的子图 | “围绕某个主题节点的局部信息” |
| global | 全局搜索,忽略当前节点,直接在所有节点里找 | “在整个图中检索最相关的节点” |
| hybrid | 先局部查询,再全局补充 | “先看局部,再回溯全局补充背景” |
| contextual | 根据当前上下文,动态选择检索区域 | “根据问题类型或语境决定局部/全局混合策略” |
- Microsoft GraphRAG
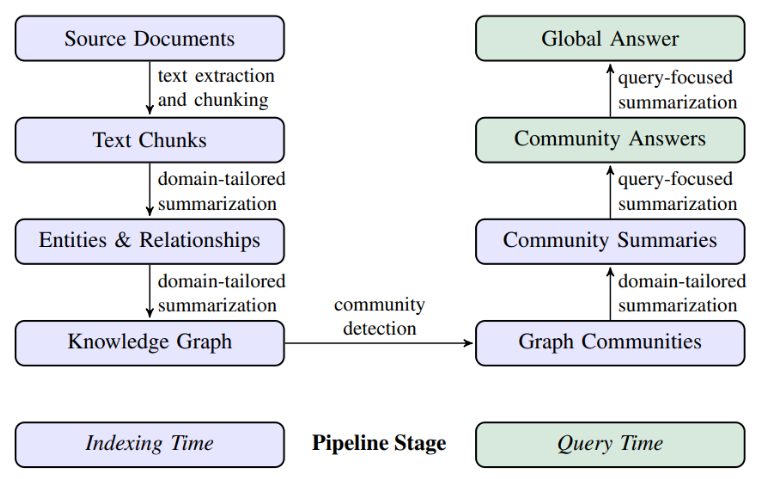
Microsoft GraphRAG在查询阶段构建的流程,相较于构建索引阶段会更为直观。核心的具体步骤包括:- 接收用户的查询请求。
- 根据查询所需的详细程度,选择合适的社区级别进行分析。
- 在选定的社区级别进行信息检索。
- 依据社区摘要生成初步的响应。
- 将多个相关社区的初步响应进行整合,形成一个全面的最终答案。
-
Indexing过程中并不是在创建完第一层社区后就停止,而是分层的。当创建第一层社区(即基础社区)后,会将这些社区视为节点,进一步构建更高层级的社区。这种方法可以实现在知识图谱中以不同的粒度级别上组织和表示数据。比如第一层社区可以包含具体的实体或数据,而更高层级的社区则可以聚合这些基础社区,形成更广泛的概览。 -
最核心的
Local Search和Global Search的实现,是源于不同的粒度级别而构建出来用于处理不同类型问题的Pipeline, 其中:Local Search是基于实体的检索。Global Search则是基于社区的检索。
二 Local Search 实现原理
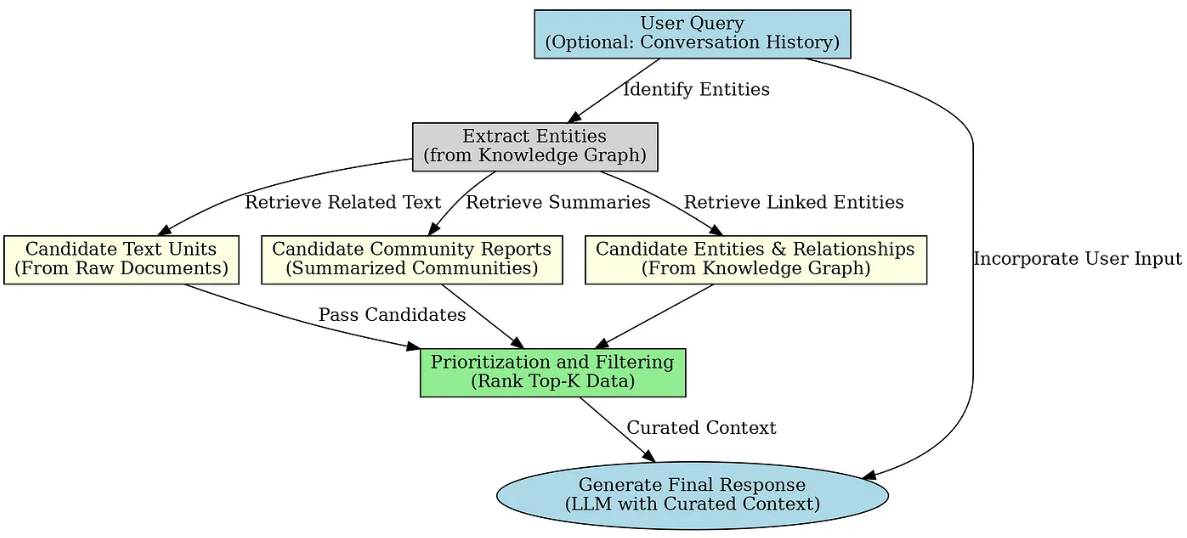
Local Search即本地检索,是基于实体的检索。本地搜索从相关实体开始,使用知识图谱来查找最相关的信息。例如,给定查询中的实体,使用的是连接节点的信息,通过辨识与查询相关的实体与关系,检索特定文本片段、摘要和关联性资料。所以Local Search本质上是基于实体的推理。特别适合回答“who”、“what”、“when” 类型的问题。Microsoft GraphRAG源码中实现的内部原理如下:
graphrag query 命令参数说明
| 参数名称 | 类型 | 描述 | 默认值 | 是否必需 |
|---|---|---|---|---|
