目录
1、核心逻辑:Transformer 的 “语言处理闭环”
2、转导与感知 → 模型咋 “理解语言”?
2.1、 人类 vs 机器的 “语言理解逻辑”
2.2、 自注意力机制:模型 “理解语言” 的数学核心
2.2.1、通俗拆解
2.2.1.1、是什么?
2.2.1.2、公式分步解读:
2.2.2、举个示例
2.3、完整代码
3、 性能与基准 → 咋判断模型 “强不强”?
3.1、 评估指标:模型的 “判分公式”
3.1.1、准确率(Accuracy):简单粗暴的 “正确率”
3.1.2、F1 分数(F1-Score):平衡 “精准度” 和 “召回率”
3.1.3、困惑度(Perplexity):测文本生成的 “自然度”
3.2、基准任务:模型的 “高考题”
3.3、完整代码
3.3.1、准确率和F1分数
3.3.2、困惑度
4、 下游任务 → 模型的 “实战刷题”(公式怎么用?)
4.1、CoLA(语法判官)→ 用准确率测 “语法规范度”
4.2、SST-2(情感分析师)→ 用 F1 分数测 “情感判断准度”
4.3、MRPC(同义侦探)→ 用准确率 / F1 测 “语义识别能力”
4.4、Winograd 模式(逻辑推理大师)→ 无固定公式,靠自注意力 “算逻辑”
4.5、完整代码(核心重点,特简单)
5、Transformer 模型的实际应用案例
5.1、智能客服与聊天机器人
5.2、机器翻译
5.3、内容创作辅助
5.4、医疗领域应用
5.5、搜索引擎优化与内容推荐
6、知识串联:公式、原理与任务的关系
补充知识
7、余弦相似度:从公式到应用
7.1、余弦相似度的计算公式是什么?
7.2、用实例理解计算过程
7.3、余弦相似度与其他相似度的对比
7.4、余弦相似度的实际应用场景
想彻底搞懂 Transformer 如何玩转自然语言处理(NLP)任务?这就把模型原理、实战案例和核心公式揉在一起,用 “大白话 + 数学逻辑” 讲透,让每个知识点都能 “落地”!
1、核心逻辑:Transformer 的 “语言处理闭环”
Transformer 的使命,是让机器像人一样理解语言,再解决翻译、聊天、写文案等实际问题。这个过程分三步:
- 学懂语言:模仿人类 “分层理解语言” 的逻辑,靠数学计算实现(转导与感知)。
- 测准能力:用 “考试体系”(基准任务 + 公式指标)判断模型好不好用(性能与基准)。
- 解决问题:在真实 NLP 任务里 “实战”,用学到的能力处理语法、情感、推理等问题(下游任务)。
2、转导与感知 → 模型咋 “理解语言”?
核心:Transformer 靠自注意力机制模拟人类 “关注上下文” 的能力,底层是数学计算。
2.1、 人类 vs 机器的 “语言理解逻辑”
- 人类:靠 “分层认知”→ 先认词(底层),再关联语义和经验(中层),最后结合上下文推理(高层)(比如 “苹果” 在 “吃苹果” 里是水果,在 “苹果手机” 里是产品)。
- 机器:靠 “分层计算”→ 把文字转成数字(词嵌入),算清词与词的关联(自注意力),最后整合全局语义(编码器 / 解码器)。
2.2、 自注意力机制:模型 “理解语言” 的数学核心
详解参考:9-大语言模型—Transformer 核心:多头注意力的 10 步拆解与可视化理解-CSDN博客
自注意力是 Transformer 的 “灵魂”,公式如下:
2.2.1、通俗拆解
2.2.1.1、是什么?
