背景意义
研究背景与意义
随着工业自动化和智能制造的迅速发展,工人安全问题日益受到重视。特别是在涉及重型机械和危险操作的工作环境中,工人手部的安全保护显得尤为重要。传统的安全手套虽然在一定程度上能够保护工人的手部,但在复杂的加工操作中,如何实时监测手部的状态和安全性,成为了一个亟待解决的技术难题。因此,开发一个基于先进计算机视觉技术的手部检测系统,不仅可以提高工人的安全性,还能提升生产效率。
本研究旨在基于改进的YOLOv11模型,构建一个高效的加工操作安全手套与手部检测系统。该系统将利用包含1500张图像的bandsaw_kolabira数据集进行训练和验证。数据集中包含了多种手套和手部的类别,包括蓝色手套、白色手套、钢制手套以及手部和头部的标注信息。这些多样化的类别为模型的训练提供了丰富的样本,有助于提高模型的准确性和鲁棒性。
在实际应用中,该系统将能够实时识别工人是否佩戴安全手套,并监测手部的活动状态,从而有效预防因操作不当导致的安全事故。此外,通过对手部状态的监测,系统还可以为工人提供实时反馈,帮助其调整操作姿势,降低受伤风险。通过将计算机视觉技术与工人安全管理相结合,本研究不仅为安全生产提供了技术支持,也为未来智能制造的发展提供了新的思路和方向。
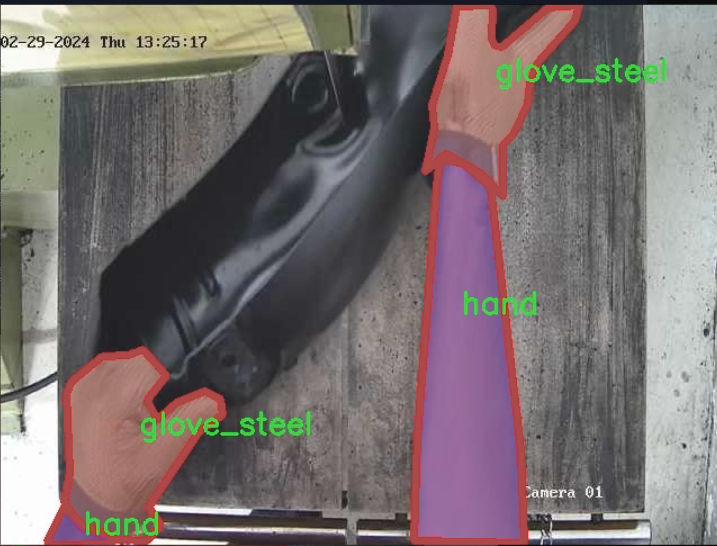
图片效果
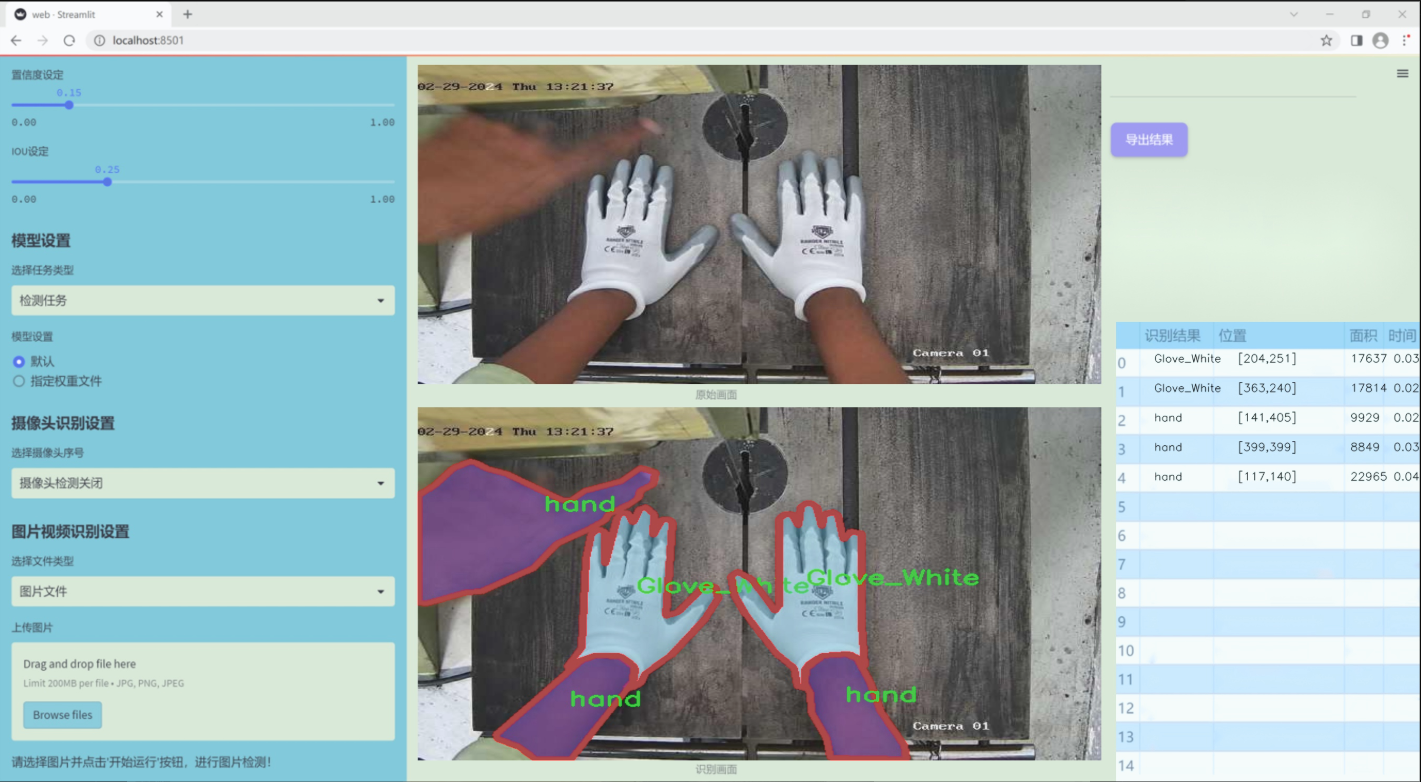
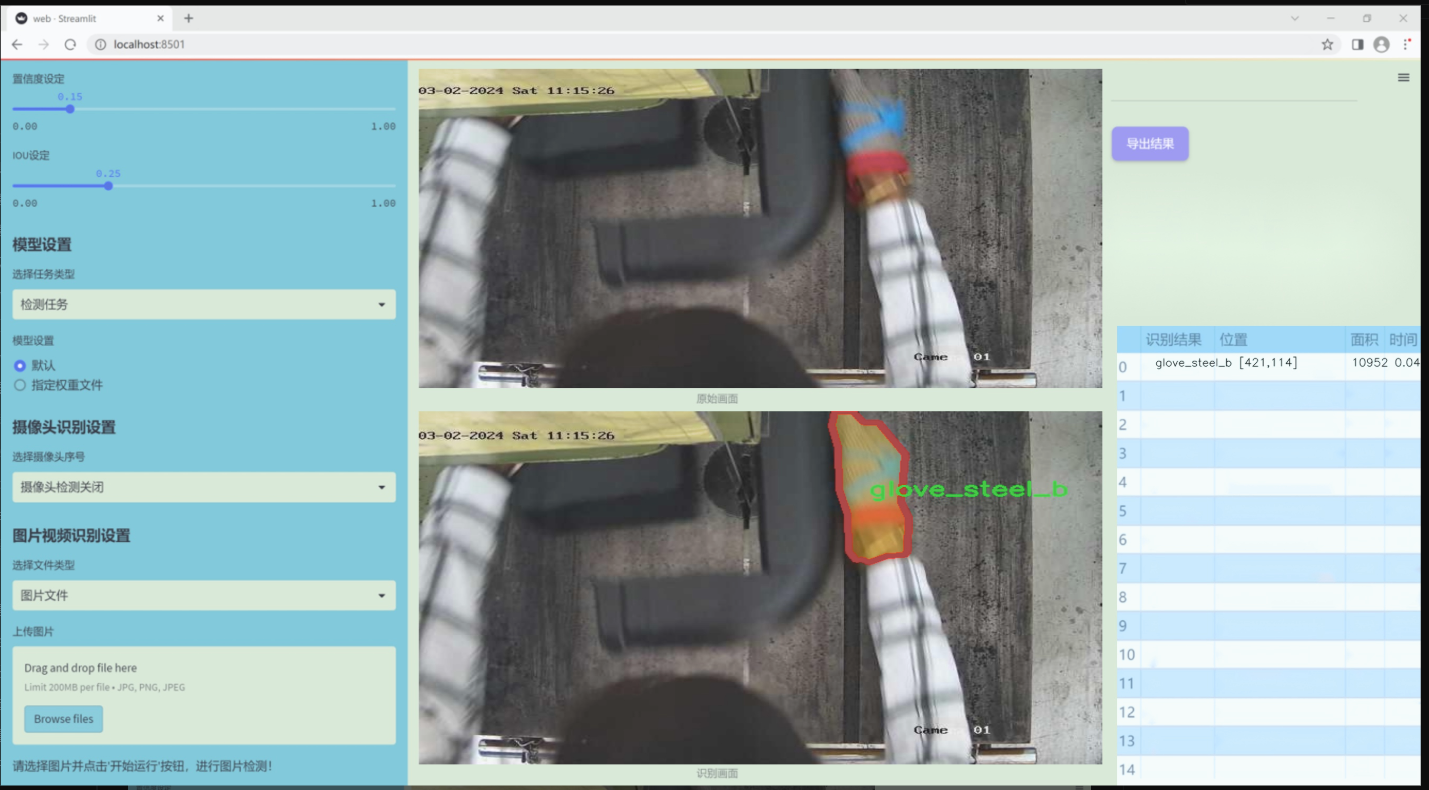
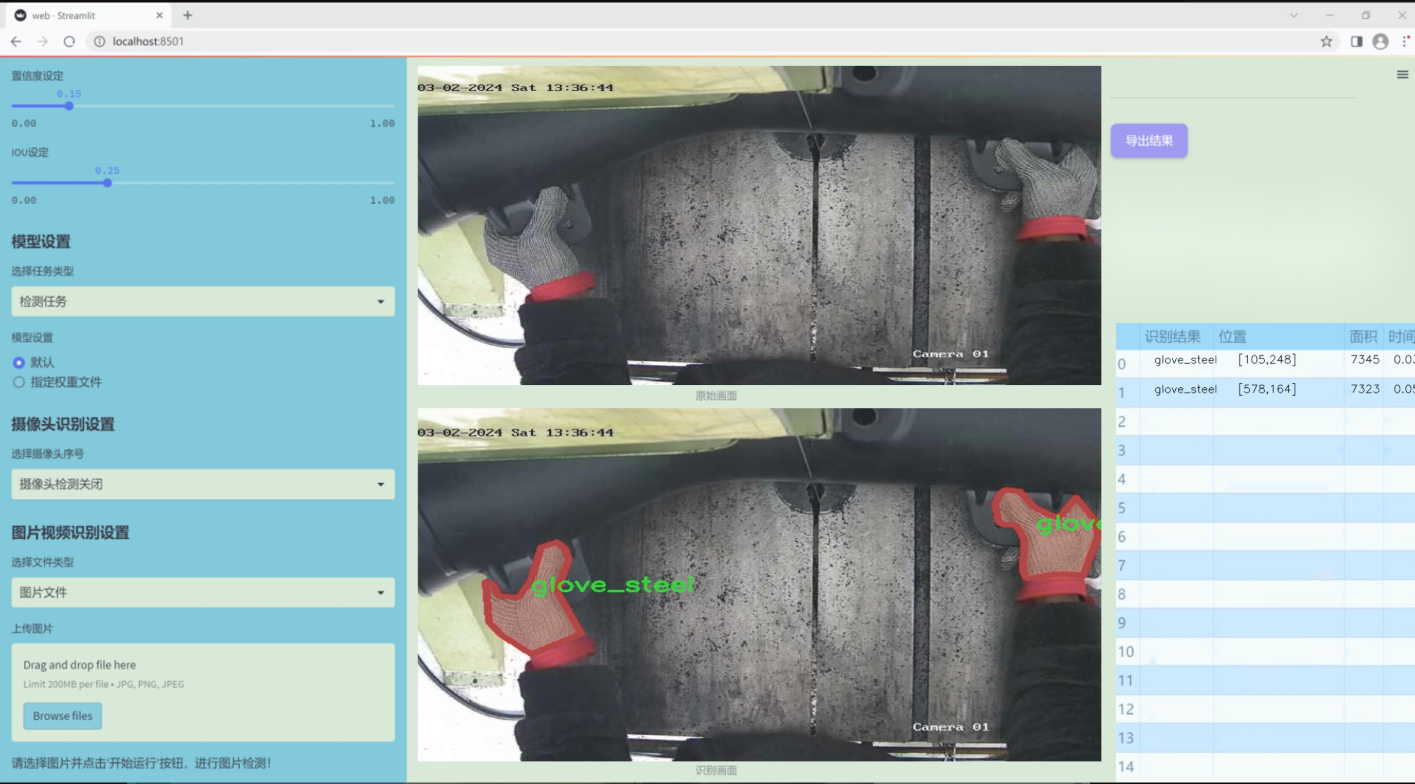
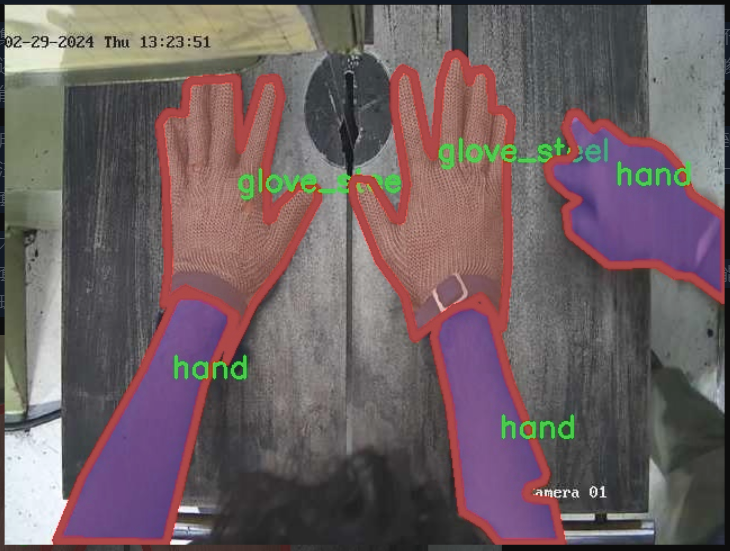
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的加工操作安全手套与手部检测系统,所使用的数据集围绕“bandsaw_kolabira”主题构建,专注于提升在加工环境中对手部及手套的检测能力。该数据集包含六个类别,具体为:蓝色手套(Glove_Blue)、白色手套(Glove_White)、钢制手套(glove_steel)、钢制手套B型(glove_steel_b)、手部(hand)以及头部(head)。这些类别的选择旨在全面覆盖加工操作中可能出现的关键安全元素,确保系统能够有效识别并响应不同的安全风险。
在数据集的构建过程中,采集了大量在实际加工环境中拍摄的图像,确保数据的多样性和真实性。这些图像不仅涵盖了不同的光照条件和背景环境,还包括了各种手部动作和手套佩戴状态,以增强模型的泛化能力。通过这种方式,数据集能够有效模拟真实工作场景中可能遇到的各种情况,从而为YOLOv11模型的训练提供坚实的基础。
在数据集的标注过程中,采用了精确的边界框标注技术,以确保每个类别的物体都能被准确识别。标注的质量直接影响到模型的性能,因此我们特别注重标注的一致性和准确性。此外,为了提升模型在实际应用中的表现,数据集中还包含了一些特殊情况的样本,例如手套未佩戴、佩戴不当等情形,以便模型能够在各种情况下做出正确的判断。
