文章目录
- 一、Dify 是什么
- 二、安装与部署
- 2.1 云端 SaaS 版(快速入门)
- 2.2 私有化部署(企业级方案)
- 三、界面导航与核心模块
- 3.1 控制台概览
- 3.2 核心功能模块详解
- 3.2.1 知识库(RAG 引擎)
- 3.2.2 工作流编排
- 3.2.3 模型管理
- 四、创建第一个 AI 应用
- 场景示例:电商客服助手
- 五、Dify 应用类型
- 5.1 Chatbot(聊天助手)
- 5.2 Text Generator(文本生成)
- 5.3 Agent
- 5.4 Chatflow
- 5.5 Workflow(工作流)
- 六、使用 Dify 的一些技巧
- 6.1 提示词工程
- 6.2 模型选择与调优
- 6.3 插件使用
- 七、常见问题解答
- 7.1 部署问题
- 7.2 应用运行问题
一、Dify 是什么
Dify 是一款开源的大语言模型(LLM)应用开发平台,融合后端即服务(Backend as Service)与 LLMOps 理念,支持零代码 / 低代码构建生产级 AI 应用 。
其命名源自 “Define + Modify”,寓意 “定义并持续优化 AI 应用”,同时强调 “为你而做”(Do it for you)的开发体验 。
它的核心价值在于降低 AI 开发门槛,通过可视化界面实现工作流编排、RAG 引擎搭建及多模型集成,覆盖从原型设计到生产部署的全生命周期管理。
它还支持云端 SaaS 与私有化部署双模式,满足个人开发者快速验证与企业级数据安全需求 。

二、安装与部署
2.1 云端 SaaS 版(快速入门)
- 适用人群:特别适合非技术用户,或者用于功能验证。
- 操作步骤:
- 访问 Dify 官网(https://dify.ai ),点击右上角 “Sign Up”。
- 支持邮箱注册或使用第三方账号(GitHub/Google)登录。
- 免费版权益:拥有 200 次 GPT-4 调用额度、5MB 知识库存储空间以及基础工作流功能。
2.2 私有化部署(企业级方案)
- 适用场景:适用于对数据敏感的场景,通过 Docker 容器化部署。
- 通用步骤
# 拉取源码
git clone https://github.com/langgenius/dify.gitcd dify/docker# 复制环境配置文件
cp.env.example.env# 启动服务(后台运行)
docker compose up -d