--method | Tpye | 可以选择local、global、drift或basic算法。 | None | 是 |
--query | TEXT | 要执行的查询,即提出的问题。 | None | 是 |
--config | PATH | 要使用的配置文件路径。 | None | 否 |
--data | PATH | 索引管道输出目录(即包含 parquet 文件的目录)。 | None | 否 |
--root | PATH | 项目根目录的路径。 | . | 否 |
--community-level | INTEGER | 从中加载社区报告的 Leiden 社区层级。较高的值表示来自较小社区的报告。 | 2 | 否 |
--dynamic-community-selection | 使用动态社区选择的全局搜索。 | no-dynamic-community-selection | 否 | |
--response-type | TEXT | 描述响应类型和格式的自由文本,可以是任何内容,例如多个段落、单个段落、单句、3-7点列表、单页、多页报告。 | Multiple Paragraphs | 否 |
--streaming | 以流式方式打印响应。 | no-streaming | 否 | |
--help | 显示帮助信息并退出。 | 否 |
- 其中,在执行查询时必须指定的参数是
--method和--query,其他参数为可选参数。其中:--method参数可以选择local、global、drift或basic算法。(接下来我们会依次介绍这几种算法)--query参数是要执行的查询,即提出的问题。
- 通过命令行快速启动问答检索。
local本地搜索命令:
graphrag query --root ./ --method local --query "苹果公司都有哪些产品?"
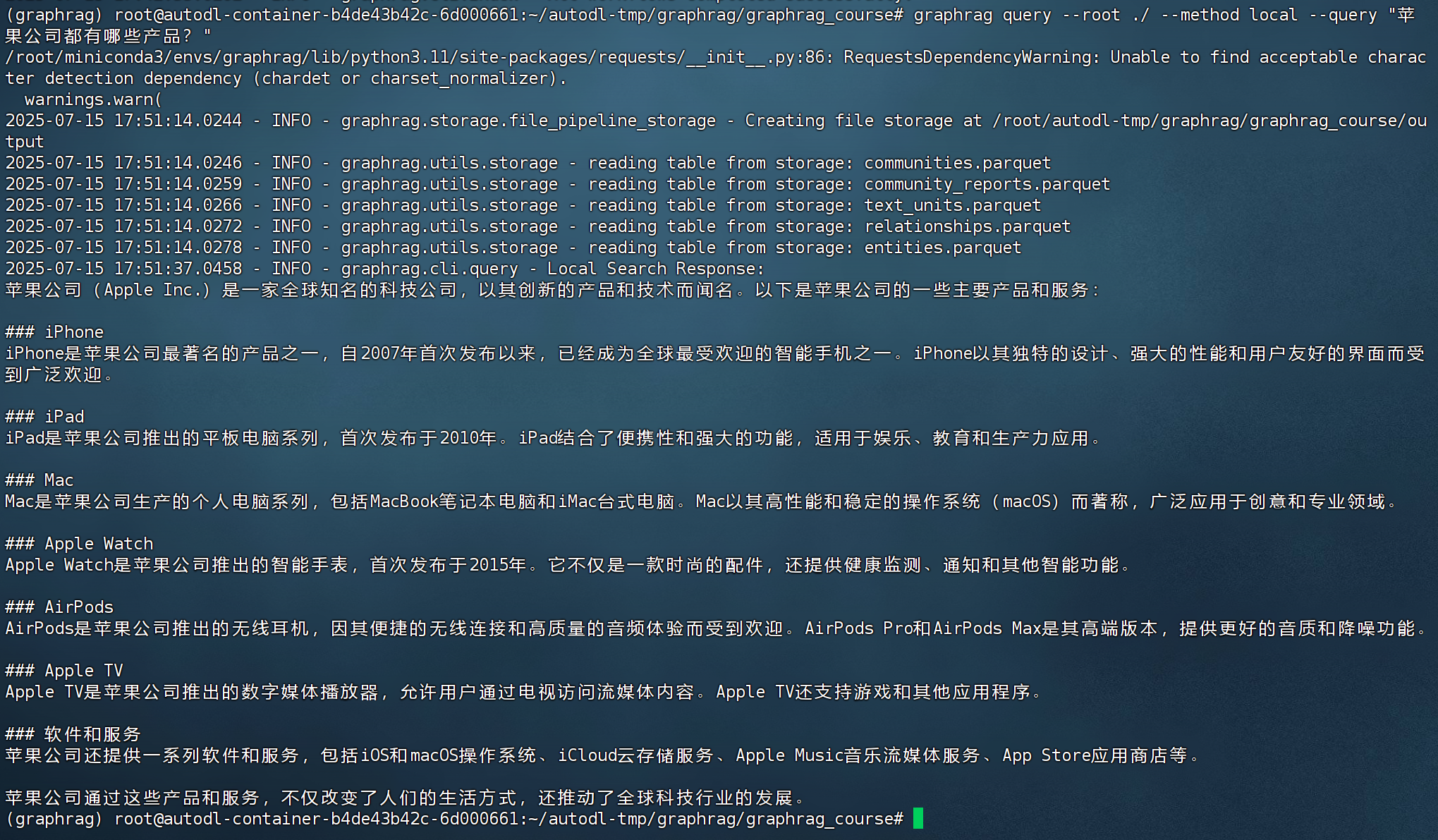
- 整个本地查询过程使用起来非常简单,但是大多数情况下基于通用流程的问答检索,并不能满足实际业务需求。比如检索的效果不准确,效率不高,检索结果不全面等,因此,需要进一步掌握
Microsoft GraphRAG的检索原理,并根据实际业务需求,进行针对性的优化和调整。
Local Search的完整实现过程:
- 依次读取
text_units.parent、entities.parent、relationships.parentcommunities.parent和community_reports.parent的索引文件,并将其加载到内存中。 - 加载
Lancedb中的词向量,准备用于后续的相似度计算。 - 根据社区的
community_level参数的值,对实体进行第一轮的过滤,过滤的规则是:如果实体的community_level小于等于community_level参数的值,则保留该实体,否则丢弃。 - 基于输入的问题,进行实体的匹配,并构建完整的上下文。
- 处理输入问题,如果存在对话历史记录,则将之前的用户问题附加到当前查询。
- 将输入的问题转化为词向量,然后和lancedb中的实体词向量进行相似度计算,得到与查询最相关的实体,这个过程中会采用两个策略:
- 过采样 (Oversampling) 策略,即最终检索的实体数量是 k * oversample_scaler。
- 如果提供了exclude_entity_names列表,则过滤掉这些实体。
- 根据匹配到的实体,读取该实体所属的社区报告,这个过程会采用的策略是:
- 统计每个社区被多少个选中实体引用(一个实体可能属于多个社区),做基于实体归属的社区投票排序
- 按匹配度和社区自身排名双重排序
- 主要排序标准:被实体引用的频次(匹配度)
- 次要排序标准:社区自身的重要性排名
- 在 2,3 的基础上,提取出文本单元、关系的附件属性
- 生成完整的数据表格
- 构建本地搜索的系统提示词,将数据表格填充到系统提示词中,引导大模型生成最终的回答。其提示词设置在
settings.yaml文件的local_search中。
- 再理解
Microsoft GraphRAG给出的Local Search原理图。
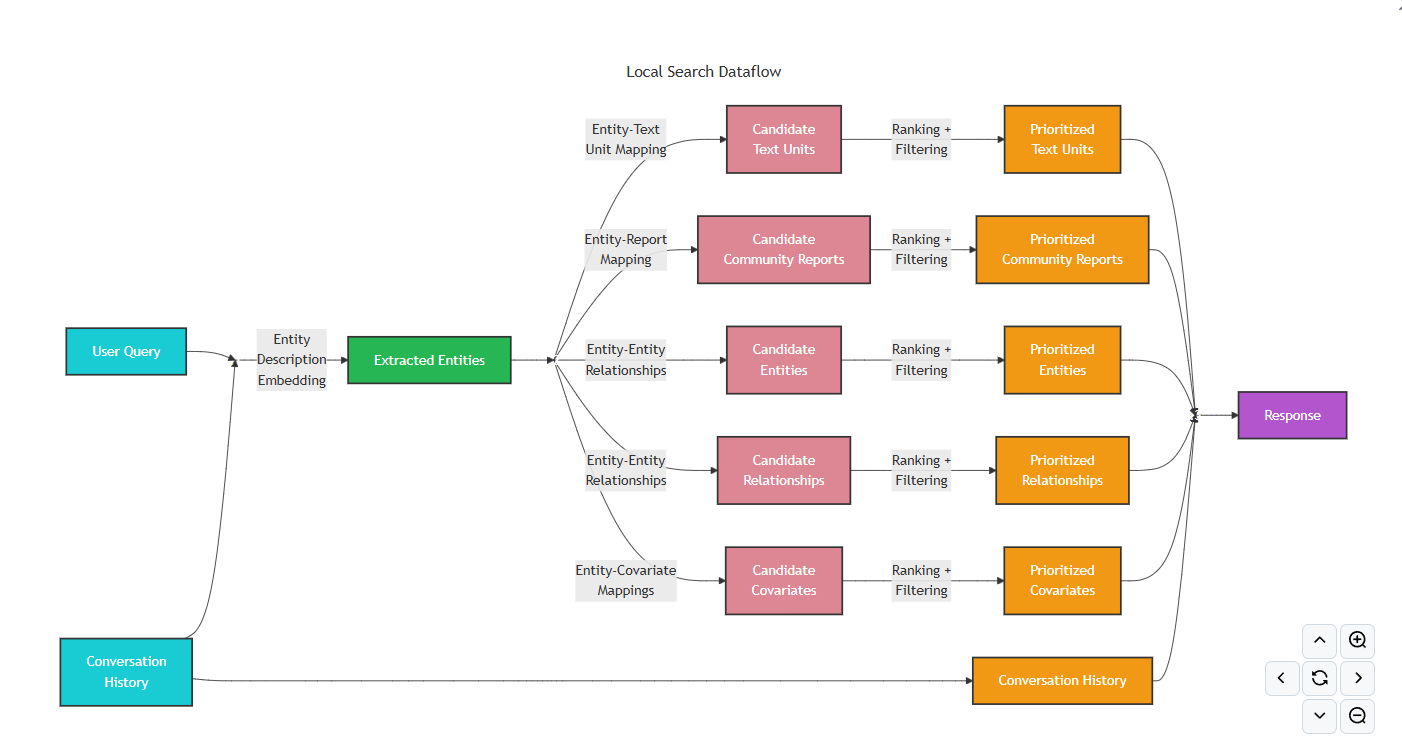
三 Global Search 实现原理
-
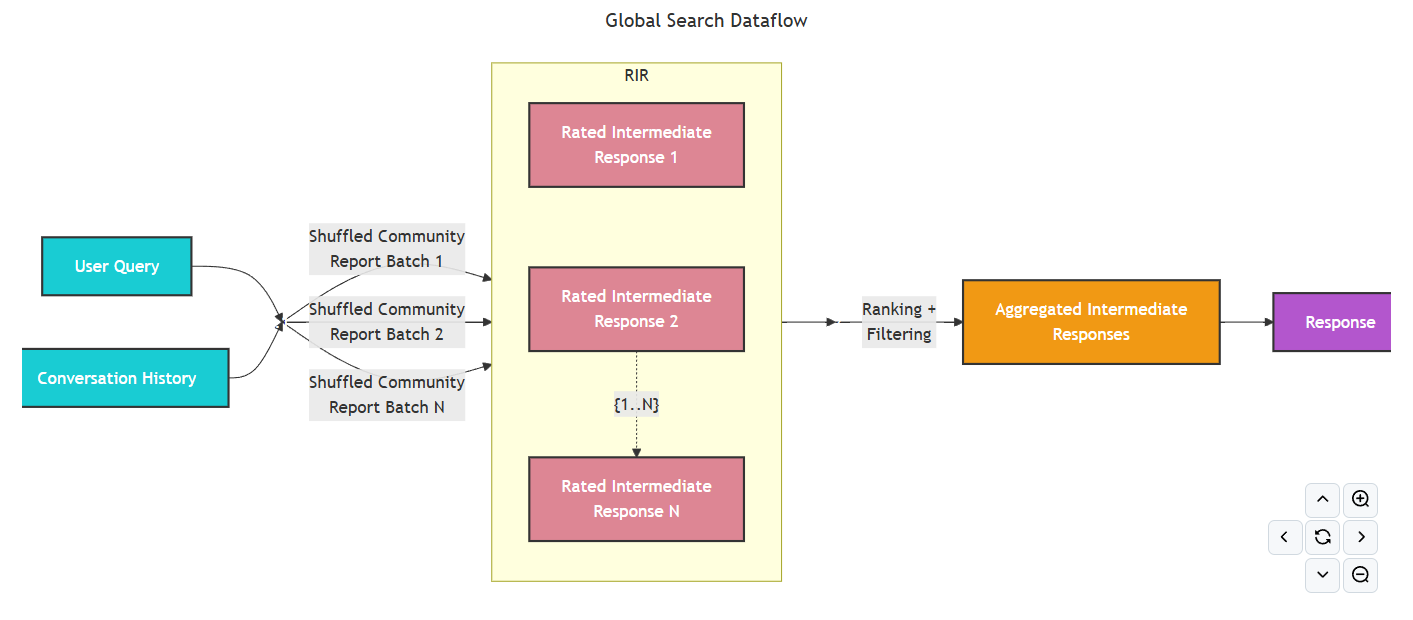
Microsoft GraphRAG中的全局搜索算法旨在回答需要了解整个数据集的抽象问题,即借助社区摘要来获取全局的答案。实现思路是通过map-reduce流程总结知识图谱中的社群摘要,汇总社区摘要中的见解,尝试生成文档中元素的概述,聚合相关资料并生成针对整体数据集的高层次回答。因此全局搜索更侧重于为需要更高层次理解的问题提供答案。比如数据中的前5个主题是什么?这类问题。 -