综上所述,本项目的数据集不仅涵盖了多样的类别和丰富的样本,还注重了标注的精确性与场景的多样性,为改进YOLOv11的加工操作安全手套与手部检测系统提供了强有力的数据支持。通过对该数据集的深入分析与应用,我们期望能够显著提升系统在实际加工环境中的安全性和有效性。



核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class OmniAttention(nn.Module):
def init(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(OmniAttention, self).init()
# 计算注意力通道数
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 温度参数,用于调整注意力分布
# 定义各个层self.avgpool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False) # 全连接层self.bn = nn.BatchNorm2d(attention_channel) # 批归一化self.relu = nn.ReLU(inplace=True) # ReLU激活函数# 定义通道注意力self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attention# 定义滤波器注意力if in_planes == groups and in_planes == out_planes: # 深度卷积self.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attention# 定义空间注意力if kernel_size == 1: # 点卷积self.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attention# 定义核注意力if kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights() # 初始化权重def _initialize_weights(self):# 初始化卷积层和批归一化层的权重for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)@staticmethod
def skip(_):return 1.0 # 跳过操作,返回1.0def get_channel_attention(self, x):# 计算通道注意力channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):# 计算滤波器注意力filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):# 计算空间注意力spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):# 计算核注意力kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):# 前向传播x = self.avgpool(x) # 自适应平均池化x = self.fc(x) # 全连接层x = self.bn(x) # 批归一化x = self.relu(x) # ReLU激活return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x) # 返回各个注意力
生成拉普拉斯金字塔的函数
def generate_laplacian_pyramid(input_tensor, num_levels, size_align=True, mode=‘bilinear’):
pyramid = [] # 存储金字塔层
current_tensor = input_tensor # 当前张量
_, _, H, W = current_tensor.shape # 获取输入张量的形状
for _ in range(num_levels):
b, _, h, w = current_tensor.shape # 获取当前张量的形状
# 下采样
downsampled_tensor = F.interpolate(current_tensor, (h//2 + h%2, w//2 + w%2), mode=mode, align_corners=(H%2) == 1)
if size_align:
# 对齐大小
upsampled_tensor = F.interpolate(downsampled_tensor, (H, W), mode=mode, align_corners=(H%2) == 1)
laplacian = F.interpolate(current_tensor, (H, W), mode=mode, align_corners=(H%2) == 1) - upsampled_tensor
else:
upsampled_tensor = F.interpolate(downsampled_tensor, (h, w), mode=mode, align_corners=(H%2) == 1)
laplacian = current_tensor - upsampled_tensor
pyramid.append(laplacian) # 添加拉普拉斯层
current_tensor = downsampled_tensor # 更新当前张量
if size_align:
current_tensor = F.interpolate(current_tensor, (H, W), mode=mode, align_corners=(H%2) == 1)
pyramid.append(current_tensor) # 添加最后一层
return pyramid # 返回金字塔
class AdaptiveDilatedConv(nn.Module):