部署完成后,访问 http://localhost/install 初始化管理员账号(密码需包含大小写字母 + 特殊符号)。
- 分操作系统指南
-
Windows:
- 需先启用 WSL2:进入控制面板→程序→启用或关闭 Windows 功能→勾选 “适用于 Linux 的 Windows 子系统”“虚拟机平台”。
- 安装 Docker Desktop(从官网下载),并在设置中启用 WSL2 集成。
- 打开 WSL 终端,执行上述通用步骤。若端口冲突(默认 80 端口),修改
.env文件中的EXPOSE_NGINX_PORT=8080后重启。
-
macOS:
- 安装 Docker Desktop(官网下载),拖拽至应用文件夹。
- 终端执行通用步骤,首次启动需授权 Docker 权限。
- 验证容器状态:
docker compose ps,确保 api/worker/web 等服务状态为 “Up”。
-
Linux(Ubuntu):
# 安装 Docker 与 Docker Compose
sudo apt update && sudo apt install docker.io docker-compose -ysudo systemctl enable --now docker# 允许当前用户管理Docker(需重启终端)
sudo usermod -aG docker $USER# 执行通用部署步骤
git clone https://github.com/langgenius/dify.gitcd dify/docker && cp.env.example.env && docker compose up -d
三、界面导航与核心模块
3.1 控制台概览
登录后进入主控台,核心模块包括:
- 应用:可在此创建 / 管理 AI 应用,如聊天助手、Agent、工作流等。
- 知识库:用于上传文档、配置检索策略(匹配数量 / 相似度阈值)。
- 工具:集成第三方服务,例如 MCP 服务、代码解释器、联网搜索等。
- 设置:进行模型供应商配置、团队权限设置以及安全策略(SSL/2FA)设置。
3.2 核心功能模块详解
3.2.1 知识库(RAG 引擎)
- 支持文档格式:支持上传 PDF/Word/Excel/TXT 等文档。
- 文档处理:自动切片(默认 500 字符 / 块)、向量化存储(基于 Weaviate 向量库)。
- 关键配置:
- 检索策略:采用混合检索(关键词匹配 + 向量相似度)、重排序(Rerank)提升 Top-K 准确率。
