目录
一、项目简介
二、模型训练+验证+保存
三、模型测试+保存csv文件
四、单张图片预测
五、模型评估
六、ONNX导出
七、ONNX推理
八、网络结构与数据增强可视化
上篇我介绍了具体步骤,今天就以我实际开发的一个具体项目来讲:
一、项目简介
苯人的项目是基于CNN实现香蕉成熟度的小颗粒度分类,针对六种不同状态(新鲜成熟的、新鲜未熟的、成熟的、腐烂的、过于成熟的、生的)进行高精度视觉识别。由于香蕉的成熟度变化主要体现在颜色渐变、斑点分布及表皮纹理等细微差异上,传统图像处理方法难以准确区分。因此,本项目通过构建深层CNN模型,利用卷积层的局部特征提取能力捕捉香蕉表皮的细微变化,并结合高阶特征融合技术提升分类精度。
数据集长这样:
苯人是在 https://universe.roboflow.com/ 这个网站上下载的,kaggle我自己觉得不好用(其实是看不来),总之数据集有了,再说一嘴苯人是引用的 ResNet18网络模型,接下来就开始写代码吧:
二、模型训练+验证+保存
这里我就不像上篇那样这么详细了,主要是看流程:
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision.models import resnet18 #导入网络结构
from torch import optim# 模型保存
last_model_path = './model/last.pth'
best_model_path = './model/best.pth'#数据预处理
train_transforms = transforms.Compose([transforms.Resize((256, 256)), # 先稍微放大点transforms.RandomCrop(224), # 随机裁剪出 224x224transforms.RandomHorizontalFlip(p=0.5), # 左右翻转transforms.RandomRotation(degrees=15), # 随机旋转 ±15°transforms.ColorJitter(brightness=0.2, # 明亮度contrast=0.2, # 对比度saturation=0.2, # 饱和度hue=0.1), # 色调transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet均值std=[0.229, 0.224, 0.225]) # ImageNet标准差
])
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])#加载数据集
train_dataset = ImageFolder(root='./Bananas/train', transform= train_transforms)
valid_dataset = ImageFolder(root='./Bananas/valid', transform= val_transforms)#数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=64, shuffle=False)#迁移模型结构
model = resnet18(pretrained = True)
in_features = model.fc.in_features #动态获得输入
model.fc = nn.Linear(in_features, 6) #改成6分类
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 优化:解冻最后两层和fc层(更有学习能力)
for name, param in model.named_parameters():if "layer4" in name or "fc" in name:param.requires_grad = Trueelse:param.requires_grad = False#再用 filter 筛选需要梯度更新的参数
param_grad_true = filter(lambda x:x.requires_grad, model.parameters())#实例化损失函数对象
criterion = nn.CrossEntropyLoss()
#优化器 这里使用AdamW
optimizer = optim.AdamW(param_grad_true, lr=1e-3, weight_decay=0.01)
