目录
RAID实现方式
RAID 0
RAID 1
RAID 5
RAID 10
管理RAID0
创建RAID
查看RAID
格式化和挂载
删除RAID
管理RAID1
创建RAID
查看RAID
格式化和挂载
增加热备盘
模拟故障
删除故障磁盘
删除RAID
管理RAID5
创建RAID
查看RAID
md5设备划分分区
RAID实现方式
从实现角度看,RAID主要分为:
-
软RAID:所有功能均有操作系统和CPU来完成,没有独立的RAID控制/处理芯片和I/O处理芯片,效率最低。
-
硬RAID:配备了专门的RAID控制/处理芯片和I/O处理芯片以及阵列缓冲,不占用CPU资源,成本很高。
-
软硬混合RAID:具备RAID控制/处理芯片,但缺乏I/O处理芯片,需要CPU和驱动程序来完成,性能和成本在软RAID和硬RAID之间。
RAID 0
RAID0使用数据条带化(striping)的方式将数据分散存储在多个磁盘驱动器上,而不进行冗余备份。数据被分成固定大小的块,并依次存储在每个磁盘上。
例如,如果有两个驱动器(驱动器A和驱动器B),一块数据的第一个部分存储在驱动器A上,第二个部分存储在驱动器B上,以此类推。这种条带化的方式可以同时从多个驱动器读取或写入数据,从而提高系统的性能。
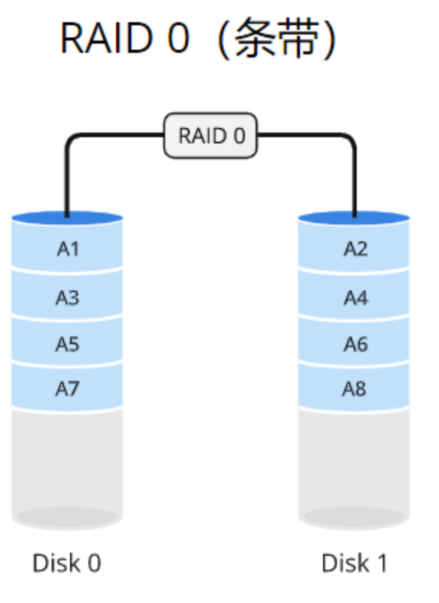
适用于需要高性能而不关心数据冗余的场景
优点
-
高性能:通过数据条带化和并行读写操作,RAID0可以提供更快的数据传输速度和更高的系统性能。
-
成本效益:相对于其他RAID级别(如RAID1或RAID5),RAID0不需要额外的磁盘用于冗余备份,因此在成本上更具竞争力。
缺点
-
缺乏冗余:由于RAID0不提供数据冗余,如果任何一个驱动器发生故障,所有数据都可能丢失。因此,RAID0不适合存储关键数据。
-
可靠性降低:由于没有冗余备份,RAID0的可靠性相对较低。如果任何一个驱动器发生故障,整个阵列的可用性将受到影响。
RAID 1
优点
-
数据冗余备份:RAID1通过数据镜像将数据完全复制到多个驱动器上,提供冗余备份,保护数据免受驱动器故障的影响。
-
高可用性:由于数据的冗余备份,即使一个驱动器发生故障,系统仍然可以从其他驱动器中读取数据,保证数据的可用性和连续性。
-
读取性能提升:RAID1可以通过并行读取数据的方式提升读取性能,从而加快数据访问速度。
缺点
-
成本增加:由于需要额外的磁盘用于数据冗余备份,RAID1的成本相对较高。需要考虑额外的硬件成本。
-
写入性能略低:由于数据需要同时写入多个驱动器,相对于单个驱动器的写入性能,RAID1的写入性能可能略低。
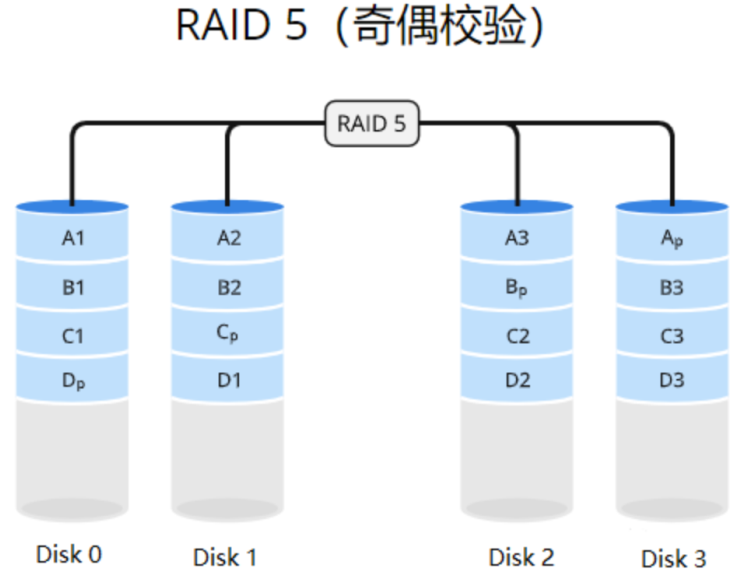
RAID 5
优点
-
性能增强:通过数据条带化和并行读写操作,RAID5可以提供较高的数据传输速度和系统性能。
-
数据冗余备份:通过分布式奇偶校验,RAID5可以提供数据的冗余备份,保护数据免受驱动器故障的影响。
-
成本效益:相对于其他RAID级别(如RAID1),RAID5只需要额外一个驱动器用于奇偶校验信息,从而在成本上更具竞争力。