在
Microsoft GraphRAG中,Map阶段会使用大模型对多个文档或信息片段并行处理,从每个片段中提取相关信息,然后Reduce阶段会汇总所有映射操作的结果,生成最终输出。 -
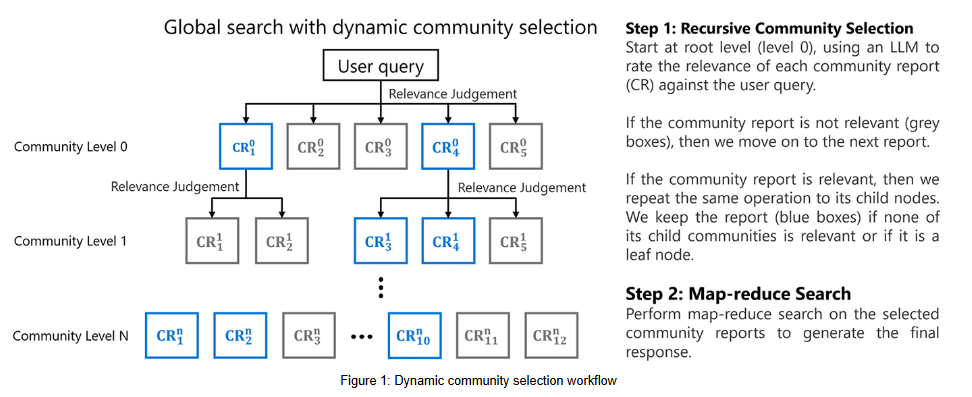
Global Search在Microsoft GraphRAG源码中的实现原理图如下:

-
当使用
Global Search时,需要指定--method global参数:graphrag query --root ./ --method global --query "文本库的内容可以分为哪几个主题?" -
Global Search的实现过程:- 依次读取
entities.parent、communities.parent和community_reports.parent的索引文件,并将其加载到内存中。 - 依次创建
entities.parent、communities.parent和community_reports.parent的实体对象,并进行格式化处理。 - 进入到构建上下文阶段。在这个阶段,最关键的一个核心概念是:静态与动态全局搜索策略的选择。
- 静态策略方法指的是知识图谱中预定级别的社区中进行搜索来生成答案。然后,大模型合并并总结此抽象级别的所有社区报告。最后,摘要用作 大模型的附加上下文,以生成对用户问题的响应。此为静态方法。它存在的问题是既昂贵又低效,因为包含许多对用户查询没有帮助的低级报告。
- 动态社区选择算法
dynamic_community_selection利用索引数据集的知识图谱结构。从知识图谱的根开始,使用提示工程 + 大模型来评估社区报告在回答用户问题方面的相关性。如果报告被视为不相关,则将其及其节点(或子社区)从搜索过程中删除。另一方面,如果报告被视为相关,将遍历其子节点并重复该操作。最后,只有相关的报告才会传递给map-reduce操作以生成对用户的响应。
- 依次读取
-
该算法类实现的核心机制并不是简单地评估所有社区,而是采用启发式遍历,具体体现在:
- 选择性探索: 并不是简单地评估所有社区,而是根据当前社区的相关性决定是否探索其子社区。只有当一个社区的评分大于或等于阈值时,才会将其子社区添加到下一轮评估中。
- 动态队列构建:
queue = communities_to_rate表明下一轮要评估的社区完全取决于当前轮次中哪些社区被认为是相关的。这不是一个固定的或预先确定的遍历顺序。 - 剪枝机制: 如果一个社区的评分低于阈值,其所有子社区都会被"剪枝",不会被进一步探索。这是启发式算法的典型特征。
- 自适应性: 算法的路径会根据不同的查询而变化,因为相关性评分依赖于具体的查询内容。
- 回退策略: 如果在当前路径上找不到相关社区,算法会尝试探索下一个层级的所有社区,这也是一种启发式决策。
-
其中,用于评估社区相关性的提示词是这样的,其对应的中文提示如下所示:
Rate_query = "“”——角色你是一个乐于助人的助手,负责决定所提供的信息是否有助于回答给定的问题,即使它只是部分相关。——目标在0到5的范围内,请对回答问题所提供的信息的相关性或帮助程度进行评分。——信息{描述}——问题{问题}——目标回复长度和格式——请以以下JSON格式回复,包含两个条目:-“原因”:评分的原因,请包括你考虑过的信息。-“评级”:相关度从0到5,其中0是最不相关的,5是最相关的。{{“理由”:str,“等级”:int。}}
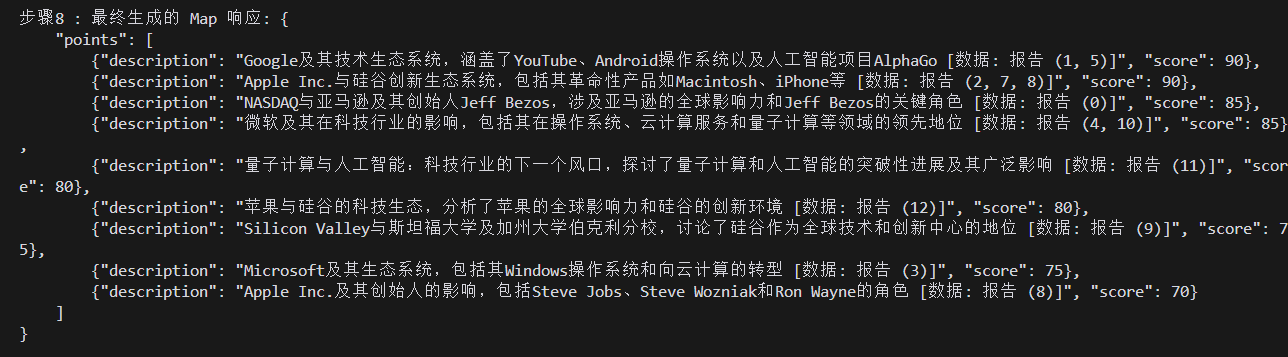
- 然后,该输出的结果会作为变量
context_data传递给global_search_reduce_system_prompt.txt中定义的提示,并调用大模型生成最终的Reduce响应,同时,Reduce响应的结果会作为变量context_text传递给global_search_knowledge_system_prompt.txt中定义的提示,引导大模型生成最终的Knowledge响应。
四 GraphRAG Python API使用
- 构建索引过程
from pathlib import Path
from pprint import pprintimport pandas as pdimport graphrag.api as api
from graphrag.config.load_config import load_config