# 优化:添加学习率调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=5, factor=0.5, verbose=True)#开始训练+每10个轮次验证一次
def train(model, train_loader, valid_loader, epochs, validate_every=10):import os# 创建模型保存目录os.makedirs('./model', exist_ok=True)model.train()best_val_acc = 0 #初始化最优准确率# 优化:增加早停机制early_stopping_patience = 10no_improve_epochs = 0for epoch in range(epochs):running_loss = 0 #初始化每轮训练的损失correct = 0 #初始化正确数与总个数total = 0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)output = model(images) #得到预测值loss = criterion(output, labels) #计算损失optimizer.zero_grad() #梯度清零loss.backward() #反向传播optimizer.step() #根据梯度更新参数running_loss += loss.item() #当前epoch的总损失pred = torch.argmax(output, dim=1) #拿到当前图片预测是最大值的索引下标当做类别total += labels.size(0)correct += (pred == labels).sum().item()train_acc = correct/total * 100 #训练准确率print(f"[Epoch {epoch + 1}/{epochs}] Loss: {running_loss:.4f}, Accuracy: {train_acc:.2f}%")#验证部分if (epoch + 1) % validate_every == 0: #每10轮验证一次val_loss = 0val_total = 0val_correct = 0model.eval()with torch.no_grad(): #逻辑与训练函数差不多for val_images, val_labels in valid_loader:val_images, val_labels = val_images.to(device), val_labels.to(device)val_output = model(val_images)val_loss += (criterion(val_output, val_labels)).item()val_pred = torch.argmax(val_output, dim=1)val_total += val_labels.size(0)val_correct += (val_pred == val_labels).sum().item()val_acc = val_correct/val_total *100 #验证准确率# 优化:根据验证准确率调整学习率scheduler.step(val_acc)print(f"[Epoch {epoch + 1}/{epochs}] Loss: {running_loss:.4f}, Accuracy: {train_acc:.2f}%")#保存最优模型参数if val_acc > best_val_acc:best_val_acc = val_acctorch.save(model.state_dict(), best_model_path)print(f"保存了当前最优模型,验证正确率:{val_acc:.2f}%")# 优化:早停法else:no_improve_epochs += 1if no_improve_epochs >= early_stopping_patience:print(f"验证准确率连续{early_stopping_patience}轮没有提升,提前停止训练")break# 保存最近一次模型参数torch.save(model.state_dict(), last_model_path)model.train()train(model, train_loader, valid_loader, epochs=50) #训练50次看看
主要逻辑还是像上篇那样:数据预处理-->加载数据集-->数据加载器-->迁移模型结构-->改变全连接层-->配置训练细节(损失优化)-->训练函数-->每10轮训练后验证一次-->保存最近一次训练模型参数以及最优模型参数
改全连接层那里说一下,因为我做的是六分类,原来的模型结构是千分类,所以要把 out_features 改成6,同时冻结其他层只训练全连接层就好,但是因为第一次训练的效果不是很好,所以在优化的时候我又解冻了最后两层,增加了学习能力;另外还有优化就是对学习率,我增加了一个学习率调度器,动态学习率对模型来说效果更好;最后一个优化是增加了早停机制,即在验证准确率连续多少轮没有提升时自动停止训练,这样大大节省了训练时间