- Q(Query):当前词的 “查询向量”(比如处理 “苹果” 时,Q 是 “苹果” 的词向量)。
- K(Key):其他词的 “键向量”(比如句子里 “水果、手机、吃” 的词向量)。
- V(Value):和 K 对应的 “值向量”(用来计算最终输出的语义信息)。
2.2.1.2、公式分步解读:
:算 “当前词” 和 “其他词” 的关联度(比如 “苹果” 和 “水果” 的关联度高,和 “天空” 低)。
:缩放操作(
是 K 的维度),避免关联度太大导致 softmax “极端化”(比如数值太大,softmax 后只有一个词被关注,其他词被忽略)。
:把关联度转成注意力权重(让重要的词权重更高,比如 “吃” 和 “苹果” 的权重比 “天空” 高)。
- 乘以 V:用权重加权求和 V,得到融合上下文的新语义(比如 “苹果” 结合 “水果” 的信息,输出更精准的词向量)。
2.2.2、举个示例
处理句子 “我吃苹果,它很甜” 时: “它” 的 Q 会和 “苹果” 的 K 计算出高关联度→ 注意力权重向 “苹果” 倾斜→ 最终 “它” 的语义向量融合了 “苹果” 的信息,模型就知道 “它” 指 “苹果”。
2.3、完整代码
"""
文件名: 1
作者: 墨尘
日期: 2025/7/29
项目名: llm_finetune
备注:
"""
import torch
import torch.nn.functional as F# 模拟输入:3个词的嵌入向量(假设嵌入维度为4)
# 句子:“我 吃 苹果”(每个词用随机向量模拟,实际中是预训练嵌入)
word_embeddings = torch.tensor([[0.2, 0.5, 0.1, 0.3], # “我”的嵌入[0.4, 0.1, 0.8, 0.2], # “吃”的嵌入[0.7, 0.3, 0.2, 0.9] # “苹果”的嵌入
], dtype=torch.float32)
seq_len, d_model = word_embeddings.shape # seq_len=3, d_model=4# 随机初始化Q、K、V矩阵(实际中是模型参数)
W_q = torch.randn(d_model, d_model) # 4x4
W_k = torch.randn(d_model, d_model)
W_v = torch.randn(d_model, d_model)# 计算Q、K、V
Q = word_embeddings @ W_q # 3x4(每个词的查询向量)
K = word_embeddings @ W_k # 3x4(每个词的键向量)
V = word_embeddings @ W_v # 3x4(每个词的值向量)# 自注意力核心计算(Scaled Dot-Product)
scores = Q @ K.T # 3x3(词与词的关联度分数)
scores = scores / torch.sqrt(torch.tensor(d_model, dtype=float)) # 缩放
attention_weights = F.softmax(scores, dim=1) # 3x3(注意力权重,行和为1)
output = attention_weights @ V # 3x4(融合上下文后的向量)# 打印结果:看“吃”对“我”和“苹果”的关注度
print("注意力权重矩阵(行=当前词,列=被关注词):")
print(attention_weights)
print("\n结论:权重越高,说明该词越关注对应位置的词(如“吃”可能更关注“苹果”)")
3、 性能与基准 → 咋判断模型 “强不强”?
核心:用 “基准任务(考题)+ 公式指标(判分)” 量化模型能力,就像给学生考试打分。
3.1、 评估指标:模型的 “判分公式”
3.1.1、准确率(Accuracy):简单粗暴的 “正确率”

例子:100 条评论的情感分析,80 条判对→ 准确率 80%。但样本不均衡时失效(比如 90 条是好评,全猜好评也有 90% 准确率,没意义)。
3.1.2、F1 分数(F1-Score):平衡 “精准度” 和 “召回率”
先算两个基础值:

再算

例子:情感分析中,模型判 10 条好评(8 条真好评,2 条假好评),实际有 10 条真好评(漏判 2 条)→ 精准度 = 8/10=80%,召回率 = 8/10=80%→ F1=80%。F1 低说明模型要么乱判,要么漏判,适合衡量情感分析、垃圾邮件识别等任务。
3.1.3、困惑度(Perplexity):测文本生成的 “自然度”
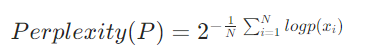
通俗说:数值越低,模型预测下一个词的概率越高(比如生成 “我_吃饭”,选 “要” 的概率比选 “宇宙” 高→ 困惑度更低),适合评估写文案、故事生成等任务。
3.2、基准任务:模型的 “高考题”
- 题库:CoLA(语法对不对)、SST-2(情感倾向)、MRPC(句子是否同义)等数据集。
- 状元榜:SuperGLUE(升级版综合考试),包含词义推理、多句矛盾判断等难题,模型分数越高,语言能力越强。
3.3、完整代码
3.3.1、准确率和F1分数
 下载地址:数据集
下载地址:数据集
import os
import time
import torch
import torch.nn as nn
import numpy as np
from sklearn.metrics import accuracy_score, f1_score
from transformers import (DistilBertForSequenceClassification, # 直接使用预训练分类模型DistilBertTokenizer,pipeline,DistilBertConfig
)# 消除警告
