paper link: paperlink
Abstract: 这个数据集是个RGB-D视频数据集,在707个不同空间中获取了1513个扫描的场景,250w个视图,并且标注了相机位姿,表面重建,语义分割。本数据集共有20人扫描+500名工作者进行标注。
数据集获取框架
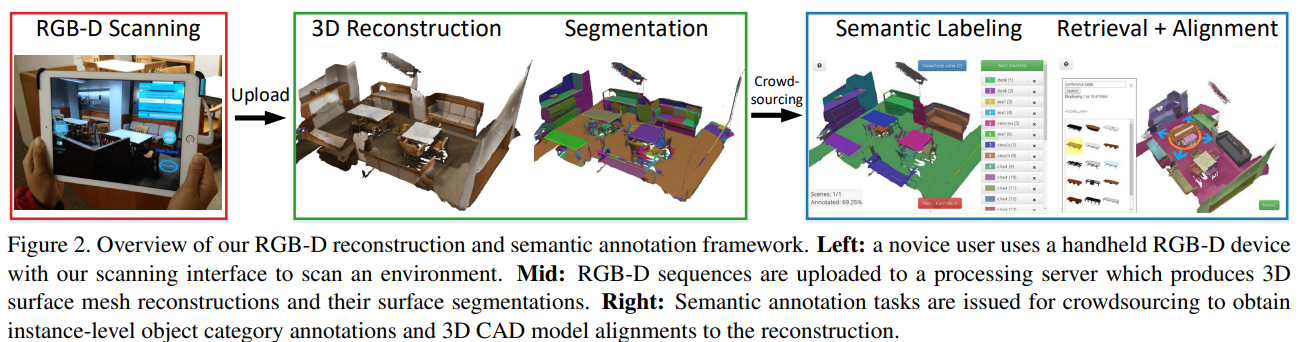
硬件设备: 使用Structure Sensor + ipad Air 2 进行收集,RGB 1296*968, Depth 640*480,默认启用白平衡+自动曝光。
相机校准:可以使用Srructure Sensor的Calibrate 软件进行校准。得到深度相机和彩色相机的关系。
用户界面:创建了ScannerApp进行数据集的采集,(但目前已经很久没更新了,sdk里有些类已经弃用了)
存储:128GB可以存储数小时的拍摄场景,用户可以随时点击“上传”按钮将扫描数据上传到处理服务器。
表面重建: BundleFusion 进行重建,1cm的 voxel resolution,VoxelHashing( 通过 VoxelHashing 实现体素融合 (Volumetric Integration)),marching cubes 在分辨率为4mm *4mm *4mm的voxel下进行高分辨率网格提取。对网格进行自动清理和简化(合并距离较近的顶点,删除重复的网格面和孤立的网格部分,对网格进行多分辨率的下采样,生成高中低分辨率的网格模型)
- 使用 BundleFusion 计算每帧扫描数据的位姿。
- 使用 VoxelHashing 构建 TSDF 表达的全局稠密体素网格。
- 使用 Marching Cubes 提取高分辨率的三角网格。
- 对网格进行清理、去噪和下采样,生成高、中、低分辨率的版本。
方向:自动将所有相机姿态对齐到一个共同的坐标系中,Z轴向上向量,xy平面和地面对齐。
验证:会自动丢弃较短、残差重建误差较大或对齐帧百分比较低的扫描序列。然后,也会手动检查并丢弃存在明显错位的重建。
准备复现一下,上述的效果,如果效果好,我再继续写
Semantic Annotation
总包。。待续


安全保障机制(技术、标准、管理))



(DAY 002))












![[网络入侵AI检测] 深度前馈神经网络(DNN)模型](http://pic.xiahunao.cn/[网络入侵AI检测] 深度前馈神经网络(DNN)模型)