运行结果我就不贴了因为我搞忘截图了。。反正最后一轮准确率有98%,模型参数也保存了:
三、模型测试+保存csv文件
import torch
import os
import torch.nn as nn
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision.models import resnet18
import numpy as np
import pandas as pd#最优模型参数路径
best_model_path = './model/best.pth'#数据预处理
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])#准备测试数据集
test_dataset = ImageFolder(root='./Bananas/test', transform=val_transforms)#数据加载器
test_load = DataLoader(test_dataset, batch_size=64, shuffle=False)#导入模型结构
model = resnet18(pretrained = False) #不用加载自带的参数
in_features = model.fc.in_features #同样动态接受输入特征
model.fc = nn.Linear(in_features, 6) #同样更改模型结构device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#加载之前保存的最优模型参数
model.load_state_dict(torch.load(best_model_path, map_location = device))
model.to(device)#开始测试
model.eval()
correct = 0
total = 0
with torch.no_grad():for images, labels in test_load:images, labels = images.to(device), labels.to(device)out = model(images) #得到预测值pred = torch.argmax(out, dim=1)correct += (pred == labels).sum().item()total += labels.size(0)
test_acc = correct / total *100
print(f'测试集测试的准确率为:{test_acc:.2f}%')valid_dataset = ImageFolder(root='./Bananas/valid', transform= val_transforms)
valid_loader = DataLoader(valid_dataset, batch_size=64, shuffle=False)
classNames = valid_dataset.classes #拿到类名model.eval()
acc_total = 0
val_dataloader = DataLoader(valid_dataset, batch_size=64, shuffle=False)
total_data = np.empty((0,8))
with torch.no_grad():# 每个批次for x, y in val_dataloader:x = x.to(device)y = y.to(device)out = model(x)# [10,3]pred = torch.detach(out).cpu().numpy()# [10,]p1 = torch.argmax(out, dim=1)# 转化为numpyp2 = p1.unsqueeze(dim=1).detach().cpu().numpy()label = y.unsqueeze(dim=1).detach().cpu().numpy()batch_data = np.concatenate([pred, p2, label],axis=1)total_data = np.concatenate([total_data, batch_data], axis=0)# 构建csv文件的第一行(列名)
pd_columns = [*classNames, 'pred', 'label']os.makedirs('./results', exist_ok=True)
csv_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'results', 'number.csv'))pd.DataFrame(total_data, columns=pd_columns).to_csv(csv_path, index=False)