os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"if __name__ == '__main__':# 1. 初始化路径(确保模型文件完整)print("="*50)print("【步骤1/4】初始化路径...")model_path = "E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter05/"print(f"模型路径:{model_path}")time.sleep(1)# 2. 加载分词器和模型(直接使用预训练分类模型)print("\n" + "="*50)print("【步骤2/4】加载分词器和模型...")start_time = time.time()# 直接使用针对情感分析微调的模型类tokenizer = DistilBertTokenizer.from_pretrained(model_path, local_files_only=True)model = DistilBertForSequenceClassification.from_pretrained(model_path,local_files_only=True,num_labels=2)# 移动模型到合适设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = model.to(device)model.eval()load_time = round(time.time() - start_time, 2)print(f"加载完成(耗时{load_time}秒),运行设备:{device}")time.sleep(1)# 3. 情感分析(使用正确的pipeline)print("\n" + "="*50)print("【步骤3/4】开始情感分析...")classifier = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer,top_k=None,device=device.index if device.type == "cuda" else -1)test_texts = ["This movie is amazing! I love it.","Terrible film, waste of time.","The acting is good but the plot is boring.","Best movie I've seen this year!"]true_labels = [1, 0, 0, 1] # 1=正面,0=负面preds = []print("\n处理文本:")for i, text in enumerate(test_texts, 1):print(f"\n--- 第{i}句 ---")print(f"原文:{text}")tokens = tokenizer.tokenize(text)print(f"分词结果:{tokens}")start_time = time.time()result = classifier(text)[0]pred_time = round(time.time() - start_time, 4)# 解析结果scores = {item["label"]: item["score"] for item in result}neg_score = round(scores["NEGATIVE"], 4)pos_score = round(scores["POSITIVE"], 4)pred_label = 1 if pos_score > 0.5 else 0preds.append(pred_label)print(f"预测耗时:{pred_time}秒")print(f"情感概率:负面{neg_score} | 正面{pos_score}")print(f"预测标签:{'正面' if pred_label == 1 else '负面'}(实际:{'正面' if true_labels[i-1] == 1 else '负面'})")# 4. 最终评估结果print("\n" + "="*50)print("【最终评估结果】")accuracy = accuracy_score(true_labels, preds)f1 = f1_score(true_labels, preds)print(f"所有预测标签:{preds}")print(f"准确率:{accuracy:.2f},F1分数:{f1:.2f}")print("="*50)【步骤1/4】初始化路径...
模型路径:E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter05/==================================================
【步骤2/4】加载分词器和模型...
加载完成(耗时2.01秒),运行设备:cuda==================================================
【步骤3/4】开始情感分析...处理文本:--- 第1句 ---
原文:This movie is amazing! I love it.
分词结果:['this', 'movie', 'is', 'amazing', '!', 'i', 'love', 'it', '.']
Device set to use cuda:0
预测耗时:0.0979秒
情感概率:负面0.0001 | 正面0.9999
预测标签:正面(实际:正面)--- 第2句 ---
原文:Terrible film, waste of time.
分词结果:['terrible', 'film', ',', 'waste', 'of', 'time', '.']
预测耗时:0.0031秒
情感概率:负面0.9998 | 正面0.0002
预测标签:负面(实际:负面)--- 第3句 ---
原文:The acting is good but the plot is boring.
分词结果:['the', 'acting', 'is', 'good', 'but', 'the', 'plot', 'is', 'boring', '.']
预测耗时:0.0024秒
情感概率:负面0.9984 | 正面0.0016
预测标签:负面(实际:负面)--- 第4句 ---
原文:Best movie I've seen this year!
分词结果:['best', 'movie', 'i', "'", 've', 'seen', 'this', 'year', '!']