“”“自适应膨胀卷积的封装类”“”
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(AdaptiveDilatedConv, self).init()
# 定义卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.omni_attention = OmniAttention(in_channels, out_channels, kernel_size) # 实例化OmniAttention
def forward(self, x):# 前向传播attention_weights = self.omni_attention(x) # 计算注意力权重x = self.conv(x) # 卷积操作return x * attention_weights # 返回加权后的输出
代码核心部分说明:
OmniAttention 类:实现了多种注意力机制,包括通道注意力、滤波器注意力、空间注意力和核注意力。通过这些注意力机制,可以动态调整特征图的不同部分的权重,从而提高模型的表现。
generate_laplacian_pyramid 函数:用于生成拉普拉斯金字塔,主要用于图像处理中的多尺度特征提取。通过逐层下采样和上采样,可以提取不同尺度的特征。
AdaptiveDilatedConv 类:实现了自适应膨胀卷积,结合了卷积操作和注意力机制。通过注意力机制,能够动态调整卷积操作的权重,从而增强模型的表达能力。
这些核心部分共同构成了一个强大的卷积神经网络架构,能够在图像处理和计算机视觉任务中取得良好的效果。
这个程序文件 fadc.py 是一个基于 PyTorch 的深度学习模型实现,主要涉及自适应膨胀卷积和频率选择机制。文件中包含多个类和函数,以下是对主要部分的讲解。
首先,文件导入了必要的库,包括 PyTorch 的核心库和一些常用的模块。然后,定义了一个名为 OmniAttention 的类,它是一个自定义的注意力机制。这个类的构造函数接收多个参数,包括输入和输出通道数、卷积核大小、组数、缩减比例等。它通过多个卷积层和激活函数来计算通道注意力、过滤器注意力、空间注意力和卷积核注意力。forward 方法将输入张量通过一系列操作生成注意力权重,这些权重可以在后续的卷积操作中使用。
接下来,定义了一个名为 generate_laplacian_pyramid 的函数,用于生成拉普拉斯金字塔。该函数通过逐层下采样输入张量,并计算当前层与下采样后的张量之间的差异,构建金字塔结构。此函数的输出是一个包含多个层次的金字塔列表,通常用于图像处理和特征提取。
然后,定义了 FrequencySelection 类,它用于选择特定频率的特征。该类支持多种操作模式,包括平均池化和拉普拉斯金字塔。构造函数中根据输入参数初始化多个卷积层和频率选择机制。forward 方法根据选择的频率对输入特征进行处理,并返回加权后的特征。
