DETR见解
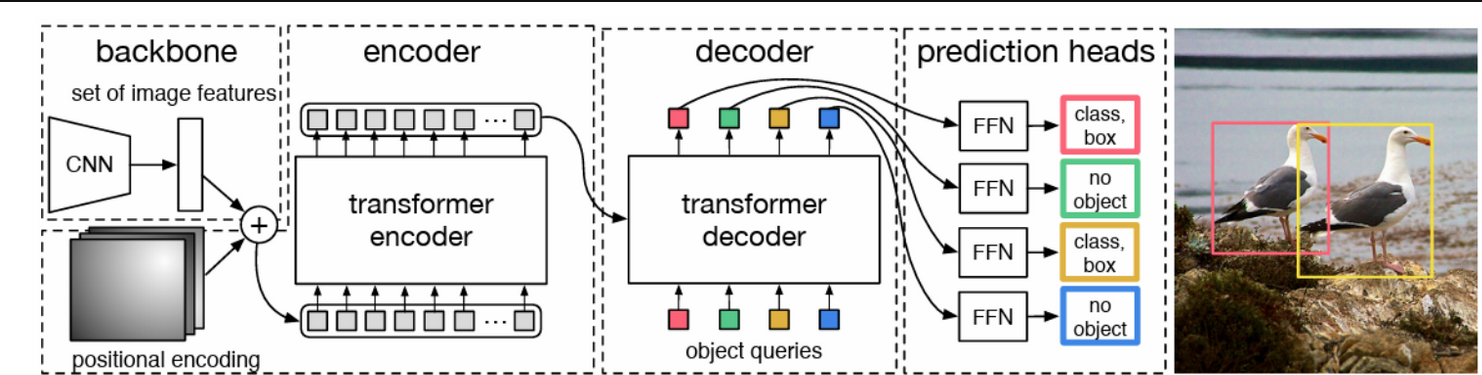
DETR(Detection Transformer)是一种端到端的目标检测模型,由Facebook AI Research(FAIR)于2020年提出。DETR采用了Transformer架构,与传统的基于区域的目标检测方法有所不同,它通过全局上下文来预测图像中的目标,而无需使用先前的候选框或区域建议网络。整个DETR可以分为四个部分,分别是:backbone、encoder、decoder以及predictionheads。基本思想是,首先用cnn抽取图像特征,拿到每一个patch对应的向量,并加上位置编码。然后用transformer encoder学习全局特征,帮助后面做检测。接着将encoder的输出作为tranformer deoder的输入,同时还输入了一个对象查询。对象查询按我的理解就是,它生成一个查询分量q和前面encoder传进来的k和v做一个交互,生成很多预测框。然后把预测框和真实框做匹配,询问框内是否包含目标,然后在匹配上的这些框里面计算loss,进而向后传播。接着就是预测头的建立,最后生成预测结果。所以整个DETR网络的工作就是:特征提取--特征加强--特征查询--预测结果
 建议使用云服务器进行操作(如果本机没有GPU或者显存资源不充足情况下)
建议使用云服务器进行操作(如果本机没有GPU或者显存资源不充足情况下)
一、代码拉取
官方:GitHub直接搜索即可
改进版:代码私信发送(资源免费)(主要原因就是资源绑定不成功 :( 哭泣哭泣 )
论文:文章顶部下载
二、环境准备
解压代码,进入主目录
安装对应包
pip install -r requirements.txt三、数据集准备
数据集下载
数据集建议准备VOC格式或者是COCO格式。(GitHub上官方使用数据集格式为coco格式)
其实不论是yolo格式或者是VOC格式,他们之间都可以通过代码去转换。
建议在训练前,随机抽取几张图片和标签,查看标注是否准确无误。
推荐数据集:CCTSDB_VOC_数据集-飞桨AI Studio星河社区
推荐数据集:水果分类目标检测VOC数据集_数据集-飞桨AI Studio星河社区
数据集加载
导入数据集之后,查看数据集是否包括:JPG和XML,以及train.txt、val.txt、test.txt
使用运行test.py生成一个存在于主目录下的train.txt和test.txt。这样我们就设置完成训练集和测试集的加载路径了。
四、模型训练
参数修改
打开detr.py,和train.py
里面有相关参数,我们可以进行设置,其中包括冻结训练层数以及解冻层数,这个是比较重要的。
detr.py参数:

