文章目录
- 存储热迁移流程
- 总体流程
- 代码路径
- QEMU Block layer
- 架构简述
- Block Job
- 结构体设计
- 状态转换
- Mirror block job
- 拓扑结构
- 构建过程
- 数据结构
存储热迁移流程
总体流程
Libvirt migrate 命令提供 copy-storage-all 选项支持存储热迁移,相应地,Libvirt 热迁移 API
(virDomainMigrateToURIX) 提供 VIR_MIGRATE_NON_SHARED_DISK flag 支持上层应用发起存储热迁移。下图为存储热迁移的简要流程图:
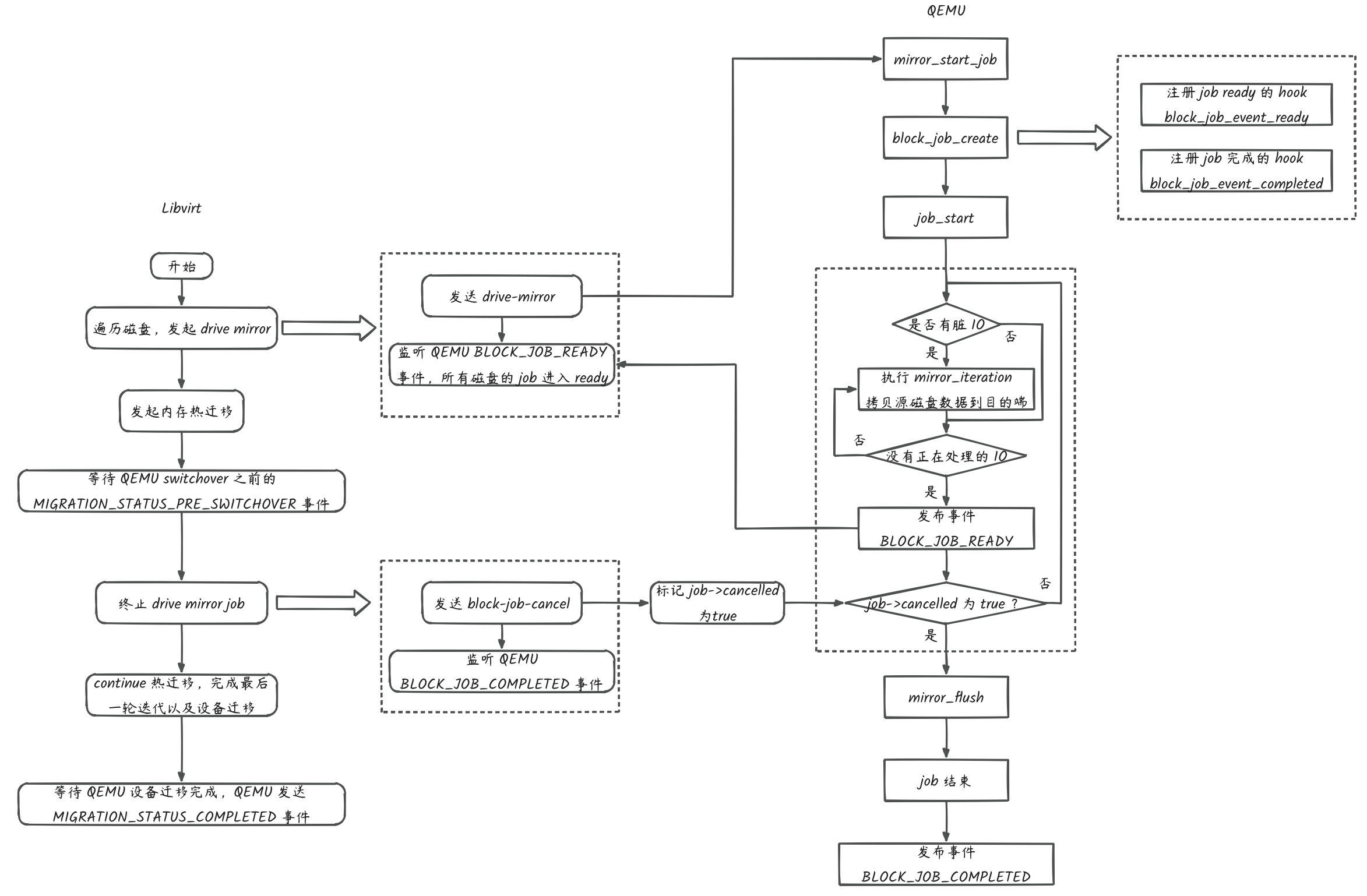
步骤如下:
- Libvirt 解析热迁移 API 的 flags 参数携带有 VIR_MIGRATE_NON_SHARED_DISK,首先通过 drive-mirror qmp 命令发起存储热迁移。
- QEMU 收到 drive-mirror 命令,内部按照 block job 的规程实现源端磁盘数据拷贝到目的端的工作。直到源端磁盘没有脏数据且 in flght IO 也没有,QEMU 发布一个 BLOCK_JOB_READY 事件,表示自己已经完成磁盘的数据迁移动作,随时可以接受终止命令。 在此之前,QEMU 会将源端磁盘的增量 IO 同步到目的端。
- Libvirt 在发起存储热迁移后等待 QEMU 的 BLOCK_JOB_READY 事件,收到该事件后发起内存热迁移。可以看到,内存热迁移是在 block job 处于 ready 状态后发起的。之后 Libvirt 监听 switchover 事件等待热迁移完成。
- QEMU 收到 migrate 命令后,发起内存热迁移。热迁移满足进入最后一轮条件后,发布 migration pre-switchover 事件。
- Libvirt 收到 switchover 事件后,首先是发送 bllock-job-cancel 命令终止 drive-mirror 的 block job,等待 QEMU 的 BLOCK_JOB_COMPLETED 事件。
- QEMU 收到 bllock-job-cancel 命令后,将新产生的增量 IO 和 in flight IO 同步到目的磁盘,发布终止 BLOCK_JOB_COMPLETED 标志 drive-mirror 完成。
- Libvirt 收到 BLOCK_JOB_COMPLETED 事件后,发送 migrate-continue 命令通知 QEMU 进行 switchover。等待 QEMU 发布 migration completed 事件。
- QEMU 收到 migrate-continue 命令,发起热迁移 switchover,完成后发布迁移完成事件。
- Libvirt 收到完成事件,迁移结束。
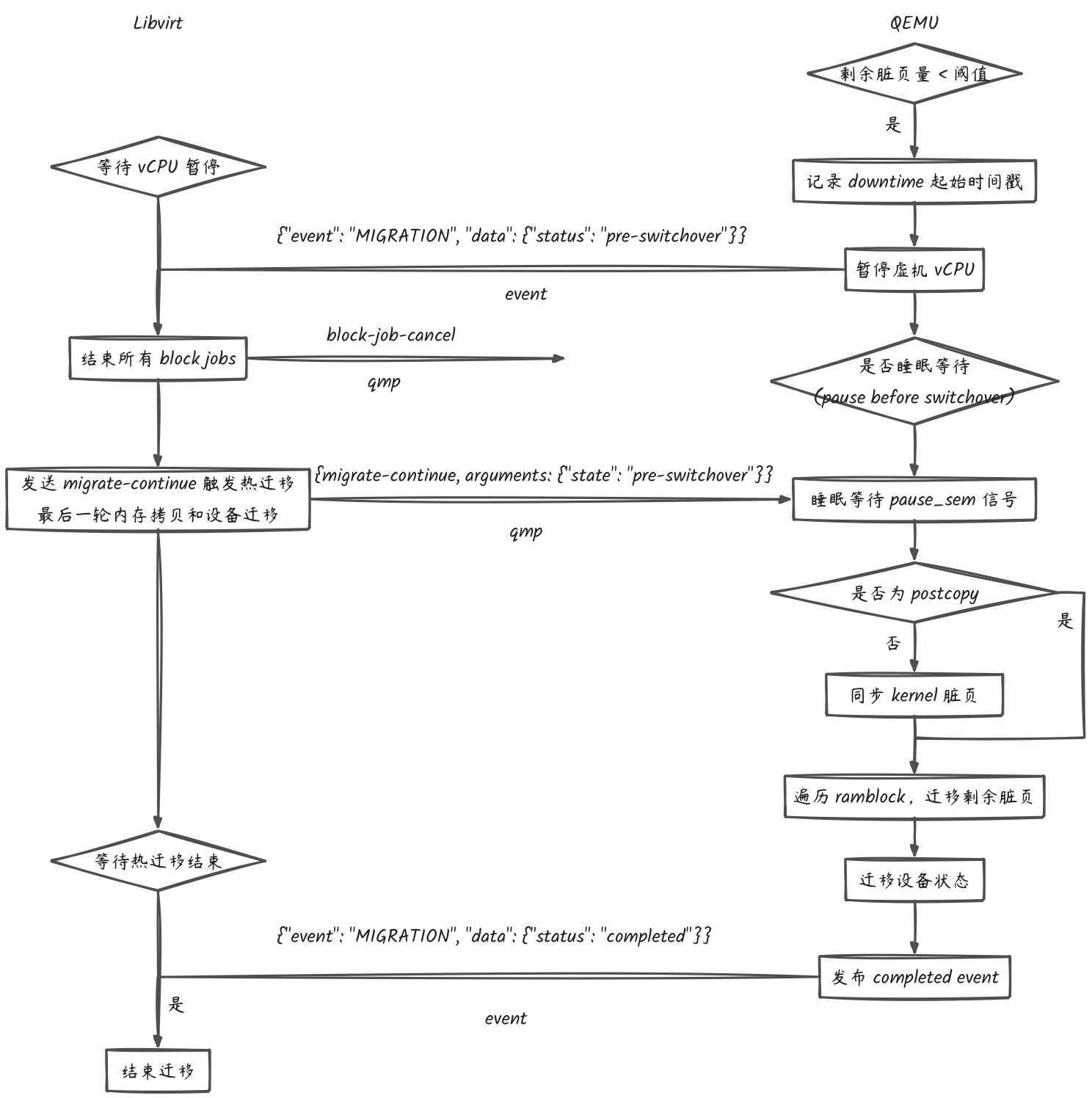
热迁移的 switchover 的简要逻辑参考下图:
代码路径
- Libvirt 关键路径与逻辑
client:
cmdMigrateif (vshCommandOptBool(cmd, "copy-storage-all"))flags |= VIR_MIGRATE_NON_SHARED_DISK;virDomainMigrateToURI3virDomainMigrateUnmanagedParams -> virDomainMigrateUnmanagedProto3
rpc:
qemuDomainMigratePerform3qemuMigrationSrcPerformqemuMigrationSrcPerformPhaseqemuMigrationSrcPerformNativeqemuMigrationSrcRun
关键函数:
qemuMigrationSrcRunif (flags & VIR_MIGRATE_NON_SHARED_DISK) {migrate_flags |= QEMU_MONITOR_MIGRATE_NON_SHARED_DISK;cookieFlags |= QEMU_MIGRATION_COOKIE_NBD;}if (migrate_flags & (QEMU_MONITOR_MIGRATE_NON_SHARED_DISK |QEMU_MONITOR_MIGRATE_NON_SHARED_INC)) {/* 调用 drive-mirror 发起存储热迁移,等待 QEMU BLOCK_JOB_READY 事件 */qemuMigrationSrcNBDStorageCopy...}/* 调用 migrate 发起内存热迁移 */qemuMonitorMigrateToFd/* 等待 QEMU migrate pre-switchover 事件 */qemuMigrationSrcWaitForCompletion/* 内存热迁移进入 switchover 前夕,终止存储热迁移 */if (mig->nbd) {qemuMigrationSrcNBDCopyCancel}/* 调用 migrate-continue 触发热迁移 switchover */qemuMigrationSrcContinue/* 等待 QEMU migrate completed 事件 */qemuMigrationSrcWaitForCompletion
- QEMU 关键路径与逻辑
qmp_drive_mirrorbs = qmp_get_root_bsaio_context = bdrv_get_aio_context(bs)target_bs = bdrv_openbdrv_try_change_aio_context(target_bs, aio_context, NULL, errp)blockdev_mirror_commonmirror_start/* 传入 mirror_job_driver,发起 mirror job */mirror_start_job
job 创建关键函数:
mirror_start_job/* 实例化 mirror filter driver,生成一个 BlockDriverState */mirror_top_bs = bdrv_new_open_driver(&bdrv_mirror_top, filter_node_name,BDRV_O_RDWR, errp)/* 清空源端磁盘上处于队列中的待落盘 IO,等待其结束 */bdrv_drained_begin(bs)/* 将 mirror filter 加到源磁盘的 root bs 之上,接管源磁盘的 IO 回调处理 */ret = bdrv_append(mirror_top_bs, bs, errp)/* 允许源端磁盘上有 IO 排队 */bdrv_drained_end(bs)/* 创建一个 job 并建立一个基于 job block 树:/* 将 mirror filter 作为树的第一个叶子节点,命名为 "main node" */block_job_create/* block job 已跟踪 mirror filter,解引用 */bdrv_unref(mirror_top_bs)/* 新建一个目的端磁盘的 BlockBackend */s->target = blk_new/* 将新建的 BlockBackend 的 root bs 指向目的磁盘 bs */blk_insert_bs(s->target, target, errp)/* 在 job block 树上添加第二个叶子节点,命令为 "source" */ret = block_job_add_bdrv(&s->common, "source", bs, 0,BLK_PERM_WRITE_UNCHANGED | BLK_PERM_WRITE |BLK_PERM_CONSISTENT_READ,errp)/* 在 job block 树上添加第二个叶子节点,命令为 "target" */block_job_add_bdrv(&s->common, "target", target, 0, BLK_PERM_ALL,&error_abort)/* 调用 job 的 run 方法: mirror_run */job_startQEMU Block layer
架构简述
- Block layer 层次
Block layer 介于响应 Guest IO 的 block device 之下、主机存储介质之上的一层 QEMU 组件,它负责处理 Guest IO 并最终将 IO 数据按照预期存储到主机存储介质上。如下图所示:
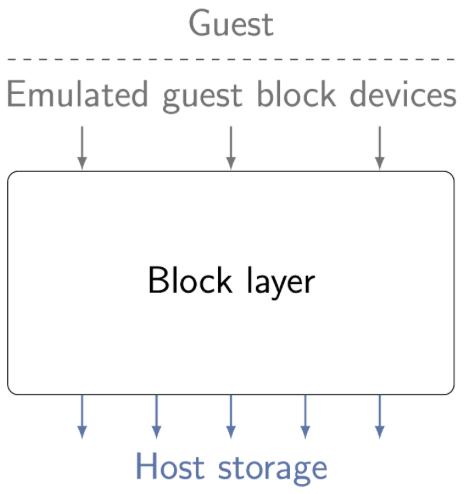
直接将 Guest IO 透传到主机存储介质不行吗?QEMU 为什么要引入 Block layer 软件层增加处理逻辑?