- 访问控制:可按团队 / 角色设置文档可见范围,比如法务文档仅合规部门访问。
- 动态更新:文档修改后自动同步索引,无需重新上传。
3.2.2 工作流编排
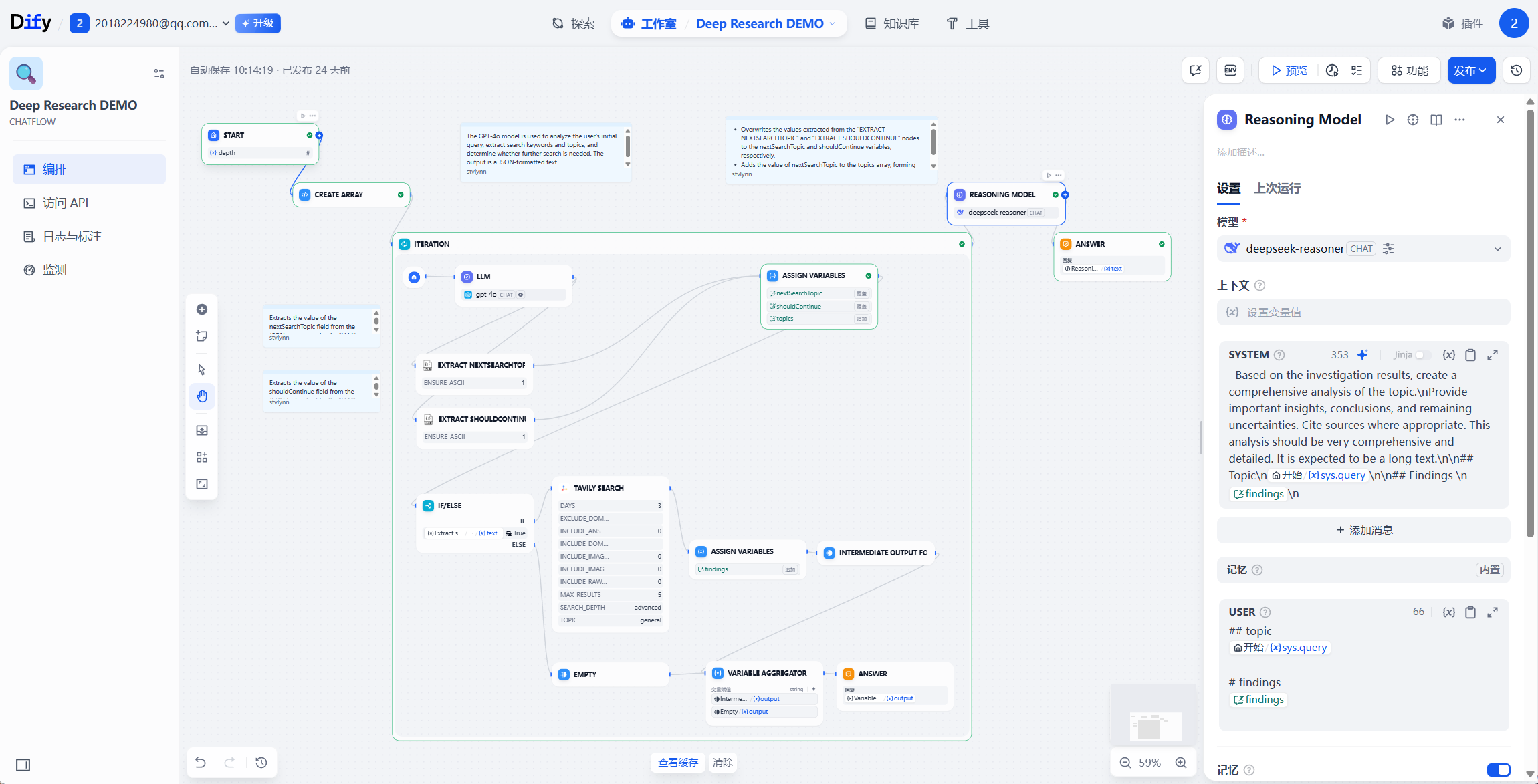
通过拖拽节点可视化设计 AI 流程,支持:
- 逻辑节点:条件分支(if-else)、循环迭代、变量赋值。
- 工具节点:HTTP 请求(调用外部 API)、代码执行(Python 沙箱)、知识库检索。
- 模型节点:集成 GPT-4/Claude/ 本地模型(如 DeepSeek-R1),支持流式输出。
3.2.3 模型管理
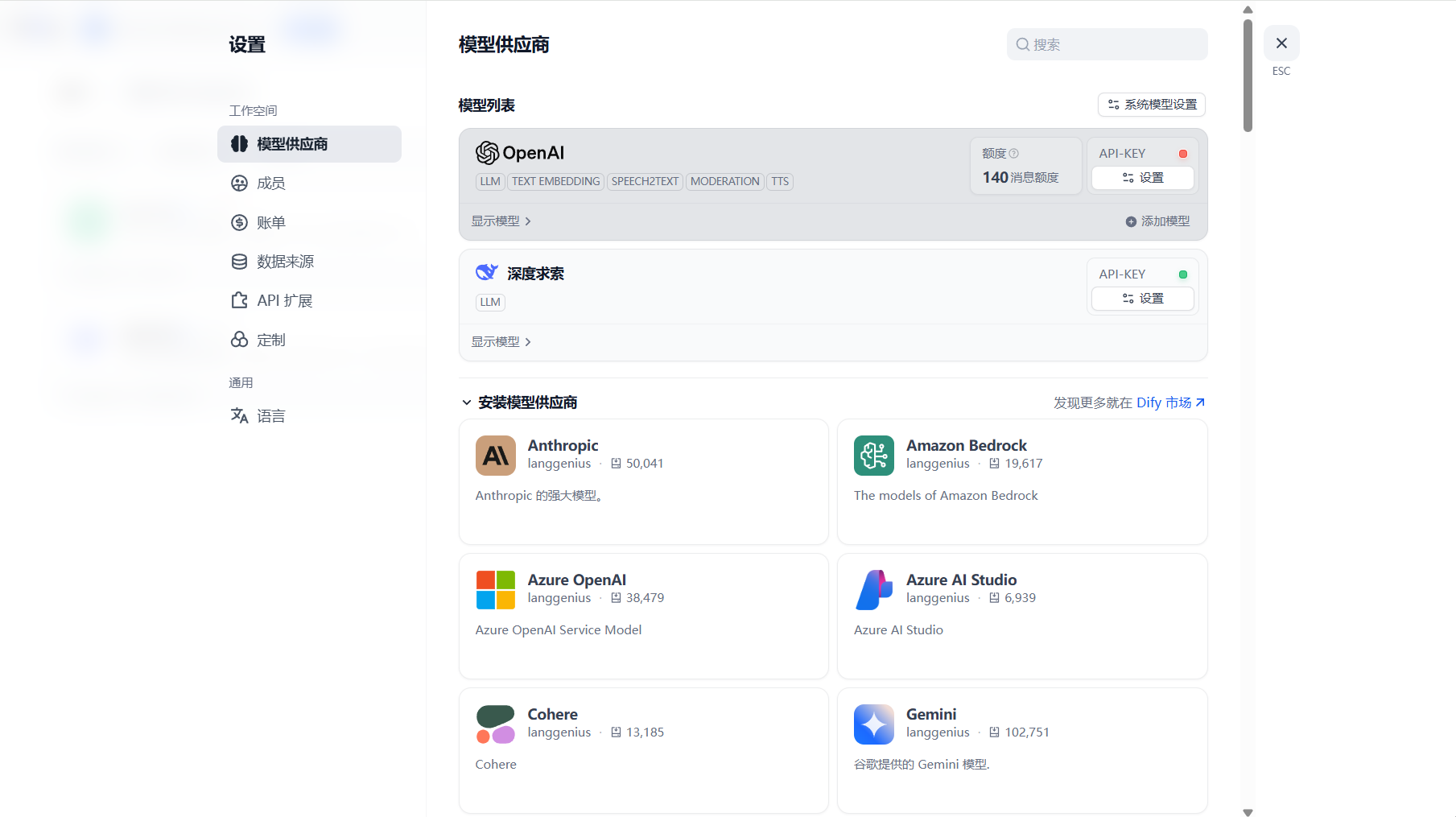
支持 100 + 模型供应商,包括:
- 闭源模型:如 OpenAI(GPT-4o)、Anthropic(Claude 3.5)、阿里云通义千问。
- 开源模型:通过 Ollama 部署本地模型(如 Llama 3、DeepSeek-R1:7b),配置示例:
# Ollama本地模型启动(需先安装Ollama)
ollama run deepseek-r1:7b
在 Dify “模型供应商” 中添加 Ollama,Base URL 填写http://host.docker.internal:11434,模型名称填deepseek-r1:7b。
四、创建第一个 AI 应用
场景示例:电商客服助手
目标:搭建能回答退货政策、商品保修等问题的智能客服,无需编写代码。
Step 1:创建应用
- 主控台点击 “创建应用”,选择类型 “聊天助手”,命名 “电商客服助手”。
- 选择模型:免费版可先用 GPT-3.5-turbo,企业用户可配置私有模型(如通义千问)。
Step 2:上传知识库
- 进入 “知识库”→“添加数据集”,上传《退货政策.docx》《商品手册.pdf》等相关文档。
- 文档处理:默认 “通用” 分段策略,点击 “预览块” 确认切片是否符合预期。
Step 3:设置回复逻辑(可选)
- 若需要更复杂的回复逻辑,可进入工作流编排界面。
- 通过拖拽节点设置,如当用户提问时,先进行知识库检索节点,若检索到相关内容,则直接返回;若未检索到,再调用大语言模型进行回答。
Step 4:测试与优化
- 在应用界面进行测试,输入诸如 “商品如何退货”“保修政策是怎样的” 等问题,查看回复是否准确。
- 若回复不理想,检查知识库文档切片是否合理,或者调整工作流节点设置,如优化大语言模型的提示词等。
Step 5:发布应用