接下来是 AdaptiveDilatedConv 类,它是一个自适应膨胀卷积的实现,继承自 ModulatedDeformConv2d。该类的构造函数中定义了多个参数,包括卷积类型、偏移频率、卷积核分解等。它的 forward 方法实现了自适应卷积操作,结合了注意力机制和频率选择。
最后,定义了 AdaptiveDilatedDWConv 类,它是一个适应性膨胀深度卷积的实现。与前一个类类似,它也包含多个卷积层和注意力机制,并在 forward 方法中实现了深度卷积的操作。
整体来看,这个文件实现了一个复杂的卷积神经网络结构,结合了自适应卷积、注意力机制和频率选择,适用于图像处理和特征提取等任务。代码中使用了大量的 PyTorch API,展示了深度学习模型的灵活性和可扩展性。
10.4 dyhead_prune.py
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DyReLU(nn.Module):
“”“动态ReLU激活函数模块,具有自适应的激活强度和偏置。”“”
def init(self, inp, reduction=4, lambda_a=1.0, use_bias=True):
super(DyReLU, self).init()
self.oup = inp # 输出通道数
self.lambda_a = lambda_a * 2 # 激活强度的缩放因子
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化层
# 根据输入通道数和缩减比例计算squeeze通道数squeeze = inp // reductionself.fc = nn.Sequential(nn.Linear(inp, squeeze), # 全连接层,输入为inp,输出为squeezenn.ReLU(inplace=True), # ReLU激活函数nn.Linear(squeeze, self.oup * 2), # 输出为两倍的输出通道数h_sigmoid() # 使用h_sigmoid激活函数)def forward(self, x):"""前向传播函数,计算动态激活值。"""b, c, h, w = x.size() # 获取输入的批量大小、通道数、高度和宽度y = self.avg_pool(x).view(b, c) # 对输入进行自适应平均池化并调整形状y = self.fc(y).view(b, self.oup * 2, 1, 1) # 通过全连接层并调整形状# 从y中分离出两个激活强度和偏置a1, b1 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + 1.0 # 计算动态激活强度out = x * a1 + b1 # 计算输出return out # 返回动态激活后的输出
class DyDCNv2(nn.Module):
“”“带有归一化层的ModulatedDeformConv2d模块。”“”
def init(self, in_channels, out_channels, stride=1, norm_cfg=dict(type=‘GN’, num_groups=16)):
