转自 NEON优化:性能优化经验总结-CSDN博客
NEON优化:性能优化经验总结
1. 什么是 NEON
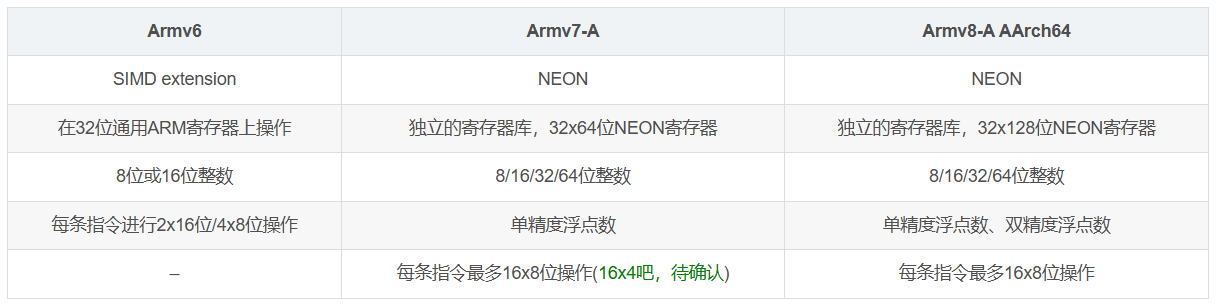
Arm Adv SIMD 历史
2. 寄存器
3. NEON 命名方式
4. 优化技巧
5. 优化 NEON 代码(Armv7-A内容,但区别不大)
5.1 优化 NEON 汇编代码
5.1.1 Cortex-A 处理器之间的 NEON 管道差异
5.1.2 内存访问优化
Reference:
- NEON优化:性能优化经验总结
- NEON官方内联函数
- Arm NEON programming quick reference
- Learn the architecture - Neon programmers’ guide
如果觉得直接在 NEON 上编译不太方便,可在SSE上编译后转NEON,可参考:https://github.com/DLTcollab/sse2neon
1. 什么是 NEON
NEON 技术是用于 Arm Cortex-A 系列处理器的先进 SIMD(单指令多数据)架构。它可以加速多媒体和信号处理算法,如视频编码器/解码器、2D/3D图形、游戏、音频和语音处理、图像处理、电话和声音。
NEON 指令执行“打包 SIMD”处理:
- 寄存器被认为是相同数据类型元素的向量
- 数据类型支持:带符号/无符号 8 88 位,16 1616 位,32 3232 位,64 6464 位,ARM 32 3232位平台上的单精度浮点数,ARM 64 6464位平台上的单精度浮点数和双精度浮点数。
- 指令在所有通道中执行相同的操作
Arm Adv SIMD 历史
2. 寄存器
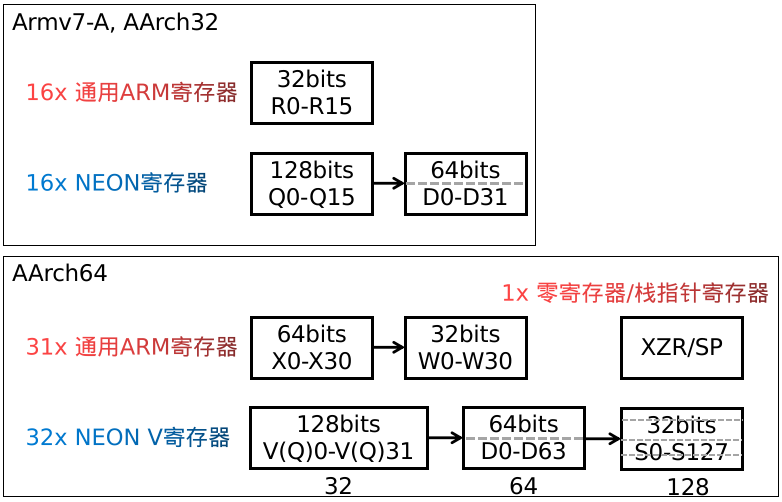
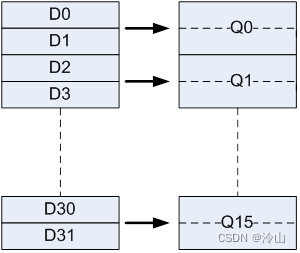
Armv7-A 和 AArch32 具有相同的通用 ARM 寄存器 - 16 1616 x 32 3232 位 通用ARM寄存器(R0-R15),以及 32 x 64 位 NEON寄存器(D0-D31)。这些寄存器也可以看作是 16 × 128 位寄存器(Quad-word, Q0-Q15)。每个 Q0-Q15 寄存器映射到一对 D寄存器,如下图所示。
相比之下,AArch64 具有 31 3131 个 64 6464 位 通用ARM寄存器 和 1 11 个具有不同名称的特殊寄存器(零寄存器/栈指针寄存器(XZR/SP)),这取决于使用它的上下文。这些寄存器可以被看作是 31 3131 个 64 6464 位寄存器(X0-X30) 或 31 3131 个32 3232 位寄存器(W0-W30)(高32位被忽略)。
AArch64 具有 32 3232 x 128 128128 位 NEON 寄存器(V0-V31,Vector Registers)(整个的寄存器被叫做V寄存器,即用来做向量化的寄存器,Vector Registers,但用作128位寄存器时,还是可以称作 Q寄存器,这样很明显更有指向性)。这些寄存器也可以看作是 32 3232 位 Sn寄存器(Single-word Registers) 或 64 6464 位 Dn寄存器(Double-word Registers) 或 16 1616 位的 H寄存器(Half-precision Registers)。