print("成功保存csv文件!")运行结果:
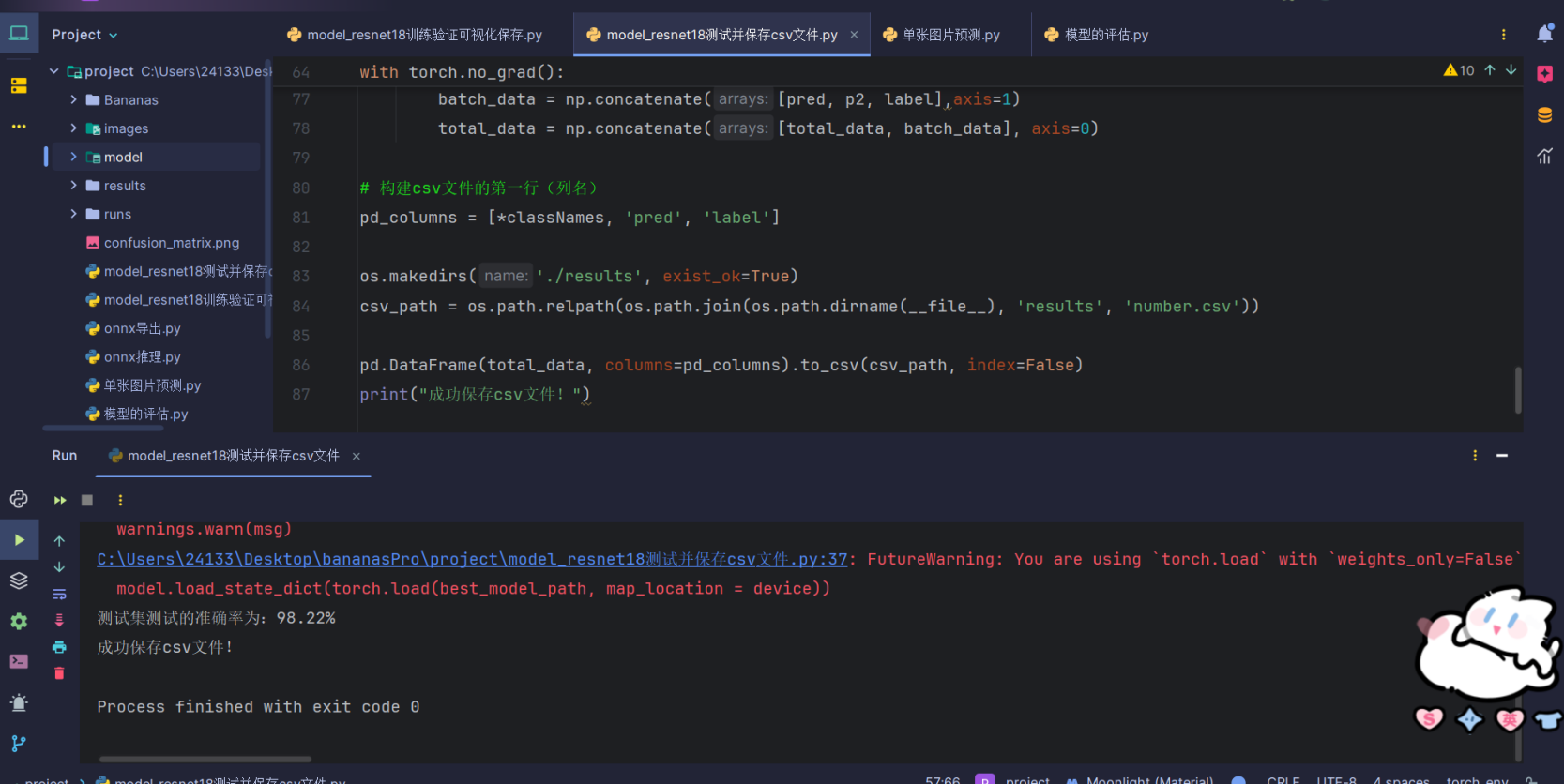
测试集的准确率也有这么高说明没有过拟合,我们可以打开csv文件看一下:
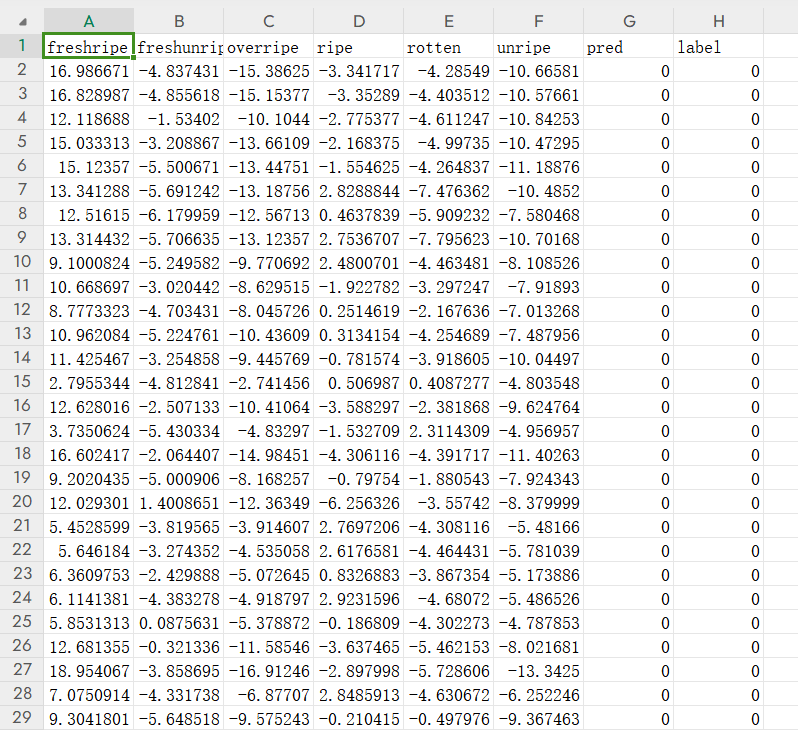
预测的准确率还是挺高的,这里也说明一下测试的时候是加载之前训练保存的模型参数,所以
model = resnet18(pretrained = False) 这里的参数填false,然后再加载保存的模型参数:
model.load_state_dict(torch.load(best_model_path, map_location = device)).
四、单张图片预测
这里我们可以从网上找几张图片来预测一下:
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torchvision.models import resnet18#最优模型参数路径
best_model_path = './model/best.pth'
10
#数据预处理
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
train_transforms = transforms.Compose([transforms.Resize((256, 256)), # 先稍微放大点transforms.RandomCrop(224), # 随机裁剪出 224x224transforms.RandomHorizontalFlip(p=0.5), # 左右翻转transforms.RandomRotation(degrees=15), # 随机旋转 ±15°transforms.ColorJitter(brightness=0.2, # 明亮度contrast=0.2, # 对比度saturation=0.2, # 饱和度hue=0.1), # 色调transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet均值std=[0.229, 0.224, 0.225]) # ImageNet标准差
])#加载图片
img_path = 'images/b8_rotten.jpg'
img = Image.open(img_path).convert('RGB') # 确保是RGB三通道
img = val_transforms(img) # 应用transform
img = img.unsqueeze(0) # 加上 batch 维度#导入模型结构
model = resnet18(pretrained = False) #不用加载自带的参数
in_features = model.fc.in_features #同样动态接受输入特征
model.fc = nn.Linear(in_features, 6) #同样更改模型结构device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#加载之前保存的最优模型参数
model.load_state_dict(torch.load(best_model_path, map_location = device))
model.to(device)#模型预测
model.eval()
with torch.no_grad():output = model(img)pred_class = torch.argmax(output, dim=1).item()train_dataset = ImageFolder(root='./Bananas/train', transform= train_transforms)
idx_to_class = {v: k for k, v in train_dataset.class_to_idx.items()}
pred_label = idx_to_class[pred_class]
print(f"模型预测这张图片是:{pred_label}")运行结果:
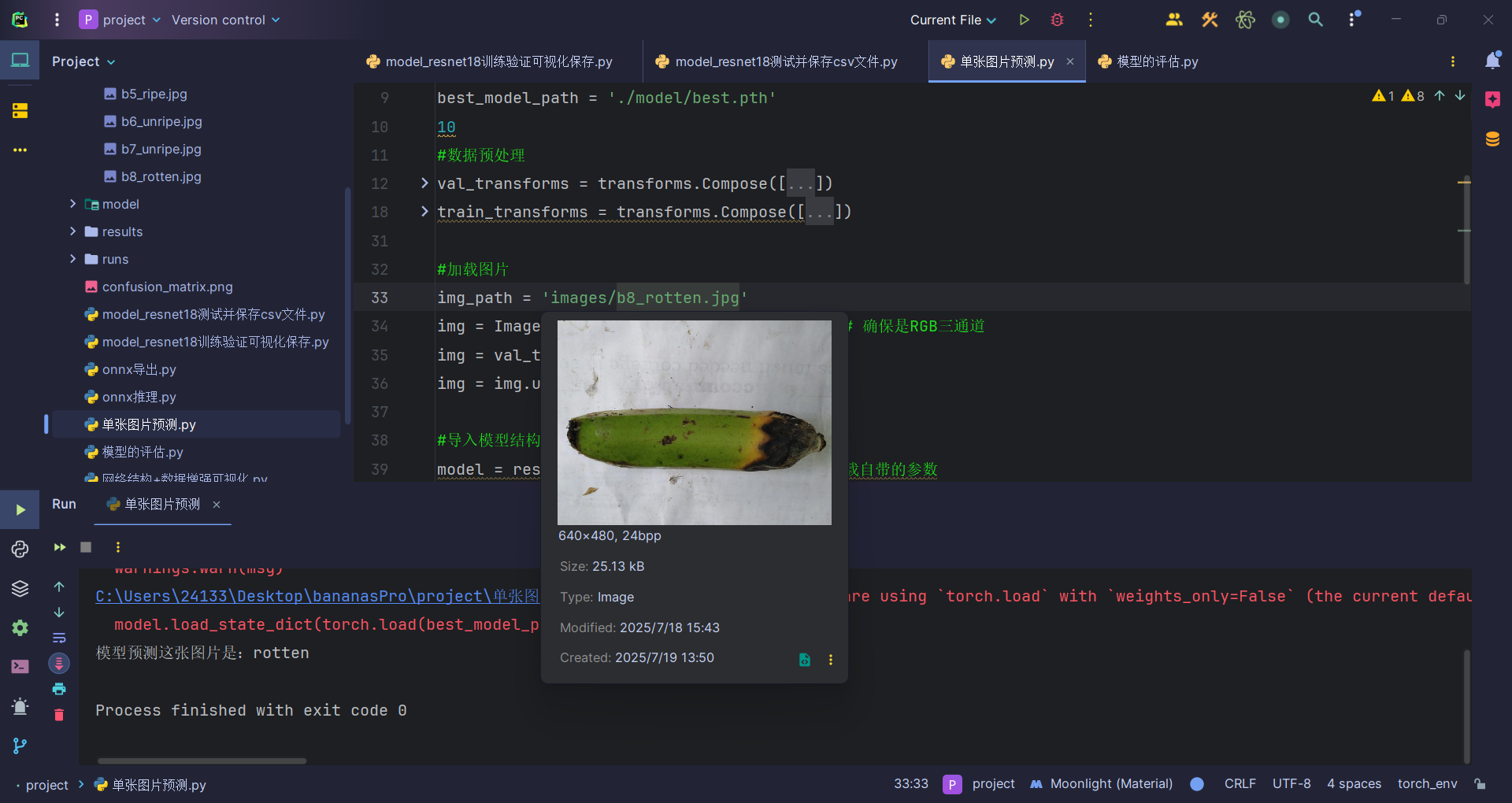
注意要记得给原图片升维,因为要求传入的图片形状是(N, C, H, W)
五、模型评估
在CNN项目中,对模型评估的指标(准确率、召回率、F1等)应该基于测试集的结果进行最终评估,因为模型在测试集上的表现是最接近于真实情况的:
import pandas as pd
import os
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib
import matplotlib.pyplot as plt#设置中文字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = Falsecsv_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'results', 'number.csv'))
# 读取CSV数据
csvdata = pd.read_csv(csv_path, index_col=0)
# 拿到真实标签
true_label = csvdata["label"].values
# 拿到预测标签
true_pred = csvdata["pred"].values# 根据预测值和真实值生成分类报告
report = classification_report(y_true=true_label, y_pred=true_pred)
print(report)# 混淆矩阵可视化
cm = confusion_matrix(true_label, true_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=[str(i) for i in range(6)])
disp.plot(cmap='Greens', values_format='d')
plt.title("训练结果混淆矩阵视图")
plt.tight_layout()
plt.savefig("confusion_matrix.png")
plt.show()
运行结果:
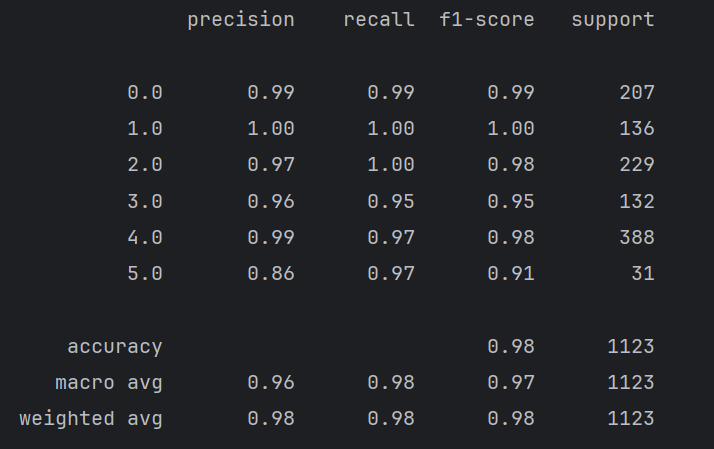
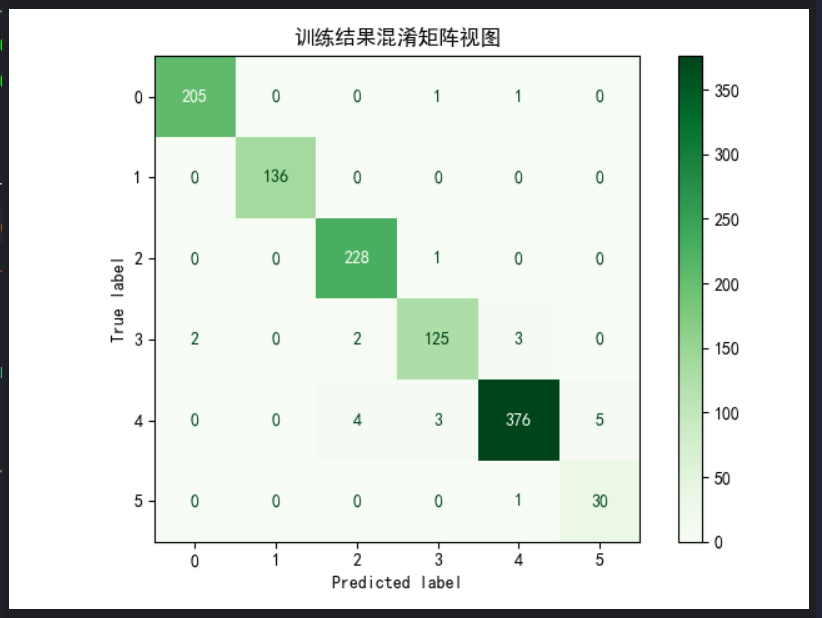
可以看到,f1分数比较高,混淆矩阵的对角线数字也很大,说明模型表现良好。
六、ONNX导出
导出为ONNX格式主要是它兼容性很高,且可以被专用推理引擎优化,减少计算开销,代码如下:
import torch
from torchvision.models import resnet18
import torch.nn as nnbest_model_path = './model/best.pth'
onnx_path = './model/best.onnx' #保存路径#加载模型结构与权重参数
model = resnet18(pretrained = False)
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, 6) #同样修改全连接层device = torch.device("cuda" if torch.cuda.is_available() else "cpu" )
model.load_state_dict(torch.load(best_model_path, map_location=device))#创建实例输入
x = torch.randn(1, 3, 224, 224)
out = model(x)
# print(out.shape) #确认输出不是None torch.Size([1, 6])#导出onnx
model.eval()
torch.onnx.export(model, x, onnx_path, verbose=False, input_names=["input"], output_names=["output"])
print("onnx导出成功!")import onnx
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print("onnx模型检查通过!")导出后我们可以通过这个网站来可视化一下:Netron,打开刚刚保存的ONNX文件:
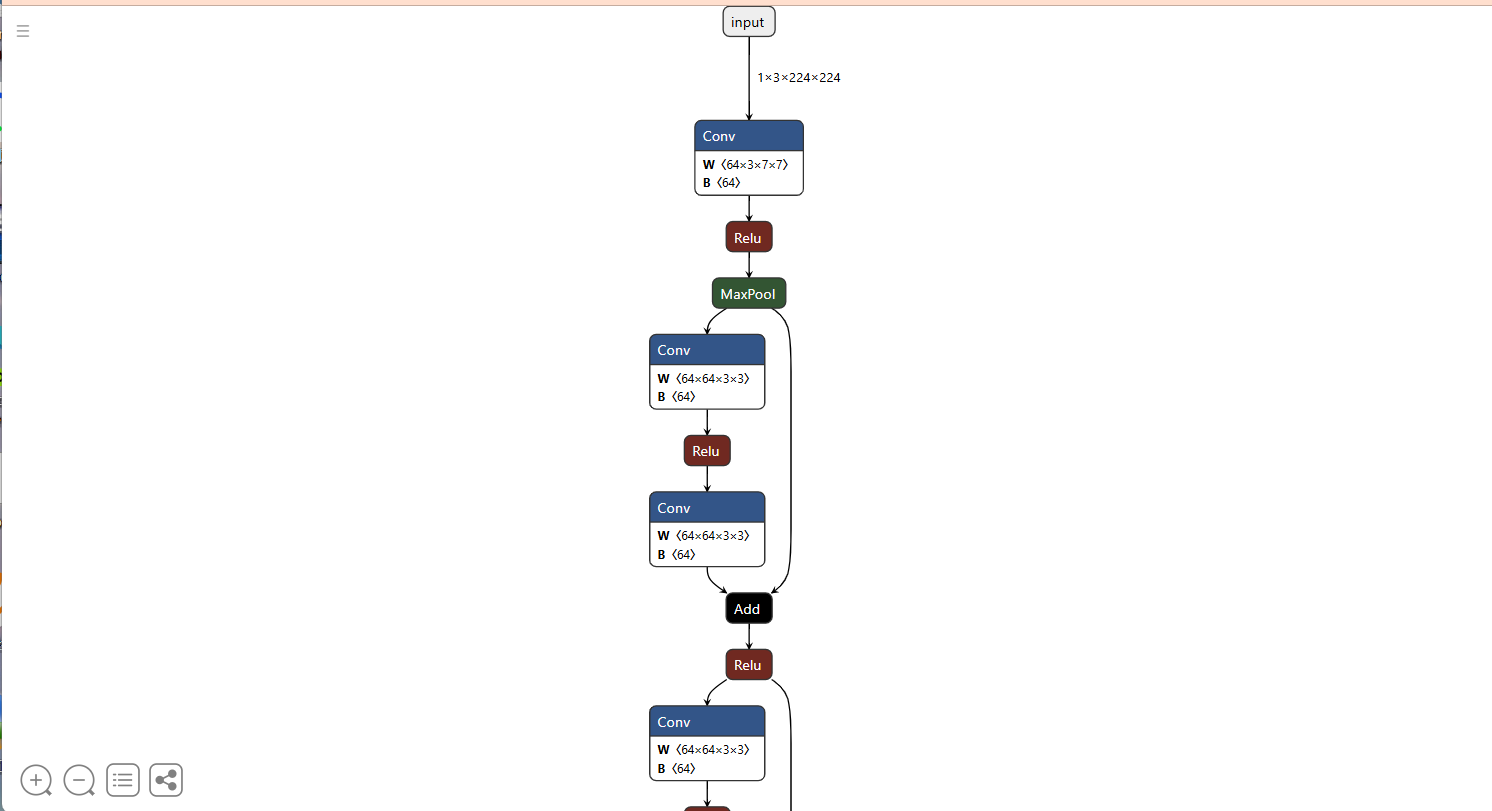
然后就可以看到网络结构了,这里我只截一部分:
七、ONNX推理
代码如下:
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
from PIL import Image
import onnxruntime as ort
import torch#数据预处理
val_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])#加载路径
img_path = './images/b8_rotten.jpg'
onnx_path = './model/best.onnx'#加载并处理图片
img = Image.open(img_path).convert("RGB")
img_tensor = val_transforms(img) #经过数据预处理后转为了tensor
img_np = img_tensor.unsqueeze(0).numpy()
# print(img_tensor.shape) torch.Size([3, 32, 32])#加载onnx模型
sess = ort.InferenceSession(onnx_path)