前者的答案是可以;后者的答案是在保证修改影响最小的前提下引入对高级存储特性的支持,比如磁盘级别的限速、加密、镜像、备份等。 存储的特性在 Block layer 内部提供的基础软件框架上实现并对外(Guest、host) 保持行为不变。 - Block layer 功能
基于 Block layer 的层次分析,我们可以推断 Block layer 需要具备以下基本功能:
- 接收 Guest IO 数据流
- 定义 Guest IO 数据流在 Block layerr 的行为
- 将 Guest IO 数据流写入主机存储介质或从中读出
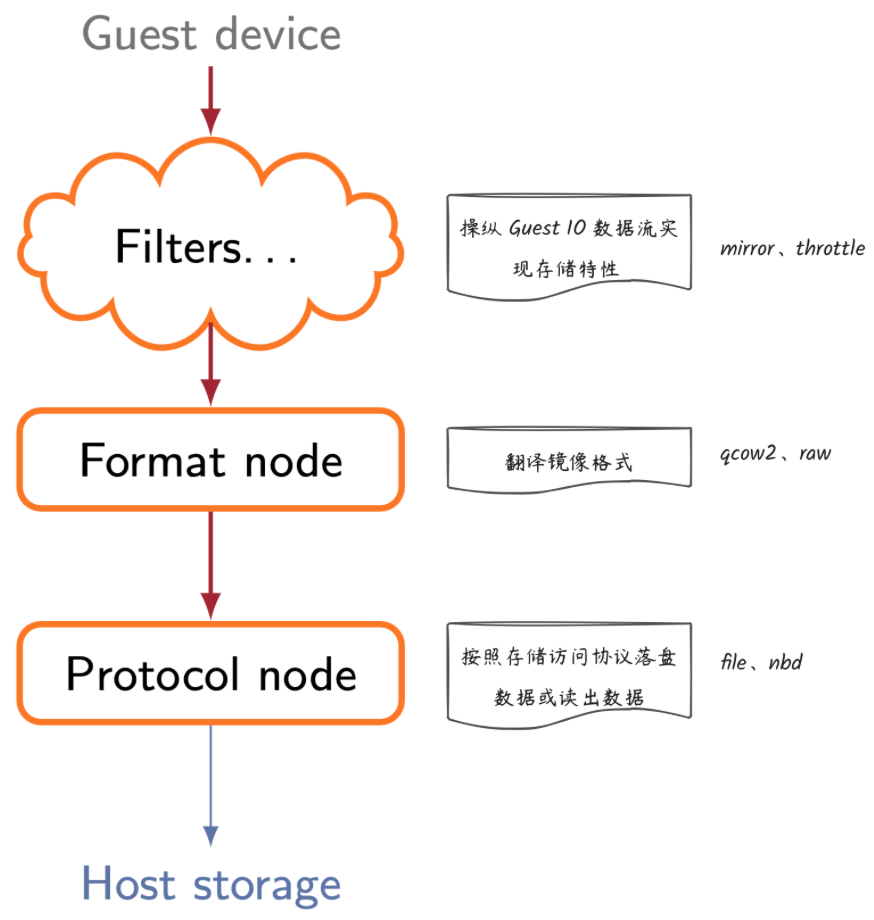
基于当前 QEMU 的 Block layer 实现以及上面的推断,Block layer 的具体功能包括: - 操纵 Guest IO 数据流实现存储特性,比如:加密、限速和备份等
- 翻译镜像格式,即按照约定的镜像格式将 IO 数据与 metadata 数据写入主机存储介质或从中读出,这里的镜像格式包括 qcow2、raw 等。
- 将 Block layer 层加工后的 IO 数据按照访问协议写入主机存储介质或从中读出,这里的协议包括 nbd、iscsi、file 等。
- Block layer tree
基于对 Block layer 层的功能分析,QEMU 将 Blocker layer 软件基础框架抽象为树,其中树的根离 Guest 最近,树的叶子节点离 Host 最近,每个层次中节点角色不同,实现的功能也不同,如下:
Block Job
结构体设计
QEMU 设计了 Job 结构体,job 生命周期各阶段通过状态来描述, job 有如下状态,参考官方文档:
- undefined – Erroneous, default state. Should not ever be visible.
- created – The job has been created, but not yet started.
- running – The job is currently running.
- paused – The job is running, but paused. The pause may be requested by either the QMP user or by internal processes.
