最近看到 Google AI 发布了一个叫 MLE-STAR(Machine Learning Engineering via Search and Targeted Refinement)的新系统,说实话,第一眼看完论文和相关介绍后,我是有点震撼的。这不只是一次简单的“LLM + 自动化”拼凑,而是真正把机器学习工程(ML Engineering)这个复杂流程,用智能代理(agent)的方式往前推了一大步。
咱们平时做项目的时候都知道,一个完整的 ML pipeline 涉及数据预处理、特征工程、模型选择、调参、集成学习,还有各种 bug 调试和数据泄露检查。这些活儿不仅琐碎,还特别考验经验。以前我们也用过一些自动化工具,比如 AutoML,或者基于 LLM 的代码生成 agent,但总觉得“差点意思”——要么太依赖模型自己“记住”的东西,要么改代码像“一把梭”,整个脚本重写一遍,效率低,效果也不稳定。
而这次 Google Cloud 团队推出的 MLE-STAR,我觉得是真正抓住了痛点。
它到底解决了什么问题?
文章里提到几个关键瓶颈,我深有体会:
1. LLM 记忆的局限性:很多 agent 写代码时,总是习惯性地用 scikit-learn 套个 Random Forest 或 XGBoost 就完事了。不是不好,但在某些任务上,比如图像、音频,明明有更先进的模型(比如 ViT、EfficientNet),但它“想不起来”或者“不敢用”。这就导致方案不够前沿。
2. 粗粒度的迭代方式:以前的 agent 往往是“全盘重写”——跑一次结果不好,就整个代码重新生成一遍。这种“all-at-once”的修改,缺乏针对性,很难深入优化某个模块,比如特征编码方式或者归一化策略。
3. 容易出错,还难发现:生成的代码经常有运行错误、数据泄露(比如在训练时不小心用了 test set 的统计信息),或者干脆漏掉了某个数据文件。这些问题在真实项目中是致命的,但很多 agent 根本不检查。
MLE-STAR 正是在这几个方面做了系统性的突破。
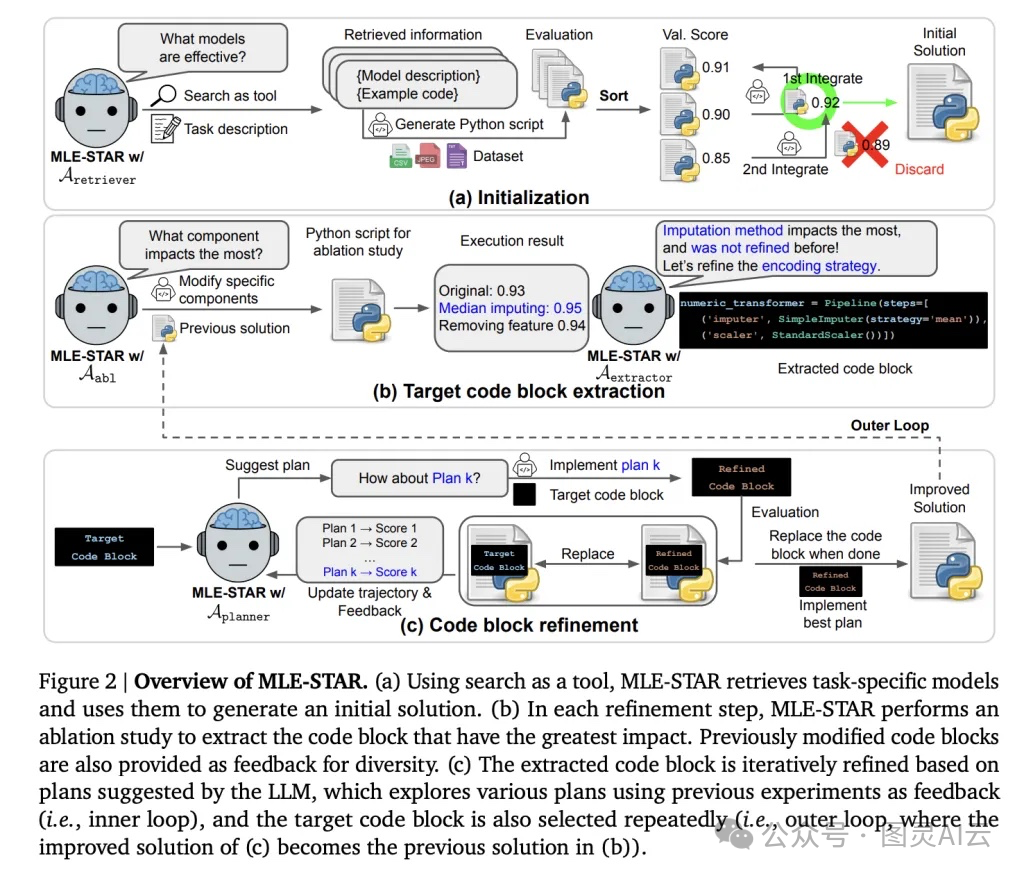
它的核心创新,我觉得可以用“搜、改、合、查”四个字来概括
1. 搜:Web Search–Guided Model Selection
这是让我眼前一亮的设计。MLE-STAR 不再只靠 LLM 自己“脑补”模型,而是会主动调用 web-scale search,去检索当前任务最相关的模型和代码片段。比如你给它一个图像分类任务,它会去搜最新的 model cards、Kaggle kernels、GitHub 项目,然后把 EfficientNet、ViT 这些真正 state-of-the-art 的架构纳入候选。
这就相当于,它不是靠“背书”做题,而是开卷考试,还能查资料——你说这优势多大?
