prompt
提示词的构成:
- 指示:描述让它做什么
- 上下文:给出与任务相关的背景信息
- 输入: 任务的输入信息
- 输出:输出的格式
生成与检索
生成:
- 优点:内容的多样性、创造性
- 缺点:存在不可控制
检索: - 优点:可控
- 缺点:内容的边界有限制
通过RAG结合生成与检索
智能客服
传统方法+检索:
- 设置很多Q(问题),A(答案)对库
- 当一个问题到来,比较Query和库中的那个Q最接近,则回答对应的答案
传统方法+生成:
- 通过Q,A对训练一个模型
- 使用时给一个Q,输出一个答案
大模型方法(检索+生成):
- 创建一个知识库(中间有各种各样的文档)
- 用户给了一个Q,在知识库中检索相关的内容(candidate)
- 把检索到的内容和Q以及message(过去的信息)放到prompt中
- 将prompt放入LLm生成答案
知识库的搭建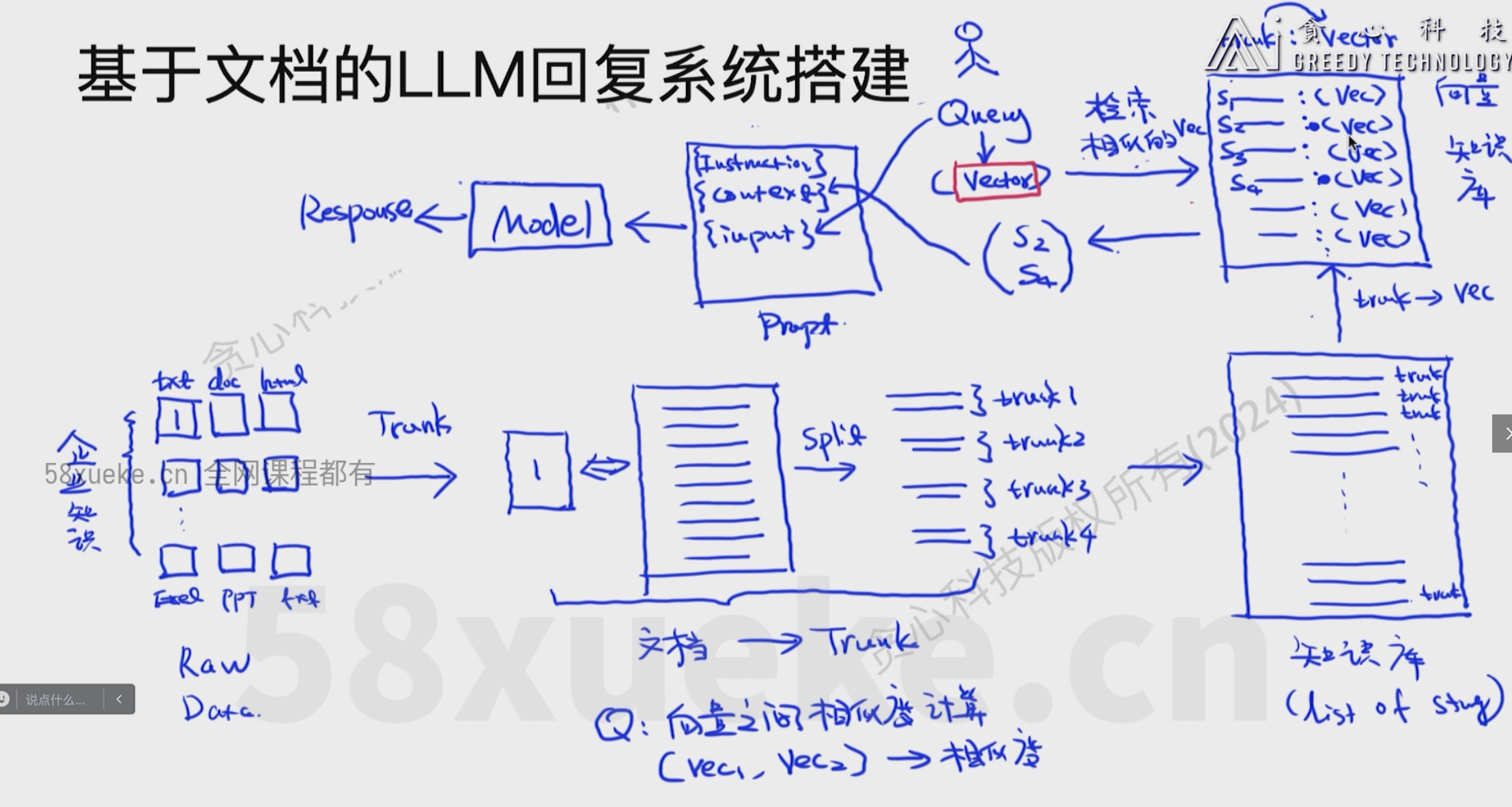
- 收集很多相关文档
- 将每个文档都分割成若干个trunk得到完整的知识库
- 将trunk转化为向量,得到向量库
- 将Q进行向量化
- 找到和Q相关的trunk,将相关的trunk和Q放入prompt中
把文本切分成Trunks
- 根据句子切分
- 按照字符数切分
- 按固定字符数,结合overlapping window(紧挨着的两个trunk末尾和开头有一定的重叠)
- 递归方法(按字符切分,考虑语义)
- 根据语义分割
倒排索引

- 将Query进行切分
- 查找切分的Query每个部分出现的文档列表
- 找到特定几个比较重要的文档列表的并集
- 进行排序
快速搜索向量
KNN搜索
将Q的向量和向量库中的向量一一对比,计算距离或相似度
精确度高,速度慢,适合小数据集
近似KNN算法
- 将数据分成若干模块,每个模块有个中心点
- 查找和query最近的中心点
- 计算中心点所在区域中所有点和Query的距离