缺点
-
写入性能受限:由于写入数据时需要重新计算奇偶校验信息,相对于读取操作,RAID5的写入性能较低。
-
驱动器故障期间的数据完整性:如果一个驱动器发生故障,系统在恢复数据时需要进行计算,这可能导致数据访问速度较慢,并且在此期间可能会有数据完整性的风险。
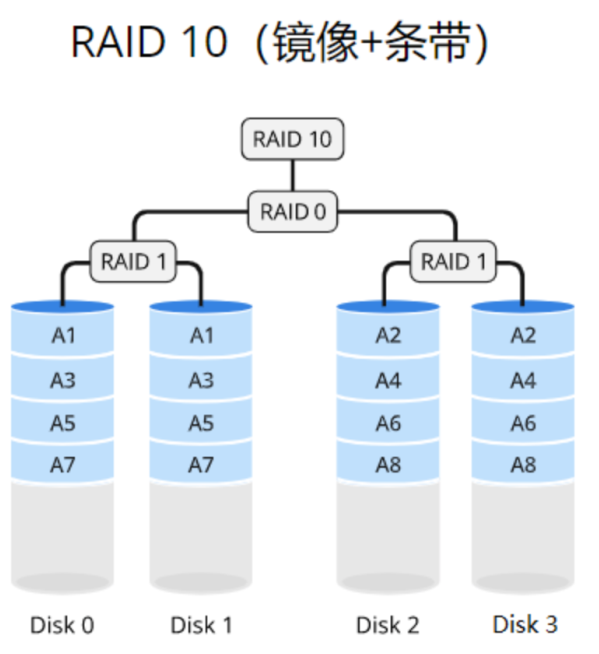
RAID 10
优点
-
高性能:通过数据条带化和并行读写操作,RAID10可以提供较高的数据传输速度和系统性能。
-
数据冗余备份:通过数据镜像将数据完全复制到另一个驱动器上,RAID10提供了数据的冗余备份,保护数据免受驱动器故障的影响。
-
较高的可靠性:由于RAID10采用镜像的方式进行数据冗余备份,即使一个驱动器发生故障,仍然可以从其他驱动器中读取数据,确保数据的可用性和连续性。
-
快速的故障恢复:在RAID10中,如果一个驱动器发生故障,系统可以直接从镜像驱动器中恢复数据,而无需进行复杂的计算,从而加快故障恢复的速度。
缺点
-
较高的成本:相对于其他RAID级别,RAID10需要更多的驱动器用于数据镜像,从而增加了硬件成本。
-
低效的空间利用:由于RAID10的数据镜像特性,有效的存储容量只等于所有驱动器中一半的容量,因此空间利用率较低。
管理RAID0
创建RAID
#创建一个包含2个块设备的raid0设备/dev/md0
mdadm -C /dev/md0 -l raid0 -n 2 /dev/sd{b,c}
查看RAID
#查看raid信息
cat /proc/mdstat
#查看raid设备详细信息
mdadm -D /dev/md0
格式化和挂载
mkfs.xfs /dev/md0
mkdir /data/raid0
mount /dev/md0 /data/raid0
df -h /data/raid0#创建数据
cp /etc/ho* /data/raid0
ls /data/raid0/
删除RAID
#卸载
umount /dev/md0
#stop RAID阵列,将删除阵列
mdadm --stop /dev/md0
#清除原先设备上的 md superblock
mdadm --zero-superblock /dev/sd{b,c}
raid0条带不能增加新成员盘
raid0条带不能强制故障成员盘
管理RAID1
创建RAID
#创建一个包含两个块设备的raid1设备/dev/md1
mdadm -C /dev/md1 -l 1 -n 2 /dev/sd{a,b}
查看RAID
mdadm -D /dev/md1
等待同步完成
格式化和挂载
mkfs.xfs /dev/md1
mkdir -p /data/raid1
mount /dev/md1 /data/raid1
df -h /data/raid1#创建数据
cp /etc/ho* /data/raid1
ls /data/raid1/

增加热备盘
mdadm /dev/md1 -a /dev/sdd
mdadm -D /dev/md1 | tail -5
