spark 基础问题面试题
以下是 Spark 基础面试题的全面梳理,涵盖核心概念、架构原理和编程模型,帮助快速掌握高频考点:
一、核心概念
1. Spark 核心组件
| 组件 | 作用 |
|---|---|
| Driver | 执行 main() 方法,调度任务,管理集群资源 |
| Executor | 在 Worker 节点执行 Task,缓存数据 |
| Cluster Manager | 管理集群资源(YARN/Mesos/Standalone) |
| RDD | 分布式数据集的抽象(弹性、不可变、可分区的集合) |
2. RDD 五大特性
图表
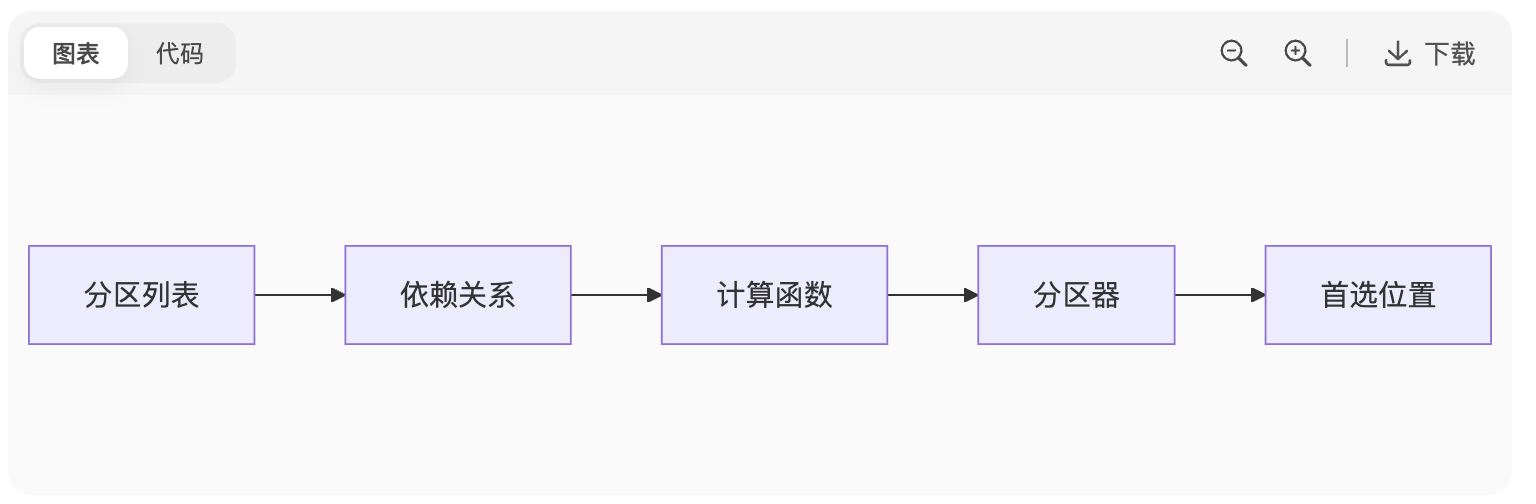
代码
分区(Partitions)、依赖(Dependencies)、计算函数(Compute)、分区器(Partitioner)、首选位置(Preferred Locations)
3. 宽窄依赖
| 类型 | 特点 | 例子 |
|---|---|---|
| 窄依赖 | 1个父RDD分区 → 1个子RDD分区 | map(), filter() |
| 宽依赖 | 1个父RDD分区 → N个子RDD分区(需Shuffle) | groupByKey(), reduceByKey() |
二、执行流程
4. Spark 任务提交流程
Driver 创建
SparkContext向 Cluster Manager 申请资源
Cluster Manager 启动 Executor
Driver 将 DAG 拆分为 Task
Executor 执行 Task 并返回结果
5. Stage 划分原理
触发条件:遇到宽依赖(Shuffle)时切割 Stage
Stage 类型:
ShuffleMapStage:输出 Shuffle 数据
ResultStage:执行 Action 算子(如
count(),collect())
6. Shuffle 过程
图表
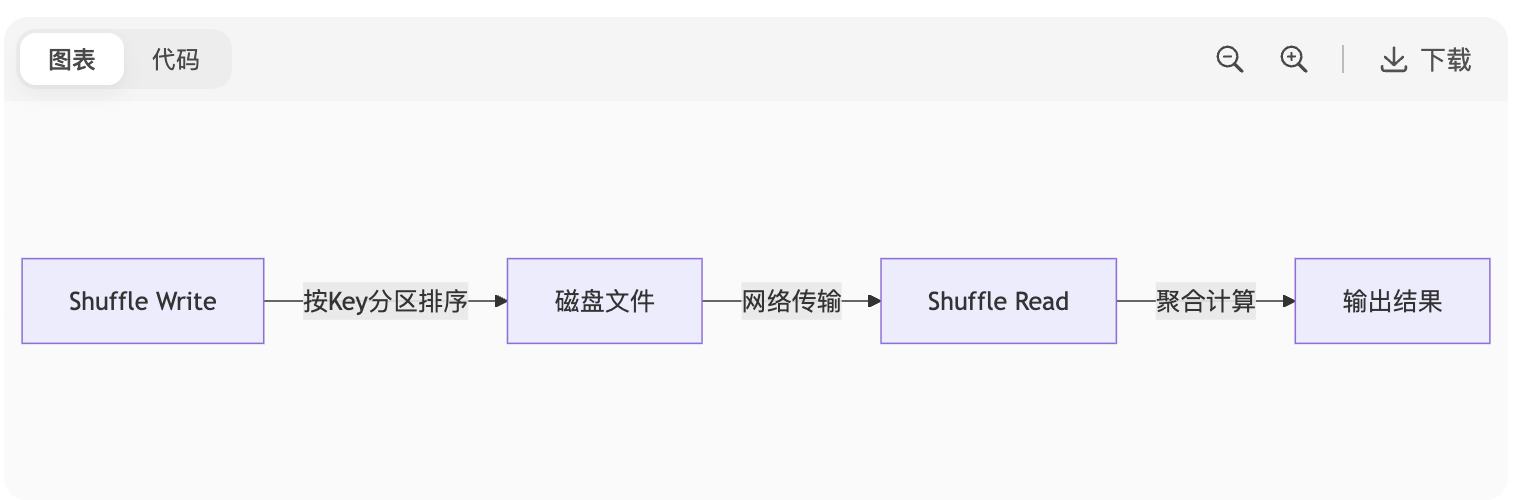
代码
优化点:减少数据传输量(
reduceByKey>groupByKey)
三、编程模型
7. Transformation vs Action
| 类型 | 特点 | 例子 |
|---|---|---|
| Transformation | 惰性执行,生成新RDD | map(), filter(), join() |
| Action | 触发Job执行,返回结果 | count(), saveAsTextFile(), collect() |
8. 持久化方法对比
| 方法 | 存储级别 | 是否保留血缘 |
|---|---|---|
cache() | MEMORY_ONLY | 保留 |
persist() | 可指定(如 MEMORY_AND_DISK) | 保留 |
checkpoint() | 可靠存储(HDFS) | 切断血缘 |
9. 广播变量 vs 累加器
| 特性 | 广播变量 | 累加器 |
|---|---|---|
| 用途 | 只读共享大变量 | 分布式计数器 |
| 修改权限 | Executor 只读 | Executor 累加,Driver 读取 |