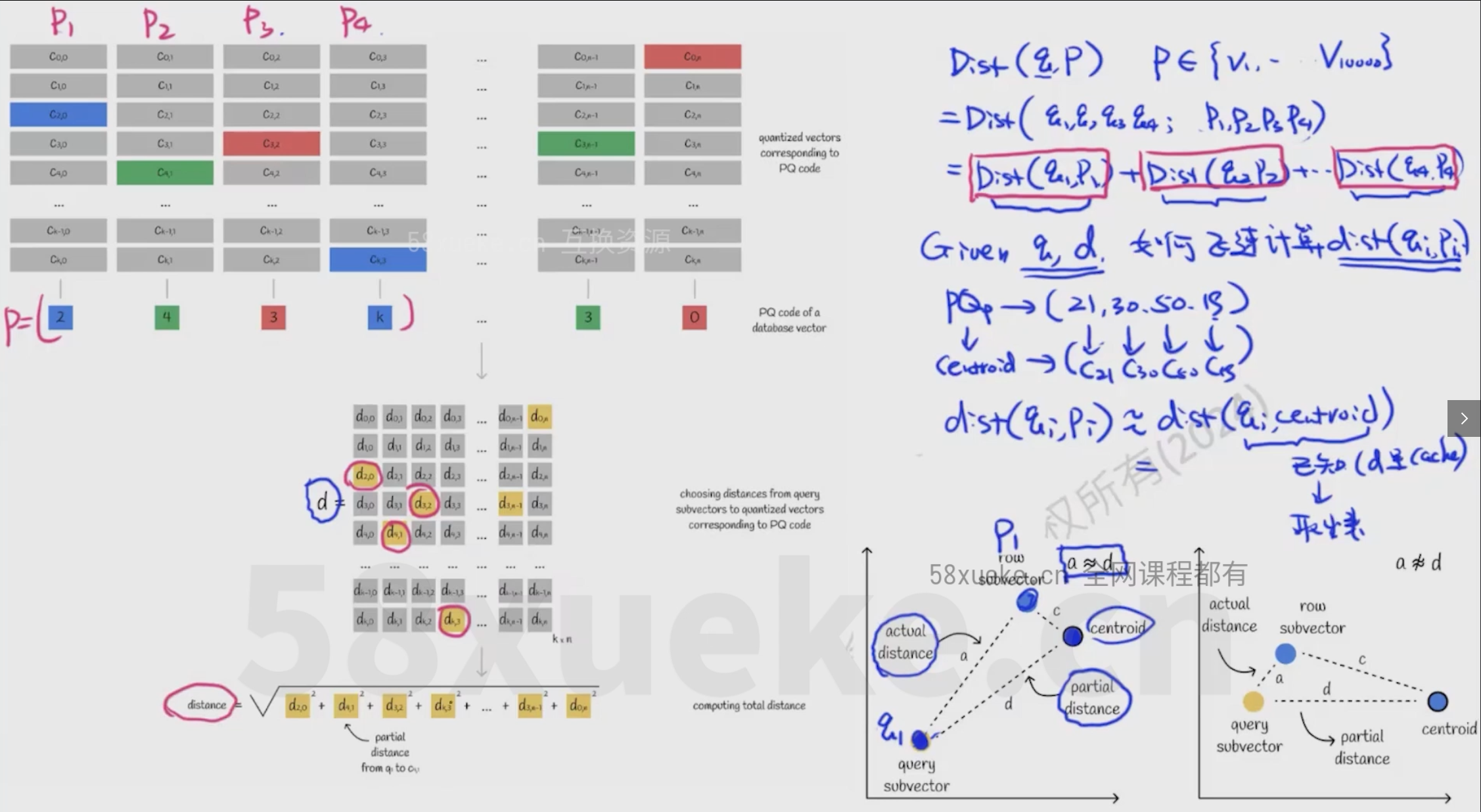
Product Quantization(PQ)
- 将向量切分成几段短向量(例如长为256的短向量)
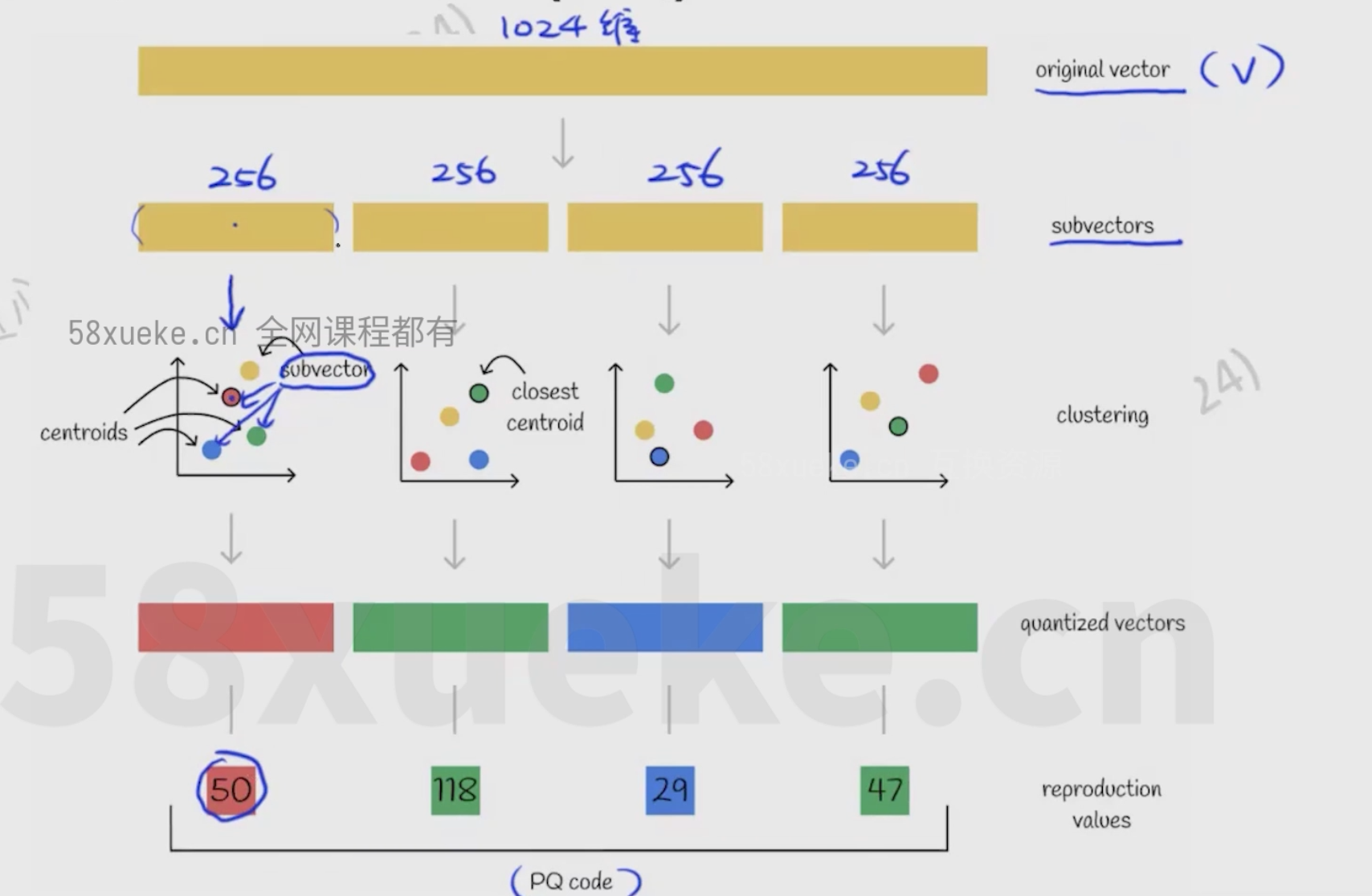
- 将长为256的短向量划分为若干区域,每个区域对应一个ID
- 将Q切分后的短向量和每个区域中心点进行计算距离
- 将Q切分后的短向量转换为区域中心距离最近的区域的ID
- 将生成的ID没向量库中的向量的ID进行对比计算距离

Optimized Approach(改进PQ)
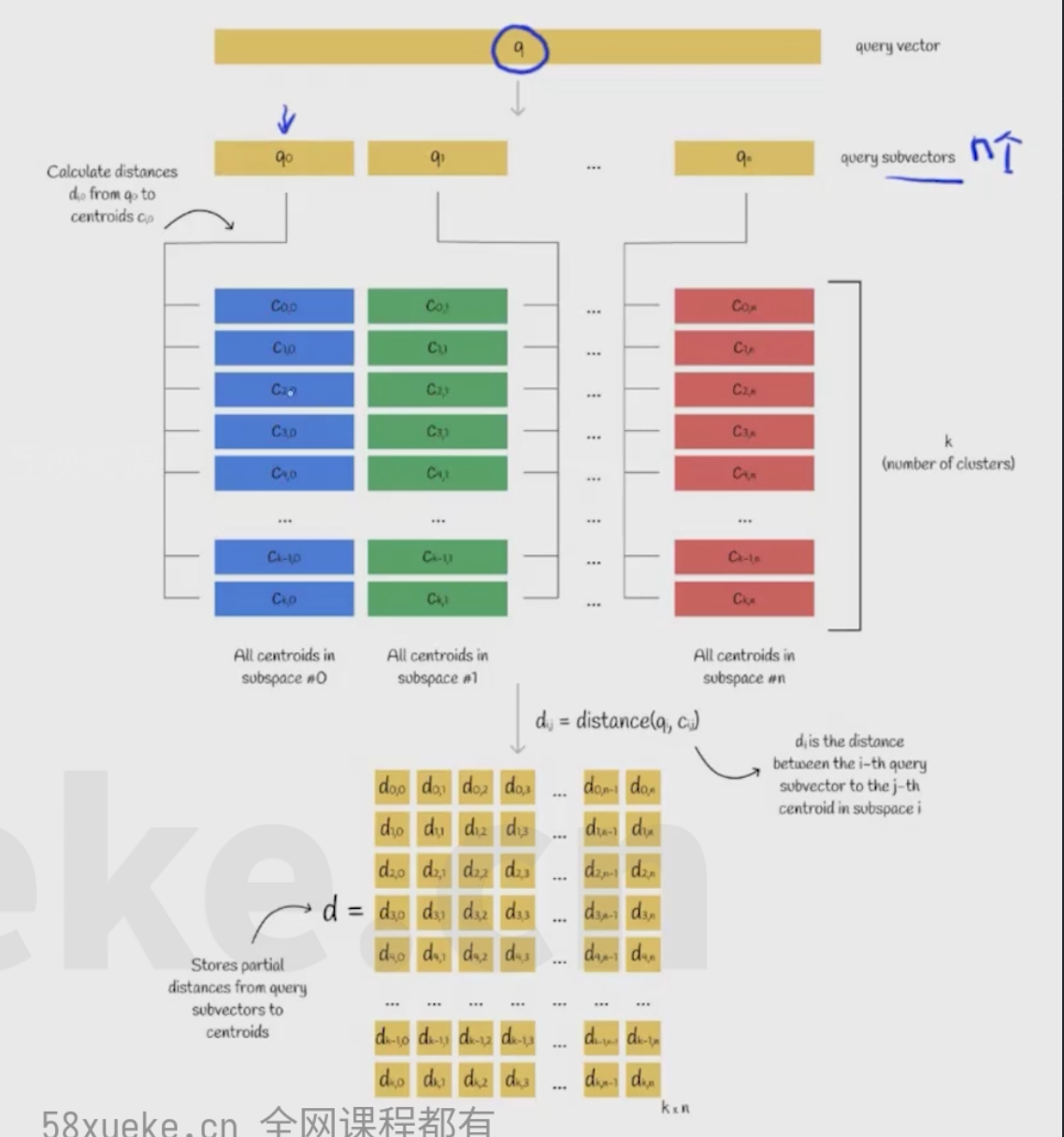
- 将Q分解成n段,有k个中心点
- 将Q的每段和每个中心点对应的小段计算距离,得到一个k×n的矩阵
- 将向量库的向量和Q的距离近似为距离这个向量最近的中心点和Q的距离
- 计算出中心点的距离即为这个向量和Q的距离
langchain
langchain是面向大模型开发的框架
Langchain的核心组件
-
模型I/O封装:包括大预言模型,chat Model,Prompt Template,output parser等
-
Retrieval:包括文档的loader,embedding模型,Text Splitter,向量存储,检索等
-
chain: 实现一个功能或者一系列功能
-
Agent: 给定用户的输入,以及可使用的tools,自动规划执行步骤(比如每个步骤调用哪些tool),并最终完成用户指令
-
记忆: 模型记忆里的管理
-
Prompt Template:管理和格式化提示词
-
chains: 串联多步流程
-
Memory:保存上下文,实现多轮对话
-
Retrieval+VectorStore :现在知识库检索,在生成回答
两种模型:
- non-chat model:非对话模型,给一句话,补全这句话
- chat model:对话模型
非Agent: 对于一个任务,明确指定每一步应该做什么
