我们可以把它想象成一个 “老师”和“学生” 协作学习的过程。
全局服务器 = “老师”
本地客户端 = “学生”
整个模型更新的过程遵循一个核心原则:“数据不动,模型动”。原始数据永远留在本地客户端,只有模型的参数(即模型的“知识”)在服务器和客户端之间流动。
下面我们以最经典、最常用的 联邦平均算法(Federated Averaging, FedAvg) 为例,分步拆解这个更新过程。
1、总体流程概览
整个过程是一个循环迭代的过程,每一轮通信(Communication Round)都包含以下四个核心步骤,如下图所示:
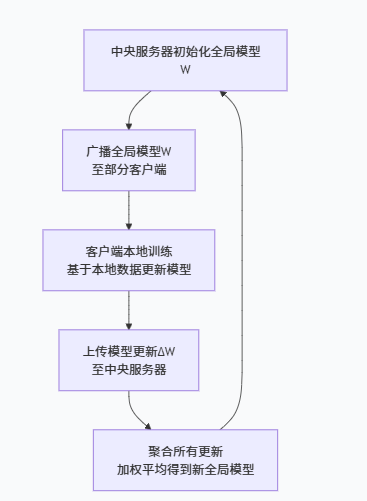
2、第一步:服务器端-初始化与广播(老师布置作业)
初始化:中央服务器会随机初始化一个全局模型,我们称之为 W_global(全局模型)。这就像一个刚毕业的新老师,脑子里有一套基础但还不精准的知识体系。
选择与广播:
在每一轮训练开始时,服务器会从所有可用的客户端(比如上百万部手机)中,随机选择一小部分(例如1000部)。这么做主要是为了效率,不可能每次都让所有人参与,不然会增加通信开销。
服务器将当前的全局模型 W_global 发送给这些被选中的客户端。
这就好比老师(服务器)把今天的教案(全局模型)发给了班上的一部分同学(客户端)。
3、第二步:客户端 - 本地模型更新(学生自己做功课)
收到全局模型的每个客户端,会开始执行本地训练:
加载数据:客户端从自己的本地存储中加载私有的训练数据(比如你手机上的照片、输入法记录)。
本地训练:
客户端用收到的 W_global 作为初始模型,用自己的本地数据进行训练,执行多次(比如10次)梯度下降(SGD)迭代。
训练完成后,客户端手上的模型参数更新了,我们称之为 W_local(本地参数)。
这就好比每个同学(客户端)都按照老师发的教案(W_global)自学,并结合自己的练习题(本地数据),总结出了一套自己的解题心得(W_local)。注意,每个同学的练习题都不一样,所以他们的心得也各有侧重(这个就设计到现实生活中的数据异构性,每个客户端的数据不一样,训练的参数也会不一样,甚至最后可能无法收敛,这过程中也会出现坏学生为了应付了事随便写的参数,或者伪造参数,就会导致最后模型的性能降低。当然也会有坏客户为了破坏模型性能,会选择伪造参数,窃取参数,也就需要对参数进行加密等操作)。
全局模型 = 一本不断再版的 “通用教材”
本地客户端 = 使用这本教材的 “学生”(每个学生都有自己的私人练习题)
联邦学习的过程 = 共同编写和修订这本教材的过程
计算更新:
客户端计算出本地模型与初始全局模型的差异(即更新量):ΔW = W_local - W_global。有些实现也会直接上传整个 W_local。
关键: 客户端绝不会上传它的原始数据,只上传模型的“更新量”或“新参数”。这完美保护了隐私。
4、全局模型
每一轮训练,服务器都会收集一批客户端的“学习心得”(模型更新),然后把这些心得中最有价值的部分融合起来,更新到这本“教材”里。所以,全局模型是所有参与客户端集体智慧的结晶。
最终的产品与目标:
联邦学习的最终目标,就是要训练出这个高质量的全局模型。我们所有的工作——本地计算、通信、聚合——都是为了让它变得更好、更智能、更通用。
训练完成后,这个全局模型可以被部署到新设备上直接使用,或者作为基础模型供进一步微调。它就是整个项目的产出物。
5、服务器端 - 聚合更新(老师批改作业,汇总答案)
收集更新:服务器等待所有被选中的客户端上传它们的模型更新 ΔW₁, ΔW₂, ..., ΔW_k(或它们的新参数 W_local₁, W_local₂, ...)。
加权平均:
服务器不会简单地把所有更新一平均了事。它会做一个加权平均。
权重取决于每个客户端本地数据的数量。数据量越大的客户端,它的“话语权”就越大。
计算公式:
新的全局模型:其中
n₁, n₂, ..., n_k是每个客户端本地数据的样本数量。