- 测试通过后,点击 “发布”。
- 发布后可获得应用的 Web 链接或者 API,可将其集成到电商网站等平台中,为用户提供服务。
五、Dify 应用类型
5.1 Chatbot(聊天助手)
- 特点:能够与用户进行多轮对话,理解用户意图并提供相应回答。常用于客服场景,可快速响应用户咨询,解决常见问题。
- 创建要点:在创建时,需重点设置初始问候语,引导用户进行交互。同时,合理配置知识库,使其能根据用户问题从知识库中准确检索信息并回复。例如电商客服聊天机器人,要确保将产品信息、售后政策等文档准确上传至知识库。
5.2 Text Generator(文本生成)
- 特点:根据用户输入的提示或要求,生成特定类型的文本,如文章、报告、故事等。适用于内容创作领域,可快速生成初稿,提高创作效率。
- 创建要点:设置好生成文本的风格、长度等参数。比如创建一个新闻稿生成器,要明确新闻稿的语言风格(正式、活泼等)、字数要求,以及可能需要提供一些新闻事件的关键信息作为生成的基础。
5.3 Agent
- 特点:具备自主决策和执行任务的能力,可调用多种工具和服务来完成复杂任务。例如可以调用搜索引擎获取实时信息,调用代码执行工具运行代码等。
- 创建要点:需要精心设计 Agent 的任务流程和工具调用逻辑。例如创建一个智能投资 Agent,要设置其在获取市场数据后,如何分析数据、根据分析结果调用交易工具进行操作等流程。
5.4 Chatflow
- 特点:侧重于定义对话流程,可根据用户不同的输入路径,引导对话走向不同分支,实现个性化对话体验。
- 创建要点:仔细规划对话的各个分支和节点,确保对话逻辑清晰、流畅。比如设计一个旅游咨询 Chatflow,当用户选择不同旅游目的地时,能引导其进入相应的景点介绍、交通推荐等不同分支。
5.5 Workflow(工作流)
- 特点:通过可视化的方式编排各种节点,实现复杂的业务逻辑自动化。可串联多个模型调用、数据处理、工具执行等操作。
- 创建要点:梳理清楚整个业务流程,选择合适的节点进行连接和配置。例如构建一个数据分析 Workflow,可能需要依次连接数据获取节点(如从数据库读取数据)、数据清洗节点、数据分析模型节点(如使用统计模型进行分析)以及结果输出节点(如生成报告)。
六、使用 Dify 的一些技巧
6.1 提示词工程
- 在 Dify 的提示词 IDE 中,精心设计提示词模板。例如在文本生成任务中,添加详细的示例可以实现 One-Shot Learning。比如让模型生成产品推广文案,可在提示词中先给出一个其他产品推广文案的优秀示例,然后引导模型按照类似风格生成目标产品的文案。