from graphrag.index.typing.pipeline_run_result import PipelineRunResultPROJECT_DIRECTORY = "./graphrag_test"
graphrag_config = load_config(Path(PROJECT_DIRECTORY))index_result: list[PipelineRunResult] = await api.build_index(config=graphrag_config)# index_result is a list of workflows that make up the indexing pipeline that was run
for workflow_result in index_result:status = f"error\n{workflow_result.errors}" if workflow_result.errors else "success"print(f"Workflow Name: {workflow_result.workflow}\tStatus: {status}")
- Query过程
entities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/entities.parquet")
communities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/communities.parquet")
community_reports = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/community_reports.parquet"
)response, context = await api.global_search(config=graphrag_config,entities=entities,communities=communities,community_reports=community_reports,community_level=1,dynamic_community_selection=False,response_type="Multiple Paragraphs",query="请帮我介绍下亚马逊公司?",
)print(response)
- 测试结果
## 亚马逊公司简介
亚马逊(Amazon),在中文中被称为“亚马逊”,是一家全球公认的电子商务和云计算领域的领导者。公司成立于1994年,最初是一个在线书店,但随着时间的推移,亚马逊已经发展成为一个综合性的在线市场,提供广泛的产品和服务 [Data: Reports (0)]。
### 电子商务与零售
亚马逊在电子商务领域的成功不仅体现在其广泛的产品种类和全球市场覆盖,还通过战略性收购进一步巩固了其在零售行业的地位。亚马逊收购全食超市(Whole Foods)就是一个重要的战略举措。这次收购不仅扩大了亚马逊的市场影响力,还将其电子商务能力与实体零售相结合,为消费者提供无缝的购物体验 [Data: Reports (0)]。
### 云计算与技术创新
亚马逊网络服务(AWS)是其云计算平台,是公司利润的主要驱动因素,也是其商业模式的关键组成部分。AWS为全球的企业提供计算能力和存储服务,显示了亚马逊在技术领域的强大实力 [Data: Reports (0)]。
此外,亚马逊在技术创新方面的投入也体现在其智能助手Alexa的推出。Alexa不仅增强了亚马逊在技术领域的影响力,还展示了其利用人工智能改善用户体验的能力 [Data: Reports (0)]。亚马逊积极投资于人工智能,以提升用户体验,这一战略重点使其在技术创新的前沿占据一席之地 [Data: Reports (0)]。
### 领导力与企业文化
杰夫·贝索斯(Jeff Bezos),亚马逊的创始人,在将公司转变为全球电子商务巨头的过程中发挥了关键作用。他的领导和远见在亚马逊的扩张和创新中起到了重要作用,特别是在AWS的发展和全食超市的收购中 [Data: Reports (0)]。
### 竞争与合作
亚马逊与其他科技巨头如苹果和谷歌的互动,突显了科技行业内的竞争与合作动态。这些公司在多个领域展开竞争,同时也在某些项目上进行合作 [Data: Reports (0)]。综上所述,亚马逊通过其在电子商务、云计算和技术创新方面的战略举措,巩固了其在全球市场的领导地位。










![[QtADS]解析ads.pro](http://pic.xiahunao.cn/[QtADS]解析ads.pro)








)