out = sess.run(None, {"input": img_np})
# print(out)
# [array([[-6.8998175, -8.683616 , -5.1299562, -2.8295422, 8.335733 ,
# -5.098113 ]], dtype=float32)]#后处理
valid_dataset = ImageFolder(root='./Bananas/valid', transform= val_transforms)
valid_loader = DataLoader(valid_dataset, batch_size=64, shuffle=False)
classNames = valid_dataset.classes #拿到类名
# print(classNames)
# ['freshripe', 'freshunripe', 'overripe', 'ripe', 'rotten', 'unripe']logits = out[0]
#用softmax函数将结果转成0-1之间的概率
probs = torch.nn.functional.softmax(torch.tensor(logits), dim=1)
pred_index = torch.argmax(probs).item()
pred_label = classNames[pred_index]print(f"\n 预测类别为:{pred_label}")
print("各类别概率:")
for i, cls in enumerate(classNames):print(f"{cls}: {probs[0][i]:.2%}")注意传入ONNX模型的必须是numpy数组。
运行结果:

其实感觉预测得有点绝对,但是这个模型的准确率这么高我也是没想到
八、网络结构与数据增强可视化
如果想要更直观地看到训练变化的话可以加这一步:
import torch
from torch.utils.tensorboard import SummaryWriter
from torchvision.utils import make_grid
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torchvision.models import resnet18
import torch.nn as nn# 可视化配置
writer = SummaryWriter("runs/501_tensorboard")# 网络结构可视化
print("添加网络结构图")
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 6)
input = torch.randn(1, 3, 224, 224) # ResNet18的输入尺寸
writer.add_graph(model, input)# 数据增强效果可视化
print("添加数据增强图像")
# 数据增强方式
train_transforms = transforms.Compose([transforms.Resize((256, 256)), # 先稍微放大点transforms.RandomCrop(224), # 随机裁剪出 224x224transforms.RandomHorizontalFlip(p=0.5), # 左右翻转transforms.RandomRotation(degrees=15), # 随机旋转 ±15°transforms.ColorJitter(brightness=0.2, # 明亮度contrast=0.2, # 对比度saturation=0.2, # 饱和度hue=0.1), # 色调transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet均值std=[0.229, 0.224, 0.225]) # ImageNet标准差
])# 加载训练数据集
train_dataset = ImageFolder(root='./Bananas/train', transform= train_transforms)# 写入3轮不同的数据增强图像
for step in range(3):imgs = torch.stack([train_dataset[i][0] for i in range(64)]) # 取64张图grid = make_grid(imgs, nrow=8, normalize=True)writer.add_image(f"augmented_mnist_step_{step}", grid, global_step=step)writer.close()
print("所有可视化完成!")