| 场景 | 字典表、配置参数 | 统计异常记录数 |
四、部署与资源
10. 部署模式对比
| 模式 | 特点 | 适用场景 |
|---|---|---|
| Local | 单机多线程调试 | 开发测试 |
| Standalone | Spark自带资源调度 | 中小规模集群 |
| YARN | 集成Hadoop资源管理 | 生产环境(主流) |
| Kubernetes | 容器化部署 | 云原生架构 |
11. 资源参数配置
bash
spark-submit \--master yarn \--num-executors 10 \ # Executor数量--executor-cores 4 \ # 每个Executor的CPU核数--executor-memory 8g \ # 每个Executor的内存--driver-memory 2g # Driver内存
五、高频考点
12. RDD vs DataFrame vs Dataset
| 特性 | RDD | DataFrame | Dataset |
|---|---|---|---|
| 类型安全 | 是 | 否 | 是 |
| 优化能力 | 无 | Catalyst优化器支持 | 支持 |
| 序列化 | Java序列化 | Tungsten二进制格式 | Tungsten二进制格式 |
13. Spark SQL 执行流程
将 SQL 解析为逻辑计划
Catalyst 优化器进行规则优化(谓词下推、列裁剪)
生成物理计划并执行
14. 常见算子作用
coalesce():减少分区数(无Shuffle)repartition():调整分区数(触发Shuffle)sample():数据采样union():合并两个RDD(不去重)
六、故障排查基础
15. OOM(内存溢出)原因
Driver OOM:
collect()拉取数据过多Executor OOM:
数据倾斜导致单Task负载过高
persist()缓存数据超出内存
16. Shuffle Fetch Failed 错误
原因:Executor 宕机或 GC 超时
解决:增加超时时间
spark.network.timeout=300s
附:基础代码示例
scala
// 创建RDD
val rdd = sc.parallelize(List(1, 2, 3, 4, 5))// Transformation: 过滤偶数
val evenRDD = rdd.filter(_ % 2 == 0)// Action: 计数并打印
println(evenRDD.count()) // 输出: 2// 广播变量使用
val broadcastVar = sc.broadcast(Map("a" -> 1, "b" -> 2))
rdd.map(x => broadcastVar.value.getOrElse(x.toString, 0)).collect()💡 面试技巧:
被问及概念时,先给出定义,再说明应用场景(如:”宽依赖在Shuffle时发生,典型场景是groupByKey“)
遇到原理题,结合流程图描述(如DAG划分、Shuffle过程)
牢记核心参数作用(如
num-executors,executor-cores)
spark 面试题