- ready – The job is running, but is ready for the user to signal completion. This is used for long-running jobs like mirror that are designed to run indefinitely.
- standby – The job is ready, but paused. This is nearly identical to paused. The job may return to ready or otherwise be canceled.
- waiting – The job is waiting for other jobs in the transaction to converge to the waiting state. This status will likely not be visible for the last job in a transaction.
- pending – The job has finished its work, but has finalization steps that it needs to make prior to completing. These changes will require manual intervention via job-finalize if auto-finalize was set to false. These pending changes may still fail.
- aborting – The job is in the process of being aborted, and will finish with an error. The job will afterwards report that it is concluded. This status may not be visible to the management process.
- concluded – The job has finished all work. If auto-dismiss was set to false, the job will remain in this state until it is dismissed via job-dismiss.
- null – The job is in the process of being dismantled. This state should not ever be visible externally.
- QEMU 设计了 JobDriver 结构体,Job 通过执行 JobDriver 中的方法将 Job 从一个状态驱动到另一个状态。
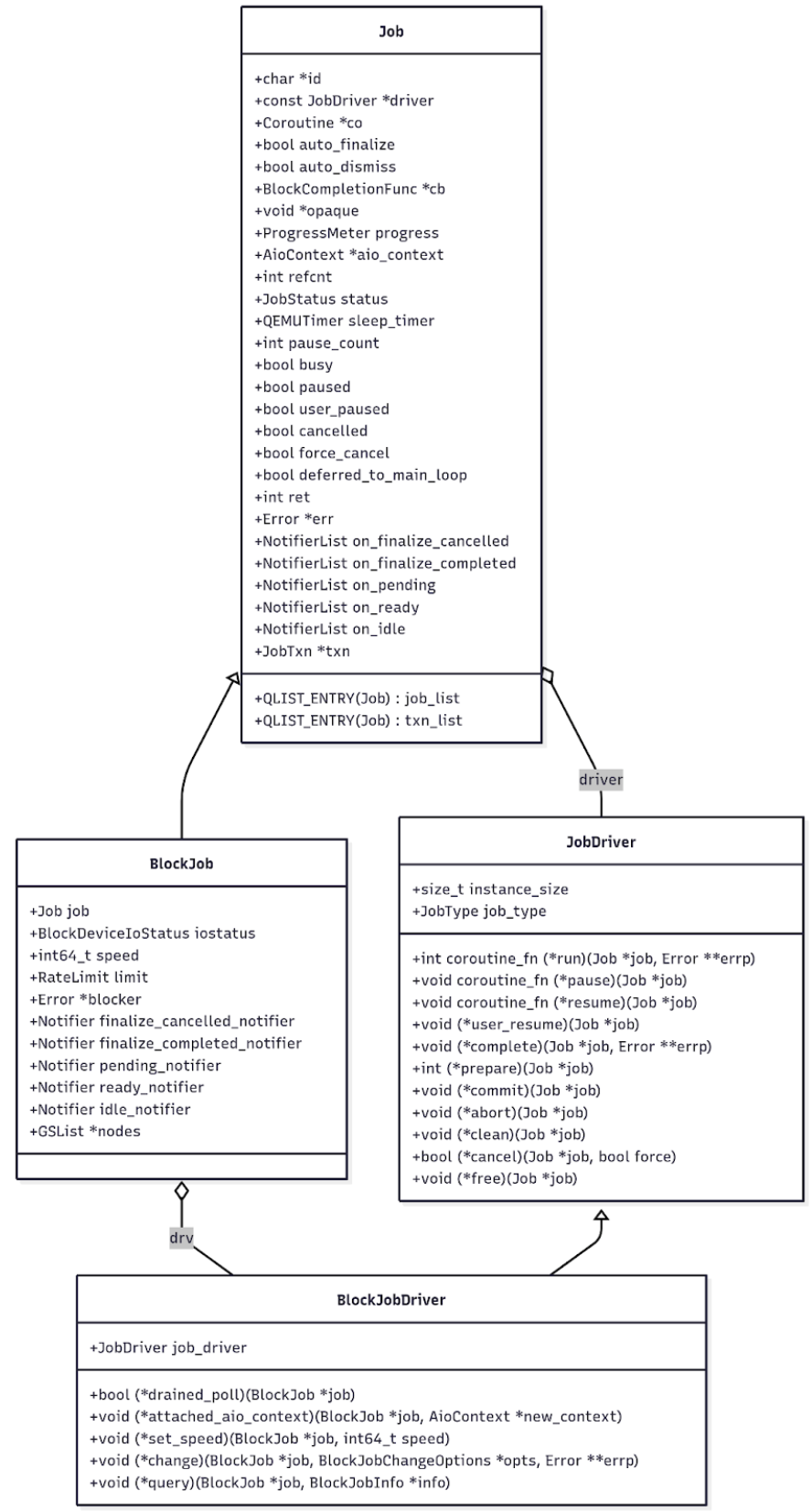
- BlockJob 继承 Job 结构体,BlockJobDriver 继承 JobDriver,用于实现块设备的 Job。QEMU BlockJob 和 BlockJobDriver 结构体为基础,实现了块设备的高级特性,比如 mirror、duplicate 等。
- Job、JobDriver、BlockJob、BlockJobDriver 4 个结构体的定义和关系如下:
状态转换
- Job 的通用状态转换如下图,其中 event 表示 QEMU 内部的状态转换:
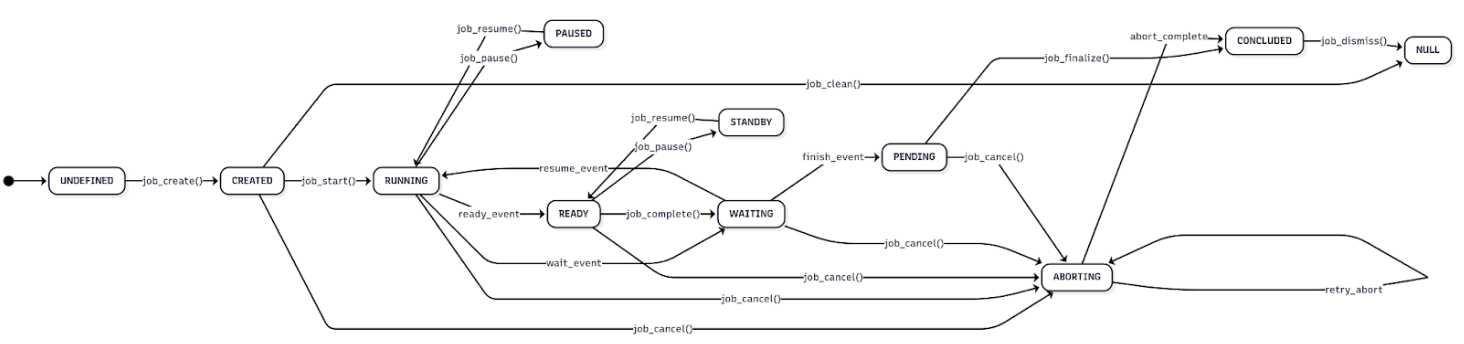
有几个点需要特别解释:
- READY 状态对于 drive-mirror 来说是一种完成的状态,drive-mirror job 进入 READY 状态时会发送同时发送 BLOCK_JOB_READY 事件。READY 状态的 drive-mirror job 可以随时可以接收 block-job-cancel 命令,这里的 block-job-cancel 命令并非字面意义上的取消任务,而是结束。QEMU 会在 block-job-cancel 命令的处理逻辑中发布 BLOCK_JOB_COMPLETED 事件,表示 drive-mirror job 结束。
- job-pause 停止任务时,处于 RUNNING 状态的任务会变为 PAUSED;处于 READY 状态的任务会变成 STANDBY。