运行代码后在终端输入 tensorboard --logdir=runs,回车后可以看到生成了一个网址,用浏览器直接访问即可,如果不行的话就在 runs 后面加当前文件的绝对路径,苯人的可视化是这样:
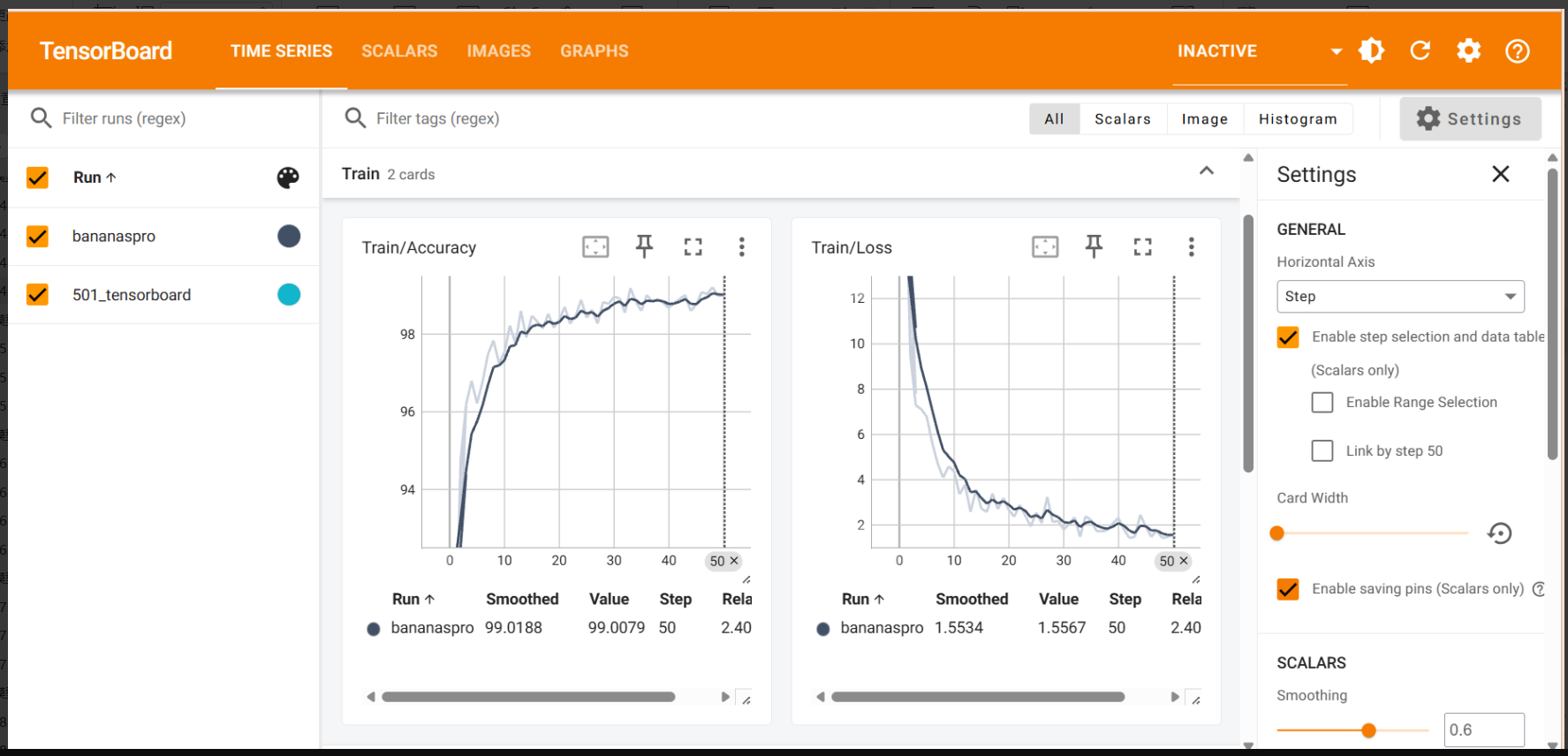
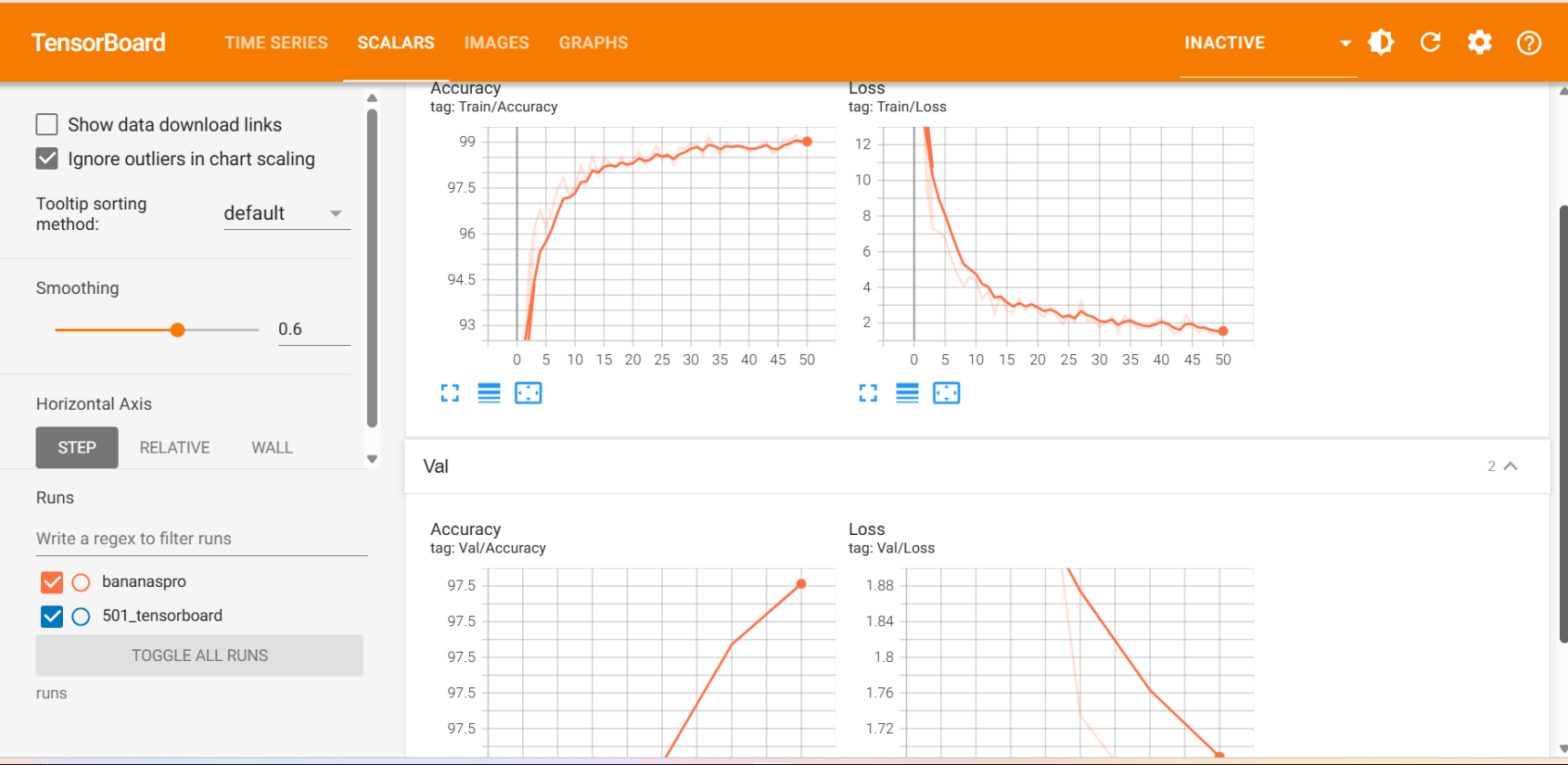
数据增强可视化:
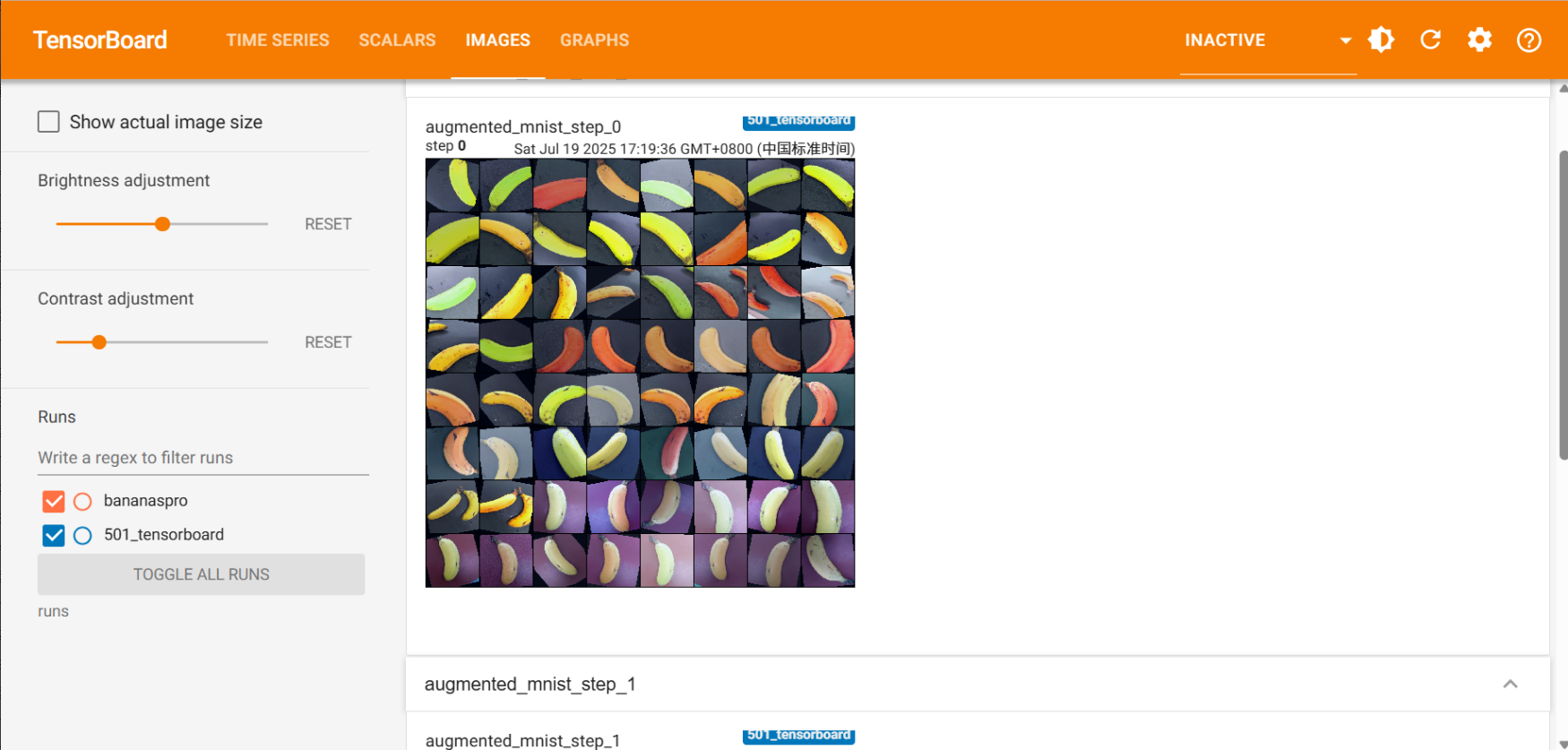
最后,我整个的项目文件夹长这样:
对上篇的补充就到此为止,下一篇写啥也没想好,前面拖得太多了。。
以上有问题可以指出(๑•̀ㅂ•́)و✧


)







)




![[IMX][UBoot] 16.Linux 内核移植](http://pic.xiahunao.cn/[IMX][UBoot] 16.Linux 内核移植)