(也就是说,V 寄存器有 128 位,D 寄存器 64 位,S寄存器 32 位,可以将 V 寄存器拆开使用)
3. NEON 命名方式
变量命名方式:
baseWxLxN_t- base:是基础数据类型
- W:是基础类型的宽度
- L:是向量的长度
- N:是向量数组的个数
- 如
uint8x16_t、uint8x16x3_t
函数命名方式:
- ret v[p][q][r]name[u][n][q](args)
- ret:返回值类型
- v:表示vector
- q:饱和运算,溢位后,为自动限制在数据类型的最大范围内
- r:圆整操作
- name:SIMD指令名称
- u:unsigned
- n:narrow
- q:做后缀表示128位满位宽寄存器运算 quarter*32
4. 优化技巧
-
热点函数涉及到大量 IO 读写操作时,数据的内存地址尽量与 NEON 数组或系统位数对齐,如32位对齐,可降低访问开销;
-
重点优先搞 NEON 指令并行计算,能大幅降低开销;
-
大部分的 NEON 问题会出在存取、移动指令的滥用、混乱使用上;
-
for循环:- 如 for (b = 0; b < num; b++):
- 可改成 for (b = 0; b < num - 3; b += 4);
- 或者 for (b = num - 1; b >= 3; b -= 4);
- 需注意结尾不能整除的几个还是用非SIMD方式计算:
- 原始:for (i = 0; i < size; i++);
- 并行:for (i = 0; i < size - 3; i += 4);
- 扫尾:for (; i < size; i ++)。
- 数组索引取值:
- 数组索引以及索引内部涉及运算的,尽量换成指针偏移加减来做;
- 避免大范围索引跳跃,减少 cache miss。
- 内存使用:
- 优先用局部变量,而非 malloc 堆内存,减少 cache miss;
- 针对具体变量类型,手动 for 循环并行拷贝值,可能比 memcpy() 函数更高效,因为 memcpy 内部还涉及大量判断,以保证平台兼容性;
- 用NEON指令时,4 路运算的数组(128位=16字节),内存地址最好要 16 字节对齐。
- 指令运算
- 矩阵乘场景,在不大幅增加寄存器变量的前提下,外部的A也最好并行多读几路数据进来,跟B的各列运算,减少B各列的读取次数;
- 乘加指令,add 和 mul 可以合并为 mla,一条指令完成乘加操作。
- C 语言编码级考虑
- C 语言中一条事件的处理函数尽可能在一个源文件中(便于编译器自动向量化);
switch比if else快,而且代码整洁。
- 深入理解计算机系统
- 组织代码结构,善用 CPU 缓存,数据段/代码段连续可以提高 CPU 缓存命中率
- 极简函数时,尽量 inline 展开,减少函数调用栈的开销;
- 消除不必要的存储器引用,如 for 循环中 *dest = *dest - nums[i],可用中间变量替换 *dest,for 循环后再赋值给 *dest,可减少 for 内的一次读写操作;
- 简单的循环展开,编译器可以自己完成,优化选项 O2 及以上,或者命令 -funroll-loops(O2 及以上自带),可调用 gcc 进行循环展开;
- 能用整型不用浮点,整数乘法/加法和浮点加法,只用一个周期,浮点乘法需要2个周期。
- NEON 与 SSE 在寄存器处理数据时有一些区别。在 NEON 中,通常需要先将要处理的数据加载到 NEON 寄存器,然后执行 SIMD 操作。这与 SSE 有一些不同,因为 SSE 寄存器(XMM 寄存器)可以直接与内存交互(这一步可能格外耗时,需要特别注意)。在 NEON 中,加载数据到 NEON 寄存器通常包括以下步骤:
- 从内存加载数据到通用寄存器(通常是ARM通用寄存器)。
- 将数据从通用寄存器传送到 NEON 寄存器。
然后,您可以在 NEON 寄存器上执行 SIMD 操作,例如矢量加法、矢量乘法等。
这与 SSE 不同,因为 SSE 寄存器可以直接从内存加载数据,而不需要中间步骤。这可以在 SSE 指令中实现,而不需要将数据先加载到通用寄存器中。
总之,NEON 需要额外的步骤来加载数据到寄存器,然后才能进行 SIMD 操作,而 SSE 可以更直接地在寄存器中操作数据。这是因为不同架构和指令集设计的差异。
5. 优化 NEON 代码(Armv7-A内容,但区别不大)