- job-finalize 的作用是让处于工作完成(PENDING)状态的 job 通过用户命令进入 QEMU 定义上的任务完成,设计这样一个接口可以方便上层应用在 QEMU job 进入完成状态之前可以执行一些准备命令。如果应用没有需要,可以在发起 block job 时设置 auto-finalize 为 true 让 QEMU 跳过等待用户下发 job-finalize 的步骤,直接进入 QEMU 定义的完成状态(CONCLUDED)。
- job-dismiss 的作用是清理 QEMU 内部维护的 Job 数据结构,没有其它实质动作,job-dismiss 下发后 job 将不再能够通过 qmp block-job-query 查询到。
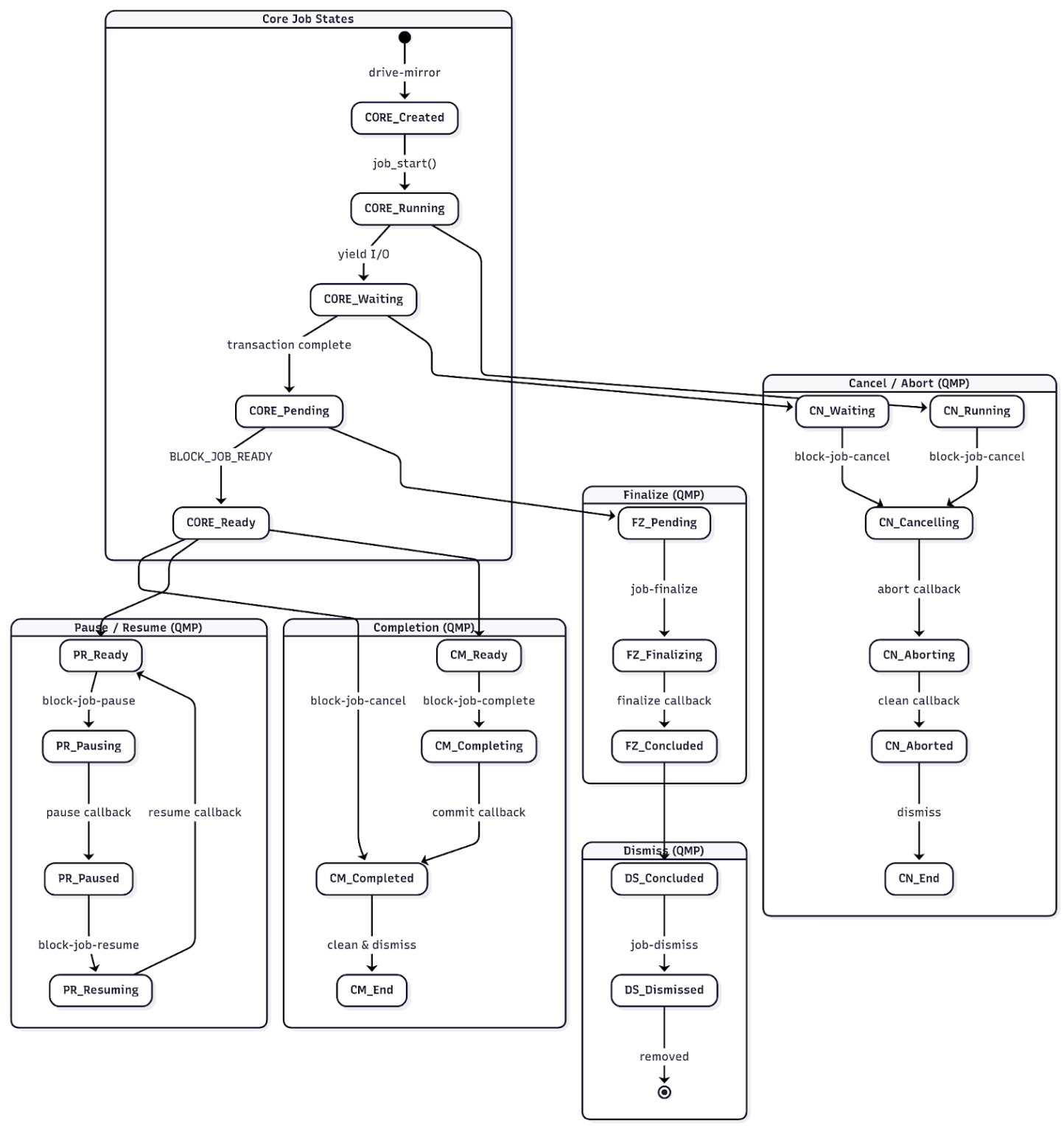
- Block job 状态转换如下图所示,以 drive-mirror 功能为例:
Mirror block job
拓扑结构
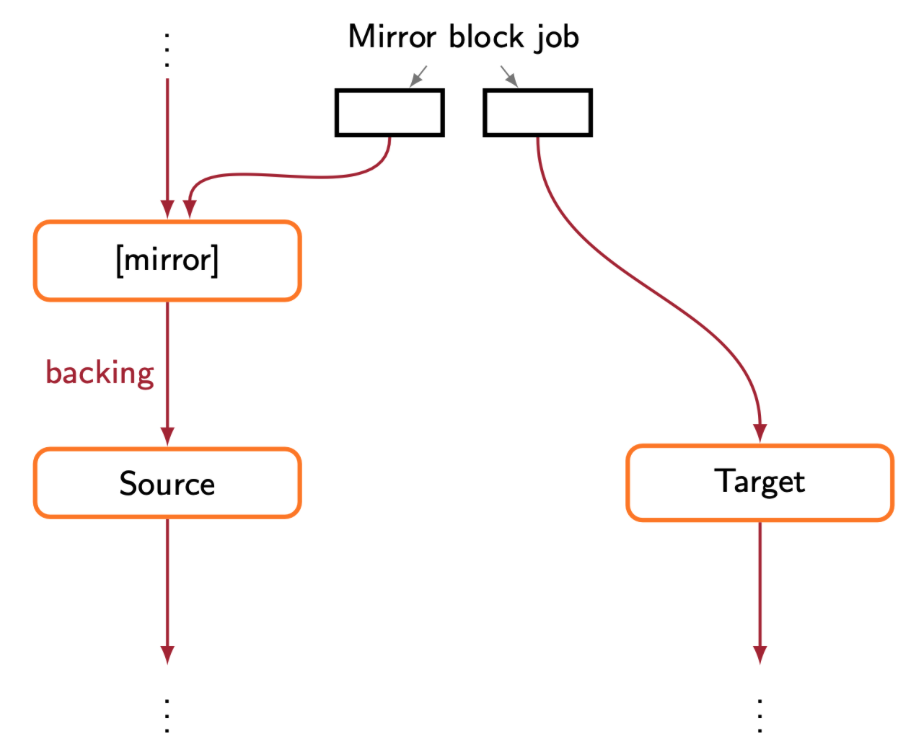
处于 mirror 状态的 Block layer tree 拓扑如上:
- MirrorBlockJOb 结构体继承自 BlockJob
- MirrorBlockJOb 包含源、目的两端的 BlockBackend
- 目的端 BlockBackend 通过 MirrorBlockJOb 结构体的 target 的跟踪
- 源端 BlockBackend 通过 mirror node 间接引用 —— mirror node 作为 filter node 被插入到源端 BlockBackend 和 root bs 之间,代替 root bs 作为源端 BlockBackend 的子节点,Mirror node 子节点指向先前的 root bs
构建过程
drive-mirror 实现中涉及到的 mirror block layer tree 的构建逻辑分四个步骤,如下:
- 初始阶段,打开源端和目的端磁盘的 bs (BlockDriverState)
- 根据参数中源磁盘的 node-name 打开源磁盘
BlockDriverState *bs = qmp_get_root_bs(arg->device, errp)
- 获取包含源磁盘 bs 的 IO 回调上下文
AioContext *aio_context = bdrv_get_aio_context(bs)
- 根据参数中目标磁盘的 node-name 打开目标磁盘