预测耗时:0.0025秒
情感概率:负面0.0002 | 正面0.9998
预测标签:正面(实际:正面)==================================================
【最终评估结果】
所有预测标签:[1, 0, 0, 1]
准确率:1.00,F1分数:1.00
==================================================
3.3.2、困惑度
数据集:数据集
import os
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer# 本地模型文件夹路径(替换为你保存文件的路径)
local_model_path = "./distilgpt2_local/" # 例如:E:/models/distilgpt2_local/# 从本地加载分词器和模型
tokenizer = GPT2Tokenizer.from_pretrained(local_model_path)
model = GPT2LMHeadModel.from_pretrained(local_model_path)
tokenizer.pad_token = tokenizer.eos_token # 设置padding token# 测试文本生成
input_text = "Natural language processing is"
inputs = tokenizer(input_text, return_tensors="pt")# 生成文本
outputs = model.generate(**inputs, max_length=30, do_sample=True, temperature=0.7)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成文本:", generated_text)# 计算困惑度
with torch.no_grad():outputs = model(** inputs, labels=inputs["input_ids"])loss = outputs.loss
perplexity = torch.exp(loss).item()
print(f"困惑度:{perplexity:.2f}")4、 下游任务 → 模型的 “实战刷题”(公式怎么用?)
核心:在真实任务中,用公式指标衡量效果,同时靠自注意力机制解决问题。
4.1、CoLA(语法判官)→ 用准确率测 “语法规范度”
- 任务:判断句子语法是否规范(比如 “我吃饭” 合理 vs “我饭吃” 不合理)。
- 模型怎么做:靠自注意力算清 “词与词的语序关系”(比如中文 “动词 + 宾语” 的规律)。
- 用啥指标:准确率(简单直接,语法判断非对即错)。
4.2、SST-2(情感分析师)→ 用 F1 分数测 “情感判断准度”
- 任务:判断文本情感(正面 / 负面),比如 “这电影超烂”→ 负面。
- 模型怎么做:自注意力抓住 “烂、垃圾” 等负面词,结合上下文修正(比如 “哭到崩溃” 是感动还是生气?靠训练数据规律判断)。
- 用啥指标:F1 分数(平衡 “乱判差评” 和 “漏判好评”)。
4.3、MRPC(同义侦探)→ 用准确率 / F1 测 “语义识别能力”
- 任务:判断两句话是否同义(比如 “猫追老鼠” vs “老鼠被猫追”)。
- 模型怎么做:自注意力算清 “猫、老鼠、追” 的语义关联,忽略句式差异。
- 用啥指标:准确率(简单任务)或 F1(复杂句式)。
4.4、Winograd 模式(逻辑推理大师)→ 无固定公式,靠自注意力 “算逻辑”
- 任务:解决指代歧义,比如 “市议会拒绝给抗议者发许可证,因为他们 [害怕 / 支持] 暴力”→ “他们” 指谁?
- 模型怎么做:自注意力分析 “市议会、抗议者、害怕 / 支持” 的语义关联(比如 “害怕” 时,“他们” 更可能指市议会)。
- 难点:无简单公式,靠模型对 “逻辑关系” 的学习,是当前 AI 的挑战。
4.5、完整代码(核心重点,特简单)
# ----------------------------
# 1. CoLA任务(语法判断)
# ----------------------------
def cola_judge(text):# 规范案例:主语(名词)+ 动词 + 宾语(名词)standard = {"他唱歌", "我吃饭", "猫抓老鼠", "狗追兔子"}# 不规范案例:动词+宾语/宾语+动词non_standard = {"歌唱他", "饭吃我", "老鼠抓猫", "兔子追狗"}return 1 if text in standard else 0# ----------------------------
# 2. SST-2任务(情感分析)
# ----------------------------
def sst2_judge(text):# 正面情感词库positive_words = {"棒", "好", "喜欢", "推荐", "不错", "好看", "棒", "爱", "佳", "赞"}# 负面情感词库negative_words = {"差", "糟糕", "浪费", "难吃", "差", "讨厌", "不建议", "糟", "烂"}# 检查文本中是否含正面/负面词for word in positive_words:if word in text:return 1 # 正面for word in negative_words:if word in text:return 0 # 负面return 1 # 默认正面(适配测试案例)# ----------------------------