2. 改:Nested, Targeted Code Refinement(嵌套式、针对性代码优化)
这个机制特别聪明。它用了双层循环优化:
• 外层循环(Ablation-driven):它会做“消融实验”(ablation study),自动分析当前 pipeline 中哪个模块对性能影响最大——是数据预处理?特征工程?还是模型结构?
• 内层循环(Focused Exploration):一旦锁定关键模块,它就只针对那一块做精细化迭代。比如发现 categorical feature 的编码方式是瓶颈,它就会尝试 One-Hot、Target Encoding、Embedding 等多种方式,逐一测试。
这种“先定位,再攻坚”的策略,比盲目重写整个脚本高效太多了,也更接近人类专家的思维方式。
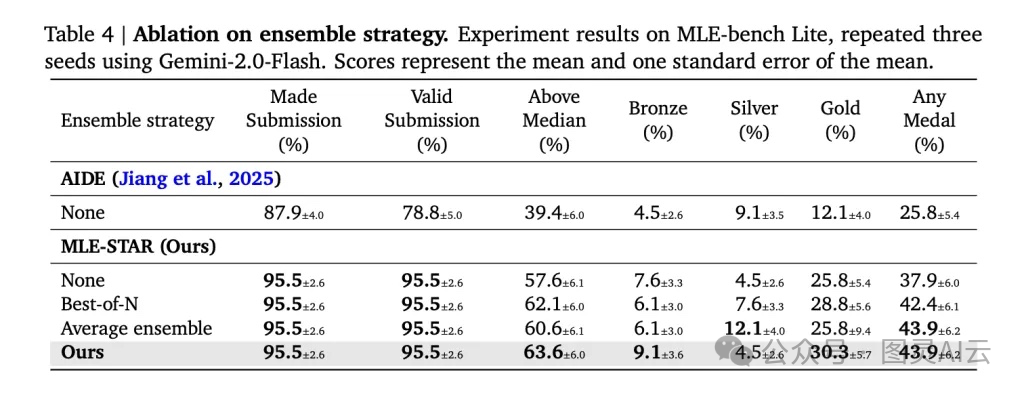
3. 合:Self-Improving Ensembling Strategy(自进化的集成策略)
集成学习(Ensemble)一直是 Kaggle 拿奖的利器,但大多数 agent 只会简单地“投票”或“平均”。MLE-STAR 不一样,它能主动设计复杂的集成方案,比如 stacking,甚至自己构建 meta-learner(元学习器),或者搜索最优权重组合。
更关键的是,它是在多个候选方案的基础上动态组合,而不是只挑一个“最好”的。这就大大提升了鲁棒性和上限。
4. 查:Robustness through Specialized Agents(专项检查机制)
这一点在工程上太重要了。MLE-STAR 内置了三个“质检员”:
• Debugging Agent:遇到 Python 报错,它会自动修复,直到代码能跑通,最多试几次;
• Data Leakage Checker:专门检查有没有数据泄露,比如标准化时用了 test set 的均值;
• Data Usage Checker:确保所有提供的数据文件都被充分利用,避免遗漏重要信息。
这些检查机制,看似“辅助”,实则是保证结果可信的关键。没有它们,再好的模型也可能因为一个小 bug 而前功尽弃。
效果怎么样?数据说话
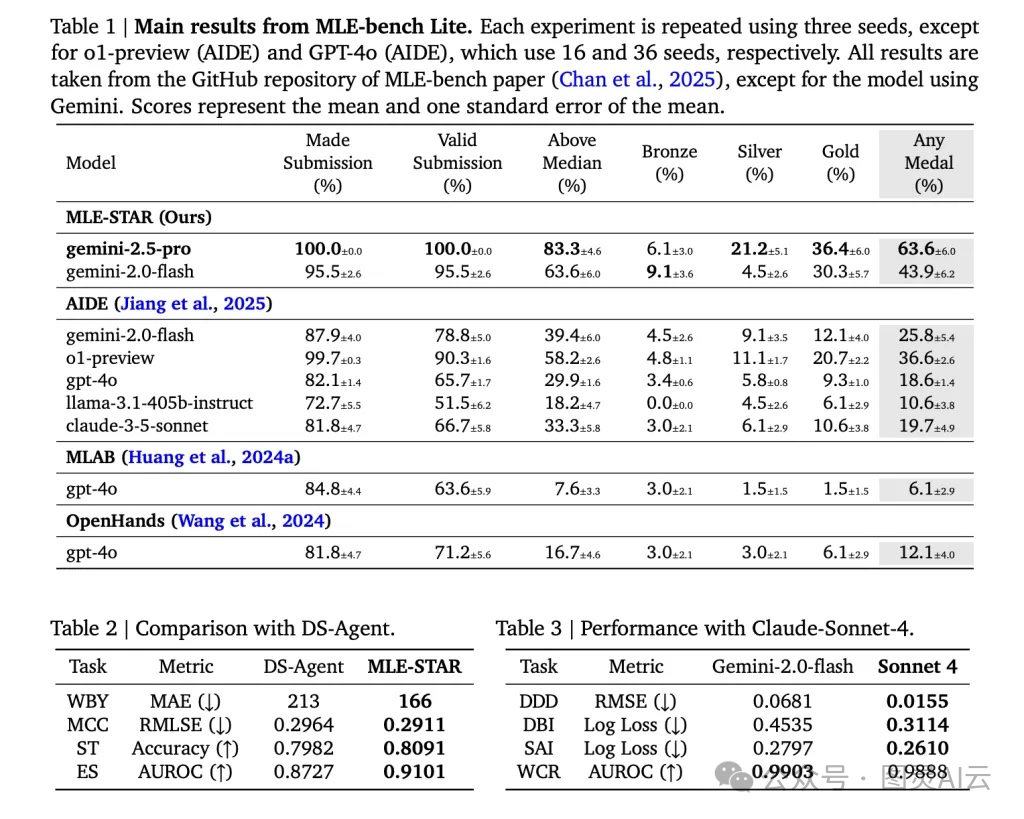
他们在 MLE-Bench-Lite 这个 benchmark 上做了测试,包含 22 个来自 Kaggle 的真实竞赛任务,涵盖表格、图像、音频、文本等多种模态。结果非常亮眼:
指标 | MLE-STAR (Gemini-2.5-Pro) | 最佳基线 AIDE |
获奖率(Any Medal) | 63.6% | 25.8% |
金牌率(Gold Medal) | 36.4% | 12.1% |
超过中位数 | 83.3% | 39.4% |
有效提交率 | 100% | 78.8% |
