上篇文章:
Spring Cloud系列—Eureka服务注册/发现![]() https://blog.csdn.net/sniper_fandc/article/details/149937589?fromshare=blogdetail&sharetype=blogdetail&sharerId=149937589&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
https://blog.csdn.net/sniper_fandc/article/details/149937589?fromshare=blogdetail&sharetype=blogdetail&sharerId=149937589&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
目录
1 如何在IDEA中启动一个服务的多个实例
2 负载均衡
3 Spring Cloud LoadBalancer实现负载均衡
3.1 添加注解@LoadBalanced
3.2 修改远程调用的ip:端口号为服务名称
4 Spring Cloud LoadBalancer负载均衡策略
5 Spring Cloud LoadBalancer负载均衡原理
在Eureka篇章中,使用了如下代码获取服务的实例:
List<ServiceInstance> productService = discoveryClient.getInstances("product-service");EurekaServiceInstance serviceInstance = (EurekaServiceInstance) productService.get(0);由于只有一个服务实例,因此并不会有问题,但是如果一个服务有多个实例,就会出现问题。
1 如何在IDEA中启动一个服务的多个实例
点击页面下方的Services:
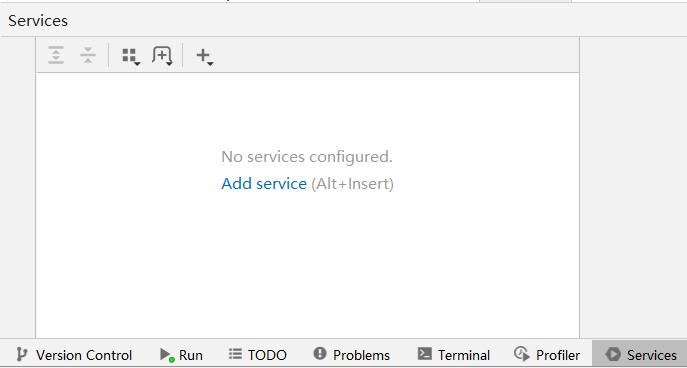
点击Add service,选择正在运行的SpringBoot服务:
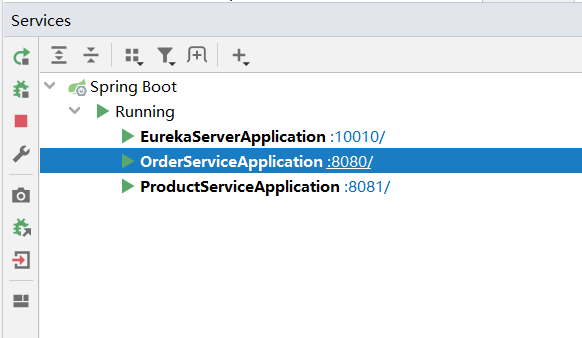
右键要复制实例的服务,点击复制:
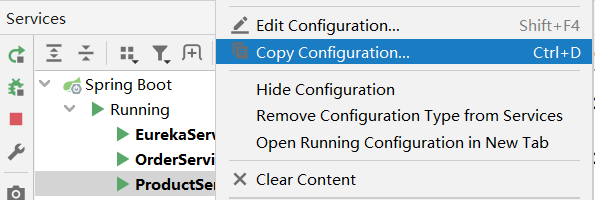
在打开的界面点击Modify options,选择Add VM options:
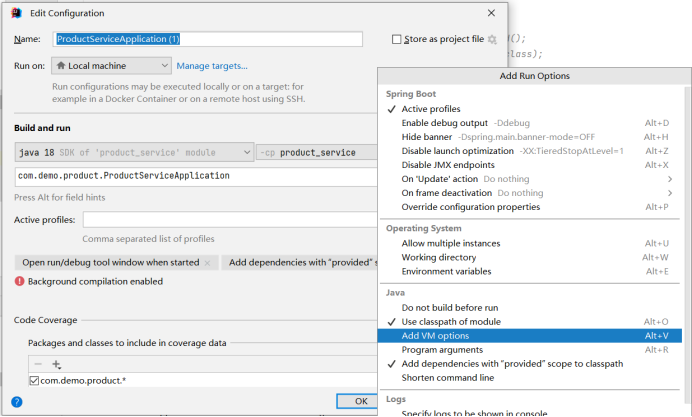
输入-Dserver.port=端口号,这里的端口号注意不要重复,之后选中创建的实例右键运行即可:
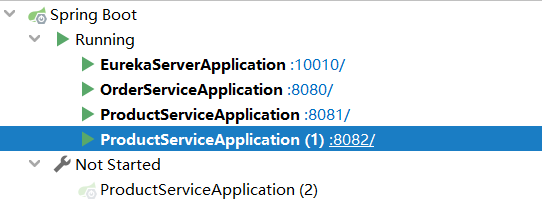
2 负载均衡
创建多个实例后,多次访问接口就会出现始终访问端口号为同一个的实例,这是因为服务发现时Eureka给我们提供随机的服务列表,但是每次都只获取其中下标为0的服务实例,这就会导致某个实例负载过大,因此需要负载均衡。
如果不借助组件,可以用hash取余的方式来轮询访问每个服务实例:
private static AtomicInteger atomicInteger = new AtomicInteger(1);private static List<ServiceInstance> instances;@PostConstructpublic void init(){//根据应用名称获取服务列表instances = discoveryClient.getInstances("product-service");}public OrderInfo selectOrderById(Integer orderId) {OrderInfo orderInfo = orderMapper.selectOrderById(orderId);//String url = "http://127.0.0.1:8081/product/"+ orderInfo.getProductId();//服务可能有多个, 轮询获取实例int index = atomicInteger.getAndIncrement() % instances.size();ServiceInstance instance =instances.get(index);log.info(instance.getInstanceId());//拼接urlString url = instance.getUri()+"/product/"+ orderInfo.getProductId();ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}这里把discoveryClient.getInstances()放到了方法外面,类加载时只获取一次,防止每次获取的服务列表顺序都不一样,同时节省网络资源。由于多线程环境下,为避免线程安全问题,使用原子类来计算hash取余。这种方式就是一种负载均衡,是一种客户端负载均衡。
但是上述代码有一些不足之处:服务一旦启动,服务发现一次,其余时间不再服务发现,因此对于服务的注册和下线是无感知的。于是需要一些专业实现负载均衡的组件,分为客户端负载均衡和服务端负载均衡:
服务端负载均衡:在服务端进行负载均衡算法分配。比如使用Nginx作为负载均衡器,请求先进入Nginx再由Nginx进行负载均衡算法选择服务来进行访问。