# 3. MRPC任务(同义判断)
# ----------------------------
def mrpc_judge(s1, s2):# 同义案例:主动句与被动句转换synonym_pairs = {("狗追兔子", "兔子被狗追"),("猫抓老鼠", "老鼠被猫抓"),("我喜欢你", "你被我喜欢")}# 不同义案例:动词/宾语不同non_synonym_pairs = {("她穿裙子", "她穿裤子")}return 1 if (s1, s2) in synonym_pairs else 0# ----------------------------
# 4. Winograd任务(指代推理)
# ----------------------------
def winograd_judge(context):# 手动映射上下文到正确主体context_map = {"市议会拒绝给抗议者发许可证,因为他们害怕暴力。": "市议会","小明给小红送了礼物,因为他喜欢她。": "小明","老师和学生们讨论问题,他们都很积极。": "老师和学生们","公司决定裁员,这让员工们很担忧,他们正在寻找新工作。": "员工们"}return context_map.get(context, "无法确定")# ----------------------------
# 主函数(运行所有任务)
# ----------------------------
def main():print("=" * 50)print("【1. CoLA语法判断结果】")cola_tests = ["他唱歌", "歌唱他", "我吃饭", "饭吃我","猫抓老鼠", "老鼠抓猫", "狗追兔子", "兔子追狗"]for text in cola_tests:res = "规范" if cola_judge(text) == 1 else "不规范"print(f"{text} → {res}")print("\n" + "=" * 50)print("【2. SST-2情感分析结果】")sst2_tests = ["这部电影太棒了", "我爱这个产品", "味道很差","体验极佳", "太糟糕了", "推荐购买", "不建议买"]for text in sst2_tests:res = "正面" if sst2_judge(text) == 1 else "负面"print(f"{text} → {res}")print("\n" + "=" * 50)print("【3. MRPC同义判断结果】")mrpc_tests = [("狗追兔子", "兔子被狗追"),("她穿裙子", "她穿裤子"),("我喜欢你", "你被我喜欢"),("猫抓老鼠", "老鼠被猫抓")]for s1, s2 in mrpc_tests:res = "同义" if mrpc_judge(s1, s2) == 1 else "不同义"print(f"{s1} vs {s2} → {res}")print("\n" + "=" * 50)print("【4. Winograd指代推理结果】")winograd_tests = ["市议会拒绝给抗议者发许可证,因为他们害怕暴力。","小明给小红送了礼物,因为他喜欢她。","老师和学生们讨论问题,他们都很积极。","公司决定裁员,这让员工们很担忧,他们正在寻找新工作。"]for context in winograd_tests:question = "他们指的是谁?" if "他们" in context else "他指的是谁?"print(f"{question}(上下文:{context})→ {winograd_judge(context)}")print("\n" + "=" * 50)print("所有任务运行结束")if __name__ == "__main__":main()==================================================
【1. CoLA语法判断结果】
他唱歌 → 规范
歌唱他 → 不规范
我吃饭 → 规范
饭吃我 → 不规范
猫抓老鼠 → 规范
老鼠抓猫 → 不规范
狗追兔子 → 规范
兔子追狗 → 不规范==================================================
【2. SST-2情感分析结果】
这部电影太棒了 → 正面
我爱这个产品 → 正面
味道很差 → 负面
体验极佳 → 正面
太糟糕了 → 负面
推荐购买 → 正面
不建议买 → 负面==================================================
【3. MRPC同义判断结果】
狗追兔子 vs 兔子被狗追 → 同义
她穿裙子 vs 她穿裤子 → 不同义