target_bs = bdrv_open(arg->target, NULL, options, flags, errp)
- 将源磁盘的 IO 回调设置到目标磁盘上
bdrv_try_change_aio_context(target_bs, aio_context, NULL, errp)
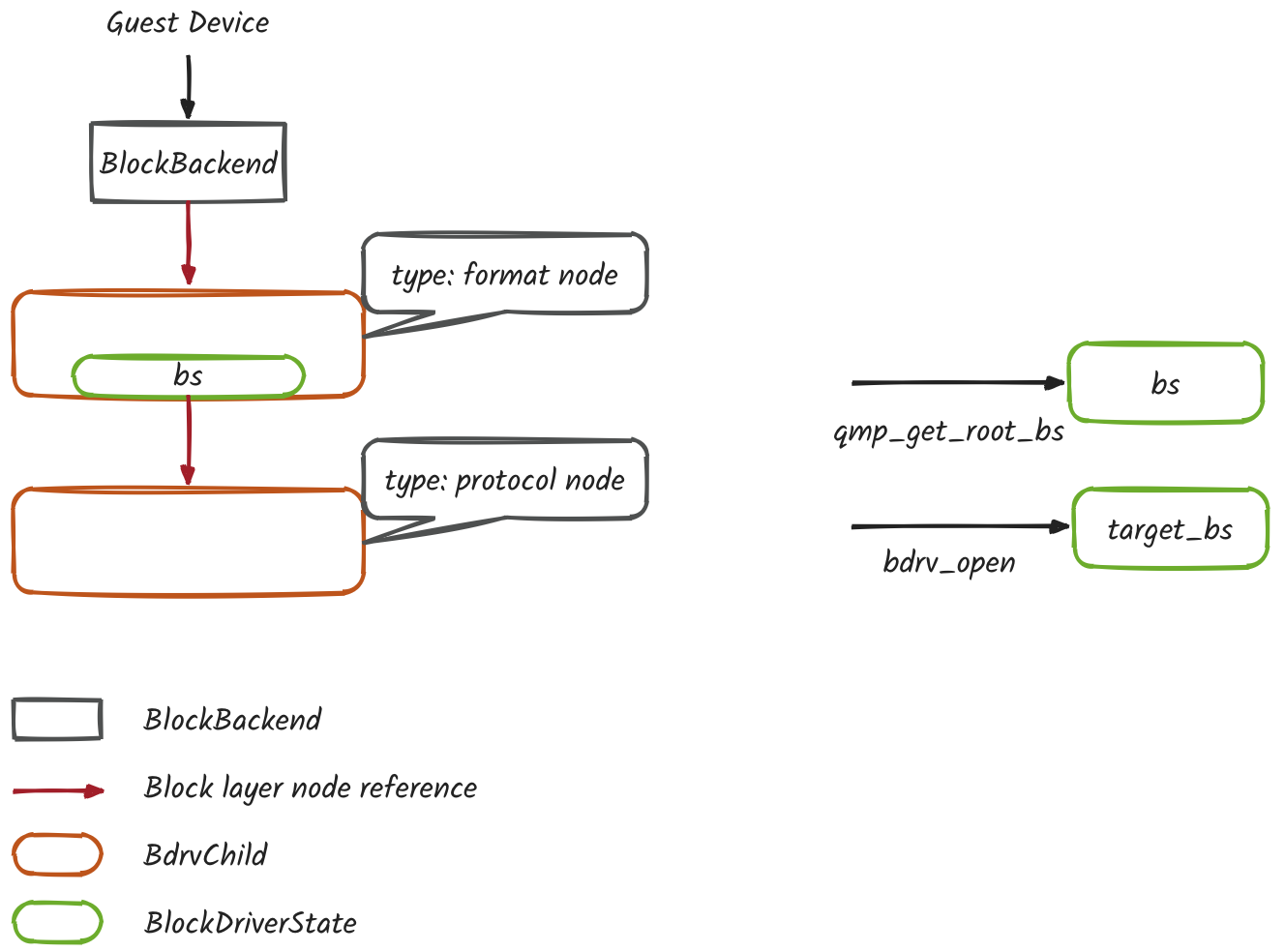
- 插入 mirror filter node 到源磁盘的 block layer tree
- 打开一个基于 bdrv_mirror_top BlockDriver 驱动的 bs
BlockDriverState *mirror_top_bs = bdrv_new_open_driver(&bdrv_mirror_top, filter_node_name,BDRV_O_RDWR, errp)
- 将 mirror filter node 插入到源磁盘 BlockBackend 与 bs 之间,取代 bs 作为 BlockBackend 的子节点
bdrv_append(mirror_top_bs, bs, errp)
- 创建 BlockJob
MirrorBlockJob *s = block_job_create(job_id, driver, NULL, mirror_top_bs,BLK_PERM_CONSISTENT_READ,BLK_PERM_CONSISTENT_READ | BLK_PERM_WRITE_UNCHANGED |BLK_PERM_WRITE, speed,creation_flags, cb, opaque, errp)
- BlockJob 维护了 mirror filter node,因此删除 qmp_drive_mirror 函数的引用
bdrv_unref(mirror_top_bs)
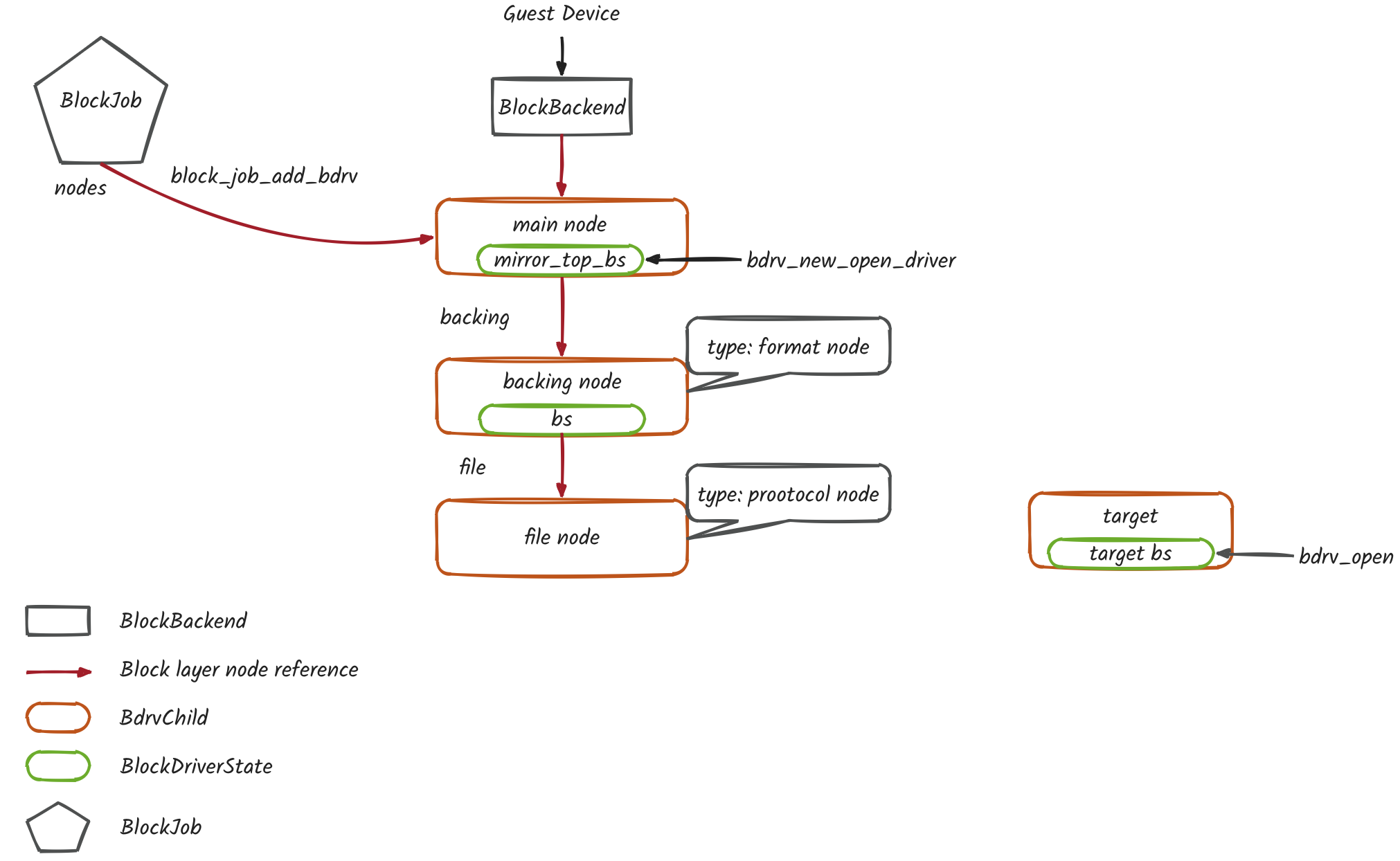
- 创建目标磁盘的 BlockBackend
- 基于源端磁盘的 IO 上下文新建一个 BlockBackend
s->target = blk_new(s->common.job.aio_context, target_perms, target_shared_perms)
- 将新建的 BlockBackend 指向目标磁盘