这就好比老师(服务器)收上所有同学的作业(模型更新),发现有的同学做的题多(数据量大),有的做的题少。老师更相信做题多的同学的经验,于是给他们的答案更高的权重,最后汇总所有答案的优点,形成了一份全新的、更完善的教案(W_global_new)。
全局模型=一本不断再版的 “通用教材”
本地客户端=使用这本教材的 “学生”(每个学生都有自己的私人练习题)
联邦学习的过程 = 共同编写和修订这本教材的过程
6、循环迭代
服务器用这个更新后的 W_global_new 替换掉旧的全局模型。然后,整个过程重复第一步:选择新的一批客户端,广播新的全局模型,开始下一轮的学习。
如此循环往复,直到全局模型达到一个令人满意的精度或收敛为止。
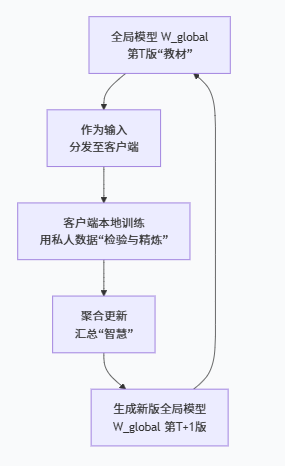
7、全局模型与联邦训练之间的关联(“教材”与“编写过程”如何互动?)
全局模型既是联邦训练的“输入”,也是它的“输出”。这个“输入-处理-输出”的循环,构成了训练的完整闭环。
作为“输入” (Starting Point):
在每一轮训练开始时,当前版本的全局模型(
W_global^t)被分发给选中的客户端。作用: 它确保了所有客户端是在同一个知识基础上进行学习和改进的。如果每个客户端都从自己的随机点开始,最终就无法将它们的知识融合到一起。
经历“处理” (Processing):
客户端收到全局模型后,用它在本地的、私有的数据上进行学习。这个学习过程可以看作是对全局模型的一次 “检验”和“ refinement(精炼)” 。
检验: 模型在用户A的数据上可能表现好,在用户B的数据上表现差,这暴露了模型的不足和偏差。
精炼: 每个客户端都会根据本地数据的特点,对模型进行微调,让它更适应自己的数据分布。这个过程相当于每个学生用私人练习题去验证和补充教材内容,并做了自己的笔记。
作为“输出” (Updated Product):
服务器将客户端返回的更新(“学生们的笔记”)进行聚合(加权平均),生成一个新版本的全局模型(
W_global^{t+1})。作用: 新模型融合了更多样、更广泛的知识,理论上比旧模型更全面、性能更好、泛化能力更强。这就像老师汇总了所有学生的优秀笔记,修订出了教材的“第二版”。
这个新模型立即成为下一轮训练的输入,循环往复。
重点:
不能把全局模型想象成一个固定的“指挥官”。
要把它想象成一个不断进化、不断成长的“核心”。它从一张白纸(随机初始化)开始,通过不断地“听取”成千上万客户端的意见(聚合更新),吸收全世界的知识,最终成长为一个见多识广、能力强大的模型。
8、总结
| 步骤 | 执行者 | 动作 | 输入 | 输出 | 比喻 |
|---|---|---|---|---|---|
| 1. 广播 | 全局服务器 | 选择客户端并发送模型 | 当前全局模型 W_global | W_global (发送) | 老师布置作业 |
| 2. 本地更新 | 本地客户端 | 本地训练 | W_global + 本地数据 | 本地模型 W_local | 学生自己做功课 |
| 3. 聚合 | 全局服务器 | 加权平均 | 所有客户端的 W_local | 新全局模型 W_global_new | 老师批改汇总 |
| 4. 循环 | 重复过程 |
隐私保护:数据始终在本地,只传输模型参数更新,这是联邦学习的立身之本。
通信效率:客户端本地进行多次迭代,大大减少了服务器和客户端之间的通信轮数,这是FedAvg算法的巨大优势。
非独立同分布:每个客户端的数据分布不同,这是联邦学习的主要挑战。加权平均是一种有效的聚合策略,旨在求取“最大公约数”。
异构性:客户端的设备、网络、数据量都不同,所以你的开题设计需要考虑如何选择客户端、如何处理掉队者等问题。

)

)

并进行归一化的标准操作)


——llama_index实现上下文窗口增强检索RAG)









)