以下是针对Spark面试的核心知识点梳理及高频考题解析,结合企业实际需求和性能调优经验整理而成,助你系统准备:
一、核心概念与架构
Spark vs MapReduce 效率对比
内存计算:中间数据优先内存存储,减少磁盘I/O(MapReduce需落盘)14
DAG调度:将任务拆解为有向无环图,优化执行路径;MapReduce仅两阶段(Map+Reduce)38
容错机制:RDD血缘(Lineage)自动恢复丢失数据;MapReduce需任务重跑16
RDD(弹性分布式数据集)
五大特性:
分区容错(自动分区恢复)
血缘追溯(Lineage重建丢失数据)
存储弹性(内存不足时自动溢写磁盘)
计算弹性(Task/Stage自动重试)
分片弹性(动态调整分区数)28
缺陷:不支持细粒度更新(如单条记录修改),仅适合批处理8
部署模式
模式 特点 适用场景 Local 单机多线程调试,无集群资源管理 开发测试 Standalone Spark自带资源调度,Master单点故障需ZK支持 中小集群 YARN 资源由YARN管理,支持Cluster(生产)和Client(调试)模式 Hadoop生态集成 Mesos 细粒度资源分配(按需调度),但配置复杂 动态资源场景 68
二、调度与执行机制
Stage划分原理
宽窄依赖:
窄依赖(Narrow):1父分区 → 1子分区(如
map、filter),同Stage内流水线执行宽依赖(Wide):1父分区 → N子分区(如
groupByKey),需Shuffle并划分新Stage23
划分算法:从Action算子反向回溯,遇宽依赖则切割Stage4
Shuffle机制详解
过程:
Shuffle Write:Map端按Key分区,排序后溢写磁盘文件
Shuffle Read:Reduce端拉取数据,聚合后计算38
优化:
避免
groupByKey→ 改用reduceByKey(Map端预聚合)调整分区数:
spark.sql.shuffle.partitions(默认200,按数据量调优)78
内存管理
统一内存模型(Unified Memory):
Execution内存(计算):Shuffle/Join等临时数据
Storage内存(存储):缓存RDD数据
两者可动态抢占,避免OOM6
调参:
spark.memory.fraction(默认0.6,总JVM内存占比)8
三、性能优化实战
数据倾斜解决
现象:个别Task耗时远高于其他
方案:
两阶段聚合:加随机前缀局部聚合 → 全局聚合
热点Key分离:单独处理或使用
salting(添加随机后缀)开启倾斜处理:
spark.sql.adaptive.skewedJoin.enabled=true(Spark 3.0+)47
算子选择原则
优先
reduceByKey>groupByKey(减少Shuffle数据量)用
mapPartitions替代map(减少函数调用开销)避免
collect()全量拉数据 → 改用take(N)或输出到存储系统7
持久化策略
机制 存储位置 血缘保留 适用场景 cache/persist 内存/磁盘 保留 频繁访问的中间RDD checkpoint HDFS等可靠存储 切断 长血缘依赖的容错恢复 34
四、容错与高级特性
Master HA实现