Agent: Agent的核心任务是将一个复杂的问题拆解成几个简单的任务
提示词工程
from langchain_openai.chat_models.base import BaseChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
# 初始化LLMllm = ChatOpenAI(model_name='gpt-3.5-turbo')template ='写一首描述{sence}的诗,格式要求为{type}'# 方法一,自动发现参数
prompt = PromptTemplate.from_template(template) #创建模板# 方法二,指定参数
prompt = PromptTemplate(template = template,input_variables = ['type','sence']
)chain = LLMChain(llm=llm, prompt=prompt)# 调用大模型
# 方法一
chain.predict(snece='春天',type='五言绝句') # 调用大模型# 方法二
chain.run({'sence':'秋天','type':'五言绝句'})
chain({'sence':'秋天','type':'五言绝句'}) # 底层也是调用chain.run# 方法三
chain.apply([{'sence':'秋天','type':'五言绝句'}])chain.generate([{'sence':'秋天','type':'五言绝句'}])
few shot
from dotenv import load_dotenv
load_dotenv()from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model='gpt-3.5-turbo-1106', temperature=0)from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplateexamples = [{'sence': '秋天', 'type': '五言绝句', 'text': '移舟泊烟渚,日暮客愁新。\n野旷天低树,江清月近人。'},{'sence': '冬天', 'type': '七言律诗', 'text': '昔人已乘黄鹤去,此地空余黄鹤楼。\n黄鹤一去不复返,白云千载空悠悠。\n晴川历历汉阳树,芳草萋萋鹦鹉洲。\n日暮乡关何处是?烟波江上使人愁。'},
]example_template = '这是一首描写{sence}的诗,格式为{type}:\n{text}'
example_prompt = PromptTemplate.from_template(example_template)
# 例子放在前缀和后缀之间
prompt = FewShotPromptTemplate(examples=examples,example_prompt=example_prompt,example_separator='\n\n',prefix='请分析以下诗歌的格式,并按格式要求创作诗歌。', # 前缀suffix='写一首描写{sence}的诗,格式要求为{type}:\n', # 后缀input_variables=['sence', 'type',]
)# print(prompt.format(sence='秋天', type='七言律诗'))chain = LLMChain(llm=llm, prompt=prompt)
result = chain.run({'sence':'夏天', 'type':'七言律诗'})
print(result)多个chain进行串联(组合链)
from dotenv import load_dotenv
load_dotenv()from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model='gpt-3.5-turbo-1106', temperature=0)from langchain.chains import LLMChain
from langchain.chains import SequentialChain
from langchain.prompts import PromptTemplateprompt1 = PromptTemplate.from_template('有一家公司的创始人叫{name},主要从事人工智能技术培训和科研辅导,请帮这家公司起10个中文名字,要求包含创始人的名字。'
)chain1 = LLMChain(llm=llm, prompt=prompt1, output_key='company_names', verbose=True)
# print(chain1.predict(name='陈华'))
# company_names = chain1.predict(name='陈华')prompt2 = PromptTemplate.from_template('请从以下公司名字中,选出你认为最好的一个:\n {company_names}'
)chain2 = LLMChain(llm=llm, prompt=prompt2, verbose=True)
# print(chain2.predict(company_names=company_names))chain = SequentialChain(chains=[chain1, chain2], input_variables=['name'], verbose=True)
result = chain.run({'name':'陈华'})
print(result)
内置组合链
from dotenv import load_dotenv
from langchain.chat_models import ChatOpenAIload_dotenv()