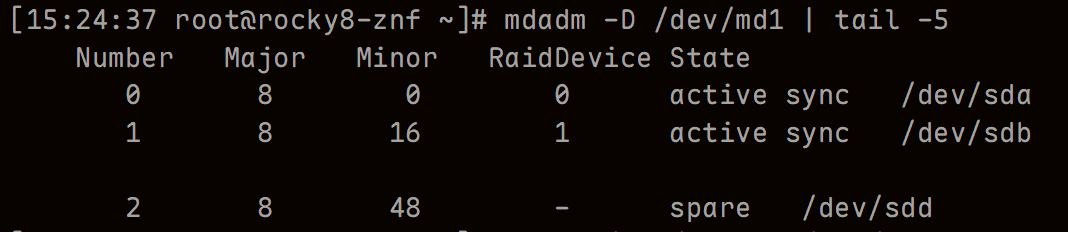
此时sdd的状态为spare(备用)
模拟故障
mdadm /dev/md1 -f /dev/sdb
#查看成员状态
mdadm -D /dev/md1 |tail -5
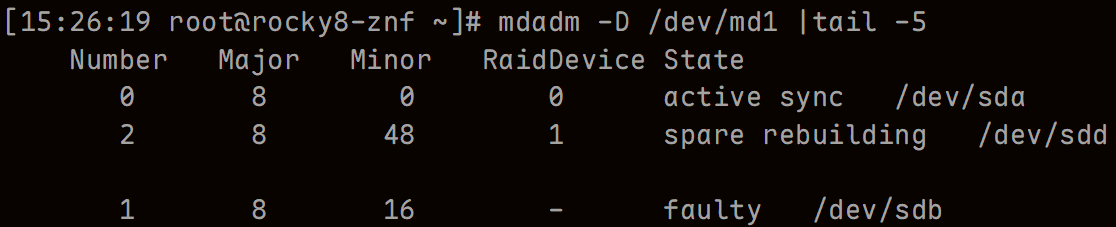
sdd立刻顶替故障磁盘,并进行同步。数据依然能够正常访问
删除故障磁盘
m3stopdadm /dev/md1 -r /dev/sdb
mdadm -D /dev/md1 |tail -5
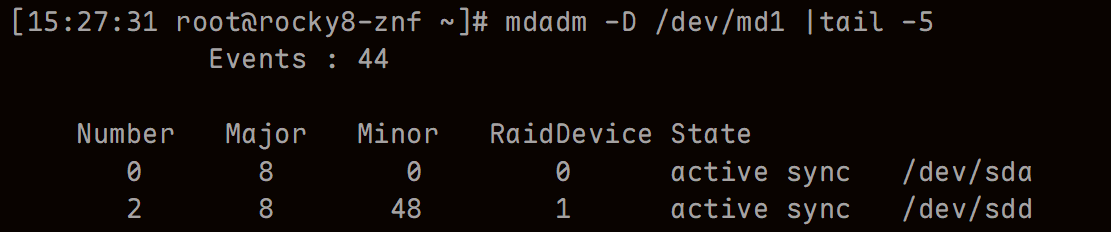
删除RAID
#卸载
umount /dev/md1
#stop RAID阵列,将删除阵列
mdadm --stop /dev/md1
#清除原先设备上的md superblock
mdadm --zero-superblock /dev/sd{a..d}
管理RAID5
创建RAID
#创建一个包含4个块设备的raid5设备/dev/md5
mdadm -C /dev/md5 -l 5 -n 4 /dev/sd{b..e}
查看RAID
mdadm -D /dev/md5
md5设备划分分区
#创建两个分区
fdisk /dev/md5
lsblk /dev/md5
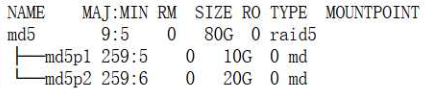
#格式化
mkfs.xfs /dev/md5p1
mkfs.xfs /dev/md5p2
#新建目录
mkdir /data/webapp /data/dbapp
#挂载
mount /dev/md5p1 /data/webapp/
mount /dev/md5p2 /data/dbapp/
#验证
df -h | grep md5
echo hello webapp > /data/webapp/test
echo hello dbapp > /data/dbapp/test
#添加备用盘
mdadm /dev/md5 --add /dev/sdf
#模拟故障
mdadm /dev/md5 --fail /dev/sdb
##此时会发现sdf立刻顶替了损坏的盘
#移除故障盘
mdadm /dev/md5 --remove /dev/sdf
#再次添加
mdadm /dev/md5 --add /dev/sdb
#扩容raid设备,将raid成员数增加到5个
mdadm -G /dev/md5 --raid-devices 5
mdadm /dev/md5 --add /dev/sdg
lsblk /dev/md5
#新建分区3
fdisk /dev/md5
lsblk
#文件系统扩容
df -hT /data/dbapp/
xfs_growfs /data/dbapp/
df -hT /data/dbapp/





 ——622. 设计循环队列(C语言))




下玩转 Metasploit 自动利用)




:Boost.Beast实现简易http服务器)