- 合理使用变量插值,使提示词能根据不同的输入动态变化。例如在客服场景中,提示词可以根据用户咨询的产品型号变量,针对性地从知识库中检索该型号产品的相关信息并回复。
6.2 模型选择与调优
- 根据不同的任务需求选择合适的模型。如处理图像相关的任务(如票据识别),可选用多模态模型 Qwen2-VL;进行长文本生成任务时,GPT-4 可能效果更佳。
- 对于一些模型,可通过调整参数来优化性能。比如某些开源模型可以调整温度参数(temperature),温度越低,生成的文本越确定、保守;温度越高,生成的文本越具多样性,但也可能更随机、不准确。在实际应用中,需根据生成文本的需求来调整该参数。
6.3 插件使用
- 充分利用插件市场(Marketplace)中的插件来扩展应用能力。例如使用 Google SERP 搜索插件,可让应用在回答用户问题时,获取最新的网络搜索结果,增强回答的时效性和准确性。
- 若现有插件无法满足需求,还可以开发自定义插件。比如企业内部有特定的业务系统,可开发插件将 Dify 与该系统连接,实现数据交互和业务流程自动化。
七、常见问题解答
7.1 部署问题
-
端口冲突
在私有化部署时,遇到端口冲突(如默认 80 端口被占用):- 在 Windows 系统中,修改
.env文件中的EXPOSE_NGINX_PORT为其他未被占用的端口,如 8080,然后重启服务。 - 在 Linux 或 macOS 系统中,也可通过类似方式修改端口配置。
- 在 Windows 系统中,修改
-
镜像拉取失败
- 可能由于网络问题导致镜像拉取失败。可尝试更换网络环境,或者使用国内的镜像源。
- 例如在 Docker 配置中添加国内镜像源地址,如阿里云的镜像源。
7.2 应用运行问题
-
回答不准确
- 检查知识库文档的切片是否合理,若切片过大或过小,可能影响检索准确性。同时,优化提示词,确保能引导模型给出准确回答。
- 另外,检查模型的选择是否合适,不同模型在不同领域的表现可能有所差异。
-
应用响应慢
- 若使用的是云端模型且调用量较大,可能会出现排队等待的情况,导致响应变慢。可考虑优化工作流,减少不必要的模型调用次数。对于一些可并行处理的任务,通过设置并行节点来提高效率。
- 若使用本地模型,检查服务器的硬件配置是否足够,如 CPU、内存等资源是否紧张,必要时升级硬件配置。







:Palette——让你的APP色彩“飞”起来!)



)






全解析2)