super().init()
self.conv = ModulatedDeformConv2d(in_channels, out_channels, 3, stride=stride, padding=1) # 定义可调变形卷积层
self.norm = build_norm_layer(norm_cfg, out_channels)[1] if norm_cfg else None # 根据配置构建归一化层
def forward(self, x, offset, mask):"""前向传播函数,计算卷积输出。"""x = self.conv(x.contiguous(), offset, mask) # 进行卷积操作if self.norm:x = self.norm(x) # 如果有归一化层,则进行归一化return x # 返回卷积后的输出
class DyHeadBlock_Prune(nn.Module):
“”“包含三种注意力机制的DyHead模块。”“”
def init(self, in_channels, norm_type=‘GN’):
super().init()
self.spatial_conv_high = DyDCNv2(in_channels, in_channels) # 高层特征卷积
self.spatial_conv_mid = DyDCNv2(in_channels, in_channels) # 中层特征卷积
self.spatial_conv_low = DyDCNv2(in_channels, in_channels, stride=2) # 低层特征卷积
self.spatial_conv_offset = nn.Conv2d(in_channels, 27, 3, padding=1) # 计算偏移和掩码的卷积层
self.task_attn_module = DyReLU(in_channels) # 任务注意力模块
def forward(self, x, level):"""前向传播函数,计算不同层次特征的融合。"""offset_and_mask = self.spatial_conv_offset(x[level]) # 计算偏移和掩码offset = offset_and_mask[:, :18, :, :] # 提取偏移mask = offset_and_mask[:, 18:, :, :].sigmoid() # 提取掩码并应用sigmoidmid_feat = self.spatial_conv_mid(x[level], offset, mask) # 中层特征卷积sum_feat = mid_feat # 初始化特征和# 如果有低层特征,则进行卷积并加权if level > 0:low_feat = self.spatial_conv_low(x[level - 1], offset, mask)sum_feat += low_feat# 如果有高层特征,则进行卷积并加权if level < len(x) - 1:high_feat = F.interpolate(self.spatial_conv_high(x[level + 1], offset, mask), size=x[level].shape[-2:], mode='bilinear', align_corners=True)sum_feat += high_featreturn self.task_attn_module(sum_feat) # 返回经过任务注意力模块处理的特征
代码核心部分说明:
DyReLU:实现了动态ReLU激活函数,可以根据输入自适应调整激活强度和偏置。
DyDCNv2:实现了带有归一化层的可调变形卷积,能够根据输入特征计算偏移和掩码。
DyHeadBlock_Prune:集成了多个卷积层和注意力机制,能够处理不同层次的特征并进行融合,最终输出经过注意力机制加权的特征。
这个程序文件 dyhead_prune.py 是一个基于 PyTorch 的深度学习模块,主要用于实现动态头部(Dynamic Head)中的一些自定义激活函数和卷积操作。文件中定义了多个类,每个类实现了特定的功能,以下是对代码的详细讲解。
首先,文件导入了必要的库,包括 PyTorch 的核心库和一些功能模块,如卷积、激活函数等。它还尝试从 mmcv 和 mmengine 导入一些功能,如果导入失败则捕获异常。
接下来,定义了一个 _make_divisible 函数,用于确保某个值可以被指定的除数整除,并且在必要时对其进行调整,以避免过大的变化。
然后,定义了几个自定义的激活函数类,包括 swish、h_swish 和 h_sigmoid。这些类继承自 nn.Module,并实现了 forward 方法,定义了它们各自的前向传播逻辑。
DyReLU 类是一个动态激活函数,具有可调的参数和可选的空间注意力机制。它的构造函数接受多个参数,包括输入通道数、缩减比例、初始化参数等。forward 方法中根据输入的特征图计算动态激活值,并根据条件选择不同的输出方式。
DyDCNv2 类是一个封装了调制变形卷积(Modulated Deformable Convolution)的模块,支持可选的归一化层。它的构造函数接受输入和输出通道数、步幅以及归一化配置,并在前向传播中执行卷积操作。
DyHeadBlock_Prune 类是动态头部的主要模块,包含了多个卷积层和注意力机制。它的构造函数初始化了多个卷积层和注意力模块,并定义了权重初始化的方法。forward 方法计算输入特征图的偏移量和掩码,并通过不同的卷积层处理特征图,最终结合不同层次的特征进行输出。
整个文件的结构清晰,功能模块化,适合在深度学习模型中使用,尤其是在需要动态调整特征图的情况下。通过这些自定义的激活函数和卷积操作,可以实现更灵活的特征提取和表示学习。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
27.移除元素 26.删除有序数组中的重复项 283.移动零 977.有序数组的平方)


)
)



)

)



)
带论文文档1万字以上,文末可获取,系统界面在最后面。)