客户端负载均衡:由客户端服务发现后,根据负载均衡算法选择一个服务,并向该服务发送请求。比如Spring Cloud LoadBalancer(Spring Cloud维护)。
3 Spring Cloud LoadBalancer实现负载均衡
3.1 添加注解@LoadBalanced
在负责远程调用的对象restTemplate上添加@LoadBalanced注解,表示客户端调用时开启负载均衡(即客户端负载均衡):
@Configurationpublic class BeanConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}}3.2 修改远程调用的ip:端口号为服务名称
@Servicepublic class OrderService {@Autowiredprivate OrderMapper orderMapper;@Autowiredprivate RestTemplate restTemplate;public OrderInfo selectOrderById(Integer orderId) {OrderInfo orderInfo = orderMapper.selectOrderById(orderId);//负载均衡String url = "http://product-service/product/" + orderInfo.getProductId();ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}}多次发送请求,发现请求被负载均衡到了各个服务上:
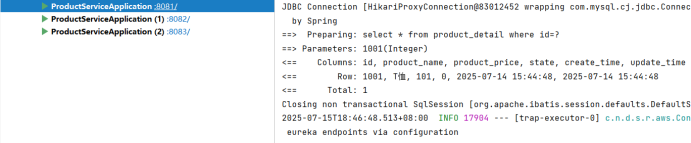


4 Spring Cloud LoadBalancer负载均衡策略
LoadBalancer默认采用轮询方式进行负载均衡,但是也支持随机选择策略。要使用随机选择策略,需要自定义负载均衡策略器:
public class LoadBalancerConfig {@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);System.out.println("==============" + name);return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name,ServiceInstanceListSupplier.class), name);}}注意:该策略器不能加@Configuration注解,并且要在Spring组件扫描范围中(即默认和启动类同一级目录下)。
接着,在RestTemplate配置类上面添加@LoadBalancerClient注解(一个服务提供者使用)或@LoadBalancerClients注解(多个服务提供者使用):
@LoadBalancerClient(name = "product-service", configuration = LoadBalancerConfig.class)@Configurationpublic class BeanConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}}@LoadBalancerClient的name表示服务名称,configuration则是定义的负载均衡策略器。
5 Spring Cloud LoadBalancer负载均衡原理
LoadBalancer最关键的源码是LoadBalancerInterceptor类,该类定义拦截器,将所有请求进行拦截并解析处理。具体的调用流程图如下:
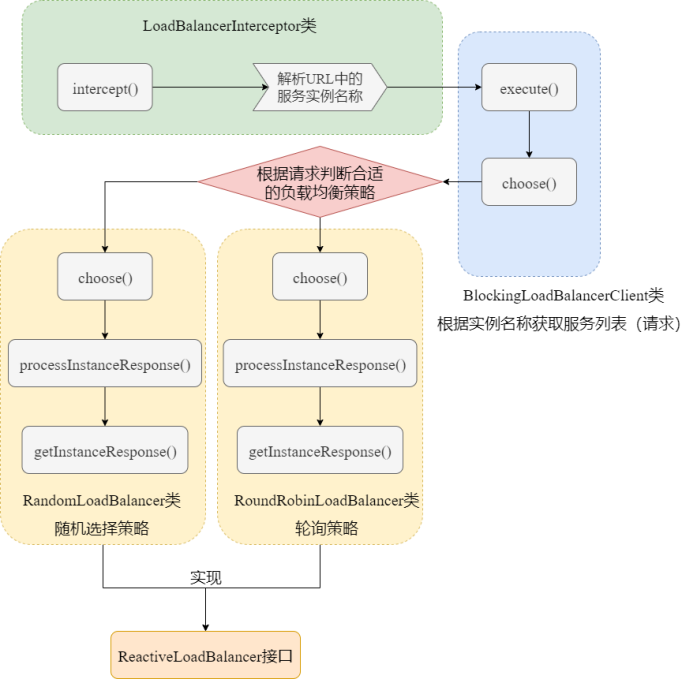
具体是LoadBalancerInterceptor类的intercept()发挥作用:
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException {URI originalUri = request.getURI();String serviceName = originalUri.getHost();//解析URL是否合法(.-等连接方式)Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);//execute()方法根据服务名称来对请求进行增强(负载均衡)return (ClientHttpResponse)this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));}execute()的实现是BlockingLoadBalancerClient类,具体作用就是根据服务实例名称(serviceId)来服务发现,并选择合适的负载均衡策略来选择对应的服务实例:
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {String hint = this.getHint(serviceId);LoadBalancerRequestAdapter<T, TimedRequestContext> lbRequest = new LoadBalancerRequestAdapter(request, this.buildRequestContext(request, hint));Set<LoadBalancerLifecycle> supportedLifecycleProcessors = this.getSupportedLifecycleProcessors(serviceId);supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onStart(lbRequest);});//choose()是核心方法,就是获取服务实例并根据负载均衡策略来返回具体请求的实例。ServiceInstance serviceInstance = this.choose(serviceId, lbRequest);if (serviceInstance == null) {supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onComplete(new CompletionContext(Status.DISCARD, lbRequest, new EmptyResponse()));});throw new IllegalStateException("No instances available for " + serviceId);} else {return this.execute(serviceId, serviceInstance, lbRequest);}}这个choose()方法也是BlockingLoadBalancerClient类实现的,内部调用了ReactiveLoadBalancer接口的choose()方法来进行负载均衡策略的选择:
public <T> ServiceInstance choose(String serviceId, Request<T> request) {//获取服务实例列表loadBalancer,也就是负载均衡器ReactiveLoadBalancer<ServiceInstance> loadBalancer = this.loadBalancerClientFactory.getInstance(serviceId);if (loadBalancer == null) {return null;} else {//根据负载均衡算法选择合适的实例Response<ServiceInstance> loadBalancerResponse = (Response)Mono.from(loadBalancer.choose(request)).block();return loadBalancerResponse == null ? null : (ServiceInstance)loadBalancerResponse.getServer();}}loadBalancer.choose()的choose()方法是ReactiveLoadBalancer接口的choose()方法,该方法的实现有RandomLoadBalancer类实现的方法和RoundRobinLoadBalancer类实现的方法,这两个类实现的choose()方法分别对应随机选择策略和轮询策略。
在RandomLoadBalancer类中,choose()方法调用processInstanceResponse()方法,processInstanceResponse()调用getInstanceResponse()方法,最终在getInstanceResponse()方法可以看到通过随机数来选择随机的服务实例进行访问,即随机选择策略:
public Mono<Response<ServiceInstance>> choose(Request request) {ServiceInstanceListSupplier supplier = (ServiceInstanceListSupplier)this.serviceInstanceListSupplierProvider.getIfAvailable(NoopServiceInstanceListSupplier::new);return supplier.get(request).next().map((serviceInstances) -> {return this.processInstanceResponse(supplier, serviceInstances);});}private Response<ServiceInstance> processInstanceResponse(ServiceInstanceListSupplier supplier, List<ServiceInstance> serviceInstances) {Response<ServiceInstance> serviceInstanceResponse = this.getInstanceResponse(serviceInstances);if (supplier instanceof SelectedInstanceCallback && serviceInstanceResponse.hasServer()) {((SelectedInstanceCallback)supplier).selectedServiceInstance((ServiceInstance)serviceInstanceResponse.getServer());}return serviceInstanceResponse;}private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) {if (instances.isEmpty()) {if (log.isWarnEnabled()) {log.warn("No servers available for service: " + this.serviceId);}return new EmptyResponse();} else {//此处就是随机选择策略最关键的几行代码int index = ThreadLocalRandom.current().nextInt(instances.size());ServiceInstance instance = (ServiceInstance)instances.get(index);return new DefaultResponse(instance);}}RoundRobinLoadBalancer类的choose方法也采用了一样的方法调用链,最终在getInstanceResponse()方法中,实现了本文的“负载均衡”部分的hash取余来轮询选择服务实例的方式:
public Mono<Response<ServiceInstance>> choose(Request request) {ServiceInstanceListSupplier supplier = (ServiceInstanceListSupplier)this.serviceInstanceListSupplierProvider.getIfAvailable(NoopServiceInstanceListSupplier::new);return supplier.get(request).next().map((serviceInstances) -> {return this.processInstanceResponse(supplier, serviceInstances);});}private Response<ServiceInstance> processInstanceResponse(ServiceInstanceListSupplier supplier, List<ServiceInstance> serviceInstances) {Response<ServiceInstance> serviceInstanceResponse = this.getInstanceResponse(serviceInstances);if (supplier instanceof SelectedInstanceCallback && serviceInstanceResponse.hasServer()) {((SelectedInstanceCallback)supplier).selectedServiceInstance((ServiceInstance)serviceInstanceResponse.getServer());}return serviceInstanceResponse;}private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) {if (instances.isEmpty()) {if (log.isWarnEnabled()) {log.warn("No servers available for service: " + this.serviceId);}return new EmptyResponse();} else if (instances.size() == 1) {return new DefaultResponse((ServiceInstance)instances.get(0));} else {//通过hash取余的方式来轮询选择服务实例int pos = this.position.incrementAndGet() & Integer.MAX_VALUE;ServiceInstance instance = (ServiceInstance)instances.get(pos % instances.size());return new DefaultResponse(instance);}}下篇文章:
Spring Cloud系列—Nacos服务注册/发现![]() https://blog.csdn.net/sniper_fandc/article/details/149938785?fromshare=blogdetail&sharetype=blogdetail&sharerId=149938785&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
https://blog.csdn.net/sniper_fandc/article/details/149938785?fromshare=blogdetail&sharetype=blogdetail&sharerId=149938785&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link



Python爬虫入门教程:从零开始学习网页抓取(爬虫教学)(Python教学))






到大语言模型落地手记(RAG/Agent/MCP),一场耗时5+3年的技术沉淀—“代码可跑,经验可抄”—【一个处女座的程序猿】携两本AI)

--使用CUB库实现基本功能)

)
)

ARM体系架构)