train.py参数修改
其中预训练权重文件可以选择resnet50或者是resnet101,可自行修改



五、训练结果可视化
运行get_map.py生成loss、Map、recall等(如果不懂可以具体了解一下模型评估的几个参数)
5.1模型评估参数介绍
- 1. 精确率(Precision)
- 定义:在所有被模型预测为正类(即存在目标)的样本中,实际为正类的比例。
- 公式:
- Precision=(True Positives (TP)+False Positives (FP)) / True Positives (TP)
- 解释:
- TP(True Positive):模型正确预测了目标的边界框和类别。
- FP(False Positive):模型错误地预测了目标的边界框或类别(例如,将背景误判为目标)。
- 意义:高精确率意味着模型在预测目标时较少出现误报。
- 2. 召回率(Recall)
- 定义:在所有实际为正类的样本中,被模型正确预测为正类的比例。
- 公式:
- Recall=True Positives (TP) / (True Positives (TP)+False Negatives (FN))
- 解释:
- FN(False Negative):模型未能检测到实际存在的目标。
- 意义:高召回率意味着模型能够检测到更多的真实目标,减少漏检。
- 3. 平均精度(Average Precision, AP)
- 定义:在不同置信度阈值下,精确率和召回率的综合表现,通常以AP@[IoU阈值]表示,如AP@0.5。
- 计算方法:
- 对每个类别,根据预测的置信度从高到低排序。
- 计算不同置信度阈值下的精确率和召回率。
- 绘制精确率-召回率曲线(Precision-Recall Curve)。
- 计算曲线下的面积(Area Under Curve, AUC),即AP。
- 意义:AP综合考量了模型在不同置信度下的精确率和召回率,是评估目标检测模型性能的重要指标。
- 4. 平均精度均值(Mean Average Precision, mAP)
- 定义:在多个类别上计算的平均AP值。
- 公式:
- mAP=N1∑i=1NAPi
- 其中,N 是类别的总数,APi 是第 i 个类别的AP值。
- 常见变体:
- mAP@[IoU阈值]:如mAP@0.5表示IoU阈值为0.5时的平均精度均值。
- mAP@[0.5:0.95]:在IoU阈值从0.5到0.95(步长为0.05)范围内计算的平均mAP,更全面地评估模型性能。
- 意义:mAP综合考虑了所有类别的性能,是目标检测任务中最常用的综合评估指标。
- 5. 交并比(Intersection over Union, IoU)
- 定义:预测边界框与真实边界框之间的重叠程度。
- 公式:
- IoU=Area of UnionArea of Overlap
- 解释:
- IoU值范围在0到1之间,值越大表示预测框与真实框的重叠程度越高。
- 常用IoU阈值(如0.5、0.75)来判断预测框是否正确。
- 意义:IoU用于评估单个预测框的准确性,是计算TP、FP和FN的基础。
- 6. 其他相关指标
- F1分数(F1-Score):精确率和召回率的调和平均数,用于平衡两者。
- F1=2×Precision+RecallPrecision×Recall
- 每秒帧数(Frames Per Second, FPS):模型推理速度,适用于实时检测任务。
- GFLOPs(Giga Floating Point Operations):模型的计算复杂度,影响推理速度和硬件需求。
- Instances 的含义
- 定义:
- Instances 指的是当前批次(Batch)中所有图像中真实存在的目标对象数量的总和。

六、模型调优
yolo相关参数介绍链接:(https://docs.ultralytics.com/zh/modes/train/#train-settings)
可以参考里面的参数介绍,来进行调优





数据库恢复技术)







)


和欧姆龙NJ PLC的高效数据交换)