llm = ChatOpenAI(model='gpt-3.5-turbo-1106', temperature=0)# # 简单对话场景
# from langchain.chains import ConversationChain# conversation = ConversationChain(llm=llm, verbose=True)
# # print(conversation.prompt.template)# while True:
# human_input = input('User: ') # hello | 你叫什么名字?
# result = conversation.predict(input=human_input)
# print('Assistant: ', result)# 修改提示词
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplatetemplate = '''
下面是一段人类和人工智能之间的友好对话。人工智能是健谈的,并根据其上下文提供许多具体细节。如果人工智能不知道一个问题的答案,它就会如实说它不知道。
请注意,无论人类用什么语言,你都用中文进行回复。当前对话:
{history}
User:{input}
Assistant:
'''
prompt = PromptTemplate.from_template(template)conversation = ConversationChain(llm=llm, prompt=prompt, verbose=True)
# print(conversation.prompt.template)while True:human_input = input('User: ') # hello | 你叫什么名字? | 感冒吃什么药好得快?result = conversation.predict(input=human_input)print('Assistant: ', result)langchain Memory
随着提问的次数增加,Memory中存储的内容会越来越多,context中的token越来越多
解决方法:
只考虑n轮的Memory
对会话内容进行总结
from dotenv import load_dotenv
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import (ConversationBufferMemory,ConversationBufferWindowMemory,ConversationSummaryMemory,ConversationSummaryBufferMemory)load_dotenv()
llm = ChatOpenAI(model='gpt-3.5-turbo-1106')# memory = ConversationBufferWindowMemory(k=3)
# conversation = ConversationChain(llm=llm, memory=memory, verbose=True)# memory = ConversationBufferMemory() # 保留完整会话(默认)
# memory = ConversationBufferWindowMemory(k=2) # 保留前k轮会话
# memory = ConversationSummaryMemory(llm=llm) # 总结前面的对话内容
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100) # 超过最大token数量的会话,会被总结conversation = ConversationChain(llm=llm, memory=memory, verbose=True)result = conversation.predict(input='hello')
result = conversation.predict(input='你叫什么名字?')result = conversation.predict(input='感冒是一种什么病?')
result = conversation.predict(input='一般会有哪些症状?')
result = conversation.predict(input='吃什么药好得快?')
print(result)RequestsChain
针对大模型不知道的内容,使用搜索引擎搜索相关内容,然后让大模型进行总结
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenvload_dotenv()
llm = ChatOpenAI(model='gpt-3.5-turbo-1106')from langchain.chains import LLMRequestsChain
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplateprompt = PromptTemplate.from_template('''
请根据如下搜索结果,回答用户问题。
搜索结果:
-----------
{requests_result}
-----------
问题:{question}
回答:
''')llm_chain = LLMChain(llm=llm, prompt=prompt, verbose=True)chain = LLMRequestsChain(llm_chain=llm_chain,verbose=True
)# question = '刀郎最近发布了什么新专辑?'