blk_insert_bs(s->target, target, errp)
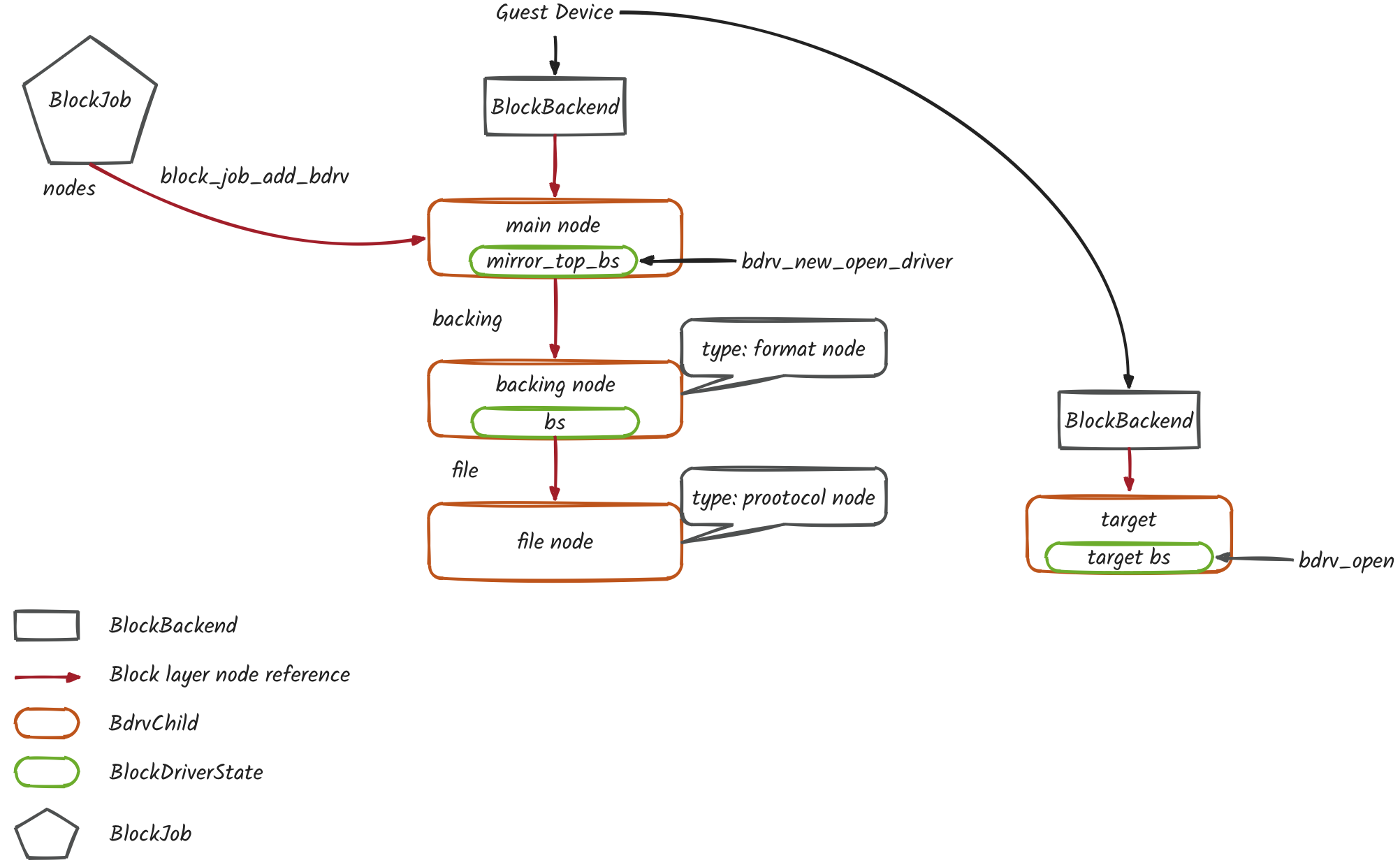
- BlockJob 管理源端磁盘和目标端磁盘
- 将源端磁盘添加到 BlockJob 维护的 tree
block_job_add_bdrv(&s->common, "source", bs, 0,BLK_PERM_WRITE_UNCHANGED | BLK_PERM_WRITE |BLK_PERM_CONSISTENT_READ,errp)
- 将目标端磁盘添加到 BlockJob 维护的 tree
block_job_add_bdrv(&s->common, "target", target, 0, BLK_PERM_ALL, &error_abort)
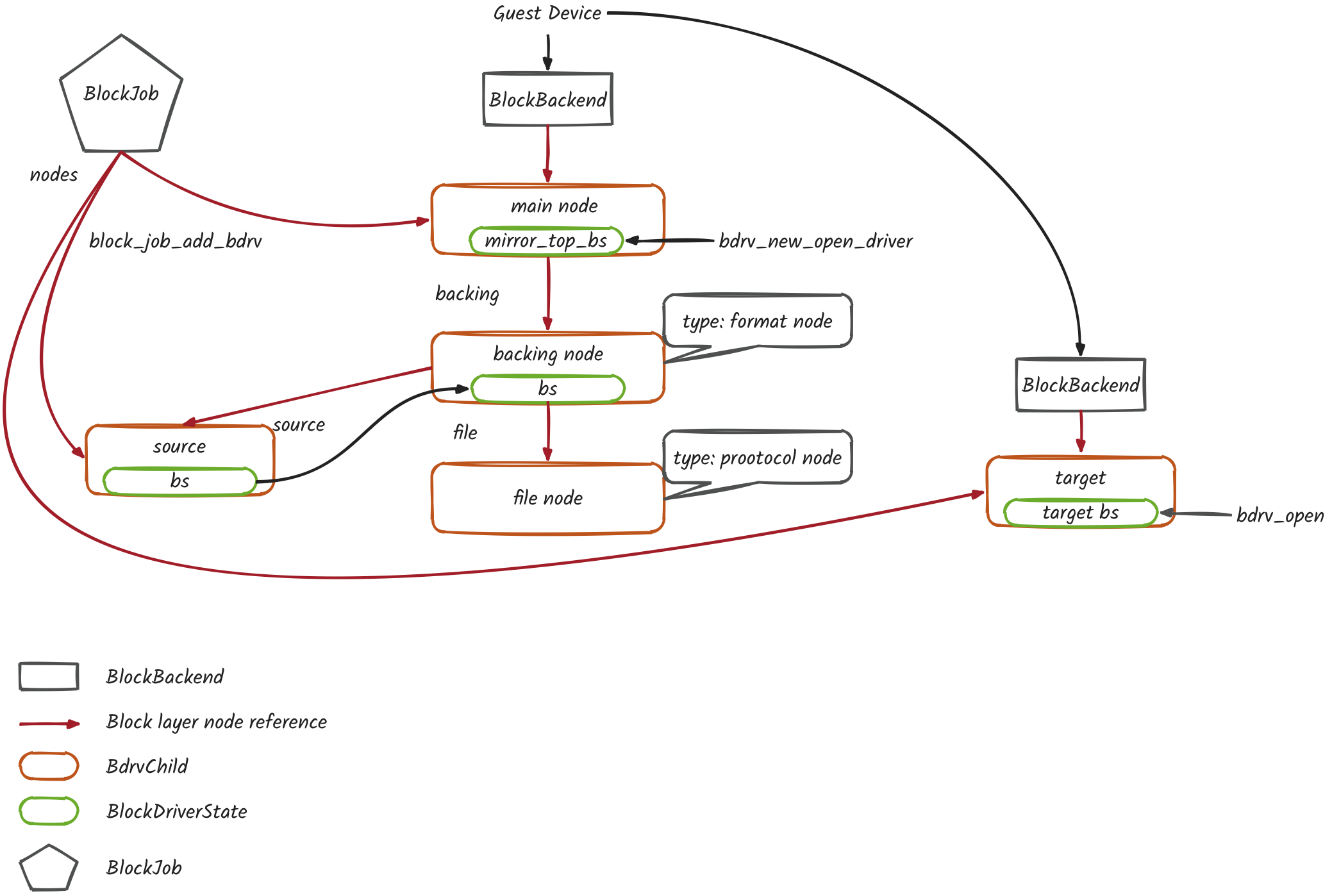
数据结构
我们通过分析一个正在 drive-mirror 虚机的 QEMU 进程 core 文件进一步了解 Block layer 相关数据结构。
-
查询当前虚机正在运行的所有 Job

-
查询第一个 BlockJob 维护所有的 BdrvChild 节点
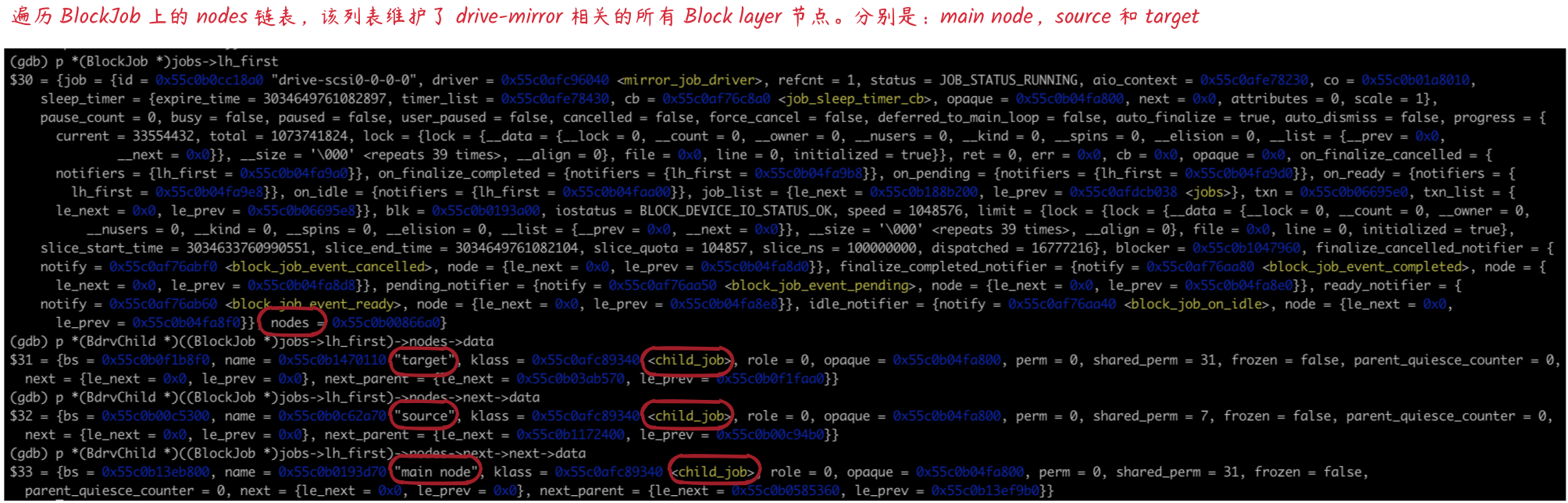
-
在源磁盘 Block layer 中查询 mirror filter node 的叶子节点
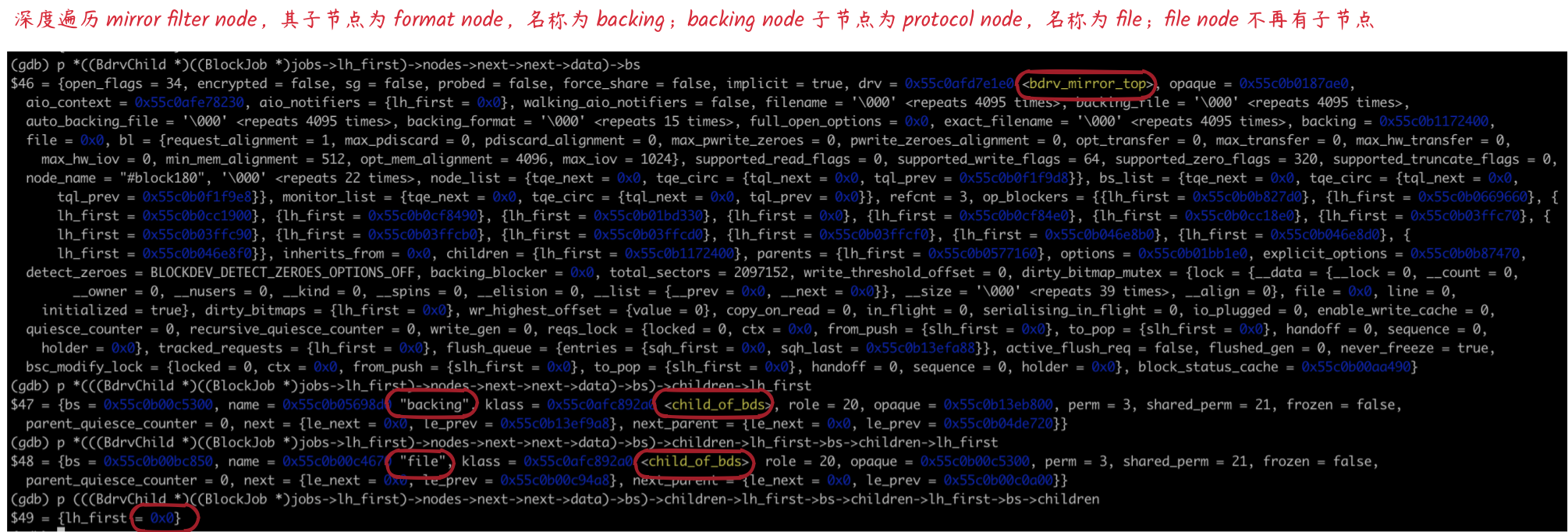
可以看到,mirror filter node 下一级 node 属性为 child_of_bds,而 BlockJob 维护的的 node 属性为 child_job,BdrvChild klass 的不同决定了做添加和删除节点操作时调用的回调函数(attach、detach、drain)不同
- 查看源端磁盘完整的 Block layer node
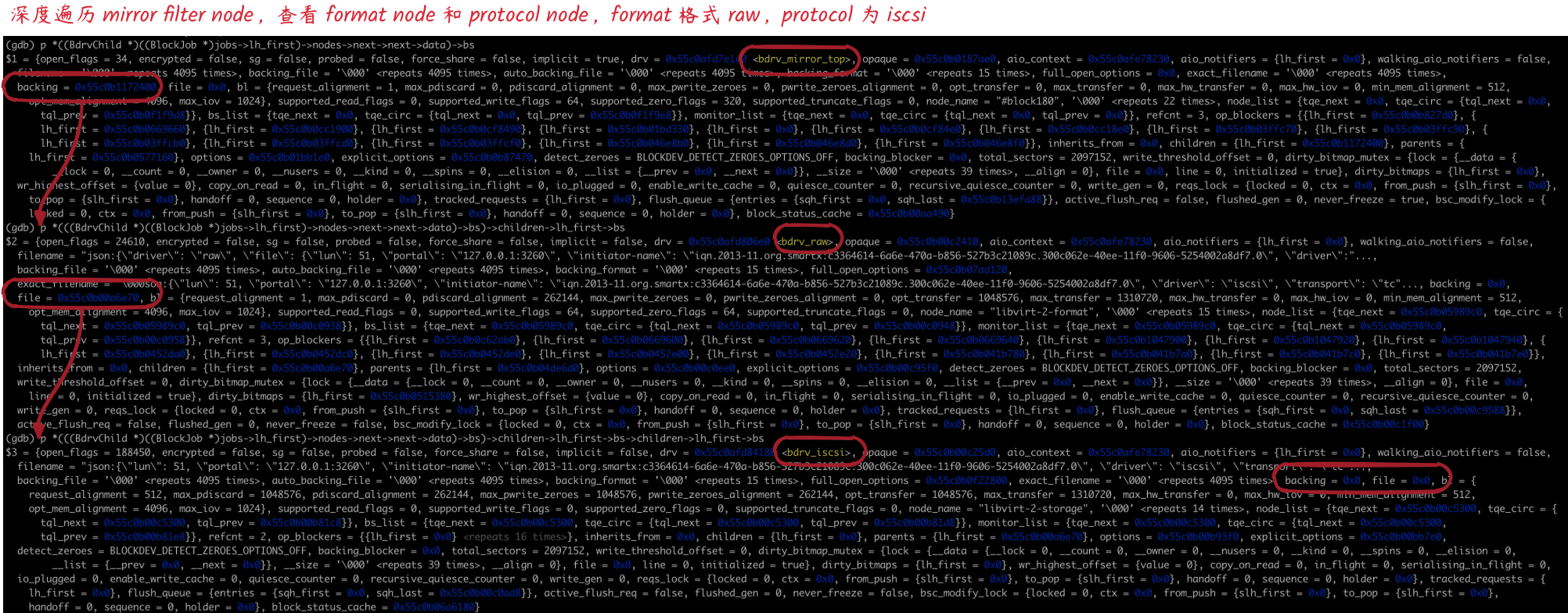
可以看到 mirror node 的 backing 指向了 format node,format node 的 file 指向了 protocol node
模式或事务(Transaction)模式)宏命令)




)

)











)