5.1 优化 NEON 汇编代码
考虑处理器如何集成 NEON 技术的实现定义方面,因为针对特定处理器优化的指令序列可能在不同的处理器上具有不同的时序特征,即使 NEON 指令周期时序相同。
为了从手写的 NEON 代码中获得最佳性能,有必要了解一些底层硬件特性。特别是,程序员应该意识到流水线和调度问题、内存访问行为和调度危害。
5.1.1 Cortex-A 处理器之间的 NEON 管道差异
Cortex-A8 和 Cortex-A9 处理器共享相同的基本 NEON 管道,尽管在如何将其集成到处理器管道中存在一些差异。Cortex-A5 处理器包含一个完全兼容的简化 NEON 执行管道,但它是为尽可能最小和最低功耗的实现而设计的。
5.1.2 内存访问优化
TLB(Translation Lookaside Buffer) 是计算机系统中的一种硬件缓存,用于加速虚拟地址到物理地址的转换过程。TLB 的每个条目称为 TLB entry(TLB条目),它存储了一组 虚拟地址 和相应的 物理地址 之间的映射关系。TLB 通常位于 CPU 内部,用于提高内存访问的速度。
当程序执行时,CPU 需要将虚拟地址(由程序使用)转换为物理地址(在内存中实际存储数据的地址)。这个地址转换通常由操作系统的内存管理单元(MMU)来执行。MMU 将虚拟地址映射到物理地址,并在需要时将这些映射关系存储在 TLB 中,以便以后的访问可以更快地完成,而无需再次执行昂贵的地址转换操作。
TLB entry 通常包括以下信息:
- 虚拟地址(Virtual Address):程序使用的地址。
- 物理地址(Physical Address):在内存中实际存储数据的地址。
- 标志位(Flags):包括权限信息(例如,读、写、执行权限)和其他控制信息。
当 CPU 需要访问内存中的数据时,它首先查看 TLB 来查找虚拟地址和物理地址之间的映射关系。如果找到了匹配的 TLB entry,那么物理地址将用于访问内存,这将显著提高内存访问速度。如果没有找到匹配的 TLB entry,CPU 将向 MMU 请求执行地址转换,并将结果存储在 TLB 中以供将来使用。
总之,TLB entry 是 TLB 中存储的虚拟地址到物理地址映射的单元,用于加速计算机内存访问的过程。这有助于提高系统的性能和效率。
L1 和 L2 缓存的概念可以看这篇文章,描述的更清楚:寄存器、缓存、内存(虚拟、物理地址)、DDR、RAM的关系
NEON 单元很可能会处理大量数据,例如数字图像。一个重要的优化是确保算法以最适合缓存的方式访问数据。这样可以从 L1 和 L2 缓存中获得最大的命中率(hit rate)。考虑活动内存位置的数量也很重要。在 Linux 下,每个 4KB 的页面都需要一个单独的 TLB 条目。Cortex-A9 处理器有多个 32 3232 个元素的 micro-TLB 和一个 128 128128 个元素的主 TLB,之后它将开始使用 L1 缓存来加载页表条目(page table entry)。一种典型的优化是安排算法以适当的大小处理图像数据,以最大限度地提高缓存和 TLB 命中率。
支持 交错(interleaving) 和 反交错(de-interleaving) 的指令可以为性能改进提供很大的空间。VLD1 从内存加载寄存器,没有去交错。然而,其他 VLDn 操作使我们能够加载、存储和反交错包含两个、三个或四个相同大小的 8 88、16 1616 或 32 3232 位元素的结构。VLD2 加载两个或四个寄存器,去交错的偶数和奇数元素。例如,这可以用于分割左通道和右通道立体声音频数据,如下图所示。类似地,VLD3 可用于将 RGB 像素分割为单独的通道,相应地,VLD4 可用于 ARGB 或 CMYK 图像。
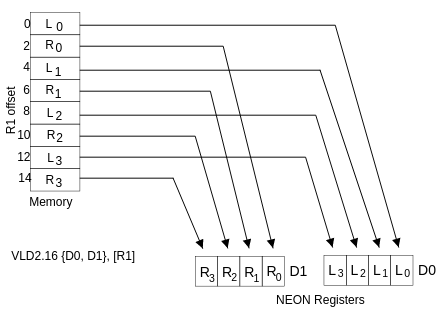
上图显示了用 VLD2.16(16字节) 从 R1 指向的内存中加载两个 NEON 寄存器。这在第一个寄存器中产生 4 44 个 16 1616 位元素,在第二个寄存器中产生 4 个 16位元素,相邻的成对左值和右值被分隔到每个寄存器中。









)


:音频重采样)

![【[特殊字符][特殊字符] 协变与逆变:用“动物收容所”讲清楚 PHP 类型的“灵活继承”】](http://pic.xiahunao.cn/【[特殊字符][特殊字符] 协变与逆变:用“动物收容所”讲清楚 PHP 类型的“灵活继承”】)





)