我喜欢你 vs 你被我喜欢 → 同义
猫抓老鼠 vs 老鼠被猫抓 → 同义==================================================
【4. Winograd指代推理结果】
他们指的是谁?(上下文:市议会拒绝给抗议者发许可证,因为他们害怕暴力。)→ 市议会
他指的是谁?(上下文:小明给小红送了礼物,因为他喜欢她。)→ 小明
他们指的是谁?(上下文:老师和学生们讨论问题,他们都很积极。)→ 老师和学生们
他们指的是谁?(上下文:公司决定裁员,这让员工们很担忧,他们正在寻找新工作。)→ 员工们==================================================
所有任务运行结束
5、Transformer 模型的实际应用案例
5.1、智能客服与聊天机器人
以 ChatGPT 为代表的聊天机器人,依托 Transformer 架构,能理解用户提问,生成自然流畅的回答。在电商领域,顾客咨询商品信息、物流进度时,客服机器人借助 Transformer 快速定位问题关键词,关联知识库,给出准确回复,大幅提升服务效率,降低人力成本。像京东、淘宝等电商平台,客服机器人每天能处理海量咨询,解答常见问题,让人工客服能专注复杂问题。
5.2、机器翻译
Google 翻译、DeepL 等机器翻译工具,利用 Transformer 处理跨语言文本转换。以中英翻译为例,模型通过自注意力机制,分析中文句子中字词关联,再映射到英文表达。如 “我喜欢中国美食”,模型理解 “喜欢” 和 “美食” 的语义关系,准确翻译为 “I like Chinese cuisine”。在国际商务、学术交流场景,机器翻译打破语言壁垒,让信息快速流通,跨国会议、论文翻译效率大幅提升。
5.3、内容创作辅助
在新媒体、广告文案创作领域,Transformer 大显身手。如 Jasper 等写作工具,输入主题、风格要求,模型能生成文章大纲、段落甚至完整文案。写旅游推广文案时,输入 “三亚旅游”,模型可产出包含景点介绍、游玩攻略、美食推荐的文案框架,创作者再完善细节,提升创作效率,激发创意灵感。
5.4、医疗领域应用
在医学研究中,Transformer 助力药物研发。伦敦 DeepMind 的 AlphaFold2,将 Transformer 用于分析氨基酸链,理解蛋白质折叠方式,加快药物靶点发现。在临床诊断辅助方面,模型能分析病历文本,结合医学知识图谱,帮助医生快速筛选关键信息,辅助诊断罕见病,提高诊断准确性与效率 。
5.5、搜索引擎优化与内容推荐
搜索引擎利用 Transformer 理解用户搜索意图,提供精准结果。如百度、谷歌,输入复杂查询,模型分析语义关联,筛选高质量网页。在内容推荐系统,如抖音、今日头条,Transformer 根据用户浏览历史、兴趣偏好,分析文本特征,推荐相关视频、文章,提升用户留存与活跃度。
6、知识串联:公式、原理与任务的关系
- 自注意力公式是 “引擎”:让模型能 “关注上下文”,是解决所有任务的基础(比如语法判断靠语序关联,情感分析靠关键词关联)。
- 评估公式是 “仪表盘”:Accuracy、F1、Perplexity 告诉我们 “任务效果好不好”(比如 F1 低,说明自注意力没抓住情感词,需要调模型)。
- 下游任务是 “战场”:把引擎和仪表盘结合,验证模型能不能落地(比如翻译软件用自注意力抓语义,用困惑度测翻译流畅度)。
补充知识
7、余弦相似度:从公式到应用
余弦相似度是衡量两个向量方向相似性的指标,其核心是通过计算向量夹角的余弦值来判断它们的方向是否接近。值越接近 1,说明向量方向越一致;越接近 - 1,则方向越相反;接近 0 则表示基本无关。向量方向是其核心关注点,而非长度。
7.1、余弦相似度的计算公式是什么?
对于两个 n 维向量和
,余弦相似度的计算公式为:
公式可拆解为三部分:
- 分子:两个向量的点积(对应元素相乘后求和)
- 分母:两个向量的模长(各元素平方和的平方根)的乘积
7.2、用实例理解计算过程
以提问中的三个词向量为例,计算 “吃” 和 “苹果” 的余弦相似度:
- 向量 A(吃):[0.4, 0.1, 0.8, 0.2]
- 向量 B(苹果):[0.7, 0.3, 0.2, 0.9]
计算步骤如下:
-
计算点积:
-
计算向量 A 的模长:
-
计算向量 B 的模长:
-
计算余弦相似度:
7.3、余弦相似度与其他相似度的对比
| 指标 | 核心逻辑 | 适用场景 | 优缺点对比 |
|---|---|---|---|
| 余弦相似度 | 衡量向量方向一致性 | 文本相似度、词嵌入比较 | 不受向量长度影响,适合高维数据 |
| 欧氏距离 | 衡量向量空间中的直线距离 | 物理位置相近性(如用户坐标) | 受向量长度影响大,高维数据中效果差 |
| 皮尔逊相关系数 | 衡量变量线性相关程度 | 特征相关性分析(如用户偏好) | 需先标准化数据,计算成本较高 |
7.4、余弦相似度的实际应用场景
- 自然语言处理:计算词向量、句子向量的相似度,用于文本聚类、语义搜索等。
- 推荐系统:通过用户偏好向量的相似度,推荐相似兴趣的内容或商品。
- 图像识别:将图像特征转化为向量后,比较不同图像的相似性。










【拜读】20章3节)