ZooKeeper存储:Application、Worker、Driver元数据2
主备切换:不影响运行中任务(Driver与Executor直连)24
广播变量与累加器
广播变量:只读缓存大对象(如字典表),避免Task重复传输7
累加器:分布式计数器(如统计异常记录数),仅Driver可读1
Spark Streaming容错
Checkpoint:定时保存DStream血缘及元数据至HDFS
WAL预写日志:接收数据后先写日志再处理4
五、编程实践与SQL优化
Spark SQL性能优势
Catalyst优化器:逻辑计划优化(谓词下推、列裁剪)
Tungsten引擎:堆外内存管理 + 代码生成5
DataFrame vs SQL
DataFrame优势:
编译时类型安全
链式调用优化更友好
支持DSL复杂操作4
典型代码示例
scala
// WordCount实现 val textFile = sc.textFile("hdfs://path/to/file") val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) counts.saveAsTextFile("hdfs://output")// TopN获取(按频次降序) val topN = counts.map(_.swap).sortByKey(false).take(N)
附:高频扩展题
解释
coalesce与repartition区别?(coalesce无Shuffle缩分区,repartition强制Shuffle)7为何Executor会Full GC?(堆内存不足或对象未释放;调大
spark.executor.memoryOverhead)6Spark on YARN下Container如何复用?(Yarn Container不支持复用,每次任务启动新Container)8
💡 提示:面试中常结合场景深度追问(如“百亿数据JOIN如何优化?”),建议准备1-2个调优实战案例,重点说明问题定位→解决策略→效果量化(如:“两阶段聚合解决数据倾斜,耗时从2小时降至20分钟”)。
spark 性能调优面试题
以下是 Spark 性能调优的高频面试题及深度解析,涵盖原理、实战场景和解决方案,帮助你在面试中展现调优思维:
一、核心调优方向
1. 数据倾斜(Data Skew)
问题现象:少数 Task 处理时间远超其他 Task(如 99% Task 1min 完成,1个 Task 卡 1h)。
解决方案:
加盐打散:对热点 Key 添加随机前缀(
concat(key, '_', rand()%10)),先局部聚合再全局聚合。
scala
// 第一阶段:加盐局部聚合 val saltedRDD = rdd.map(key => (s"${key}_${Random.nextInt(10)}", 1)) val partialAgg = saltedRDD.reduceByKey(_ + _)// 第二阶段:去盐全局聚合 val restoredRDD = partialAgg.map{ case (saltedKey, count) => val key = saltedKey.split("_")(0)(key, count) } val finalResult = restoredRDD.reduceByKey(_ + _)分离热点数据:单独处理热点 Key(