question = '陈华编程是什么?'inputs = {'question': question,'url': 'https://www.google.com/search?q=' + question.replace(' ', '+') # google地址+问题
}result = chain.run(inputs)
print(result)
问答QAchain
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenvload_dotenv()llm = ChatOpenAI(model='gpt-3.5-turbo-1106', temperature=0)# 构建文档库
from langchain.schema import Documentcorpus = ['武汉市,简称“汉”,别称江城,湖北省辖地级市、省会,副省级市、国家中心城市、超大城市,国务院批复确定的中国中部地区的中心城市。', '武汉市下辖13个区,总面积8569.15平方千米。截至2022年末,常住人口1373.90万人,地区生产总值18866.43亿元。','武汉市地处江汉平原东部、长江中游,长江及其最大支流汉水在此交汇,形成武汉三镇(武昌、汉口、汉阳)隔江鼎立的格局。','湖北省,简称“鄂”,别名楚、荆楚,中华人民共和国省级行政区,省会武汉。','湖北省辖12个地级市、1个自治州,39个市辖区、26个县级市、37个县(其中2个自治县)、1个林区。','截至2022年末,湖北省常住人口5844万人,地区生产总值为53734.92亿元,人均地区生产总值为92059元。',
]documents = [Document(page_content=cp) for cp in corpus]
# print(documents)from langchain.chains.question_answering import load_qa_chainchain = load_qa_chain(llm=llm, chain_type='map_rerank', verbose=True)# question = '武汉三镇是哪三个?'
question = '湖北省常住人口是多少?'result = chain.run(input_documents=documents, question=question)
print(result)
FAISS 文档召回
from langchain.vectorstores.faiss import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema import Document
from dotenv import load_dotenv
from langchain.chat_models import ChatOpenAIfrom langchain.chains.question_answering import load_qa_chainload_dotenv()
llm = ChatOpenAI(model='gpt-3.5-turbo-1106', temperature=0)corpus = ['武汉市,简称“汉”,别称江城,湖北省辖地级市、省会,副省级市、国家中心城市、超大城市,国务院批复确定的中国中部地区的中心城市。', '武汉市下辖13个区,总面积8569.15平方千米。截至2022年末,常住人口1373.90万人,地区生产总值18866.43亿元。','武汉市地处江汉平原东部、长江中游,长江及其最大支流汉水在此交汇,形成武汉三镇(武昌、汉口、汉阳)隔江鼎立的格局。','湖北省,简称“鄂”,别名楚、荆楚,中华人民共和国省级行政区,省会武汉。','湖北省辖12个地级市、1个自治州,39个市辖区、26个县级市、37个县(其中2个自治县)、1个林区。','截至2022年末,湖北省常住人口5844万人,地区生产总值为53734.92亿元,人均地区生产总值为92059元。',
]documents = [Document(page_content=cp) for cp in corpus]embedding = OpenAIEmbeddings(model='text-embedding-ada-002')
documents_db = FAISS.from_documents(documents, embedding)chain = load_qa_chain(llm=llm, chain_type='stuff', verbose=True)question = '武汉三镇是哪三个?'
# question = '湖北省常住人口是多少?'# 检索出最相关的内容
retrieval_documents = documents_db.max_marginal_relevance_search(question, k=3) # 最大边际搜索,优化了与查询的相似性和文档之间的多样性
retrieval_documents = documents_db.similarity_search(question, k=3) # 相似性搜索,返回最相关的k条信息
retrieval_documents = documents_db.similarity_search_with_score(question, k=3) # 相似性搜索,并且返回相似度分数,分数越小越相关
retrieval_documents = documents_db.similarity_search_with_relevance_scores(question) # 相似性搜索,分数越大越相关print(retrieval_documents)
exit()result = chain.run(input_documents=retrieval_documents, question=question)
print(result)
读取文档并分割
from langchain.document_loaders import CSVLoader, TextLoader, PyMuPDFLoader
import osfile_dir = os.path.dirname(__file__)# loader = CSVLoader(os.path.join(file_dir, './data/about.csv'))
# print(len(loader.load()))# loader = PyMuPDFLoader(os.path.join(file_dir, './data/about.pdf'))
# loader = TextLoader(os.path.join(file_dir, './data/about.txt'))# print(loader.load())# 加载并分割文档
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(# separator = ['\n\n', '\n', ' ', ''],chunk_size = 50, # default:4000chunk_overlap = 10, # default:200
)loader = TextLoader(os.path.join(file_dir,'./data/about.txt'))
documents = loader.load_and_split(text_splitter)print(documents)
LLama
即便模型规模小,资源有限,如果选择适当的训练方法,用足够多高质量的数据训练足够长的时间,也能得到一个较好的模型








缓存线程池)



)

![[假面骑士] 555浅谈](http://pic.xiahunao.cn/[假面骑士] 555浅谈)
)