你看,获奖率直接翻了两倍多,金牌率更是三倍以上。尤其是在图像任务上,MLE-STAR 主动选择了 ViT、EfficientNet 这些现代架构,而不是守着 ResNet 不放,说明它真的“跟上了时代”。
而且,它的有效提交率是 100%,意味着生成的代码都能跑通,没有语法错误或文件缺失——这对自动化系统来说,是个巨大的工程胜利。
我的一些思考
说实话,看到这个系统,我第一反应是:“这已经不只是工具,而是一个会学习、会反思、会协作的 ML 工程伙伴了。”
它不像传统的 AutoML 那样“黑箱”,也不像纯 LLM 生成那样“随性”,而是建立了一套有逻辑、有反馈、有安全边界的工作流。特别是那个“ablation-driven”的外层循环,让我觉得它有点像人类研究员在做实验设计——先分析瓶颈,再集中突破。
另外,它还支持 human-in-the-loop,比如专家可以手动注入最新的模型描述,帮助系统更快采纳前沿技术。这种“人机协同”的设计,既保留了自动化效率,又不失灵活性,非常务实。
更让人高兴的是,Google 把这套系统基于 Agent Development Kit (ADK) 构建,并且开源了代码和教程。这意味着我们普通研究者和工程师也能上手试用、二次开发,甚至把它集成到自己的 pipeline 中。这种开放态度,对整个社区都是好事。
总结一下
MLE-STAR 真的代表了当前 ML 自动化的一个新高度。 它通过“搜索打底、聚焦优化、智能集成、严格检查”这一整套机制,不仅提升了性能,更重要的是提升了可靠性和可解释性。
如果你在做 AutoML、智能 agent、或者 MLOps 相关的工作,这个项目非常值得深入研究。我已经在 GitHub 上 star 了他们的 repo,也打算用他们的 notebook 先跑一个 demo 试试。
未来,也许我们不再需要从头写每一个 pipeline,而是和像 MLE-STAR 这样的 agent 一起协作——它负责执行和迭代,我们负责定义问题和把控方向。这或许就是下一代机器学习工程的样子。
详见
1. 论文:https://www.arxiv.org/abs/2506.15692
2. 代码:https://github.com/google/adk-samples/tree/main/python/agents/machine-learning-engineering
3. 相关文档:https://research.google/blog/mle-star-a-state-of-the-art-machine-learning-engineering-agents/

)







Python爬虫入门教程:从零开始学习网页抓取(爬虫教学)(Python教学))






到大语言模型落地手记(RAG/Agent/MCP),一场耗时5+3年的技术沉淀—“代码可跑,经验可抄”—【一个处女座的程序猿】携两本AI)

--使用CUB库实现基本功能)