filter拆分 → 分别计算 →union)。开启 AQE(Spark 3.0+):
spark.sql.adaptive.skewedJoin.enabled=true自动拆分倾斜分区。
2. Shuffle 优化
核心问题:Shuffle 写磁盘 + 网络传输是最大瓶颈。
调优手段:
减少 Shuffle 数据量:
避免
groupByKey→ 改用reduceByKey(Map 端预聚合)。使用
broadcast join替代shuffle join(小表 < 10MB)。
调整分区数:
合理设置
spark.sql.shuffle.partitions(默认200,建议:集群核数*2~4)。动态分区:
spark.sql.adaptive.enabled=true(AQE 自动合并小分区)。
选择 Shuffle 管理器:
SortShuffleManager(默认,支持压缩) >HashShuffleManager(易 OOM)。
3. 内存管理
堆内存结构:
图表
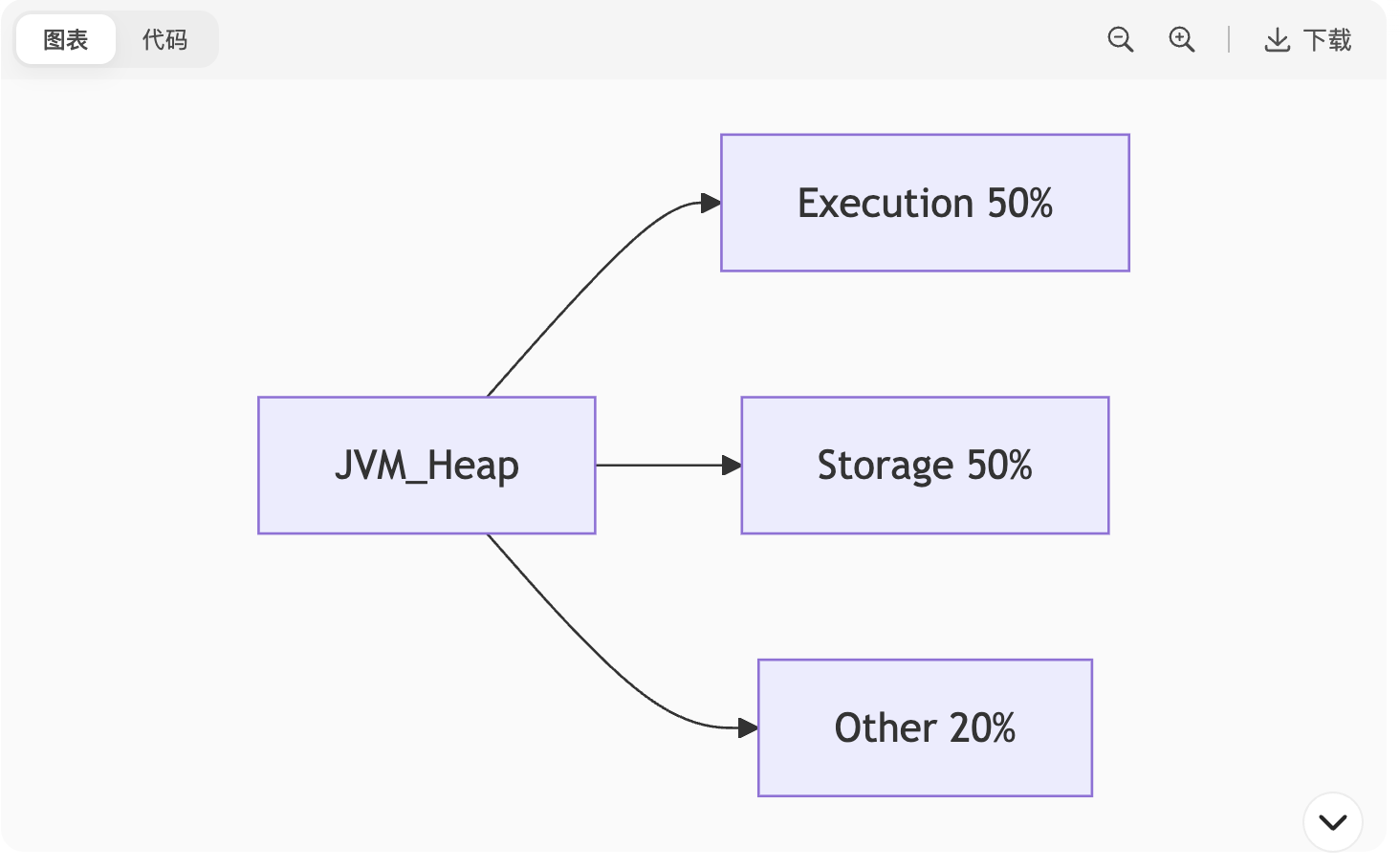
关键参数:
参数 作用 推荐值 spark.executor.memoryExecutor 总内存 根据集群调整 spark.memory.fractionExecution+Storage 占比 0.6~0.8 spark.storage.memoryFractionStorage 内存占比 0.3~0.5 OOM 解决:
增加
spark.executor.memoryOverhead(堆外内存,默认 executor-memory * 0.1)。
二、执行效率优化
4. 执行计划优化
查看执行计划:
scala
df.explain("extended") // 展示逻辑/物理计划Catalyst 优化器生效点:
谓词下推(Predicate Pushdown):提前过滤数据。
列裁剪(Column Pruning):仅读取必要列。
强制广播:
spark.sql.autoBroadcastJoinThreshold=10485760(10MB)。
5. 资源并行度
黄金公式:
text
总并行度 = Executor 数 * 每个 Executor 的 core 数
参数配置:
参数 说明 优化建议 spark.executor.instancesExecutor 数量 根据数据量调整 spark.executor.cores每个 Executor 的 CPU 核数 4~8 spark.default.parallelismRDD 默认分区数 设为总 core 数 2~3 倍
6. 数据读写优化
输入数据:
优先使用 Parquet/ORC(列式存储 + 谓词下推)。
避免小文件:
spark.sql.files.maxPartitionBytes=128MB(合并小文件)。
输出数据:
用
coalesce减少输出文件数(无 Shuffle)。禁用生成
_SUCCESS文件:spark.hadoop.mapreduce.fileoutputcommitter.marksuccessfuljobs=false。
三、高级调优技巧
7. Join 优化策略
| Join 类型 | 适用场景 | 调优手段 |
|---|---|---|
| Broadcast Join | 小表 + 大表 | 自动触发或手动 hint |
| Sort Merge Join | 大表 + 大表 | 确保分区有序 |
| Bucket Join | 预分桶表 | 创建分桶表 CLUSTERED BY |
8. 序列化优化
Kryo 序列化:
scala
spark.conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") spark.conf.registerKryoClasses(Array(classOf[MyClass]))效果:比 Java 序列化快 10 倍,体积小 50%。
9. AQE(自适应查询执行)
Spark 3.0+ 核心特性:
scala
spark.sql("SET spark.sql.adaptive.enabled=true")功能:
动态合并小分区(
Coalesce Shuffle Partitions)。倾斜 Join 自动优化(
Optimize Skewed Join)。运行时调整 Join 策略(
Demote BroadcastHashJoin)。
四、故障排查实战题
10. 慢 Task 定位
步骤:
查看 Spark UI 定位慢 Task 所在 Stage。
检查该 Task 的 GC 时间(是否频繁 Full GC)。
分析输入数据量(是否数据倾斜)。
工具:
spark.eventLog.enabled=true记录日志。使用 Spark History Server 离线分析。
11. Shuffle Fetch Failed
错误原因:
Executor 宕机导致 Shuffle 数据丢失。
GC 停顿超时(默认 60s)。
解决方案:
增加超时:
spark.network.timeout=300s。减少 GC:切 G1 垃圾回收器。
bash
--conf "spark.executor.extraJavaOptions=-XX:+UseG1GC"
调优思维回答模板
面试官:”如果遇到 Spark 作业运行缓慢,你会如何排查?“
回答框架:
定位瓶颈:通过 Spark UI 分析 Stage/Task 耗时,确认是 Shuffle、计算还是 IO 问题。
数据倾斜检查:观察 Task 数据分布,用
df.stat.approxQuantile检测 Key 分布。内存分析:检查 GC 日志,调整内存比例或切 G1 回收器。
优化执行:启用 AQE、广播小表、避免
collect全量拉取。资源调整:根据数据量动态增加 Executor 或 core 数。
案例佐证:”曾优化某 Join 作业,通过广播表+AQE 倾斜处理,从 2h 降至 20min“。
掌握这些核心点,你将能系统性应对 90% 的 Spark 调优面试问题!









)


![[LVGL] 布局系统 lv_flex, lv_grid | 输入设备 lv_indev | union](http://pic.xiahunao.cn/[LVGL] 布局系统 lv_flex, lv_grid | 输入设备 lv_indev | union)


)
系统可靠性设计)


